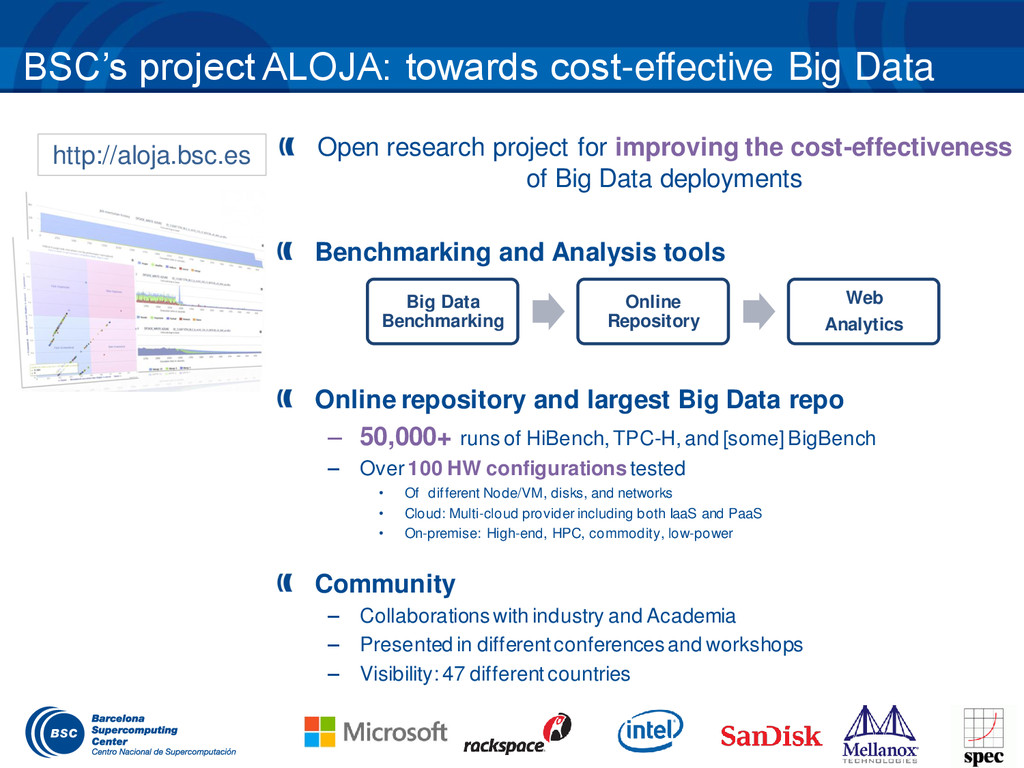
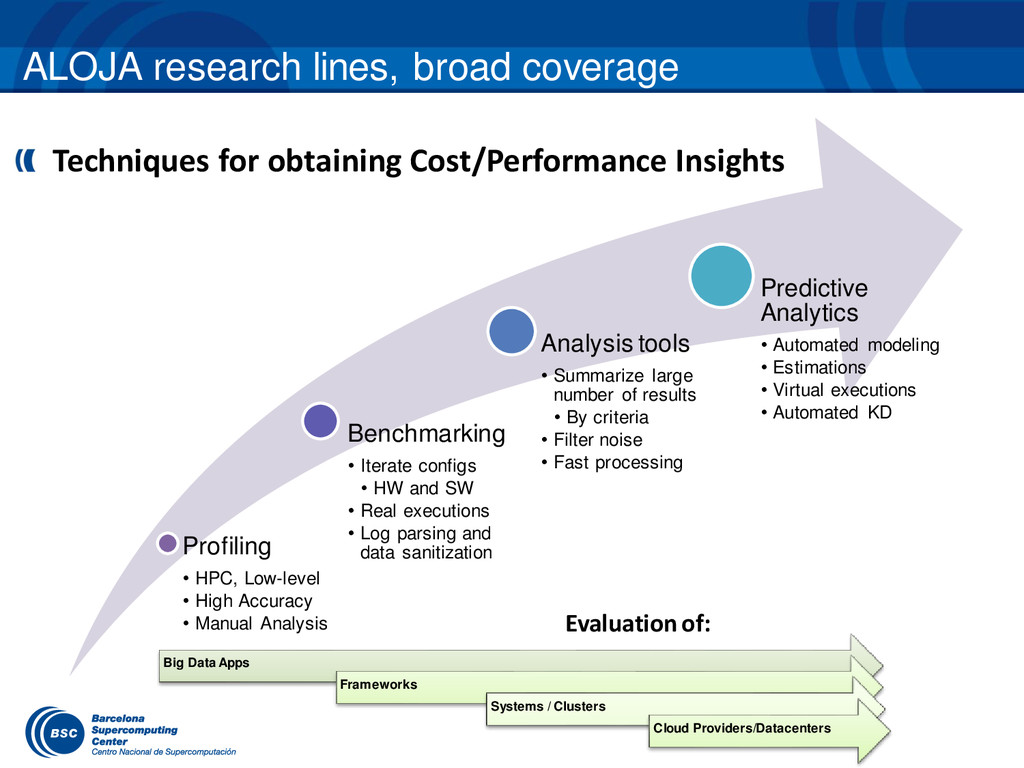
Automating Big Data Benchmarking and Performance Analysis workshop will give a hands-on experience on the different aspects getting the most value of Big Data infrastructures using ALOJA's open source tools. ALOJA (http://aloja.bsc.es), is a research initiative from the Barcelona Supercomputing Center (BSC) and Microsoft Research to explore new cost-effective hardware architectures and applications for Big Data. ALOJA's main goal and intent is to better understand the performance, therefore the costs of running different Big Data applications. As well as to automate Knowledge Discovery (KD) from system behavior, to produce insights that can optimize and guide the development of efficient Big Data applications and data centers.
Session presented at Big Data Spain 2015 Conference
15th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/program/thu/slot-20.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
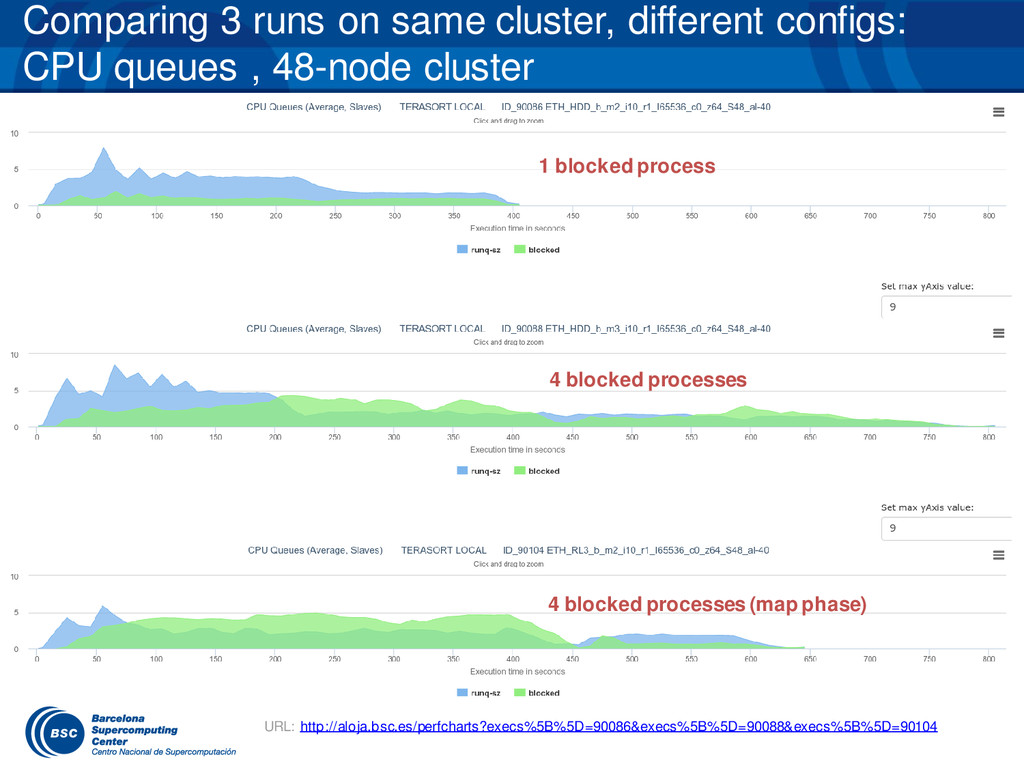{kind=link}
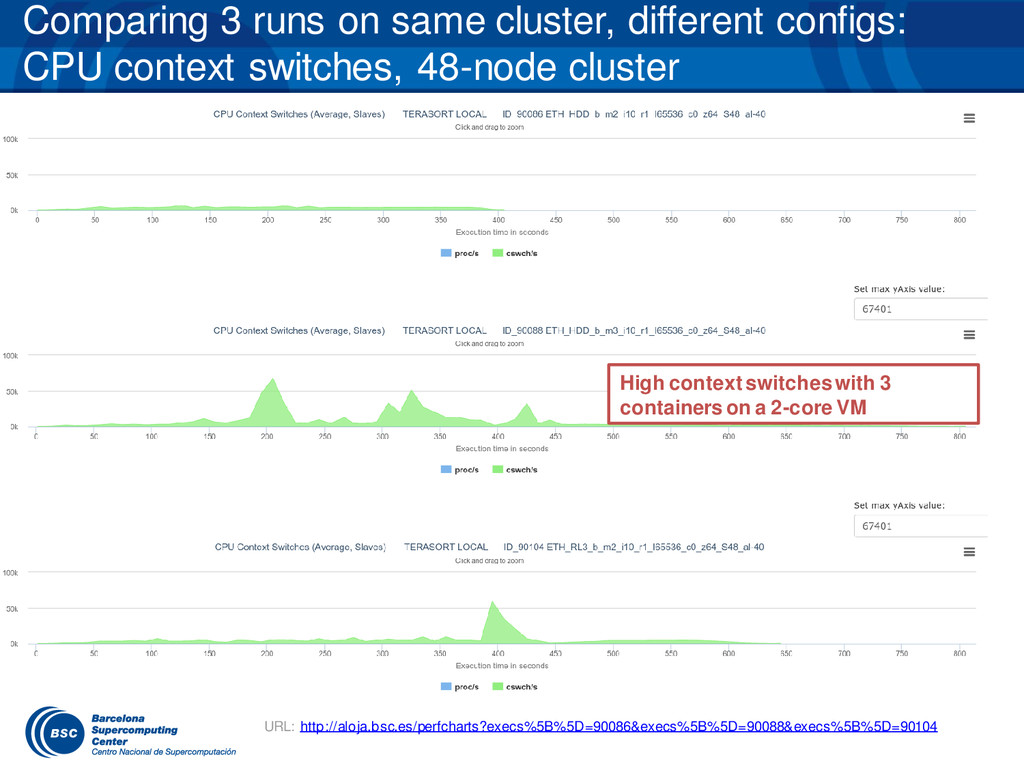{kind=link}
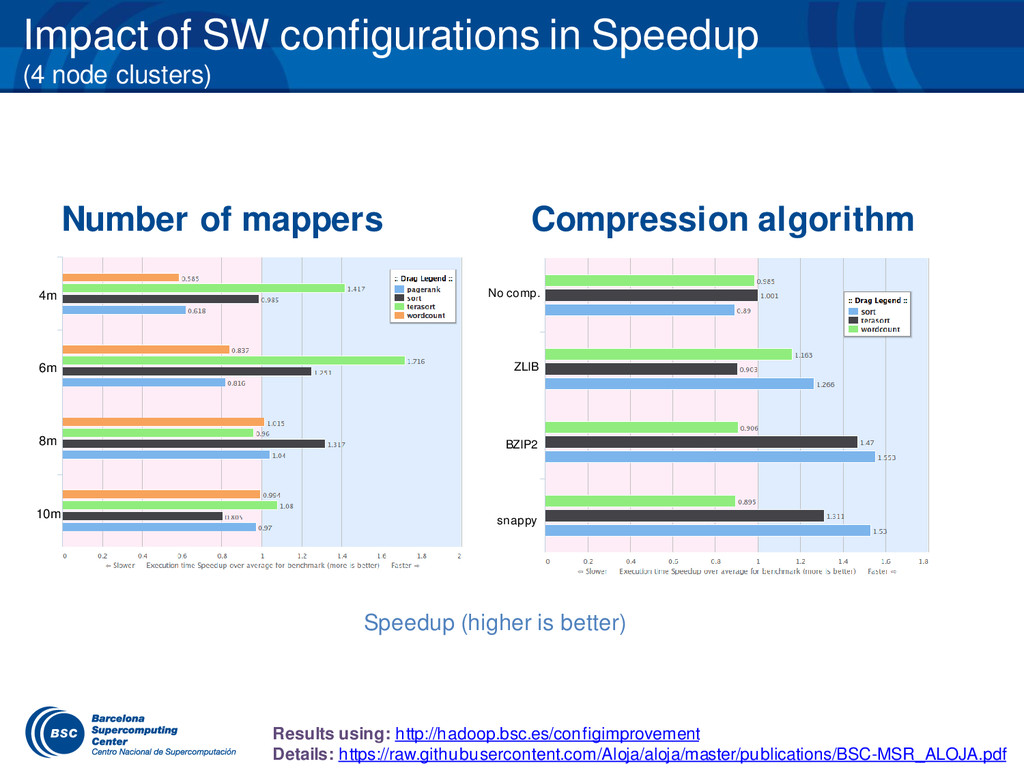{kind=link}
{kind=link}
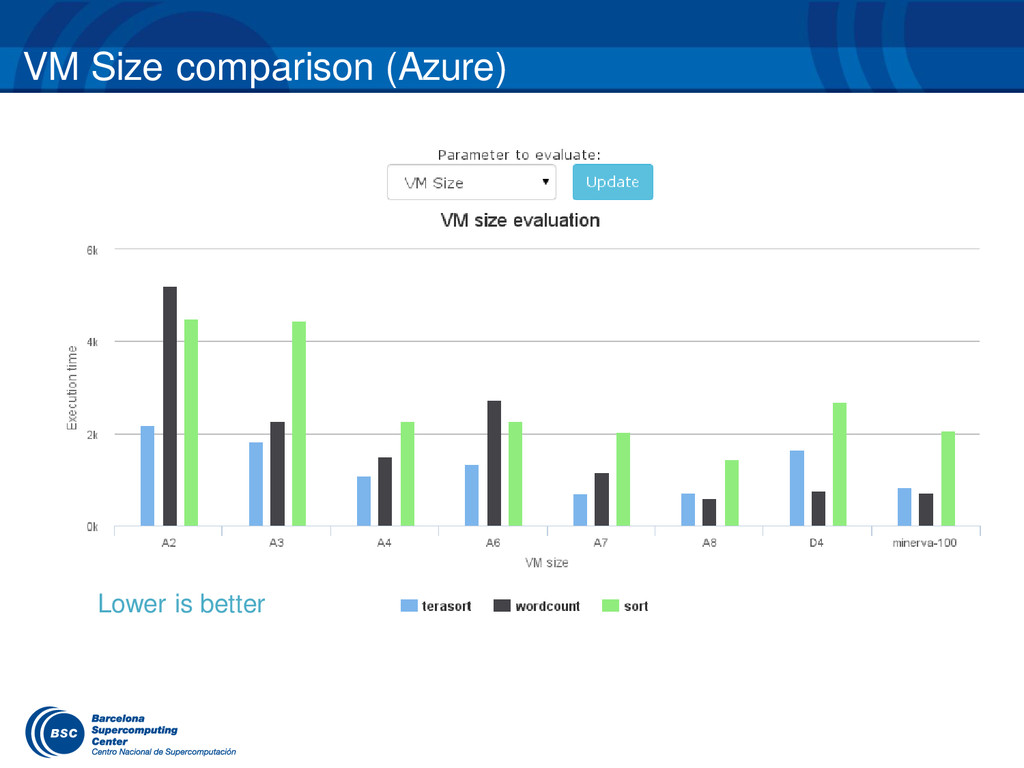{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.bsc.es Q&A Thanks! Contact: [email protected]](https://files.speakerdeck.com/presentations/ea23592acafc4cb2890f062926a437b2/slide_44.jpg){kind=link}