and K. E. Maarry, “Design patterns for hybrid algorithmic crowdsourcing workflows,” in CBI, 2014, pp. 1–8. • N. Luz, N. Silva, and P. Novais, “A survey of task-oriented crowdsourcing,” Artificial Intelligence Review, pp. 1–27, 2014. • N. Luz, N. Silva, and P. Novais, “Generating human-computer microtask workflows from domain ontologies,” in Human-Computer Interaction. Theories, Methods, and Tools. Springer, 2014, pp. 98–109. • E. Kamar, S. Hacker, and E. Horvitz, “Combining human and machine intelligence in large-scale crowdsourcing” in AAMAS, 2012, pp.467-474. • S. K. Kondreddi, P. Triantafillou, and G. Weikum, “Combining information extraction and human computing for crowdsourced knowledge acquisition,” in ICDE, 2014, pp. 988–999. • There are no related work on academic knowledge discovery and acquisition using crowdsourcing methods.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
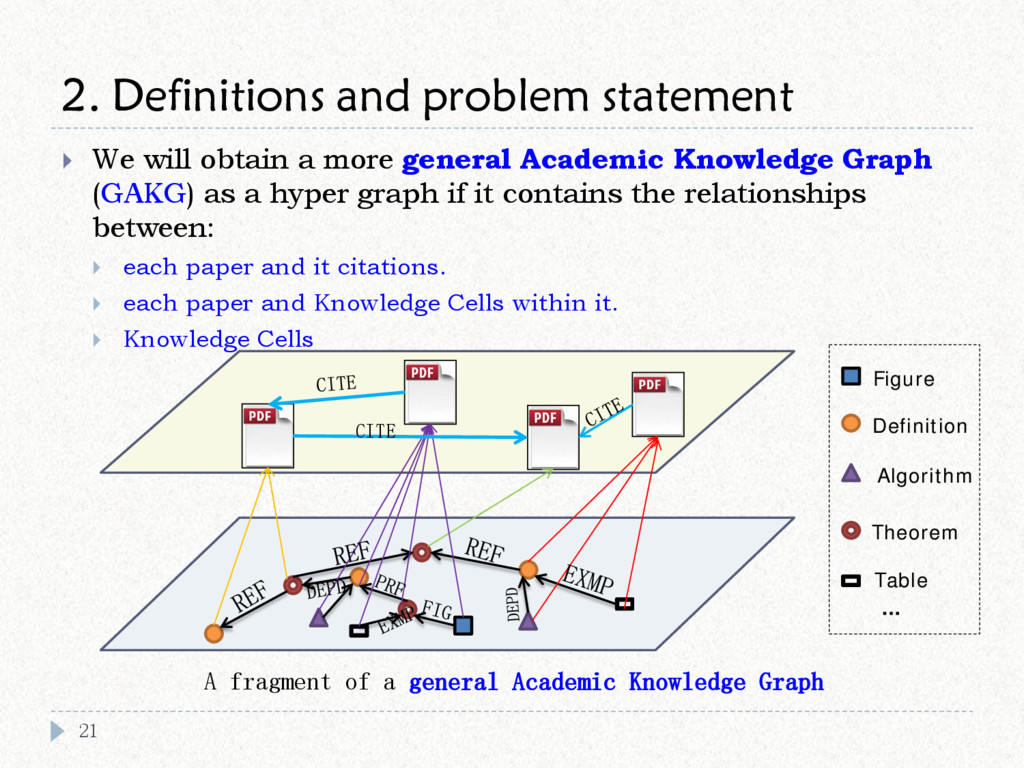{kind=link}
{kind=link}
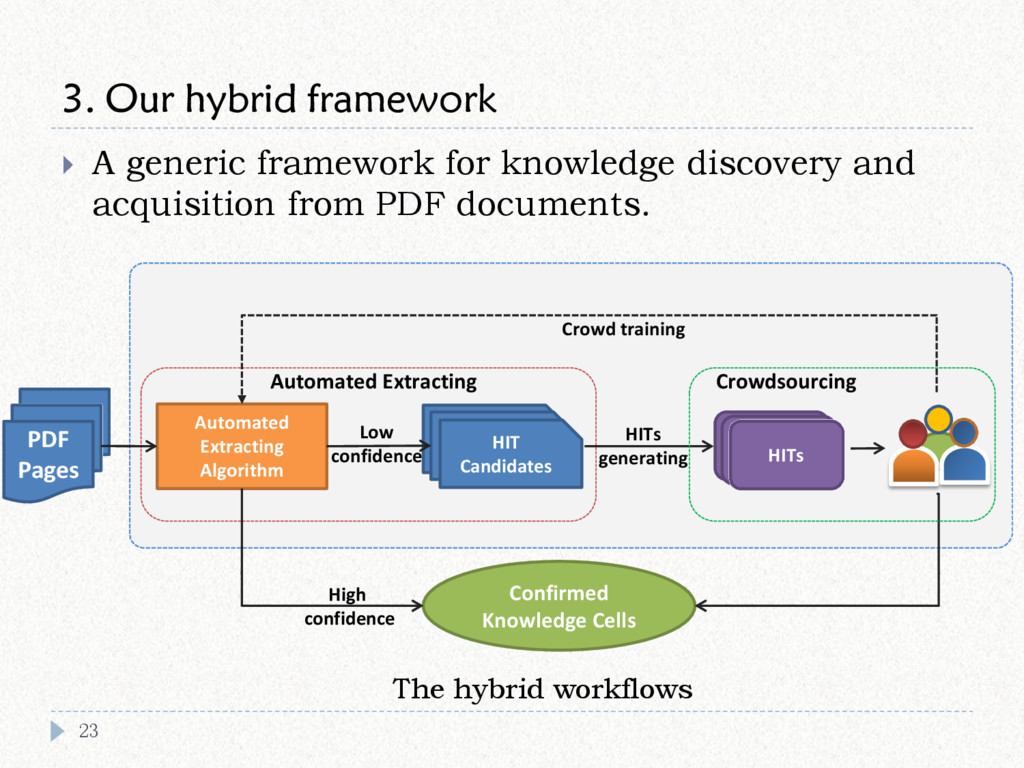{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
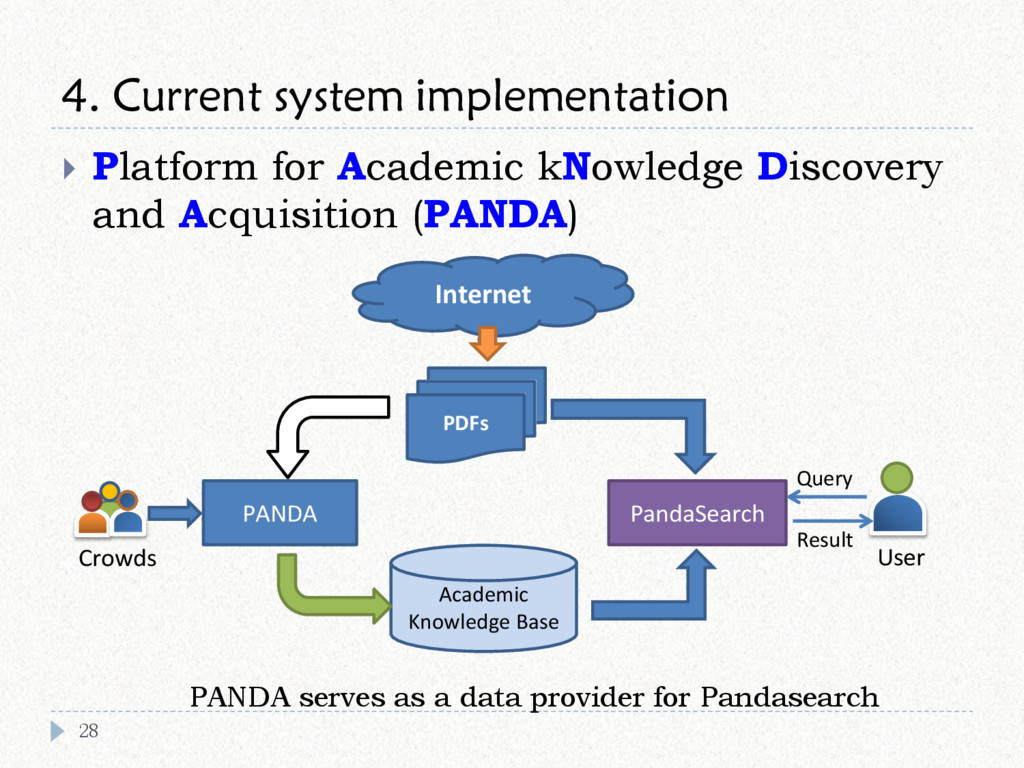{kind=link}
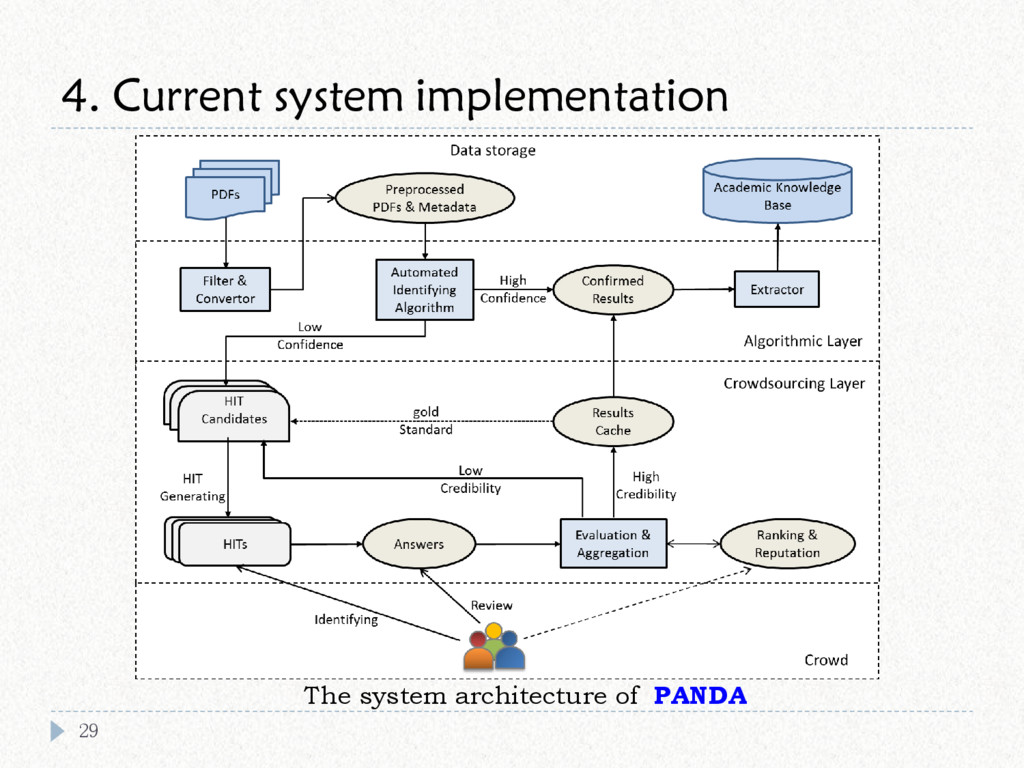{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![45 Thank you! Email: [email protected]](https://files.speakerdeck.com/presentations/eed0399031b642aa97c5df24ed3fc050/slide_44.jpg){kind=link}