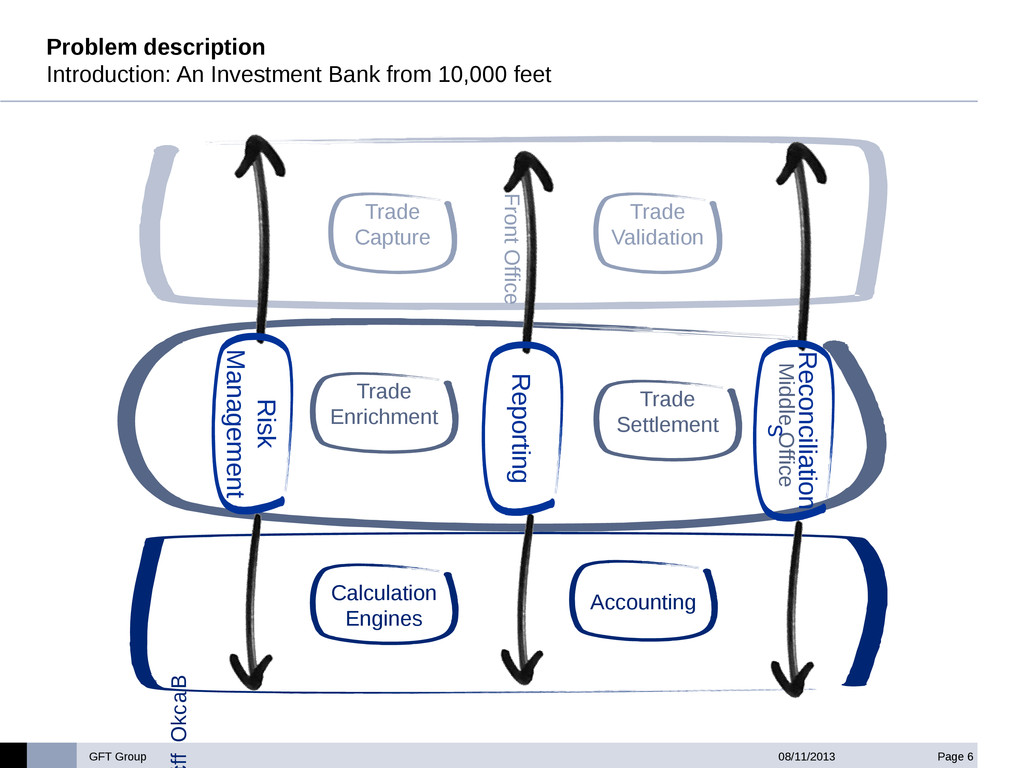
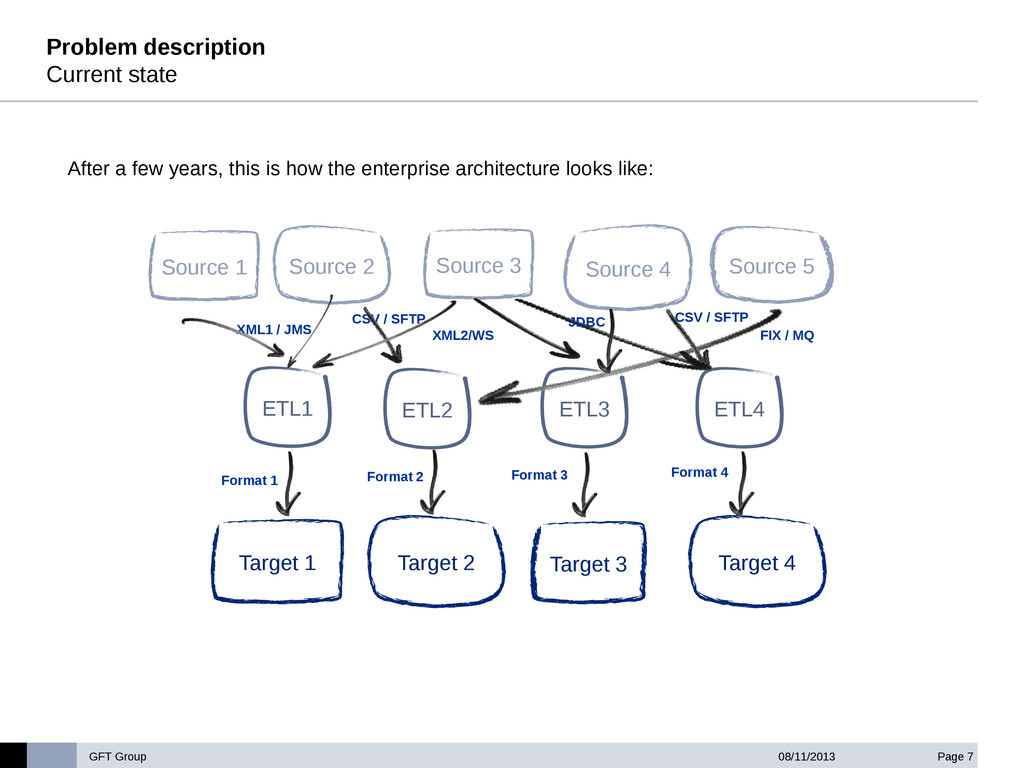
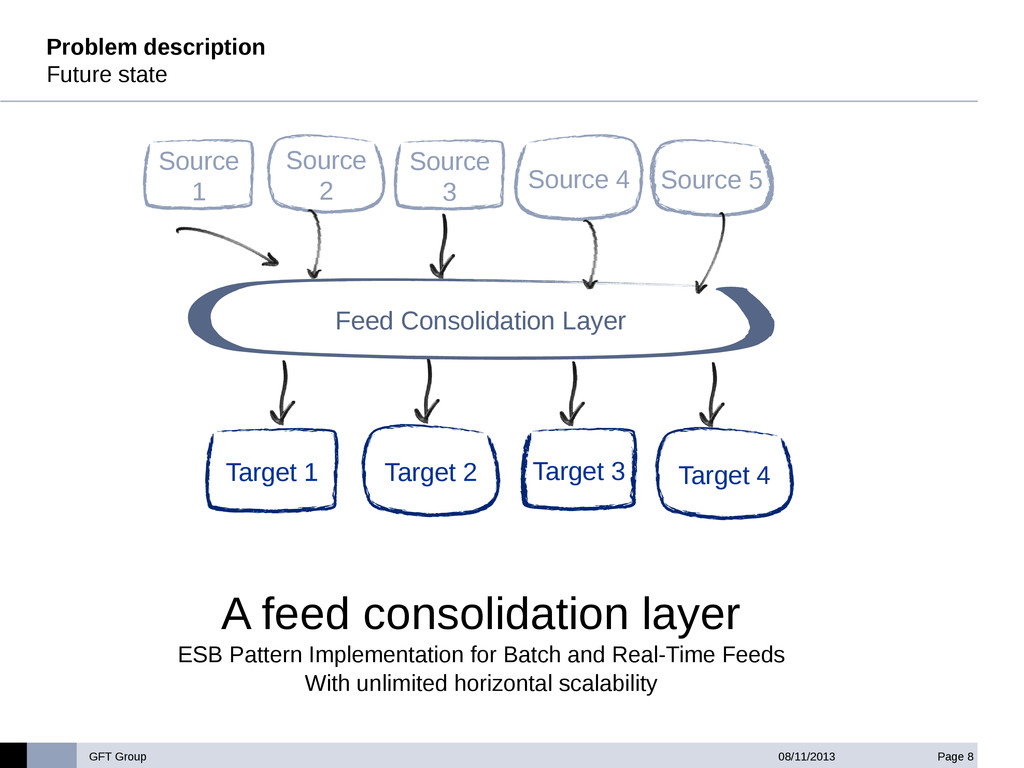
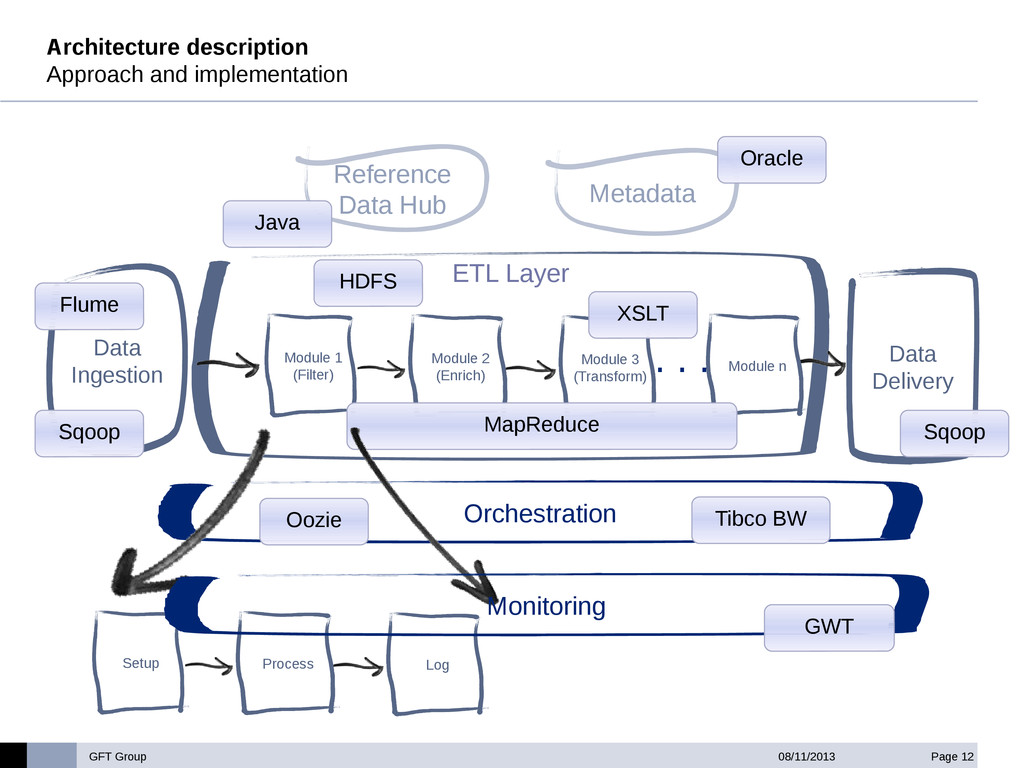
GFT has built an ETL accelerator platform under Hadoop for a big international investment bank. This ETL layer is used to consolidate, enrich and validate financial data gathered from different source systems in the bank, and make it available to the Accounting Layer of the bank in an homogeneous format .
8th Nov 2013
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/2013/conference/developing-a-hadoop-based-etl-platform-for-feed-consolidation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}