peak • 500 million unique monthly visitors • 230 million requests to Python in one day Slighty dated traffic information, higher now. Except the 230MM number I just pulled from logs: doesn’t include cached varnish hits, media, etc. Growing rapidly, when I joined I thought it was “big”... hahaha.
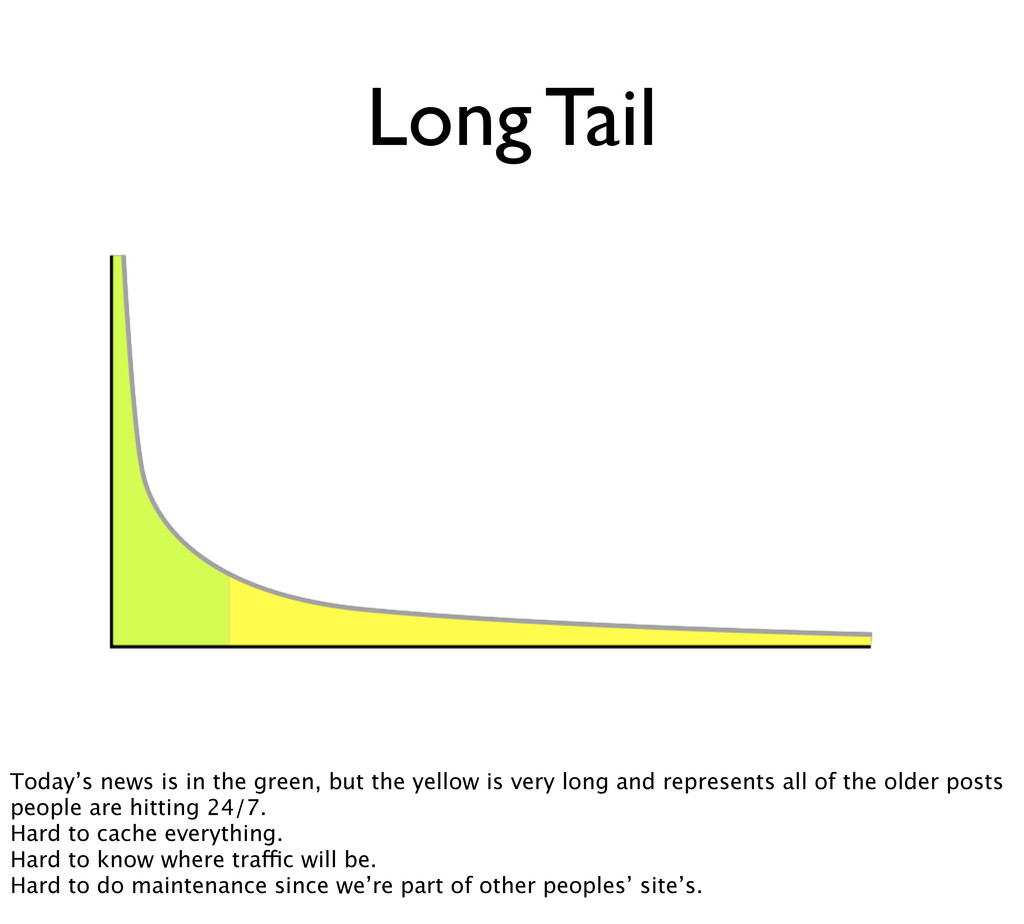
yellow is very long and represents all of the older posts people are hitting 24/7. Hard to cache everything. Hard to know where traffic will be. Hard to do maintenance since we’re part of other peoples’ site’s.
Redis • Solr • Nginx • Haproxy • Varnish • RabbitMQ • ... and more A little over 100 total servers; not Google/FB scale, but big. Don’t need our own datacenter. Still one of the largest pure Python apps, afaik. Not going deep on non-python/app stuff, happy to elaborate now/later.
pet project. If you do anything else you’re reinventing wheels. It’s not that hard. Your code 6 months later may as well be someone else’s, same holds true for sysadmin work. But ... not really the subject of this talk.
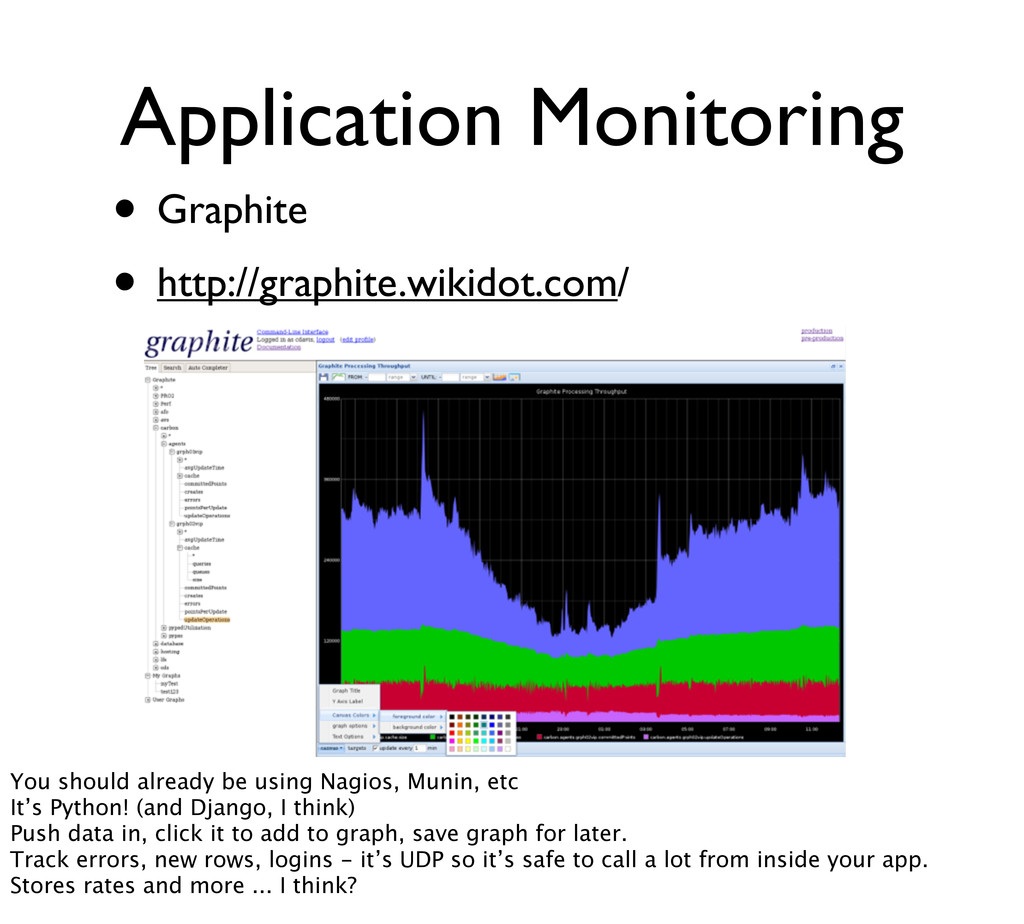
using Nagios, Munin, etc It’s Python! (and Django, I think) Push data in, click it to add to graph, save graph for later. Track errors, new rows, logins - it’s UDP so it’s safe to call a lot from inside your app. Stores rates and more ... I think?
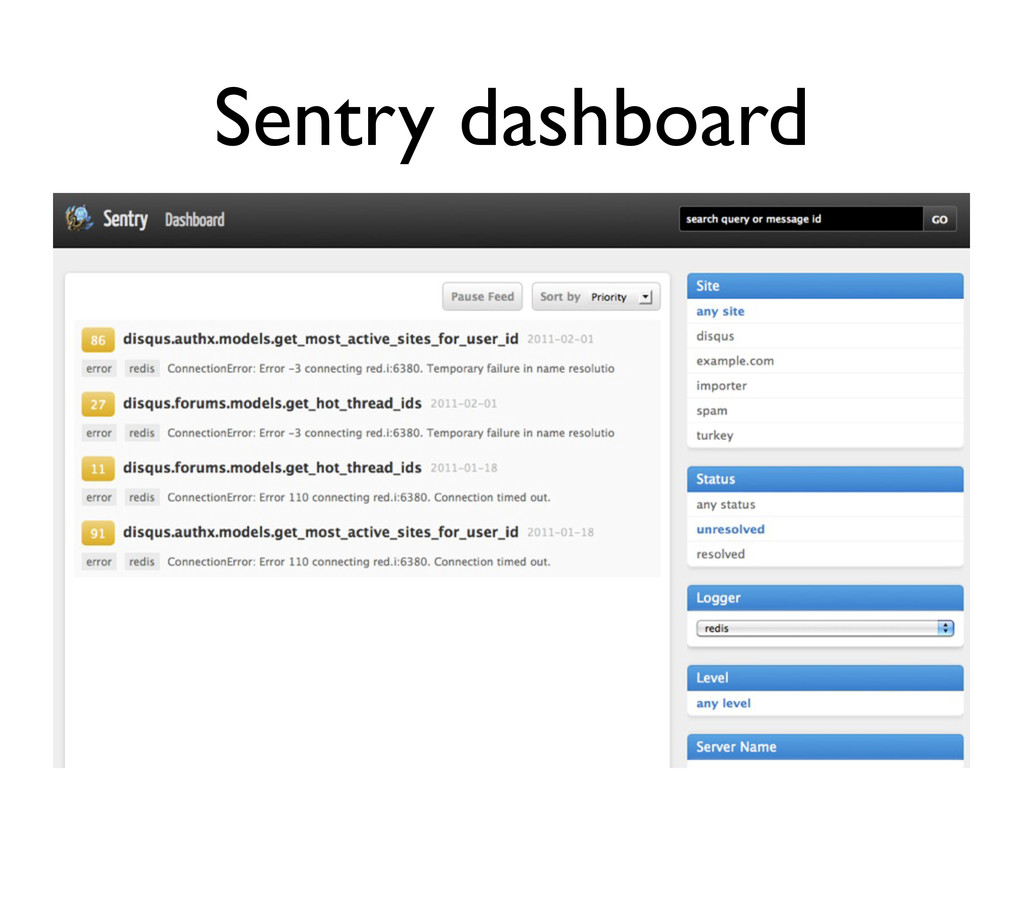
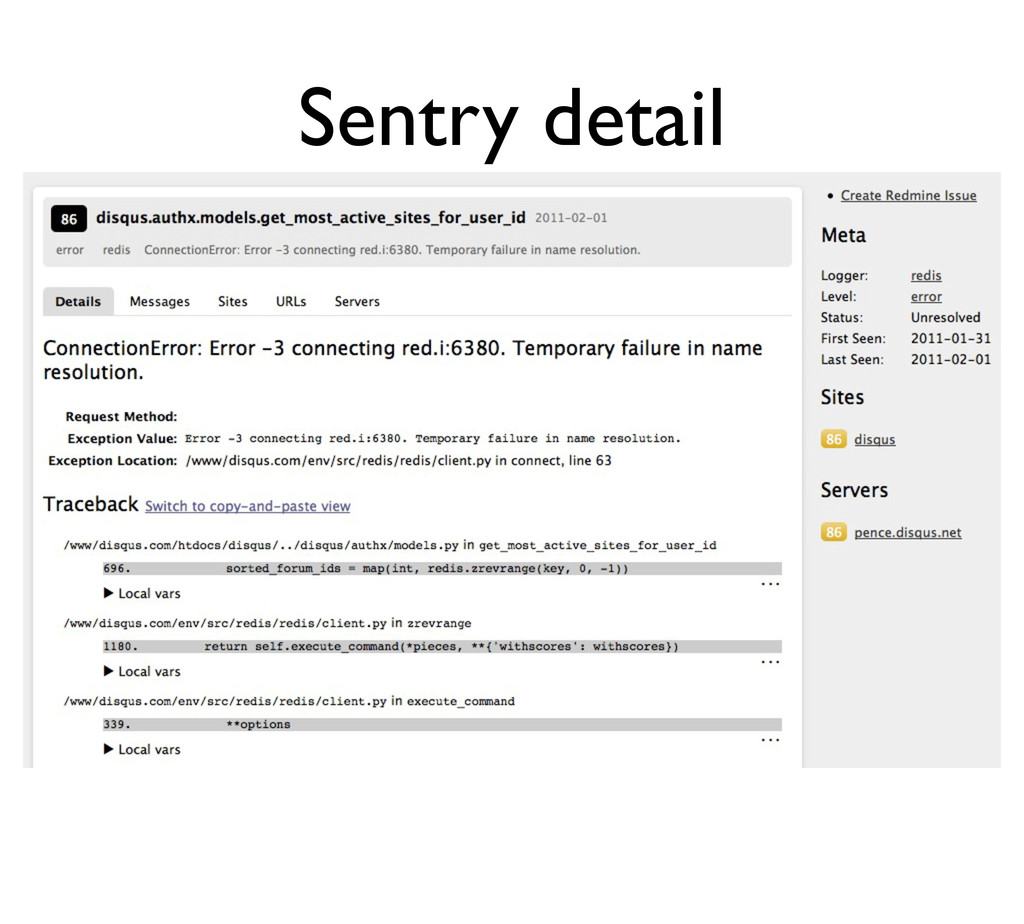
• ... group by issue • ... store more than exceptions • ... mark things fixed • ... store more detailed output • ... tie unique ID of a 500 to an exception We were regularly locked out of Gmail when we used exception emails.
logging.getLogger() logger.addHandler(SentryHandler()) # usage logging.error('There was some crazy error', exc_info=sys.exc_info(), extra={ # Optionally pass a request and we'll grab any information we can 'request': request, # Otherwise you can pass additional arguments to specify request info 'view': 'my.view.name', 'url': request.build_absolute_url(), 'data': { # You may specify any values here and Sentry will log and output them 'username': request.user.username } }) Try generating and sending unique IDs, send them out with your 500 so you can search for them later (from user support requests, etc).
processing • Denormalization • Sending email • Updating avatars • Running large imports/exports/deletes Everyone can use this, it helps with scale but is useful for even the smallest apps.
AMQP (and more) @task def check_spam(post): if slow_api.check_spam(post): post.update(spam=True) # usage post = Post.objects.all()[0] check_spam.delay(post) Tried inventing our own queues and failed, don’t do it. Currently have over 40 queues. We have a Task subclass to help with testing (enable only tasks you want to run). Also good for throttling.
APIs • Run hundreds/thousands of requests simultaneously • Save yourself gigs of RAM, maybe a machine or two Can be a bit painful... shoving functionality into Python that nobody expected. We have hacks to use the Django ORM, ask if you need help. Beware “threading” issues pop up with greenthreads, too.
# in models.py post_save.connect(delayed.post_save_sender, sender=Post, weak=False) # elsewhere def check_spam(sender, data, created, **kwargs): post = Post.objects.get(pk=data['id']) if slow_api.check_spam(post): post.update(spam=True) delayed.post_save_receivers['spam'].connect(check_spam, sender=Post) # usage post = Post.objects.create(message="v1agr4!") Not really for ‘scale’, more dev ease of use. We don’t serialize the object (hence the query). Not open sourced currently, easy to recreate. Questionable use ... it’s pretty easy to just task.delay() inside a normal post_save handler.
• ... in realtime • ... as a non-developer Things that don’t deserve their own table. Hard to think of an example right now (but we built something more useful ontop of this... you’ll see).
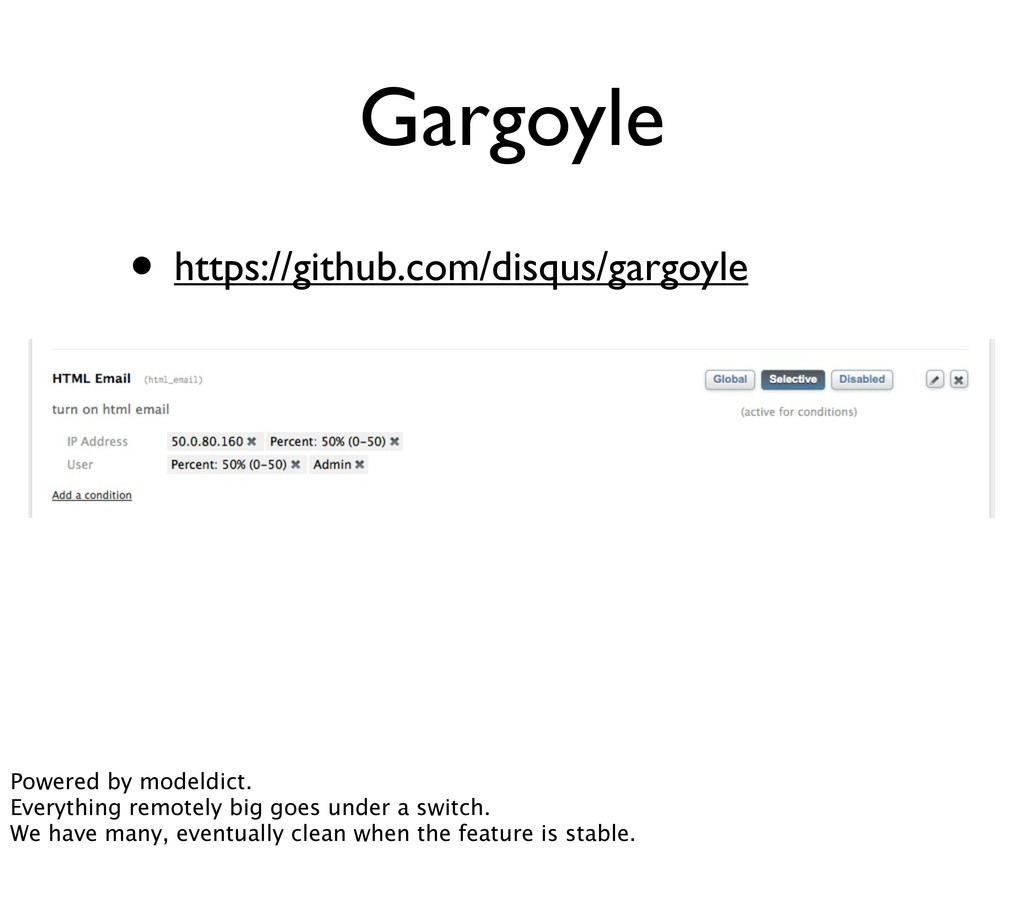
= ModelDict(Setting, key='key', value='value', instances=False) # access missing value settings['foo'] >>> KeyError # set the value settings['foo'] = 'hello' # fetch the current value using either method Setting.objects.get(key='foo').value >>> 'hello' settings['foo'] >>> 'hello' https://github.com/disqus/django-modeldict Backed by the DB. Cached, invalidated on change, fetched once per request.
launch risky features • Release big changes slowly • Free and easy beta testing • Change all of this live without knowing how to code (and thus without needing to deploy) No DB Magic, your stuff needs to be backwards compatible on the data layer.
switch name', request): return 'foo' else: return 'bar' Also usable as a decorator, check out the docs. You can extend it for other models like .is_active(‘foo’, forum). Super handy but still overhead to support both versions, not free.
cache.delete("page:home") return HttpResponse("yay") def homepage(request): page = cache.get("page:home") if not page: page = Page.objects.get(name='home') cache.set("page:home", page) return HttpResponse(page.body) Caching problem in update_homepage? See any problems related to caching in “update_homepage”? If not, imagine the homepage is being hit 1000/sec, still?
... • ... races • ... stampedes Previous slide: Race: Another request in transaction stores the old copy when it gets a cache miss. Stampede: 900 users start a DB query to fill the empty cache. Setting > Deleting fixes both of these. This happened to us a lot when we went from “pretty busy” to “constantly under high load”. Can still happen (more rarely) on small sites. Confuses users, gets you support tickets.
dict after request finishes cache.get("moderators:cnn", keep=True) Useful when something that hits cache may be called multiple times in different parts of the codebase. Yes, you can solve this in lots of other ways, I just feel like “keep” should be on by default. No released project, pretty easy to implement. Surprised I haven’t seen this elsewhere? Does anyone else do this?
few) clients will refresh cache, instead of a ton of them • django-newcache does this One guy gets an early miss, causing him to update the cache. Alternative is: item falls out of cache, stampede of users all go to update it at once. Check out newcache for code.
to go through here • Not comprehensive • All for 1.2, I have a (Disqus) branch where they’re ported to 1.3 ... can release if anyone cares Maybe worth glancing through. Just wanted to point this out. Some of these MAY be needed for edge cases inside of our own open sources Django projects... we should really check. :)
• But none of this is specific to Postgres • Joins are great, don’t shard until you have to • Use an external connection pooler • Beware NoSQL promises but embrace the shit out of it External connection poolers have other advantages like sharing/re-using autocommit connections. Ad-hoc queries, relations and joins help you build most features faster, period. Also come to the Austin NoSQL meetup.
code can be weird, check out our patches or ask me later • Remember: as soon as you use a read slave you’ve entered the world of eventual consistency No general solution to consistency problem, app specific. Huge annoyance/issue for us. Beware, here there be dragons.
.save() flushes the entire row • Someone else only changes ColA, you only change ColB ... if you .save() you revert his change We send signals on update (lots of denormalization happens via signals), you may want to do this also. (in 1.3? a ticket? dunno)
)) # Add awesome_flag Foo.objects.filter(pk=o.pk).update(flags=F('flags') | Foo.flags.awesome_flag) # Find by awesome_flag Foo.objects.filter(flags=Foo.flags.awesome_flag) # Test awesome_flag if o.flags.awesome_flag: print "Happy times!" Uses a single BigInt field for 64 booleans. Put one on your model from the start and you probably won’t need to add booleans ever again.
use TransactionMiddleware unless you can prove that you need it • Scalability pits that are hard to dig out of Middleware was sexy as hell when I first saw it, now sworn mortal enemy. Hurts connection pooling, hurts the master DB, most apps just don’t need it.
used and moved off of Mongo, Membase • I’m a Riak fanboy We mostly use Redis for denormalization, counters, things that aren’t 100% critical and can be re-filled on data loss. Has helped a ton with write load on Postgres.
'nydus.db.backends.redis.Redis', 'router': 'nydus.db.routers.redis.PartitionRouter', 'hosts': { 0: {'db': 0}, 1: {'db': 1}, 2: {'db': 2}, } }) res = conn.incr('foo') assert res == 1 It’s like django.db.connections for NoSQL. Notice that you never told conn which Redis host to use, the Router decided that for you based on key. Doesn’t do magic like rebalancing if you add a node (don’t do that), just a cleaner API.
pretty easy • Need a good key to shard on, very app specific • Lose full-table queries, aggregates, joins • If you actually need it let’s talk Fun to talk about but not general or applicable to 99%.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}