Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DTD_AIエージェント開発プロジェクトのメソッドを体系化してみる
Search
BrainPad
January 29, 2026
Technology
380
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DTD_AIエージェント開発プロジェクトのメソッドを体系化してみる
BrainPad
January 29, 2026
More Decks by BrainPad
See All by BrainPad
白金鉱業Meetup_Vol.24_「AIエージェントは分けるほど良い」は本当か? / Is it true that “the more you divide AI agents, the better”?
brainpadpr
1
560
「ビジネス現場でのデータ分析者」 東京大学 GCI 2026 Summer
brainpadpr
2
2.4k
BrainPad_DE_202604
brainpadpr
1
14k
BrainPad AAA_AIエージェントの社会実装する上での壁 / Barriers to the Social Implementation of AI Agents
brainpadpr
1
280
白金鉱業Meetup_Vol.22_Orbital Senseを支える衛星画像のマルチモーダルエンベディングと地理空間のあいまい検索技術
brainpadpr
3
450
DTD_Databricksことはじめ
brainpadpr
0
320
【採用候補者向け】BrainPad AAAご紹介資料
brainpadpr
0
2.4k
DTD_はじめての因子分析_理論とビジネス活用.pdf
brainpadpr
2
2.6k
DTD_TensorRTを用いた自然言語処理モデルの高速化
brainpadpr
0
150
Other Decks in Technology
See All in Technology
文字起こし基盤の信頼性
abnoumaru
0
150
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
330
現場で使える AWS DevOps Agent 活用ノウハウ - Release Management 機能の検証結果を添えて / AWS DevOps Agent Release Management and Know-How
kinunori
3
250
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
6
540
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
200
iOS/Androidの二刀流エンジニアがFlutter & TypeScriptへ越境後の現在地 - Flutterがメインになって見えた景色と現在の醍醐味 / Dual-Platform Mobile Engineer Shifts to Flutter & TypeScript - The View and Real Thrill of Going Flutter-First
bitkey
PRO
0
110
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
490
reFACToring
moznion
1
730
Power Automateアップデート情報
miyakemito
0
260
Git 研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
660
QAと開発の両側から進める AI活用 -QAプロセスAI支援ツールキットと Inner Loop / Outer Loopの取り組み-
legalontechnologies
PRO
2
150
Git 研修【MIXI 26新卒技術研修】#2
mixi_engineers
PRO
1
360
Featured
See All Featured
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
190
Building a Scalable Design System with Sketch
lauravandoore
463
34k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
The Mindset for Success: Future Career Progression
greggifford
PRO
0
430
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
270
What's in a price? How to price your products and services
michaelherold
247
13k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Faster Mobile Websites
deanohume
310
32k
Transcript
DEU TECH DRIVE AIエージェント開発プロジェクトのメソッドを体系化してみた 2026年 1月29日
2 ©BrainPad Inc. Strictly Confidential 自己紹介 井出 大介 IDE DAISUKE
データエンジニアリングユニット ML/アプリケーション開発 機械学習エンジニア 所属 【経歴】 • 2017 株式会社ブレインパッド入社 データサイエンティスト • 2021 株式会社ブレインパッド 機械学習エンジニア 【生成AIプロジェクト経験】 • 社内問い合わせシステムの開発 • 特許収集・要約システムの開発 • 動画の広告ガイドラインチェック・クリエイティブ評価 • 研究支援エージェントの開発 • マーケティングレポート作成エージェントの開発 • など 【プロジェクト外の活動】 • ブログ執筆 • CNNによる楽曲分類 • Transformerによる時系列データ予測 • コンペティション参加 • 日本たばこ産業 たばこ商品の画像検出 3位入賞 • Kaggle Expert
©BrainPad Inc. Strictly Confidential 3 1.AIエージェント開発プロセスの全体像 2.検証フェーズにおける選択肢・使い分けの基準 3.AIエージェントの『定着化』を実現するための重要ポイント 4.ユースケースごとのノーコードvsフルコード 5.まとめ
アジェンダ
4 ©BrainPad Inc. Strictly Confidential 1. AIエージェント開発プロセスの全体像 本資料では、検証(PoC)から本番化に至る各ステップで押さえるべき重要ポイントを整理する。 企画・ ユースケース
定義 ツール・ データ準 備 エージェ ント 設計 プロトタ イプ 開発 評価・ チューニ ング アプリ開 発 運用・保 守 AIエージェント開発プロジェクト 検証フェーズ(PoC) • ツール・データ準備: ✔ ツール・データ: Vector DB, Web検索, MCP/API ✔ チャンキング・検索手法 • エージェント設計: ✔ シングルエージェント, マルチエージェント, Agentic workflow ✔ システムプロンプトの構成 • プロトタイプ開発: ✔ クラウド:Google Cloud, AWS, Azure ✔ 開発方法:ノーコード, ローコード, フルコード • 評価・チューニング: ✔ LLM as a Judge, Feedback loop 本番化フェーズ • アプリ開発: ✔ UI/UX ✔ データ・セキュリティ整備 • 運用・保守: ✔ Human in the loop ✔ モニタリング ✔ Feedback loop ✔ モデルバージョン管理
5 ©BrainPad Inc. Strictly Confidential 2. 検証フェーズにおける選択肢・使い分けの基準|ツール・データ準備 AIエージェントのコンテキスト(判断材料)となる情報源・アクションの選択肢です。 選択肢 特徴・役割
使い分けの基準 (When to use) システムプロンプト エージェントが常に保持し続ける、最も優先 度の高い指示セット 「絶対に守らせたい、検索不要の重要情報」 の場合。 エージェントの性格(ペルソナ)、禁止事項 (ガードレール)、検索させずに即答すべき 中核的な業務知識など。 Vector DB 意味検索(Semantic Search)を用いた社内 ナレッジの長期記憶・検索 「答えが既存の文書内にある」場合。 マニュアル、FAQ、規定、過去ログなどの 参照が必要なとき。 Web検索 最新情報や外部情報の取得 「学習データに含まれない最新情報」が必要 な場合。 ニュース、天気、現在の株価など。 API / MCP 外部システムへの操作、計算、データ取得 「アクション(行動)」が必要な場合。 予約システムへの登録、DBの最新値取得、 複雑な計算など。
6 ©BrainPad Inc. Strictly Confidential 2. 検証フェーズにおける選択肢・使い分けの基準|ツール・データ準備|非構造データのチャンキング テキストデータをLLMが処理しやすい「チャンキング:小さな意味のまとまり」に分割するアプローチ。 チャンキング 特徴
メリット / デメリット 使い分けの基準 (When to use) 固定長 文字数やトークン数で機械的に分割す る。 (例: 500文字ごとにカット) 処理が非常に高速で、実装が容易。 APIコストも最小限。 文脈が途中で途切れるリスクが高い。 PoC、単純な検証 とりあえずRAGを動かしたい場 合や、文脈の維持が重要でない 単純なデータ。 階層的 文書の構造(章・節・段落)や区切り 文字で分割する。 (親チャンク・子チャンクの連携含む) 「見出し」等の構造を保持できる。 元データの構造(Markdown等)が整 っている必要がある。 マニュアル、技術文書 見出しや章立てが明確な文書。 「文脈」と「検索ヒット率」を 両立させたい標準的なケース。 セマンティック 文章の「意味(ベクトル)」の変化点 を計算して分割する。 (話題が変わった瞬間に切る) 一つのチャンク内に同じトピックがま とまるため、検索時のノイズが減る。 処理が重くコストがかかる。閾値調整 が難しい。 議事録、論文、エッセイ 見出し等の構造が少なく、トピ ックが流動的に変化する長文テ キスト。 Agentic LLM(エージェント)が内容を読み、 「ここで区切るべき」と論理的に判断 する。 複雑な文脈や論理構造を人間と同レベ ルで理解し、最適な位置で分割できる。 LLMの呼び出し回数が膨大になるため、 大量データには向かない。 契約書、法務・医療文書 (※構築コスト高) コスト度外視で「正確性」が最 優先される、複雑かつクリティ カルな文書。
7 ©BrainPad Inc. Strictly Confidential 2. 検証フェーズにおける選択肢・使い分けの基準|ツール・データ準備|検索手法 ユーザープロンプトを入力としてチャンキングされたデータを検索し、LLMに受け渡すまでのアプローチ。 フェーズ 手法
特徴・役割 使い分けの基準 (When to use) 前処理 クエリ拡張 ユーザーの質問をそのまま検索せず、LLM を使って「検索しやすいキーワード」に変 換したり、「類似質問」を複数生成してか ら検索する。 ユーザーの質問が短い・曖昧 チャットボットなど、ユーザーが適切な検 索ワードを入力してくれるとは限らない場 合。 インデックス ・検索 ハイブリッド検索 (キーワード+ベクトル) 「キーワード検索(完全一致)」と「ベク トル検索(意味)」の結果を統合して返す。 基本 一般的なQ&A、マニュアル検索など、あら ゆる用途のベースラインとして最適。 インデックス ・検索 メタデータ検索 事前にメタデータ(属性)を付与し、範囲 を絞ってから検索する。 属性が明確なデータ 社内規定(部署別)、製品マニュアル(機 種別)、契約書(企業別)など、範囲指定 が可能な場合。 インデックス ・検索 GraphRAG 事前に文書内のエンティティ(人、物、事 象)の関係性をナレッジグラフ(ノードと エッジ)化し、つながりを辿って検索する。 高度な分析・調査(※構築コスト高) 「全体要約」が必要な場合や、医療・金 融・犯罪捜査など、複雑な因果関係を紐解 く必要がある場合。 後処理 リランキング 検索で多め(例:50件)に取った結果を、高 精度なAIモデルで精密に並び替えて上位 (例:5件)を渡す。 精度最優先のケース 検索結果にノイズが多く、LLMが誤回答 (ハルシネーション)を起こす場合。
8 ©BrainPad Inc. Strictly Confidential 2. 検証フェーズにおける選択肢・使い分けの基準|エージェント設計 タスクの「複雑性」と求められる「専門性」の度合いがシングルかマルチかの分岐点となる。 選択肢 特徴・仕組み
使い分けの基準 (When to use) Single Agent (シングルエージェント) 「汎用的な自律解決」 1つのLLMがツール(検索、計算機など)を 持ち、自分で計画を立ててゴールを目指す。 役割が明確。 「手順は不明だが、ゴールは明確なタス ク」の場合。 ・「〇〇について調べて」のような探索的 タスク。 ・使用するツールが少なく(3〜5個程度)、 コンテキスト(文脈)が複雑すぎないとき。 Multi Agent (マルチエージェント) 「専門家チームによる分業」 役割の異なる複数のエージェント(計画役、 実行役、監査役など)が協調して動く。 お互いに会話・レビューしながら精度を高 める。 「1人の能力では抱えきれない複雑なタス ク」の場合。 ・「コードを書いて、テストして、修正す る」といった複合プロセス。 ・異なる視点(作成者 vs 批判者)での品質 担保が必要なとき。 マルチエージェントにも複数のパターンがあり、問題に最適なパターンを判断する必要がある • Workflow(ワークフロー / 階層型) • Swarm(スウォーム / 群衆型) • Graph(グラフ / ネットワーク型)
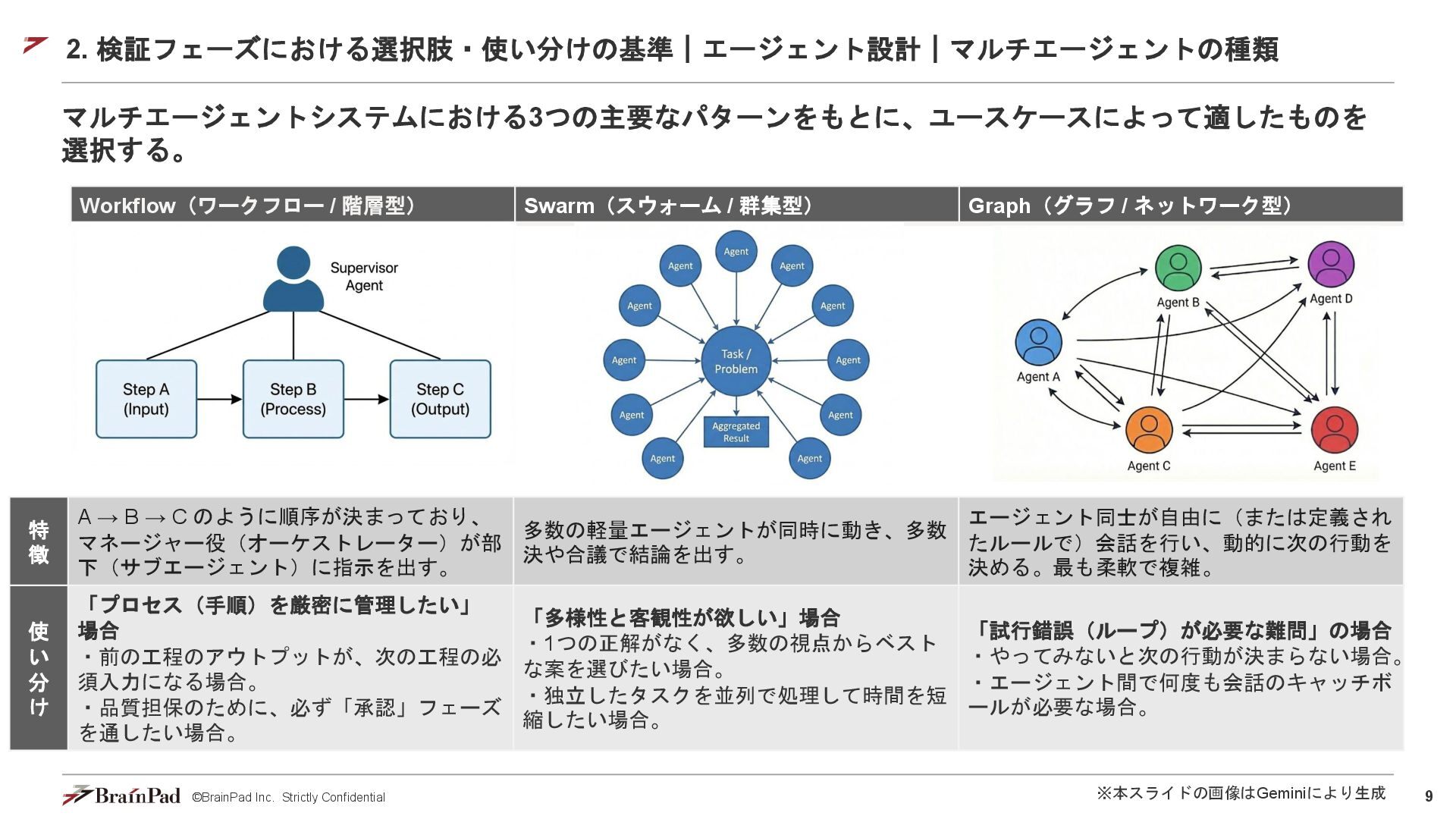
9 ©BrainPad Inc. Strictly Confidential 2. 検証フェーズにおける選択肢・使い分けの基準|エージェント設計|マルチエージェントの種類 マルチエージェントシステムにおける3つの主要なパターンをもとに、ユースケースによって適したものを 選択する。 Workflow(ワークフロー
/ 階層型) Swarm(スウォーム / 群集型) Graph(グラフ / ネットワーク型) 特 徴 A → B → C のように順序が決まっており、 マネージャー役(オーケストレーター)が部 下(サブエージェント)に指示を出す。 多数の軽量エージェントが同時に動き、多数 決や合議で結論を出す。 エージェント同士が自由に(または定義され たルールで)会話を行い、動的に次の行動を 決める。最も柔軟で複雑。 使 い 分 け 「プロセス(手順)を厳密に管理したい」 場合 ・前の工程のアウトプットが、次の工程の必 須入力になる場合。 ・品質担保のために、必ず「承認」フェーズ を通したい場合。 「多様性と客観性が欲しい」場合 ・1つの正解がなく、多数の視点からベスト な案を選びたい場合。 ・独立したタスクを並列で処理して時間を短 縮したい場合。 「試行錯誤(ループ)が必要な難問」の場合 ・やってみないと次の行動が決まらない場合。 ・エージェント間で何度も会話のキャッチボ ールが必要な場合。 ※本スライドの画像はGeminiにより生成
10 ©BrainPad Inc. Strictly Confidential 2. 検証フェーズにおける選択肢・使い分けの基準|エージェント設計|システムプロンプト設計 プロンプト作成時は、人間への『文章』ではなく、AIへの『仕様書』として定義することを意識する。 セクション 役割
記述内容例(テンプレート) Role (役割定義) 人格と専門性のセット AIに「誰として振る舞うべきか」を定義し、 回答のトーンや視点を固定する。 あなたは熟練したPythonエンジニアです。 可読性が高く、保守しやすいコードを書くこ とに情熱を持っています。 Objective (目的・ゴール) ゴールの明確化 何をすればタスク完了となるのか、最終的な 成果物の定義を行う。 ユーザーの要件に基づき、最適な設計パター ンを用いたコードを生成し、その解説を行う ことです。 Constraints (制約・ルール) ガードレール(禁止事項) やってはいけないこと、守るべきフォーマッ ト、安全性の基準を列挙する。 - 外部ライブラリは標準的なものに限る - 説明は日本語で行う - 絶対に嘘のURLを生成しない Process (思考プロセス) Chain of Thought (思考連鎖) いきなり回答せず、手順を踏ませることで論 理的なミスを減らす。 1. まず要件を分析する 2. 必要なライブラリを選定する 3. コードを実装する 4. エッジケースを検証する ✔ 構造化(Structuring):「ダラダラ書かない」指示をベタ書きの文章にせず、#や<>を使ってセクション分けする。 ✔ 例示(Few-shot):「指示より例示」詳細を事細かに書くより、例を1つ見せる方が、ニュアンスが正確に伝わる。 ✔ 思考の明示(Chain of Thought):「Step-by-Stepで思考」いきなり答えを出して間違えるハルシネーションを抑制できる。 ✔ 否定命令(Negative Prompting):「禁止より代替案」やってはいけないだけでなく、代わりに何をすべきかを指示する。 システムプロンプト作成時の工夫ポイン ト:
11 ©BrainPad Inc. Strictly Confidential 2. 検証フェーズにおける選択肢・使い分けの基準|プロトタイプ開発 検証スピードや要件の複雑さに加え、クラウド環境との親和性を考慮して最適なツールを選定する。 開発手法 メリット
/ デメリット 使い分けの基準 (When to use) ノーコード (Gemini Enterprise, Amazon Q Business, MS Copilot Studio等) 爆速で構築可能、学習コスト低 複雑なループ処理や独自UIの実装に限界 あり 検証スピード最優先 / 非エンジニア主導 まずはアイデアを形にし、有用性を確認した い場合。 ローコード (Azure AI Foundry, Amazon Bedrock Flows, Vertex AI Agent Builder等) 視覚的にフロー管理可能、拡張性そこそ こ ツール固有の仕様に依存する 標準的なフロー構築 / チーム開発 ある程度のカスタマイズ性は欲しいが、1か らコードは書きたくない場合。 フルコード (Google ADK, Strands Agents, MS Agent Framework, LangGraph等) 完全な自由度、バージョン管理・テスト が容易 実装・保守工数が高い 本番運用前提 / 高度な制御が必要 独自のAgentic Loop実装、既存システムとの 深い統合、細かいチューニングが必要な場合。 • Agentic Loop:AIが思考と行動を反復し、 自律的にゴールを目指す循環プロセス
12 ©BrainPad Inc. Strictly Confidential 2. 検証フェーズにおける選択肢・使い分けの基準|評価・チューニング 定量評価で『スピード』を、定性評価で『信頼』を担保し、改善サイクルを回し続ける。 評価カテゴリ 評価手法・具体的な指標
選択使い分けの基準 (When to use) 定量評価 (正解あり) NLP指標 ・Exact Match (完全一致) ・ROUGE / BLEU (単語の重複) ・Embedding Similarity (ベクトル類似度) 「正解が決定的でかつ正解データ(Ground Truth)がある」場合 ・正解とAIの生成結果を比較することで正答率などを算出。 ・ハルシネーションの検知には不向きだが、修正時のリグレッション テスト(回帰試験)として活用。 定量評価 (正解なし) LLM-as-a-judge ・一貫性、流暢さ ・RAG:根拠付け、ドキュメント取得、関連性、完 全性 ・リスクと安全:差別的、暴力的、著作権、脆弱性 「正解基準が曖昧で正解データを用意できない」場合 ・クリエイティブな生成タスク(要約、アイディア創出など)向け。 ・人間の評価軸・基準を事前に定義した評価エージェントによってス コアリングを実施。 定性評価 (人間の感性) Human-in-the-loop ・専門家(ユーザー)によるレビュー ・複数エージェントのA/Bテスト ・ユーザーフィードバック (5段階スコアリング) 「最終的な品質保証または継続的なユーザーテストが可能」な場合 ・数値化できない「ユーザー体験」や「品質」の確認。 ・LLM自身のバイアスを防ぐため、リリース判断には必ず人の介在が 必要。 ✔ 正解データの合成(Synthetic Data)にも生成AIを活用する ✔ LLM-as-a-judgeの評価軸・基準をユーザーと一緒に検討し、定性評価時と揃える ✔ 開発段階からユーザーに定性評価をしてもらうことで、改善サイクルを繰り返す 評価・チューニングのポイント:
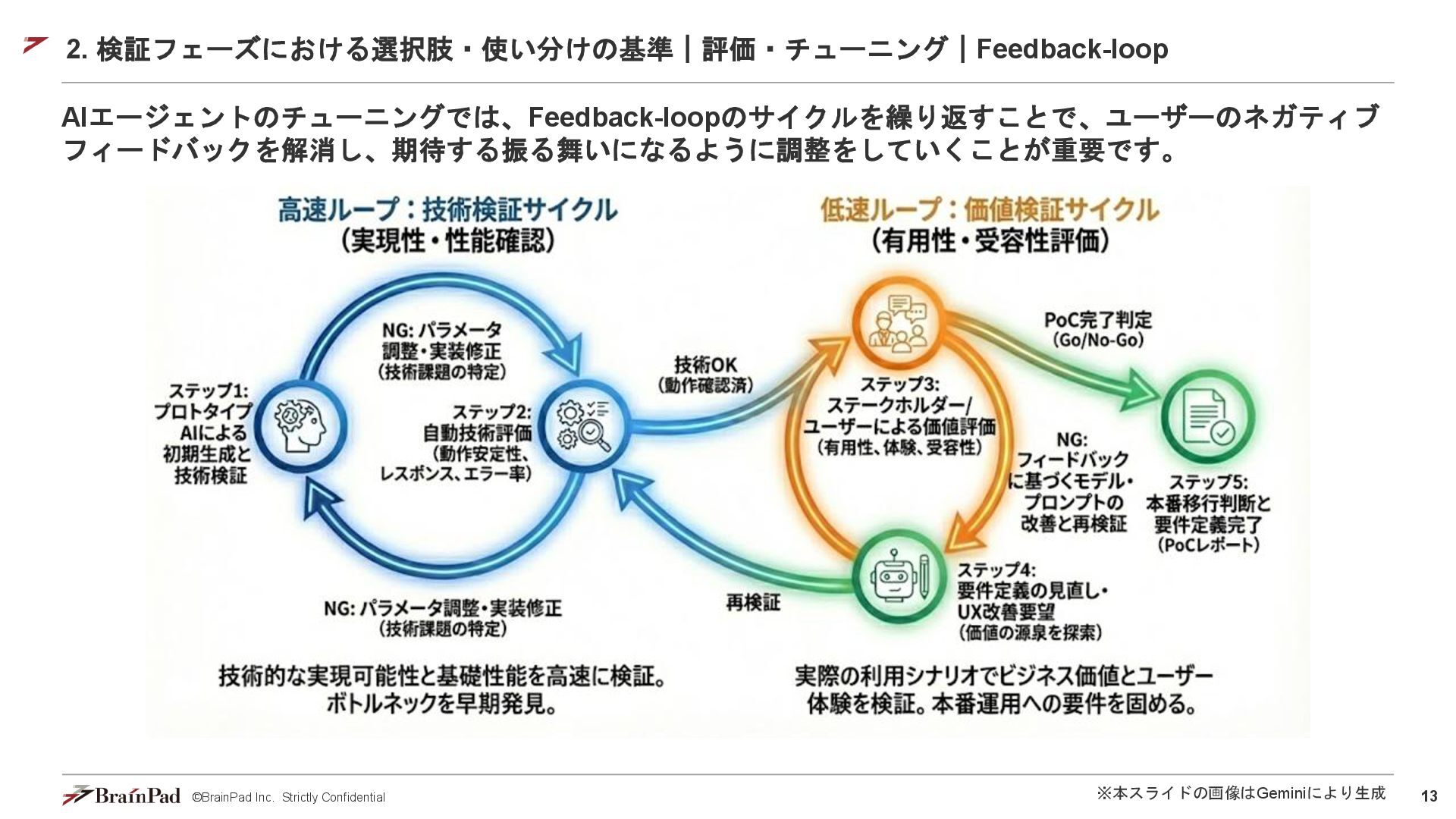
13 ©BrainPad Inc. Strictly Confidential 2. 検証フェーズにおける選択肢・使い分けの基準|評価・チューニング|Feedback-loop AIエージェントのチューニングでは、Feedback-loopのサイクルを繰り返すことで、ユーザーのネガティブ フィードバックを解消し、期待する振る舞いになるように調整をしていくことが重要です。 ※本スライドの画像はGeminiにより生成
14 ©BrainPad Inc. Strictly Confidential 3. AIエージェントの『定着化』を実現するための重要ポイント AIエージェントは作って終わりではなく、エラーを許容する設計と運用による継続的な賢さの向上がプロジ ェクト成功の鍵となる。 ▪
企画・ユースケース定義 「AIに“100点”を求めず、人が補完する前提でスコープを切る」 ✔ AIならなんでもできるは禁物 ✔ エラー許容性の設計 ✔ エンドユーザーを巻き込んだプロジェクト体制を組成 ▪ アプリ開発 「エージェントの性能だけでなく、“UX”がユーザー満足度を決める」 ✔ なぜその解答になったのかの根拠(引用元ドキュメント)を必ず提示 ✔ ユーザーを待たせないよう、回答のストリーミング表示や「処理中」ステータスの明示が必須 ✔ 「何が得意で何ができないか」を提示し、ユーザーの過度な期待を防ぐ ▪ 運用・保守 「ユーザーのフィードバックをもとに、継続的にエージェントを成長させる」 ✔ Feedback-loopの確立 ✔ Human-in-the-loop:AIに全てを任せるのではなく、最終的な意思決定は人間が行う ✔ KPI(利用数・精度)と定性評価のモニタリング
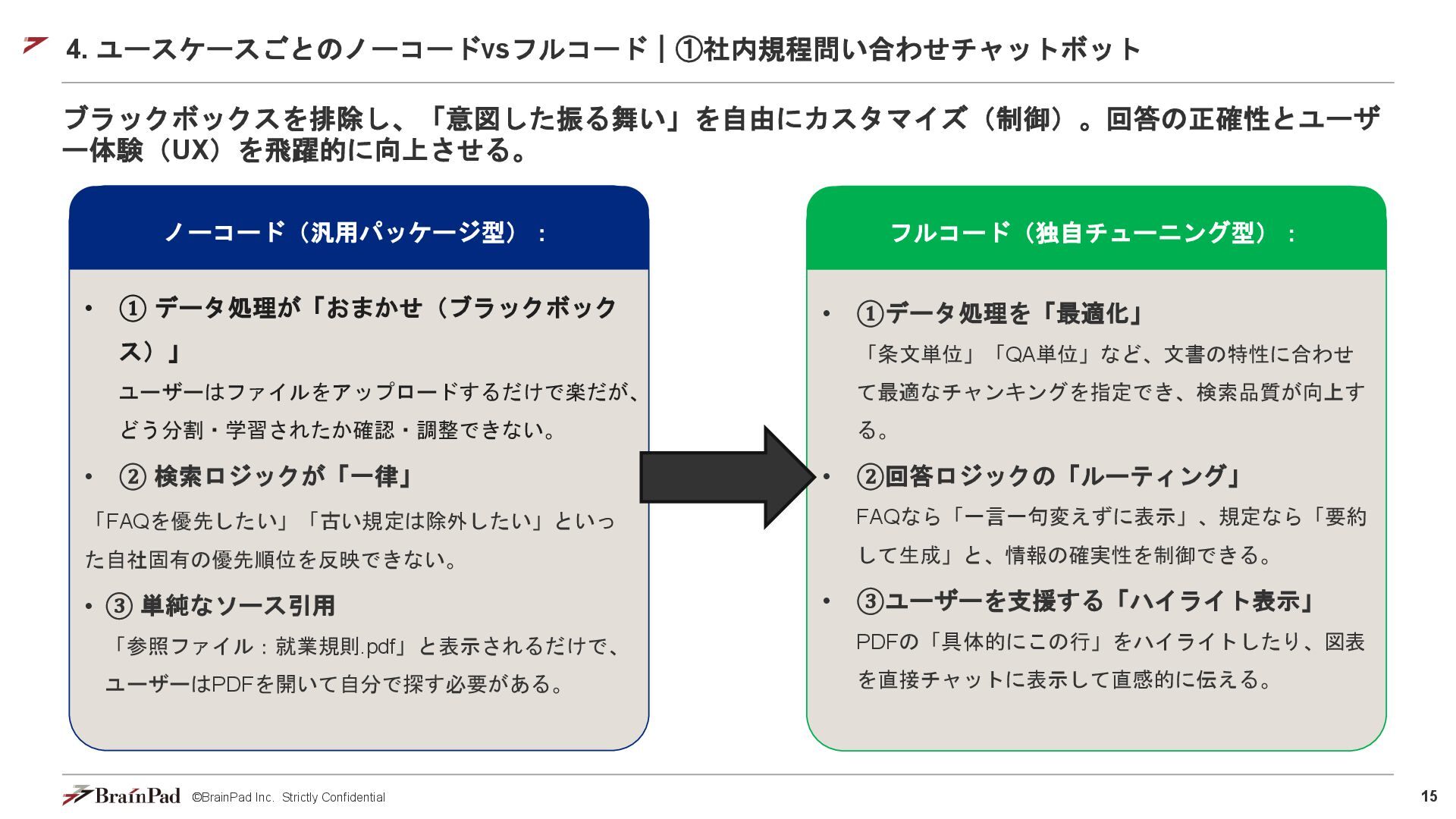
15 ©BrainPad Inc. Strictly Confidential 4. ユースケースごとのノーコードvsフルコード|①社内規程問い合わせチャットボット ブラックボックスを排除し、「意図した振る舞い」を自由にカスタマイズ(制御)。回答の正確性とユーザ ー体験(UX)を飛躍的に向上させる。 •
① データ処理が「おまかせ(ブラックボック ス)」 ユーザーはファイルをアップロードするだけで楽だが、 どう分割・学習されたか確認・調整できない。 • ② 検索ロジックが「一律」 「FAQを優先したい」「古い規定は除外したい」といっ た自社固有の優先順位を反映できない。 • ③ 単純なソース引用 「参照ファイル:就業規則.pdf」と表示されるだけで、 ユーザーはPDFを開いて自分で探す必要がある。 ノーコード(汎用パッケージ型): • ①データ処理を「最適化」 「条文単位」「QA単位」など、文書の特性に合わせ て最適なチャンキングを指定でき、検索品質が向上す る。 • ②回答ロジックの「ルーティング」 FAQなら「一言一句変えずに表示」、規定なら「要約 して生成」と、情報の確実性を制御できる。 • ③ユーザーを支援する「ハイライト表示」 PDFの「具体的にこの行」をハイライトしたり、図表 を直接チャットに表示して直感的に伝える。 フルコード(独自チューニング型):
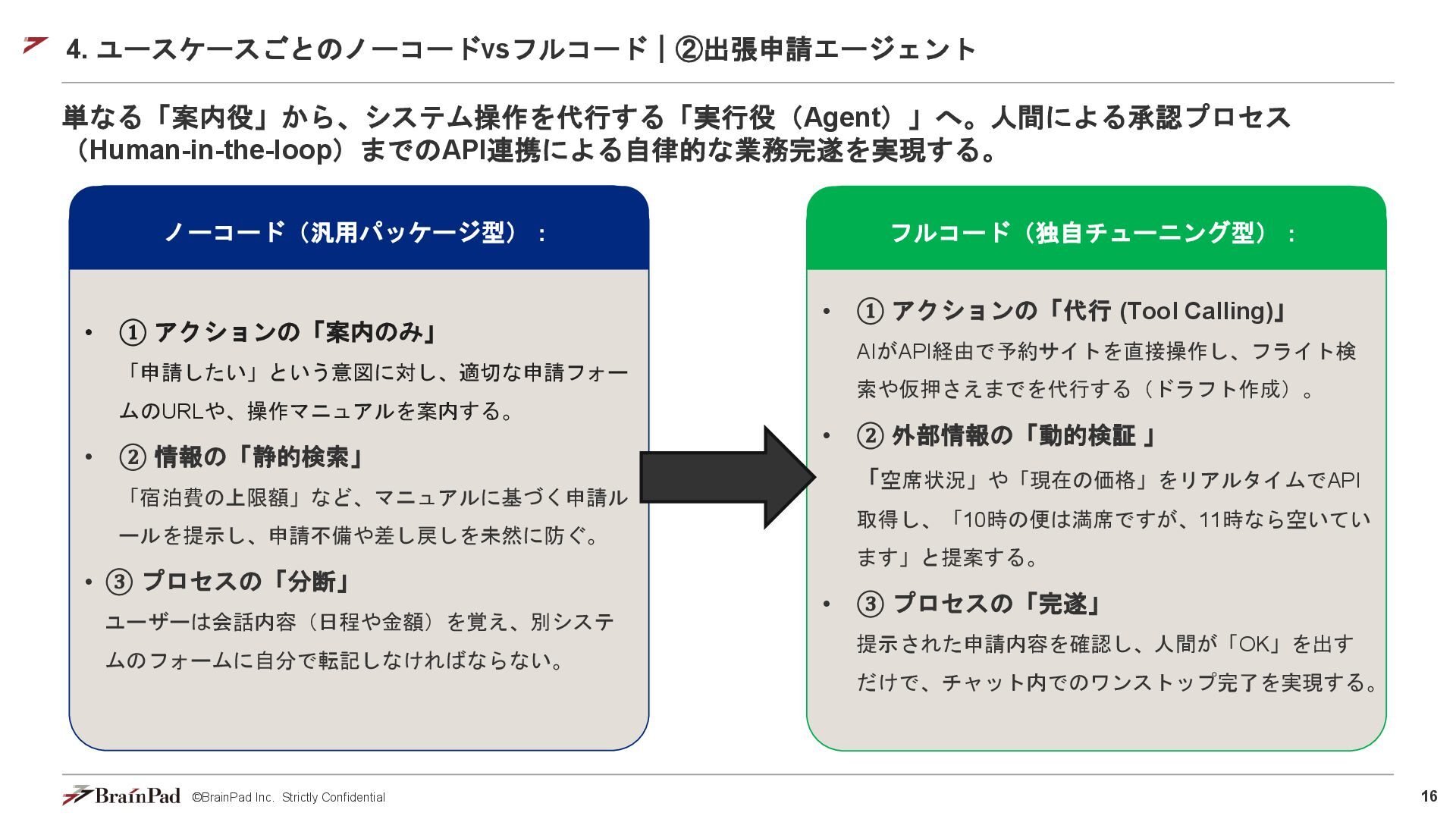
16 ©BrainPad Inc. Strictly Confidential 4. ユースケースごとのノーコードvsフルコード|②出張申請エージェント 単なる「案内役」から、システム操作を代行する「実行役(Agent)」へ。人間による承認プロセス (Human-in-the-loop)までのAPI連携による自律的な業務完遂を実現する。 •
① アクションの「案内のみ」 「申請したい」という意図に対し、適切な申請フォー ムのURLや、操作マニュアルを案内する。 • ② 情報の「静的検索」 「宿泊費の上限額」など、マニュアルに基づく申請ル ールを提示し、申請不備や差し戻しを未然に防ぐ。 • ③ プロセスの「分断」 ユーザーは会話内容(日程や金額)を覚え、別システ ムのフォームに自分で転記しなければならない。 ノーコード(汎用パッケージ型): • ① アクションの「代行 (Tool Calling)」 AIがAPI経由で予約サイトを直接操作し、フライト検 索や仮押さえまでを代行する(ドラフト作成)。 • ② 外部情報の「動的検証 」 「空席状況」や「現在の価格」をリアルタイムでAPI 取得し、「10時の便は満席ですが、11時なら空いてい ます」と提案する。 • ③ プロセスの「完遂」 提示された申請内容を確認し、人間が「OK」を出す だけで、チャット内でのワンストップ完了を実現する。 フルコード(独自チューニング型):
17 ©BrainPad Inc. Strictly Confidential 5. まとめ 「作る」から「育てる」へ。技術と人の協調プロセスこそが、AIエージェントを社会実装する鍵となる。 1. 最適な「道具」を選び、
検証速度を最大化する 2. 定量評価で「スピード」を、 定性評価で「信頼」を両立する 3. ユーザーと共に 「賢くなる仕組み」を作る • 要件や開発スケジュールに応じて最適 な技術選定を進めていくことでプロジ ェクトの成功率を高める。 • すべての機能をフルスクラッチで作る 必要はない • 期待水準を達成するために段階的に 技術のレべルを高めていく。 • 正解のあるタスクは定量指標で効率的 にチェックし、デグレ(劣化)を防ぐ。 • 正解のない生成タスクは人間による 定性評価で品質を担保する。 • 定量評価と定性評価で 改善サイクルを繰り返していく。 • リリースはゴールではなくスタート。 • ユーザーのフィードバックを収集し、 プロンプトやデータに還元する改善サ イクルを回し続けることで、エージェ ントは真の価値を発揮する。 確実な成功事例を積み重ね、 AIエージェントの社会実装を推進してきましょう。
株式会社ブレインパッド 106-0032 東京都港区六本木三丁目1番1号 六本木ティーキューブ TEL:03-6721-7002 FAX:03-6721-7010 www.brainpad.co.jp
[email protected]
本資料は、未刊行文書として日本及び各国の著作権法に基づき保護されております。本資料には、株式会社ブレインパッド所有の特定情報が含まれており、これら情報に基づく本資料の内容は、貴社以外の第三者に開示されること、また、本資料を評価する以外の目的で、その 一部または全文を複製、使用、公開することは、禁止されています。また、株式会社ブレインパッドによる書面での許可なく、それら情報の一部または全文を使用または公開することは、いかなる場合も禁じられております。
©BrainPad Inc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![株式会社ブレインパッド 106-0032 東京都港区六本木三丁目1番1号 六本木ティーキューブ TEL:03-6721-7002 FAX:03-6721-7010 www.brainpad.co.jp [email protected] 本資料は、未刊行文書として日本及び各国の著作権法に基づき保護されております。本資料には、株式会社ブレインパッド所有の特定情報が含まれており、これら情報に基づく本資料の内容は、貴社以外の第三者に開示されること、また、本資料を評価する以外の目的で、その 一部または全文を複製、使用、公開することは、禁止されています。また、株式会社ブレインパッドによる書面での許可なく、それら情報の一部または全文を使用または公開することは、いかなる場合も禁じられております。](https://files.speakerdeck.com/presentations/5941d3d1c2ef4325a87cbb2c88beb849/slide_17.jpg){kind=link}