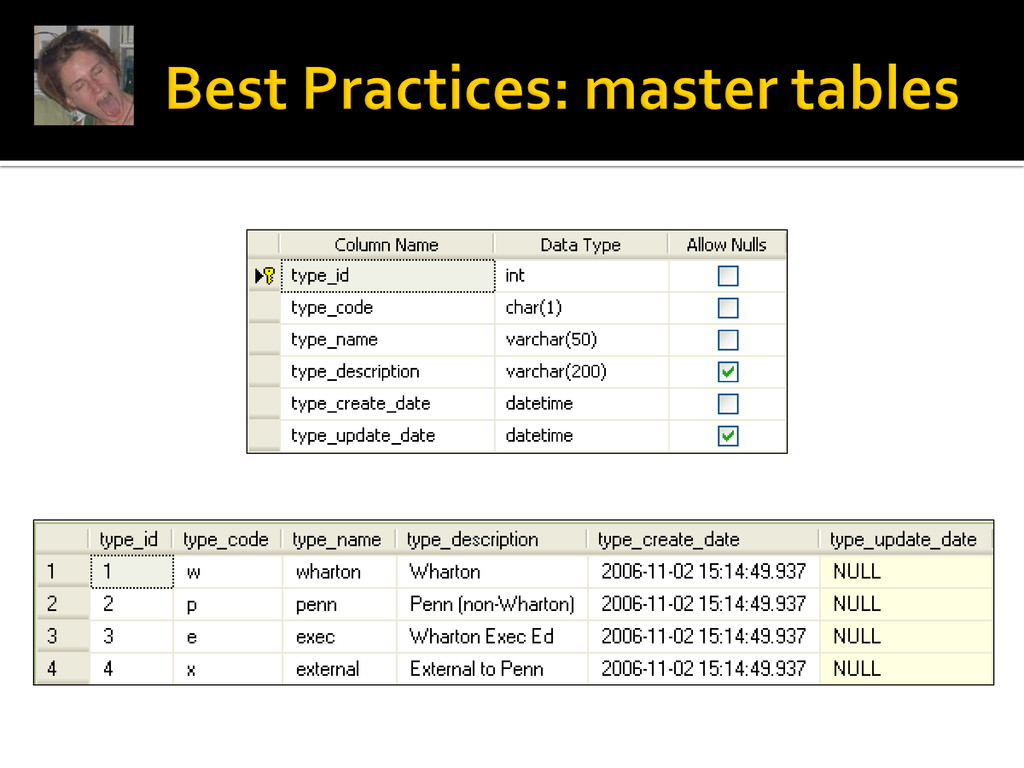
Why? Cleaner code Logical joins Sanity of future developers and future you Explicitly name constraints Avoid keywords as column names WRDS Fail: group, client, school, subscriber, and institution are all used for the same data entity
clear buffers & cache */ SELECT s.term, s.section_id, COUNT(penn_id) FROM flat_section s JOIN flat_enrollment e ON s.section_id = e.section_id AND s.term = e.term GROUP BY s.term, s.section_id
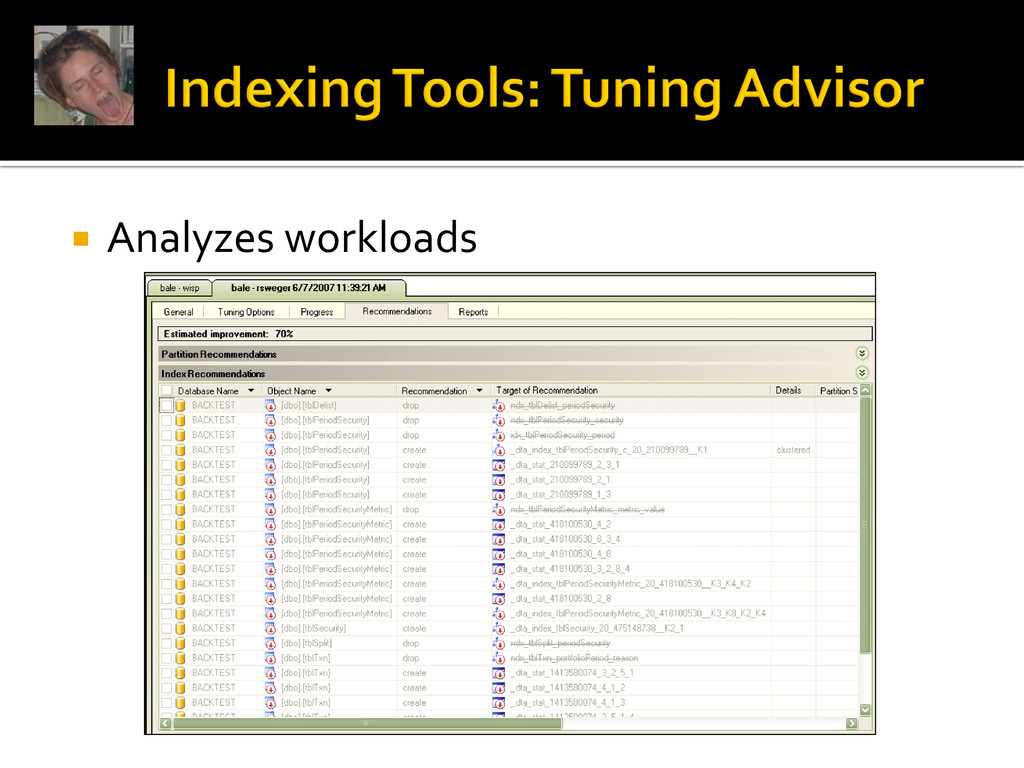
How are the columns used in queries? Cardinality: 1:1, 1:many, many:many Data type Indexing multiple columns: moderation Goal 1: performance! Goal 2: smallest index file possible.
INTEGER: 16 bits (0 – 65536): 0101010101010101 INTEGER: 32 bits (0 – 16777215): 01010101010101010101010101010101 VARCHAR ‘philadelphia’: 104 bits, at least (encoding UTF-8): 01010101010101010101010101010101010101010101010101010101 010101010101010101010101010101010101010101010101 Consider joining 4 tables on ‘philadelphia’: 4 initial lookups on indexes, 8 times as bulky and less cacheable as a small integer. Index on VARCHARs only when needed Keeps index files smaller and less chance of fragmentation; fragmented index files make Matt Frew’s life hellish (no, that is NOT a positive!) Consider purpose: don’t index for a one time script or report
each WRDS query VARCHAR columns that should be INTEGERS Report requests for subscribers asking number of queries for a date range group by library and file Before indexing, full table scan: 30 secs per query Index added: subscriber, query date, library, file After indexing, without table scan: 0.02 secs per query
Default constraints Triggers image courtesy of My New Filing Technique is Unstoppable by David Rees: http://www.mnftiu.cc/2002/11/26/filing-009/(nsfw)
after. Ask for opinions, and share your opinions! More eyes = better database design More ideas = better database design Anyone have any tips… or questions?
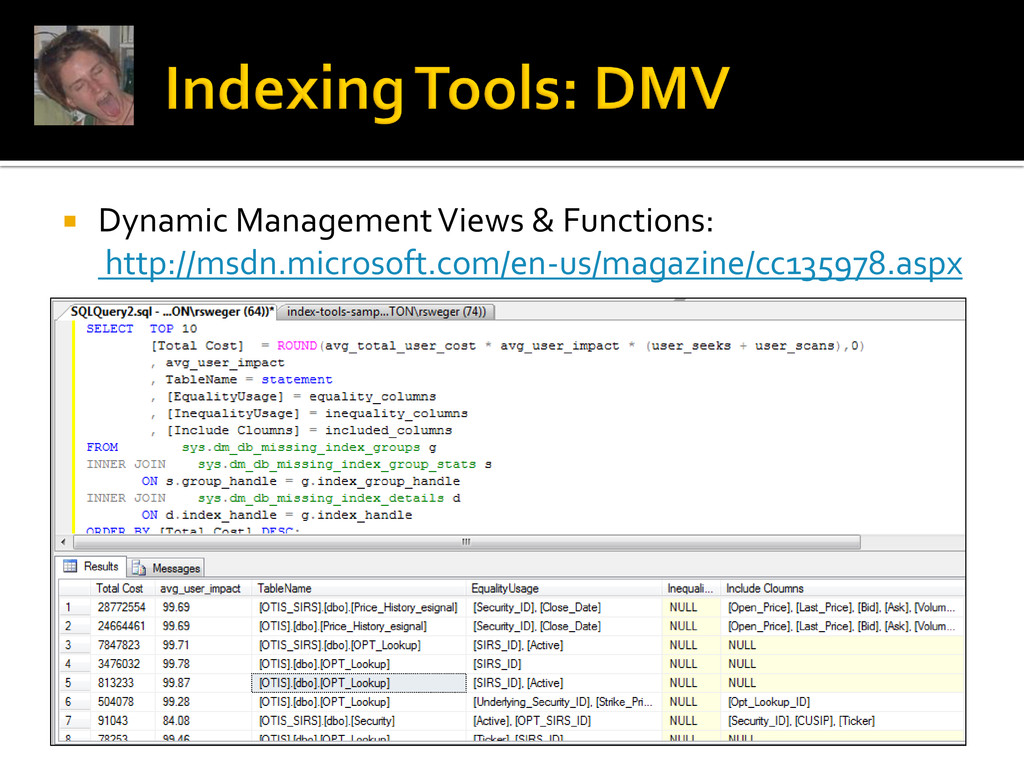
Query Performance Turning Distilled by Grant Fritchey and Sajal Dam 3. Comparing Tables Organized with Clustered Indexes versus Heaps http://technet.microsoft.com/en-us/library/cc917672.aspx 4. MS Index Design Guidelines http://msdn.microsoft.com/en-us/library/ms191195.aspx 5. Clustered Indexes vs. Nonclustered Indexes in SQL Server http://digcode.com/default.aspx?page=ed51cde3-d979-4daf-afae-fa6192562ea9&article=443e9774-7d26-422d-a2f1- dbcafbb1e1fc&pc=5 6. SQL Server Execution Plans (free e-book, registration required) http://www.sqlservercentral.com/articles/books/65831/ 7. Uncover Hidden Data to Optimize Application Performance http://msdn.microsoft.com/en-us/magazine/cc135978.aspx 8. My New Filing Technique is Unstoppable (NSFW) http://www.mnftiu.cc/2002/11/26/filing-001/ 9. SQL in the Wild http://sqlinthewild.co.za/ 10. Journey to SQL Authority With Pinal Dave http://blog.sqlauthority.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}