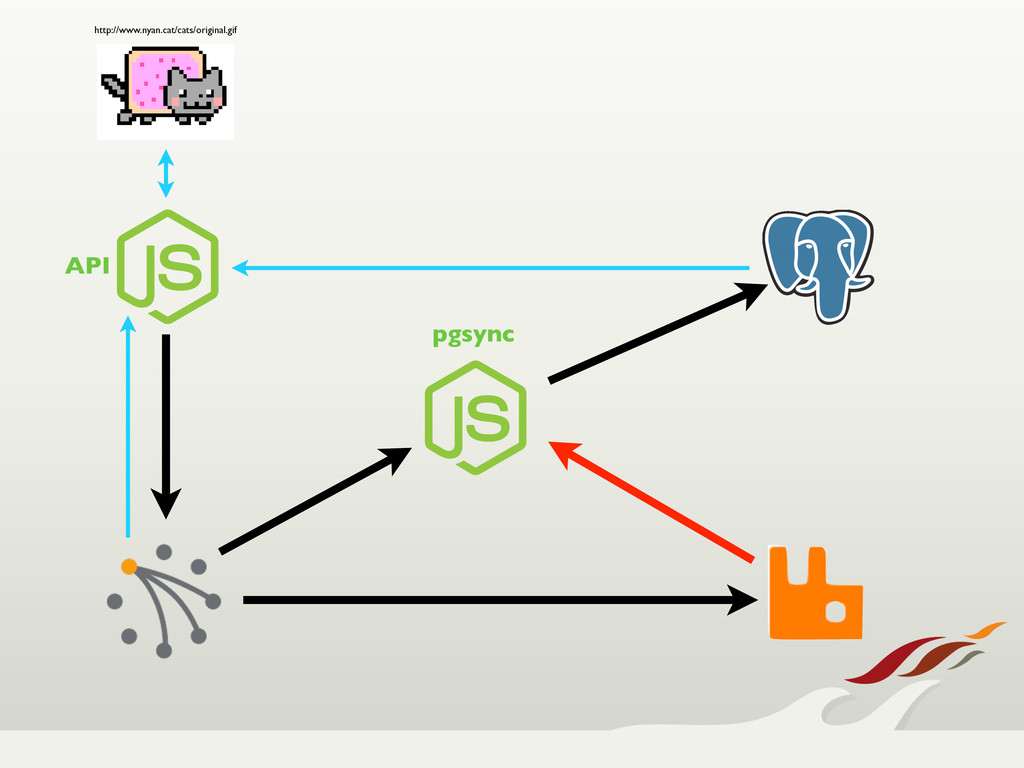
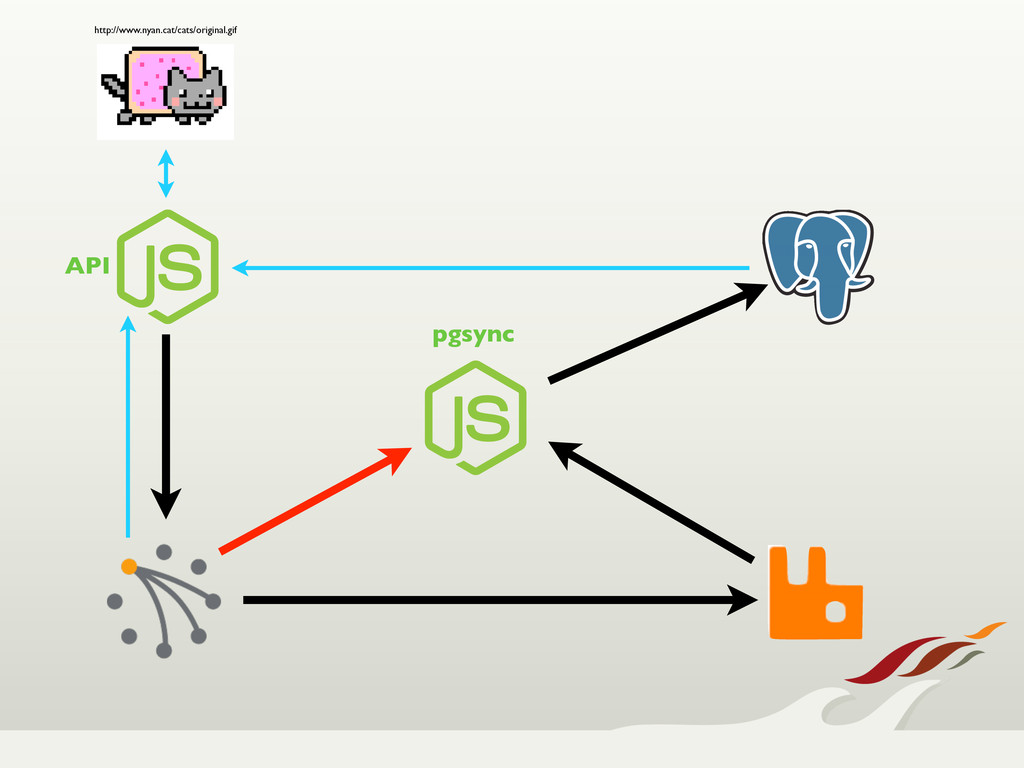
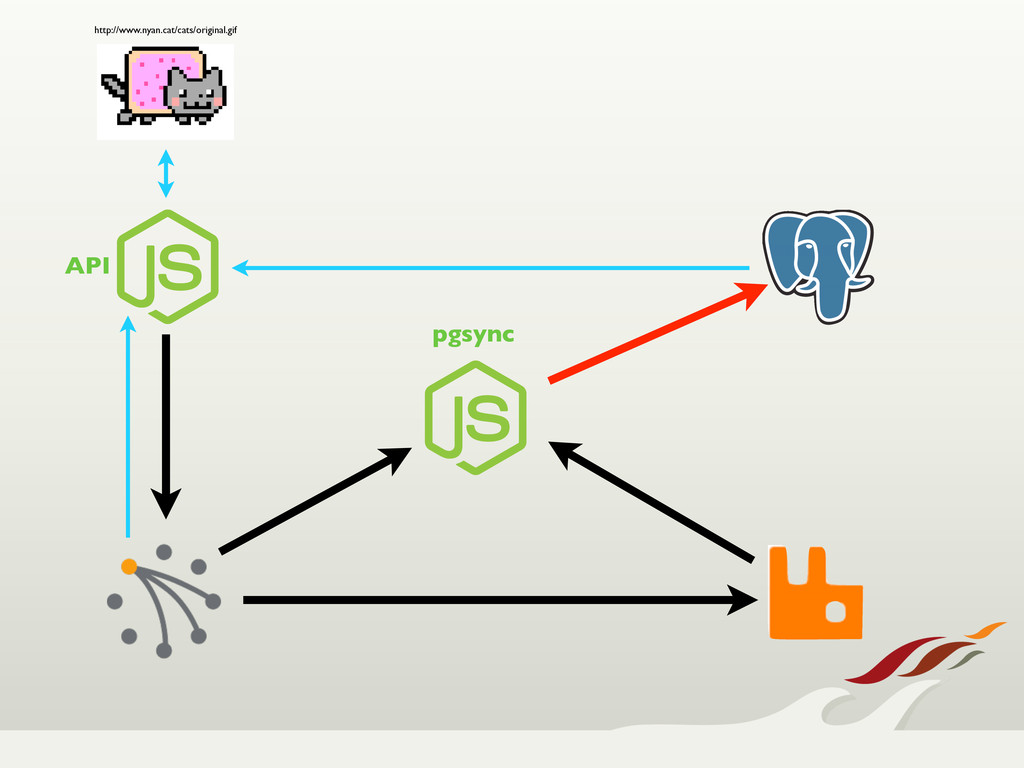
Recently we were tasked with building the core API and user service for a high-traffic mobile product. As part of the project, we were given two main priorities to focus on; that we could never have downtime, and that we couldn't lose data. With those constraints, we
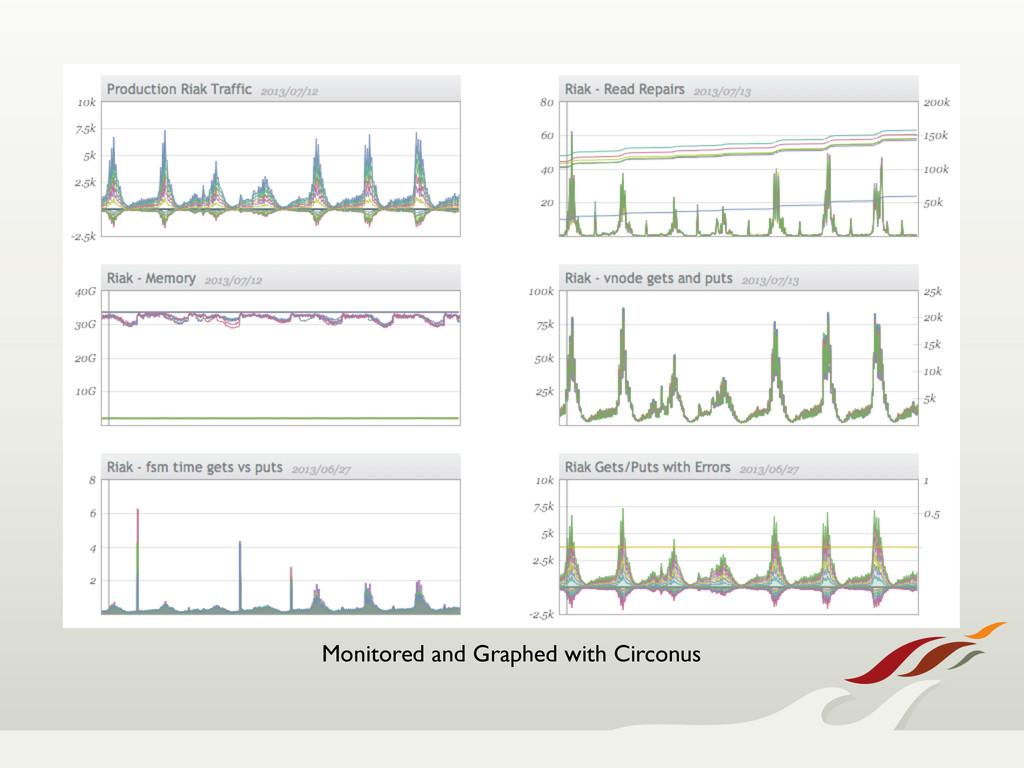
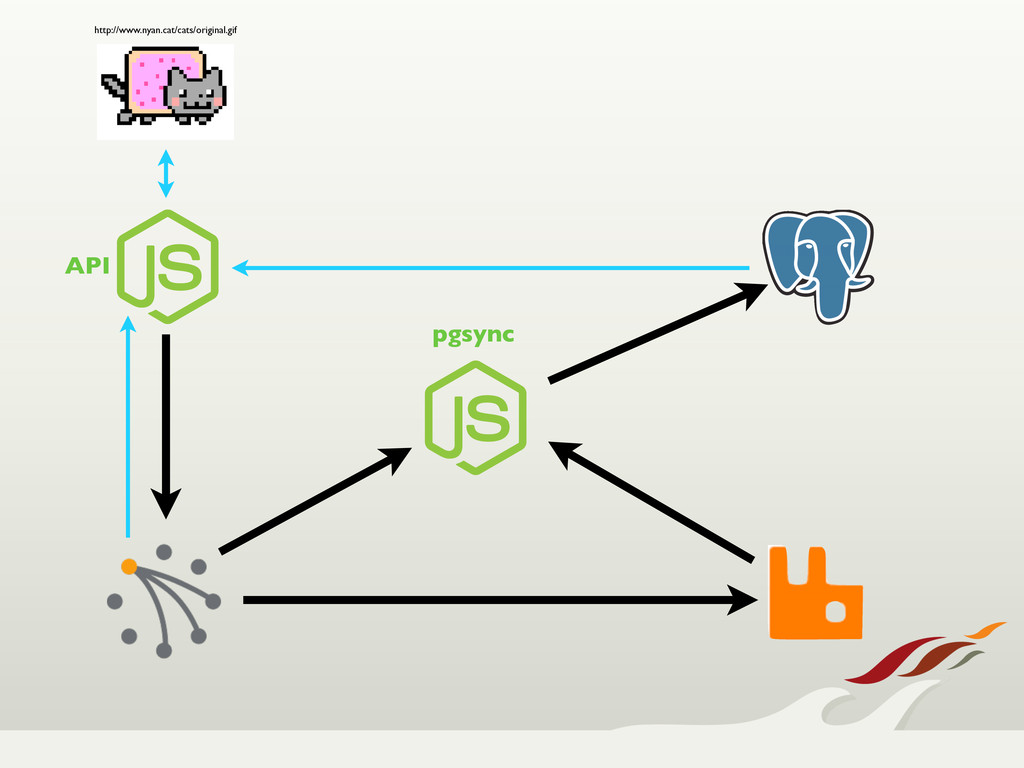
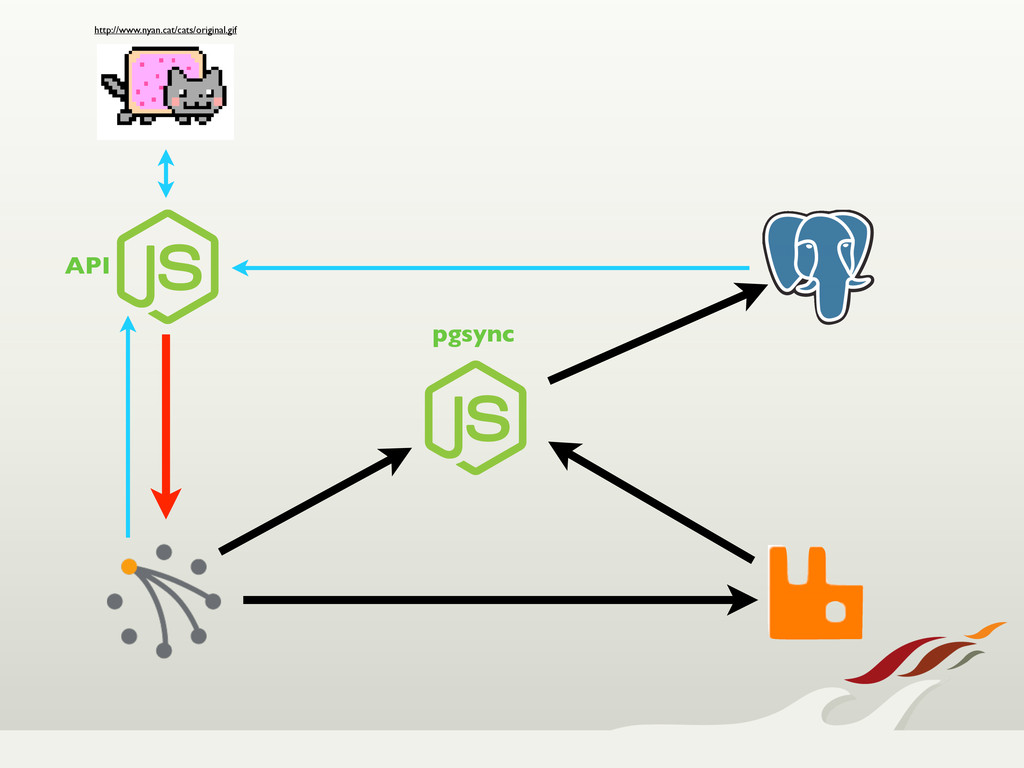
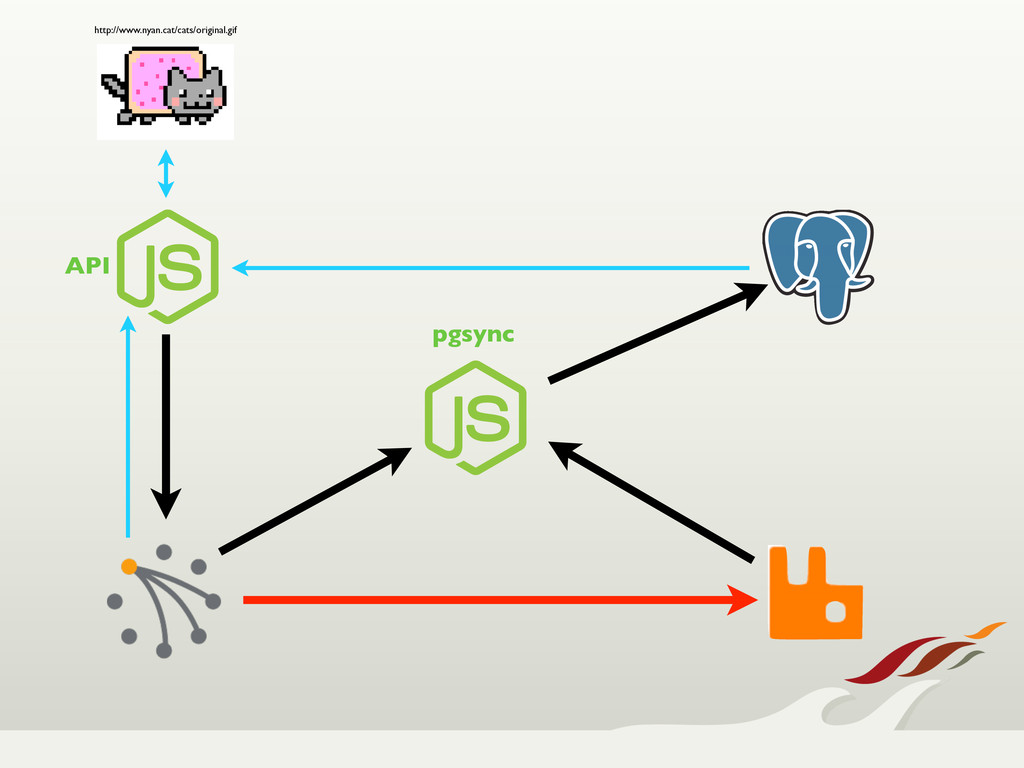
turned toward Riak, which provided us with a highly available, fault tolerant, easily scalable solution.
Through node failures, upgrades, and migrations, Riak held its own. When we needed features from a traditional relational database, we were still able to use Riak for
up-front write guarantees, and synched that data over to Postgres, never losing data. All in all, we're very happy with our choice to use Riak, and expect it to become a regular choice in our tool box.
![Riak in Production Brian Bickerton Web Engineer [email protected] @tau_zero](https://files.speakerdeck.com/presentations/27e98200d300013013f03674f65d703d/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Any Questions? Brian Bickerton [email protected] @tau_zero OmniTI omniti.com @omniti](https://files.speakerdeck.com/presentations/27e98200d300013013f03674f65d703d/slide_24.jpg){kind=link}