Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DTD_TensorRTを用いた自然言語処理モデルの高速化
Search
BrainPad
December 18, 2025
Technology
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DTD_TensorRTを用いた自然言語処理モデルの高速化
BrainPad
December 18, 2025
More Decks by BrainPad
See All by BrainPad
白金鉱業Meetup_Vol.24_「AIエージェントは分けるほど良い」は本当か? / Is it true that “the more you divide AI agents, the better”?
brainpadpr
1
550
「ビジネス現場でのデータ分析者」 東京大学 GCI 2026 Summer
brainpadpr
2
2.3k
BrainPad_DE_202604
brainpadpr
1
14k
BrainPad AAA_AIエージェントの社会実装する上での壁 / Barriers to the Social Implementation of AI Agents
brainpadpr
1
280
白金鉱業Meetup_Vol.22_Orbital Senseを支える衛星画像のマルチモーダルエンベディングと地理空間のあいまい検索技術
brainpadpr
3
450
DTD_AIエージェント開発プロジェクトのメソッドを体系化してみる
brainpadpr
1
380
DTD_Databricksことはじめ
brainpadpr
0
320
【採用候補者向け】BrainPad AAAご紹介資料
brainpadpr
0
2.4k
DTD_はじめての因子分析_理論とビジネス活用.pdf
brainpadpr
2
2.6k
Other Decks in Technology
See All in Technology
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
810
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
300
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
280
穢れた技術選定について
watany
19
6.2k
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
210
人とエージェントが高め合う協業設計
kintotechdev
0
850
GoでCコンパイラを作った話
repunit
0
150
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
170
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
380
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
5
500
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
280
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
270
Featured
See All Featured
Crafting Experiences
bethany
1
230
How STYLIGHT went responsive
nonsquared
100
6.2k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Google's AI Overviews - The New Search
badams
0
1.1k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
ラッコキーワード サービス紹介資料
rakko
1
4M
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
AI: The stuff that nobody shows you
jnunemaker
PRO
9
840
Transcript
DEU TECH DRIVE TensorRTを⽤いた⾃然⾔語処理モデルの⾼速化 2025年12月18日
2 ©BrainPad Inc. Strictly Confidential 自己紹介 2023年、ブレインパッドに新卒入社。学生時代は情報理工学を専攻。入社後は大規模言語モデル、画像生成 モデルを用いた案件に従事。現在は自然言語処理モデルを用いた推論システムの構築を行っている 株式会社ブレインパッド 機械学習エンジニア
栄喜 宥汰 (えいき ゆうた) 主な案件 - LLMチャットボット(RAG)構築 - 画像生成モデルを利用したプロダクトのPoC - 自然言語処理モデルの学習改善・推論基盤の実装
©BrainPad Inc. Strictly Confidential 3 1.導⼊・背景 - なぜ推論⾼速化が必要か 2.TensorRTの概要 -
仕組みと特徴 3.実装⽅法 - Hugging Face Optimumとの連携 4.ベンチマーク結果 - ⾼速化効果の検証 5.まとめ・今後の展望 アジェンダ
©BrainPad Inc. Strictly Confidential 1. 導⼊・背景
5 ©BrainPad Inc. Strictly Confidential 深層学習推論の課題 ①:待ち時間 課題:モデルの"待ち時間" = ⼈の待ち時間
toB:結果が出るまで次の作業が⽌まる toC:応答遅延 → UX悪化・離脱率上昇 「待ち時間」の積み上がりが⽣産性を低下させ る 解決策 推論⾼速化でレイテンシを短縮 → 業務効率とユーザー体験の向上
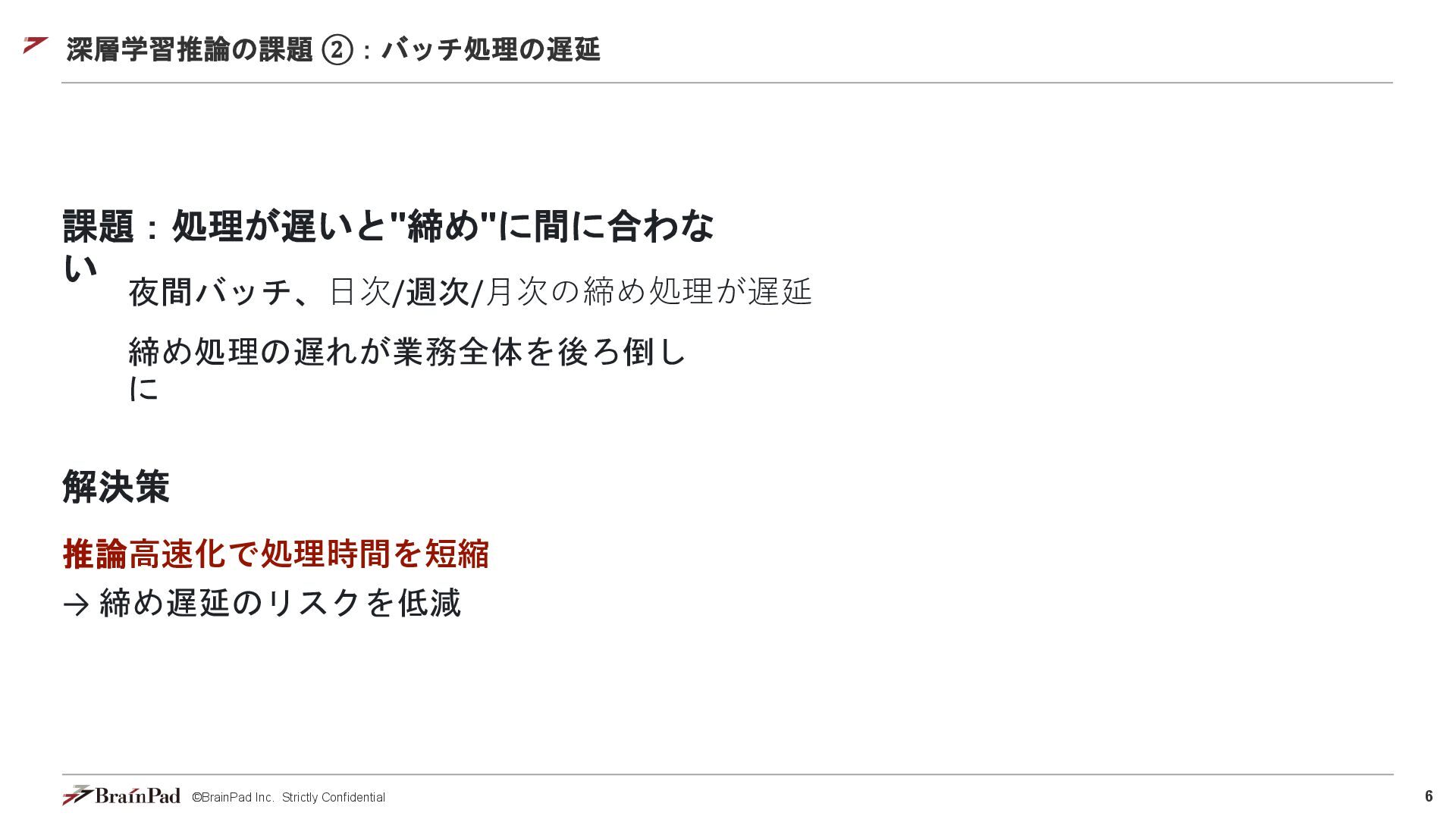
6 ©BrainPad Inc. Strictly Confidential 深層学習推論の課題 ②:バッチ処理の遅延 課題:処理が遅いと"締め"に間に合わな い 夜間バッチ、⽇次/週次/⽉次の締め処理が遅延
締め処理の遅れが業務全体を後ろ倒し に 解決策 推論⾼速化で処理時間を短縮 → 締め遅延のリスクを低減
7 ©BrainPad Inc. Strictly Confidential 深層学習推論の課題 ③:コスト増⼤ 課題:処理が遅いほど運⽤コストが増える ⼩さな処理時間の差が⽉次コストに直 撃
⻑期運⽤での累積コストが膨⼤ に 解決策 推論⾼速化でリソース効率を向上 → 同じ処理量をより少ないリソースで実⾏、クラウド課⾦を削減
8 ©BrainPad Inc. Strictly Confidential モデル圧縮 ⽐較的少ない⼯数で効果が出やすい 主な⼿法 ⼿法 概要
特徴 量⼦化・枝刈り 効果がモデル/環境次第でブレやすい TensorRT 推論実⾏の最適化 量⼦化・枝刈りの課題 効果がモデル/実⾏環境/設計次第でブレやすい 速度改善には精度検証・キャリブレーションなど⼯数がかかる 推論⾼速化の選択肢
9 ©BrainPad Inc. Strictly Confidential TensorRTの優位性(NVIDIA GPU環境の場合) ⽐較的少ない⼯数で実⾏⽅法そのものを最適化 速度改善が出やすい 万能ではないが、最初に狙うべき⼿堅い⼀⼿
実務での優先順位 1. GPU + TensorRT(まずFP16) ← 本発表のスコープ 2. 必要なら TensorRT INT8 3. さらに必要なら 量⼦化/枝刈り 推論⾼速化の優先順位
©BrainPad Inc. Strictly Confidential 2. TensorRTの概要
11 ©BrainPad Inc. Strictly Confidential TensorRT は、NVIDIAが提供する深層学習推論最適化エンジン 訓練済みモデルを最適化して⾼速な推論を実 現 NVIDIA
GPU上で動作 Python APIを提供 TensorRTとは
12 ©BrainPad Inc. Strictly Confidential 1. グラフ/モデル最適化 レイヤーフュージョン:連続するレイヤーを統合、メモリアクセスを削減 グラフ最適化:不要演算の削除、定数化で計算を軽量化 2.
精度最適化(低精度化) FP32 → FP16:精度影響が⼩さく、まず狙う定番の⾼速化 FP32 → INT8:さらに⾼速化可能(精度検証・キャリブレーションが必要) 3. エンジン化 最適化済みモデルをTensorRTエンジンとして保存・再利⽤ TensorRTの主な機能
13 ©BrainPad Inc. Strictly Confidential ONNX フレームワーク⾮依存のモデル形式 PyTorch、TensorFlowなどからエクスポート可能 TensorRTはONNX形式のモデルを最適化可能 Hugging
Face Optimumとの連携 Optimum:Hugging Faceが提供する最適化ライブラリ ONNX Runtime経由でTensorRTを利⽤ Transformersモデルを簡単にTensorRT最適化可能 対応フレームワーク・モデル形式
©BrainPad Inc. Strictly Confidential 3. 実装⽅法
15 ©BrainPad Inc. Strictly Confidential Optimumとは Hugging Faceが提供する最適化ライブラリ TensorRT、ONNX Runtimeなどを統⼀的に利⽤可能
主な利点 簡単なAPI:数⾏のコードで最適化 Transformers互換:既存コードを最⼩限の変更で利⽤ ⾃動変換:モデル形式の変換を⾃動化 Hugging Face Optimumとの連携
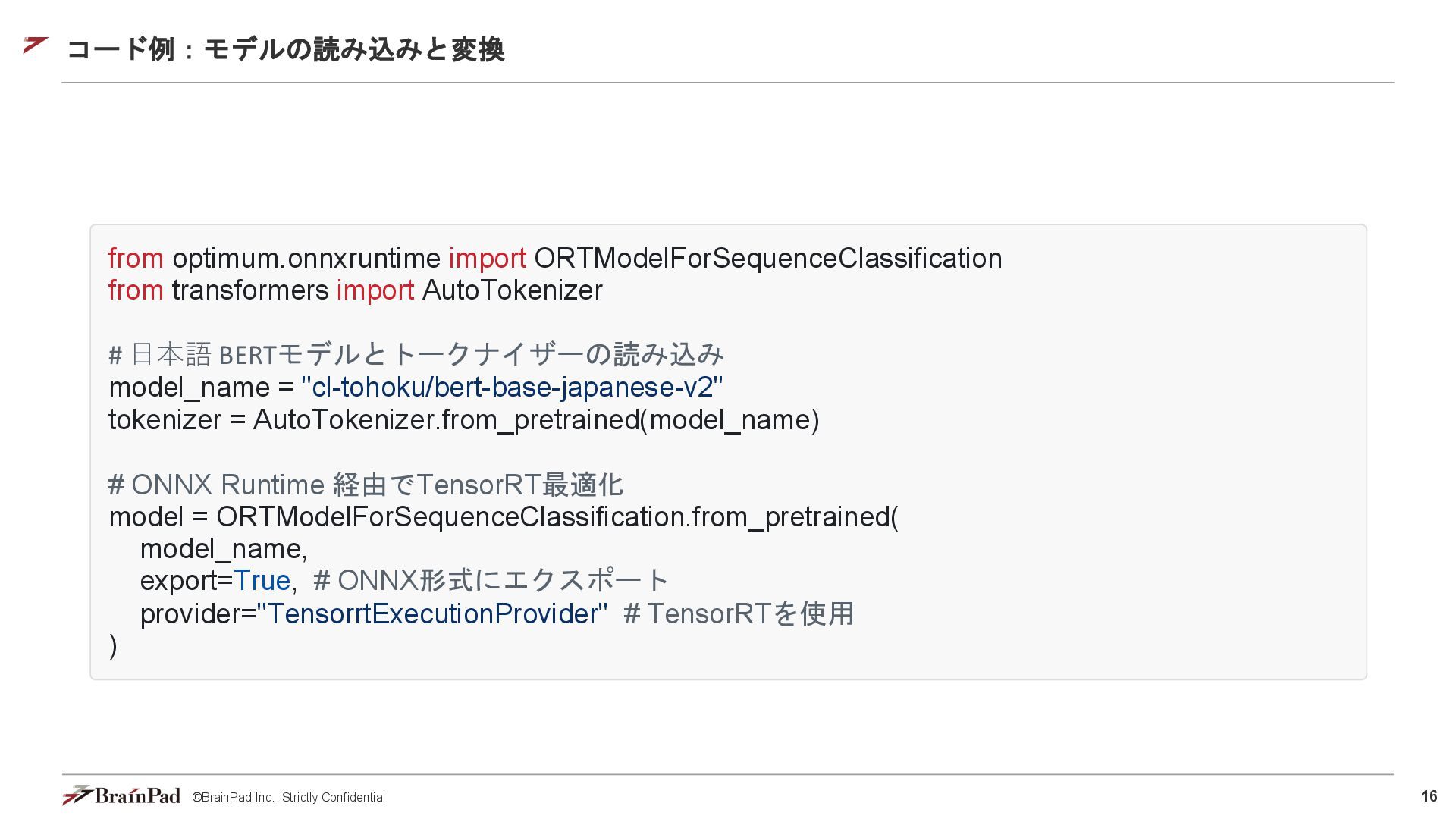
16 ©BrainPad Inc. Strictly Confidential from optimum.onnxruntime import ORTModelForSequenceClassification from
transformers import AutoTokenizer # ⽇本語 BERTモデルとトークナイザーの読み込み model_name = "cl-tohoku/bert-base-japanese-v2" tokenizer = AutoTokenizer.from_pretrained(model_name) # ONNX Runtime 経由でTensorRT最適化 model = ORTModelForSequenceClassification.from_pretrained( model_name, export=True, # ONNX形式にエクスポート provider="TensorrtExecutionProvider" # TensorRTを使用 ) コード例:モデルの読み込みと変換
17 ©BrainPad Inc. Strictly Confidential export=True ポイント で⾃動的にONNX形式に変換 → TensorRTで最適化
BERT系など多くのTransformersモデルはそのまま動作 注意点 ModernBERTのように未対応のモデルは独⾃でエクスポート処理が必要 新しいアーキテクチャは対応状況を要確 認 モデル対応状況
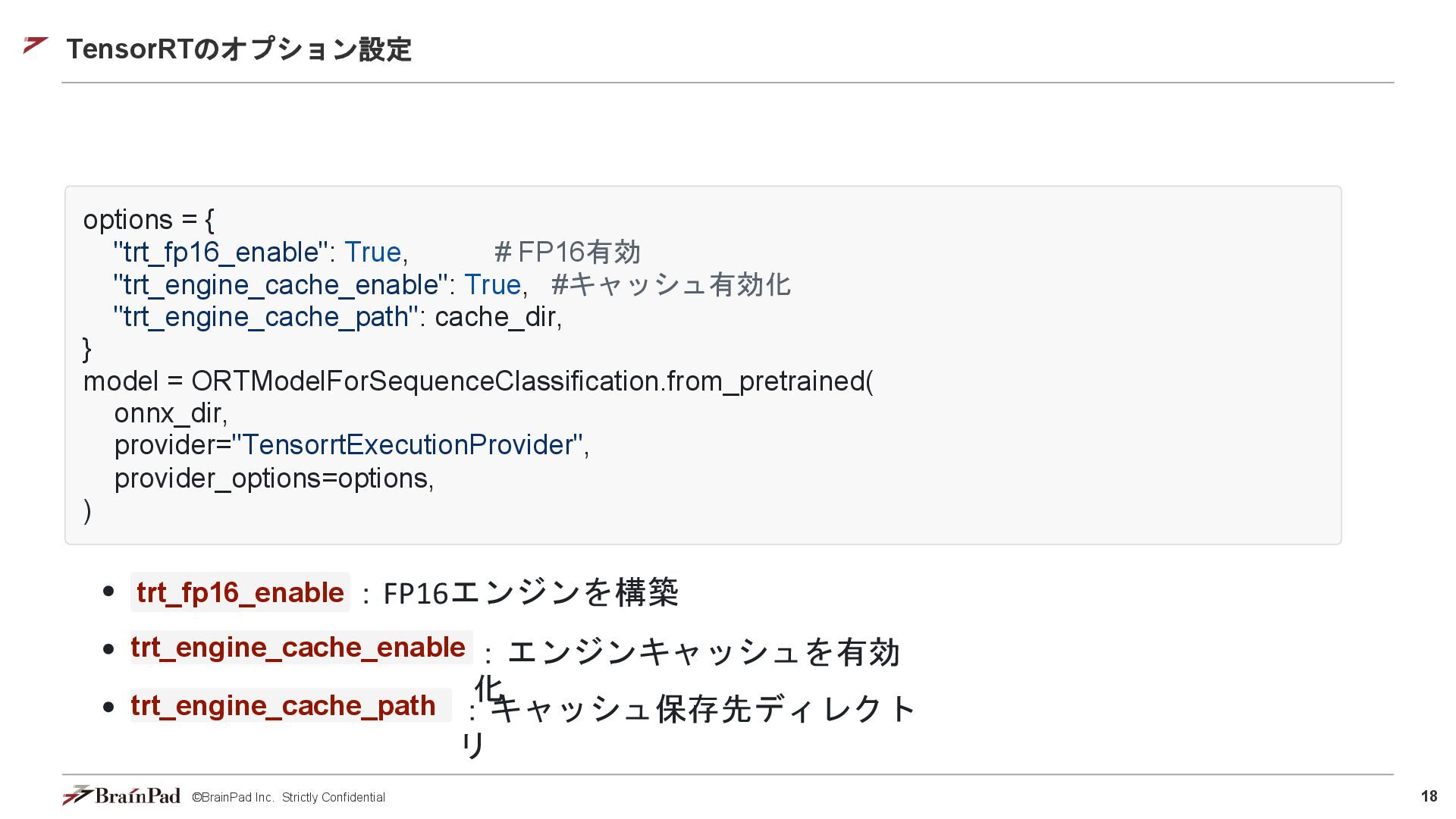
18 ©BrainPad Inc. Strictly Confidential options = { "trt_fp16_enable": True,
# FP16有効 "trt_engine_cache_enable": True, #キャッシュ有効化 "trt_engine_cache_path": cache_dir, } model = ORTModelForSequenceClassification.from_pretrained( onnx_dir, provider="TensorrtExecutionProvider", provider_options=options, trt_fp16_enable ) trt_engine_cache_enable :FP16エンジンを構築 trt_engine_cache_path :エンジンキャッシュを有効 化 :キャッシュ保存先ディレクト リ TensorRTのオプション設定
©BrainPad Inc. Strictly Confidential 4. ベンチマーク結果
20 ©BrainPad Inc. Strictly Confidential 実⾏環境 GPU:NVIDIA Tesla T4(クラウド環境) CUDA:12.9
Python:3.12 PyTorch:2.9.1 推論エンジン:ONNX Runtime + TensorRT Execution Provider モデル・データセット モデル:modernbert-ja-130m データセット:Livedoorニュースコーパス 測定環境
21 ©BrainPad Inc. Strictly Confidential パラメータ バッチサイズ:1, 8, 16, 32
ウォームアップ:10回 測定回数:50回 測定項⽬:スループット(samples/sec)、レイテンシ(ms) ⽐較対象 FP32:Transformers(ベースライン) vs TensorRT FP16:Transformers vs TensorRT 測定条件
22 ©BrainPad Inc. Strictly Confidential FP32:スループット⽐較 FP32ではスループットの伸びは約1.1倍 バッチサイズ Transformers FP32
TensorRT FP32 ⾼速化率 1 28.8 samples/s 31.1 samples/s 1.08x 8 32.9 samples/s 35.6 samples/s 1.08x 16 33.5 samples/s 36.5 samples/s 1.09x 32 34.6 samples/s 36.7 samples/s 1.06x
23 ©BrainPad Inc. Strictly Confidential FP32:レイテンシ⽐較 FP32ではスループットの伸びは約1.1倍 バッチサイズ Transformers FP32
TensorRT FP32 改善率 1 34.7ms 32.1ms 7.5% 8 234.0ms 215.8ms 7.8% 16 426.9ms 391.6ms 8.3% 32 723.4ms 680.4ms 5.9%
24 ©BrainPad Inc. Strictly Confidential FP16:スループット⽐較 バッチサイズ1で3.5倍、8〜32でも1.1〜1.3倍のスループット向上 バッチサイズ Transformers FP16
TensorRT FP16 ⾼速化率 1 45.3 samples/s 158.5 samples/s 3.50x 8 127.5 samples/s 163.3 samples/s 1.28x 16 132.0 samples/s 151.5 samples/s 1.15x 32 130.5 samples/s 145.5 samples/s 1.11x
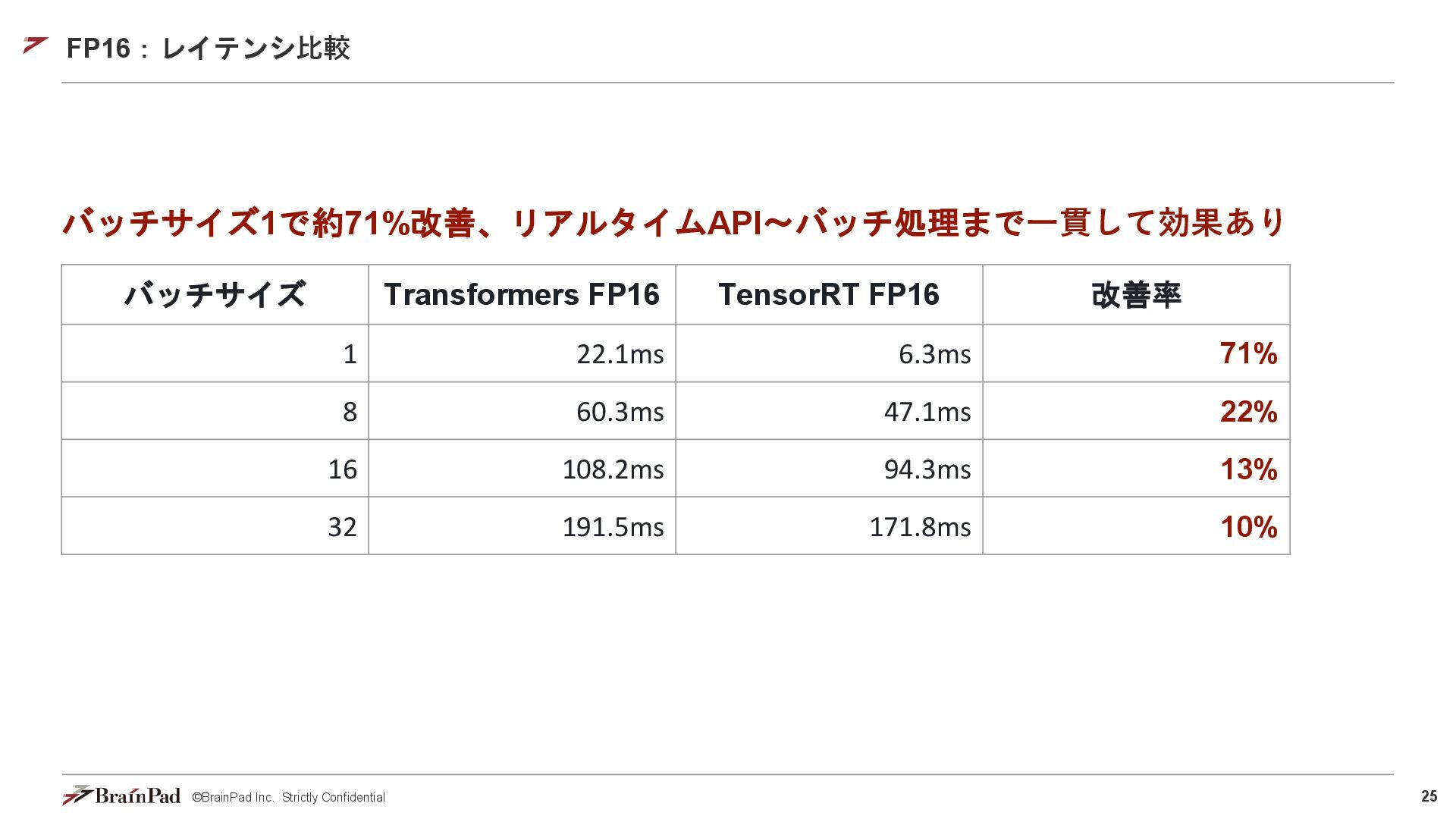
25 ©BrainPad Inc. Strictly Confidential FP16:レイテンシ⽐較 バッチサイズ1で約71%改善、リアルタイムAPI〜バッチ処理まで⼀貫して効果あり バッチサイズ Transformers FP16
TensorRT FP16 改善率 1 22.1ms 6.3ms 71% 8 60.3ms 47.1ms 22% 16 108.2ms 94.3ms 13% 32 191.5ms 171.8ms 10%
26 ©BrainPad Inc. Strictly Confidential 今回のベンチマークから⾒えたこと 1. TensorRTで全体的に推論速度が向上 すべてのバッチサイズでTransformersより⾼速 2.
FP32よりFP16の⽅が⾼速化効果が⼤きい FP32:約1.1倍 FP16:1.1〜3.5倍 3. 特にFP16 + バッチサイズ1で効果⼤ スループット3.5倍、レイテンシ71%改善 リアルタイム⽤途で特に有 効 結果の分析
©BrainPad Inc. Strictly Confidential 5. まとめ・今後の展望
28 ©BrainPad Inc. Strictly Confidential 本発表のポイント 背景:MLサービス運⽤では「待ち時間・締め遅延・コスト」が課題 検証:ModernBERTをTensorRTで最適化、FP32/FP16でベンチマーク 結果:FP32で約1.1倍、FP16でバッチ1で3.5倍の⾼速化 結
論 TensorRTを⽤いることで、既存のTransformersベースの推論でも ⽐較的少ない変更でレイテンシとスループットを底上げできる まとめ
29 ©BrainPad Inc. Strictly Confidential 現実的な次のステップ パラメータチューニング TensorRTの最適化設定を探索し、より⾼速・安定な設定を探る INT8量⼦化 キャリブレーションを⾏い、さらなる⾼速化を図る
CI/CDへの統合 モデル更新時のFP16/INT8変換をパイプライン化し、本番反映を⾃動化 今後の展望
©BrainPad Inc. Strictly Confidential 質疑応答
31 ©BrainPad Inc. Strictly Confidential https://developer.nvidia.com/tensorrt https://huggingface.co/docs/optimum/ https://onnxruntime.ai/ 公式ドキュメント リソース
URL TensorRT Hugging Face Optimum ONNX Runtime 質問・フィードバックぜひお願いします! 参考資料・リンク
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}