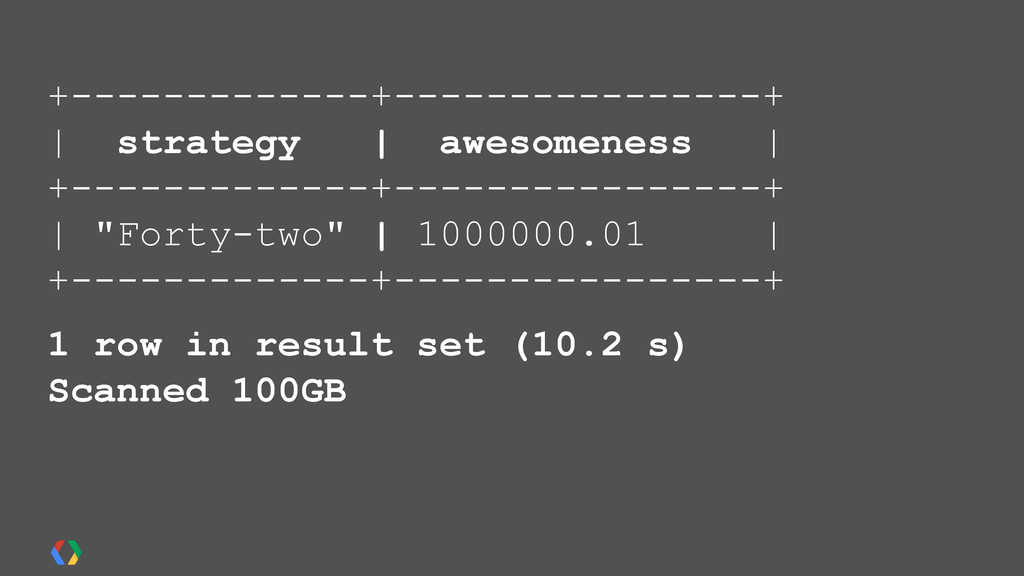
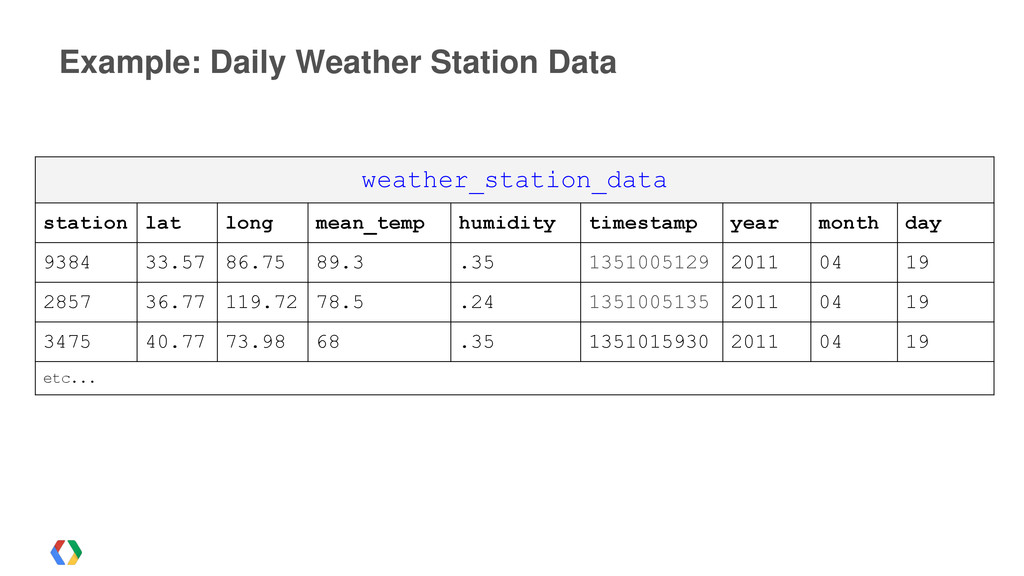
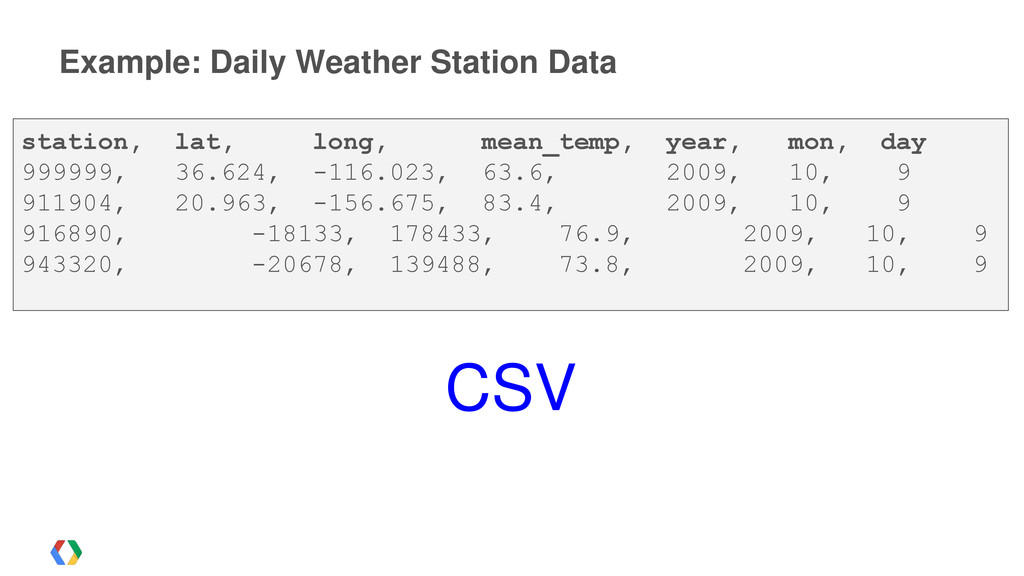
"Listens": [ {"TrackId":1234,"Title":"Gangam Style", "Artist":"PSY","Timestamp":1351075700}, {"TrackId":1234,"Title":"Alex Clare", "Artist":"Alex Clare",'Timestamp":1351075700} ] "Purchases": [ {"Track":2345,"Title":"Gangam Style", "Artist":"PSY","Timestamp":1351075700,"Cost":0.99} ]} JSON {"UserID" : "Michael", "Listens": [ {"TrackId":1234,"Title":"Gangam Style", "Artist":"PSY","Timestamp":1351075700}, {"TrackId":1234,"Title":"Alex Clare", "Artist":"Alex Clare",'Timestamp":1351075700} ] "Purchases": [ {"Track":2345,"Title":"Gangam Style", "Artist":"PSY","Timestamp":1351075700,"Cost":0.99} ]} {"UserID" : "Michael", "Listens": [ {"TrackId":1234,"Title":"Gangnam Style", "Artist":"PSY","Timestamp":1351075700}, {"TrackId":1234,"Title":"Alex Clare", "Artist":"Alex Clare",'Timestamp":1351075700} ] "Purchases": [ {"Track":2345,"Title":"Gangnam Style", "Artist":"PSY","Timestamp":1351075700,"Cost":0.99} ]}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
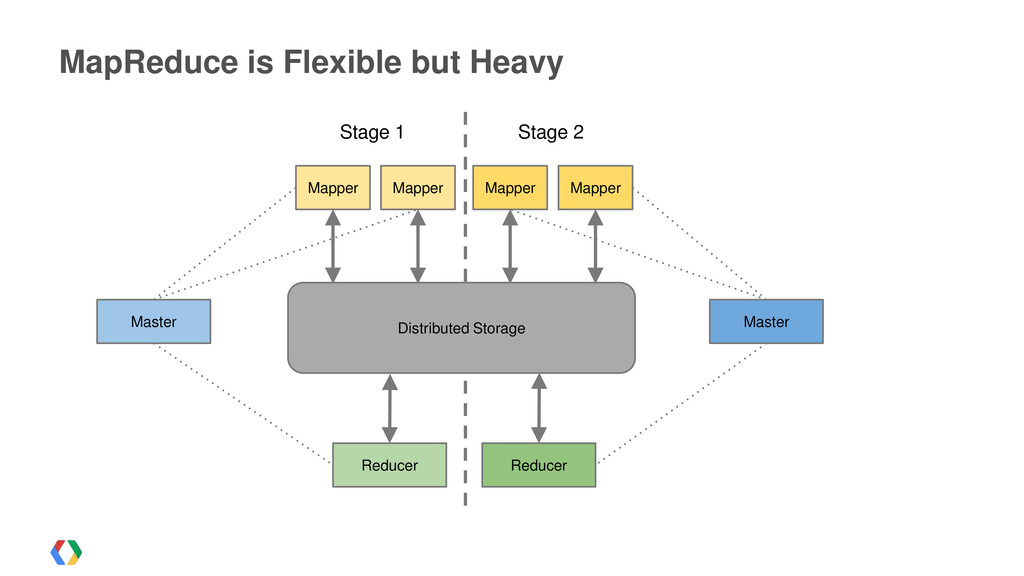
{kind=link}
{kind=link}
{kind=link}
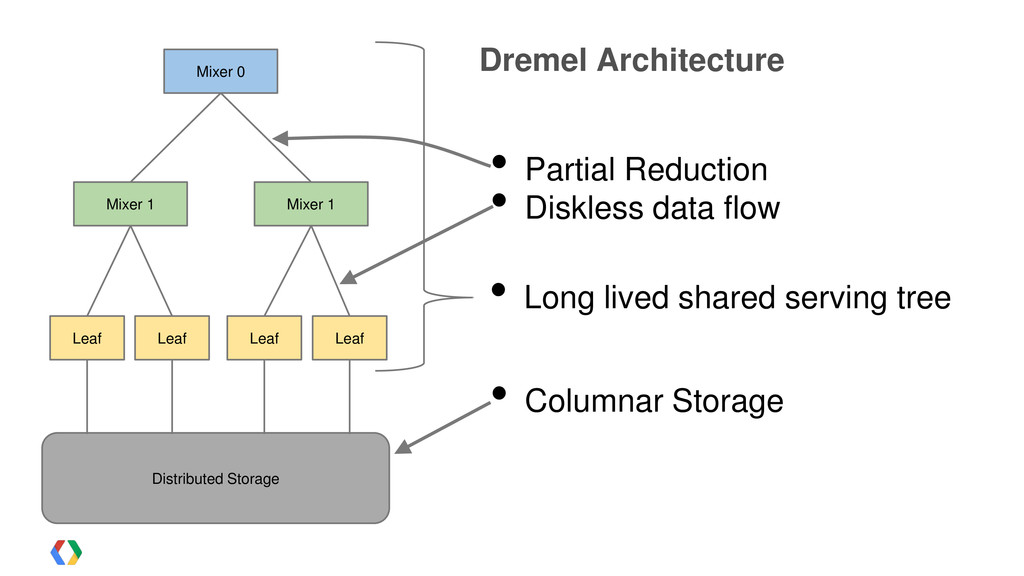
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
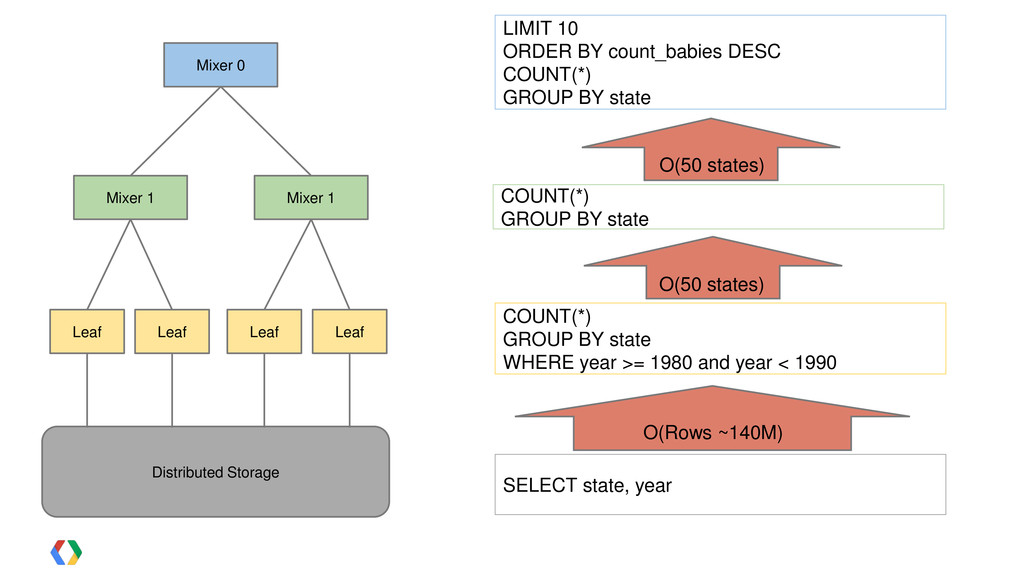
![SELECT state, COUNT(*) count_babies FROM [publicdata:samples.natality] WHERE year >= 1980](https://files.speakerdeck.com/presentations/922968101b69013014db1231380fad16/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
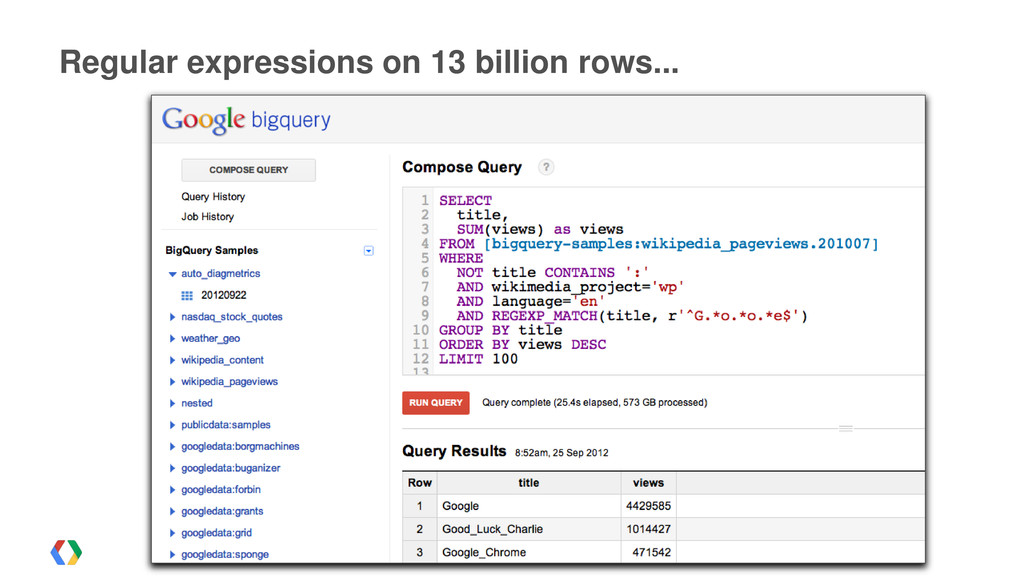
![SELECT AVG(POSITION(ListenActivities.artist)) FROM [sample_music_logs.oct_24_2012_songactivities], [sample_music_logs.oct_23_2012_songactivities], /* etc... */ WHERE ListenActivities.artist](https://files.speakerdeck.com/presentations/922968101b69013014db1231380fad16/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
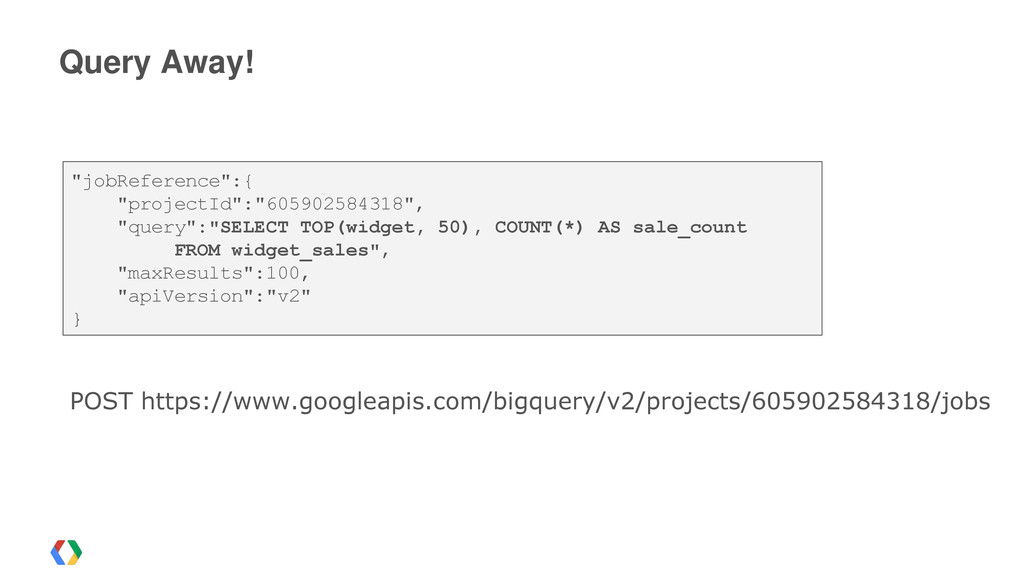{kind=link}
{kind=link}
{kind=link}
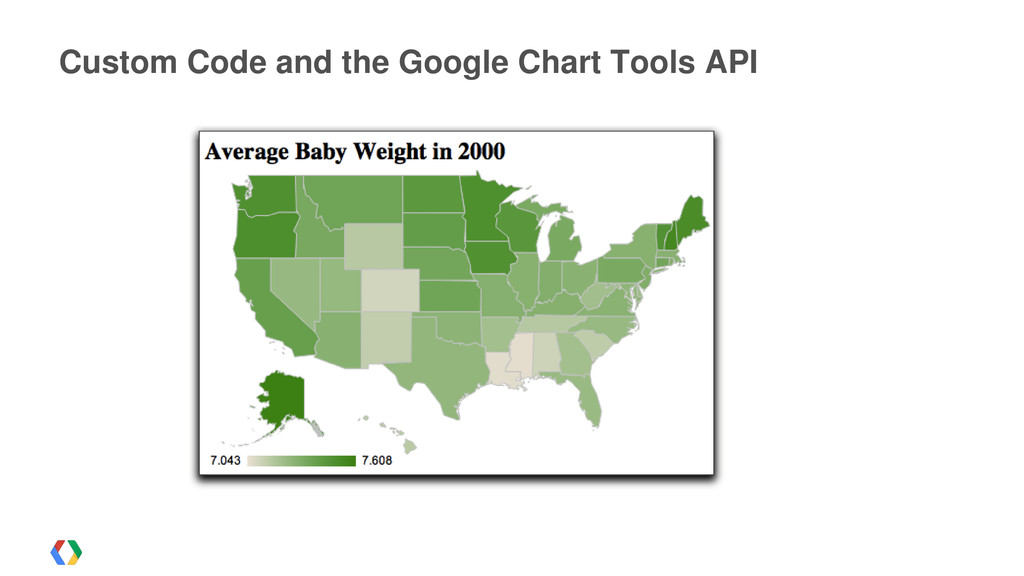{kind=link}
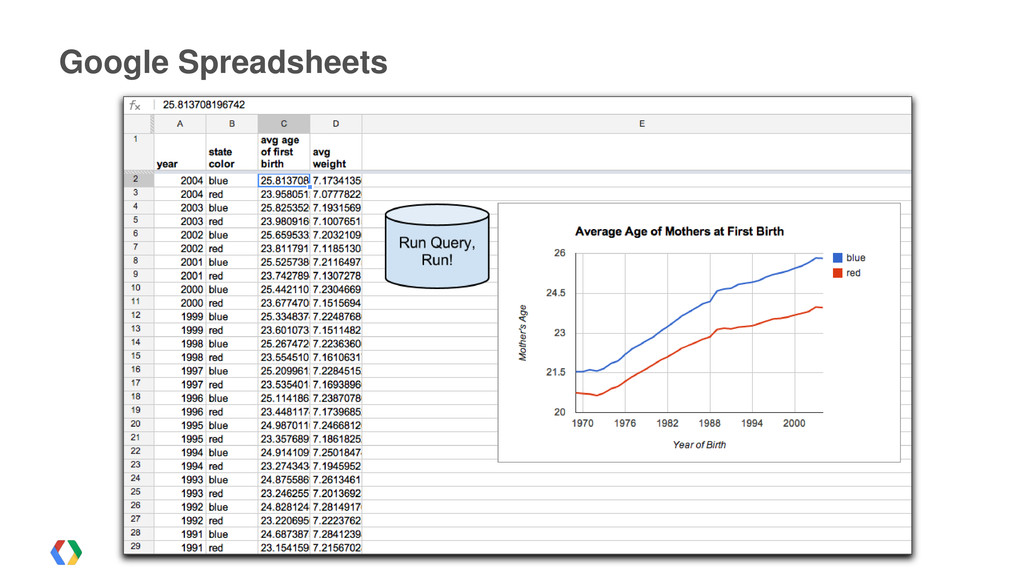{kind=link}
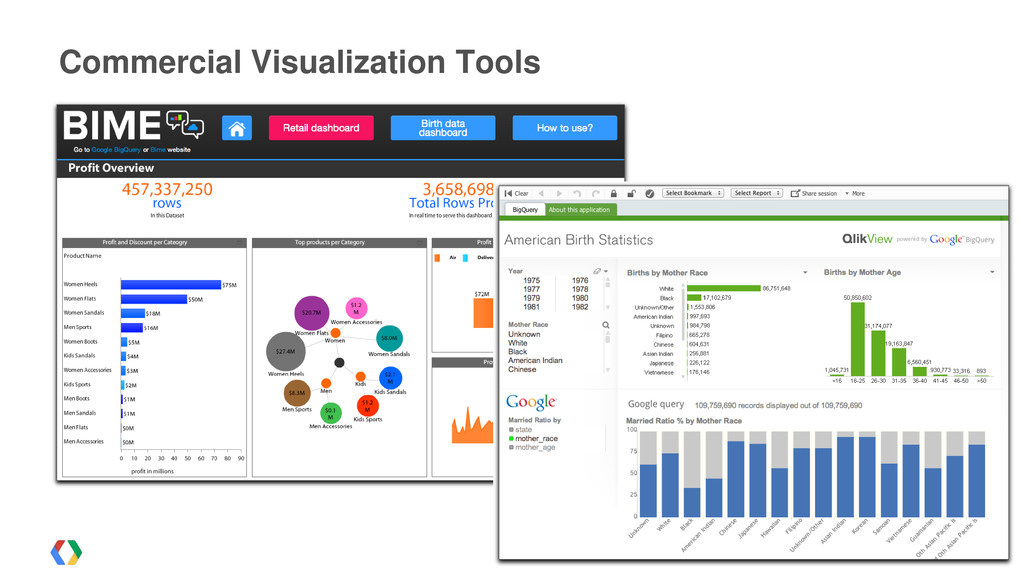{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
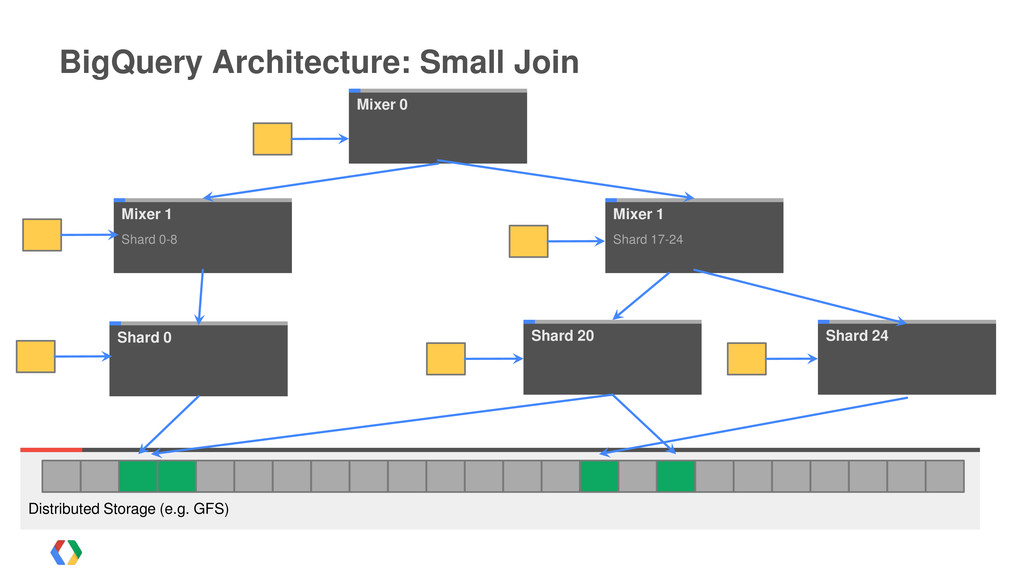{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
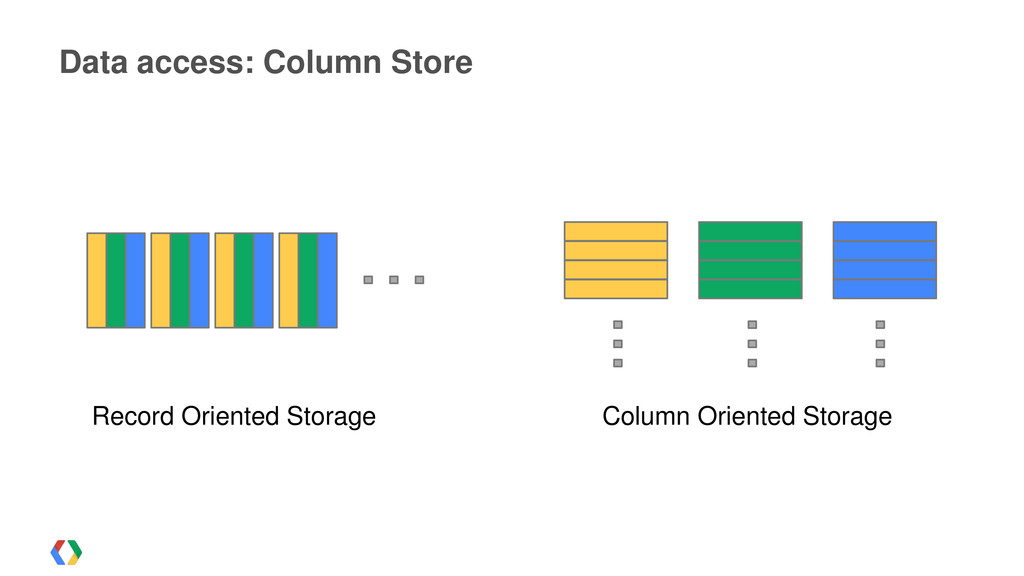{kind=link}
{kind=link}
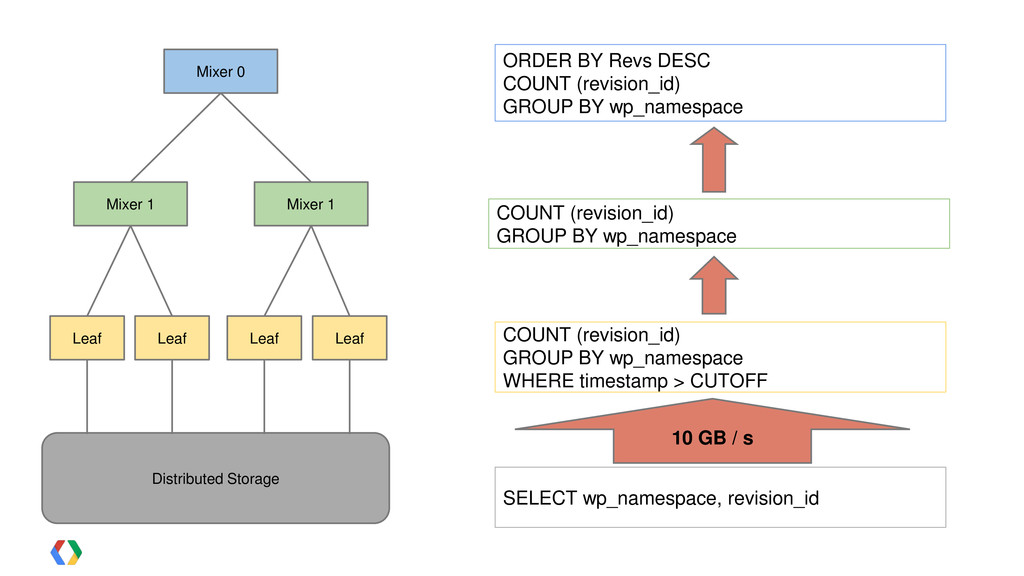{kind=link}
!["Multi-stage" Query SELECT contributor_id, INTEGER(LOG10(COUNT(revision_id))) LogEdits FROM [publicdata:samples.wikipedia] SELECT contributor_id,](https://files.speakerdeck.com/presentations/922968101b69013014db1231380fad16/slide_68.jpg){kind=link}
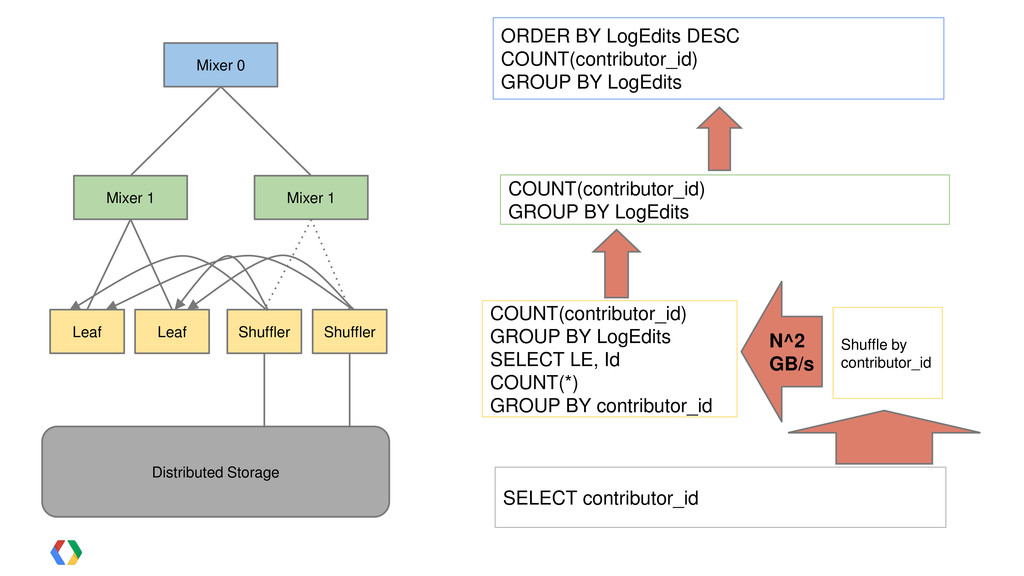{kind=link}
{kind=link}