About Us • Călin-Andrei Burloiu, Big Data Engineer at Adobe • Adobe • Creative • Photoshop, Premiere, Audition etc. • Marketing Cloud • Audience Manager, Analytics, Target etc.
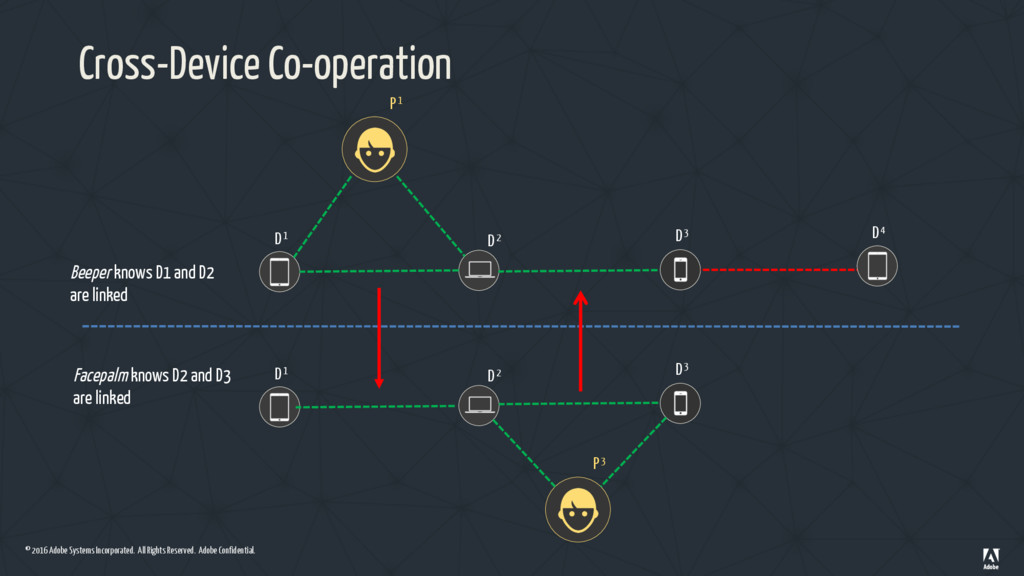
DeviceGraph • Also known as Cross-Device Co-op • Problem solved – Identify devicesthat belong to the same person • Solution – Perform connected components on a graph of IDs – Identify people as clusters
Apache Spark • We use Apache Spark with Scala • A fast and general engine for large-scale data processing (Big Data) • API: – Functional (Scala-like) • map, flatMap, filter, sort – Relational (SQL-like) • select, where, groupBy, join • Distributed – A Driver node submits work to Executor nodes
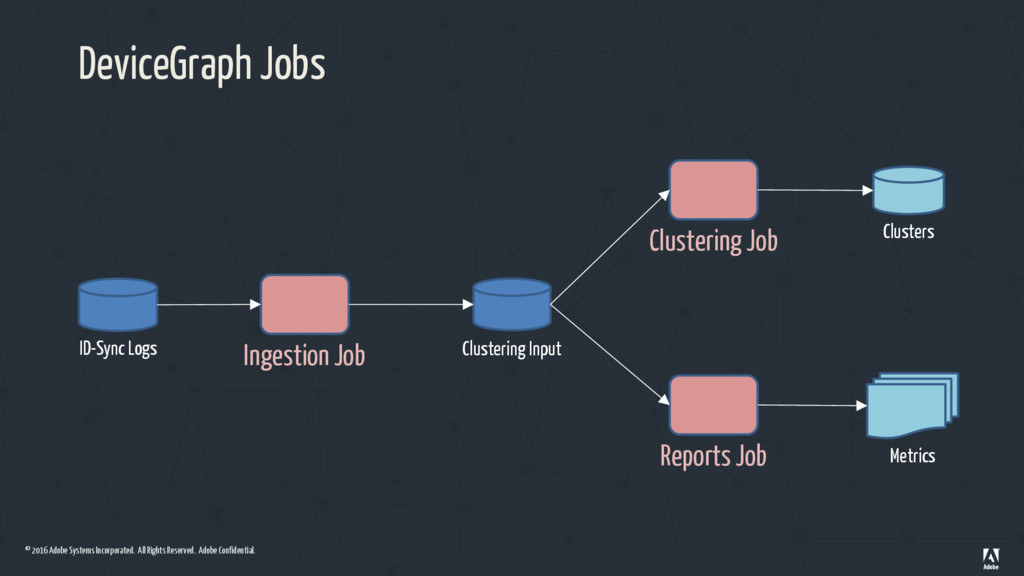
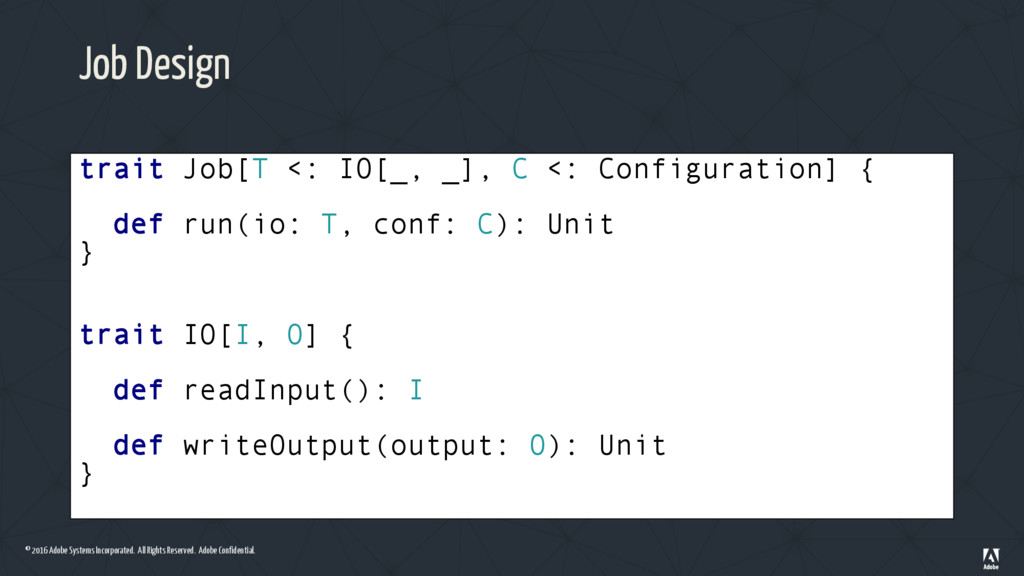
Job Design • Extracting data access(IO) from the business logic (Job) • IO depends on the environment – In production we read/write data from Amazon S3 (or HDFS) – In tests we create an IO stub with input test cases and expected output
Functional Infrastructure • Immutable Infrastructure – IT resources are replaced rather than changed – Create a Spark Cluster cluster every time we want to run a bunch of jobs • Deploy on Amazon EMR (Elastic MapReduce) • Deploying jobs is a function – which • creates a cluster • deploys the jobs • runs the jobs – takes as input • Configuration • Environment • Jobs to run
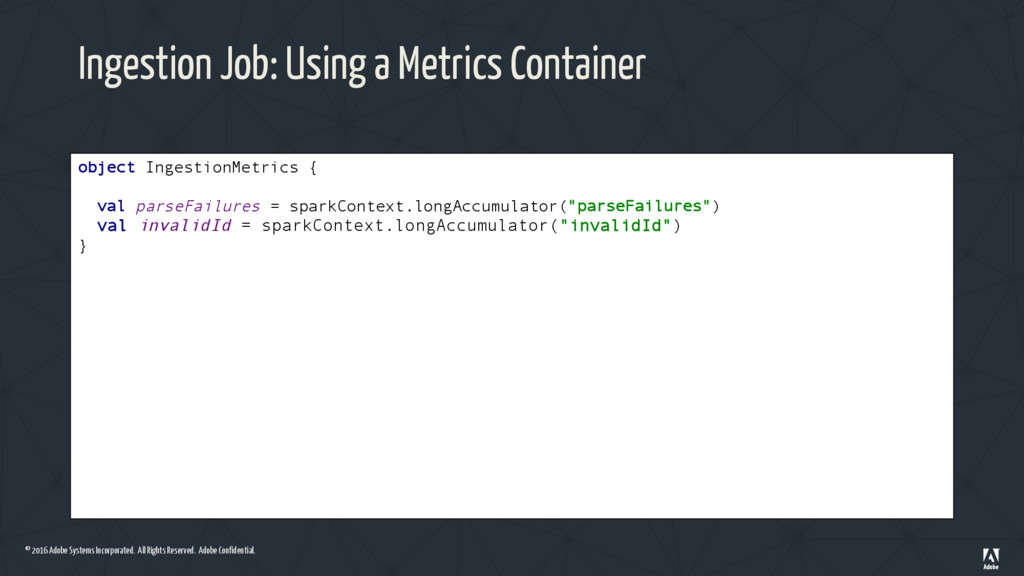
Ingestion Job: Using a Metrics Container object IngestionMetrics { val parseFailures = sparkContext.longAccumulator("parseFailures") val invalidId = sparkContext.longAccumulator("invalidId") }
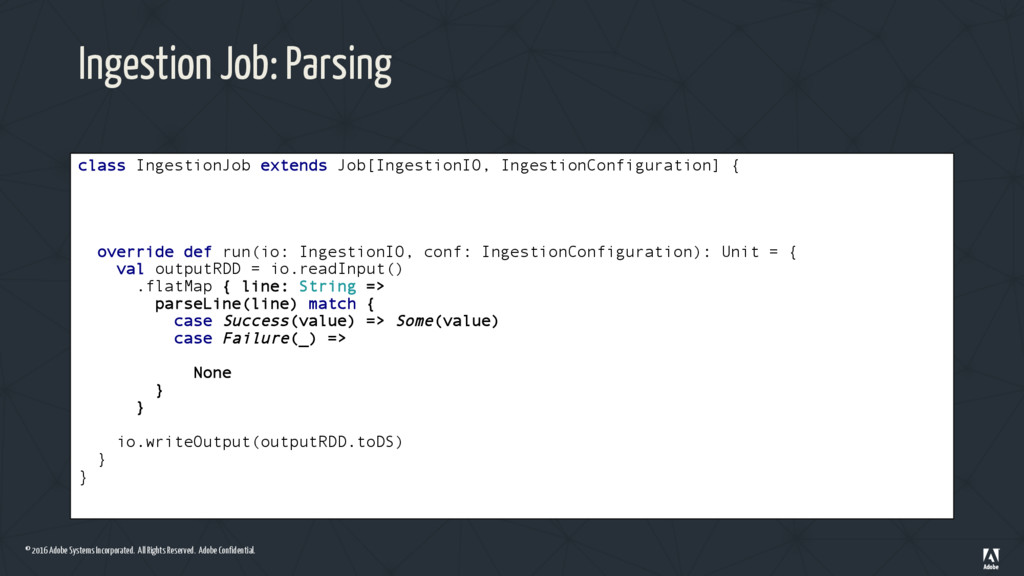
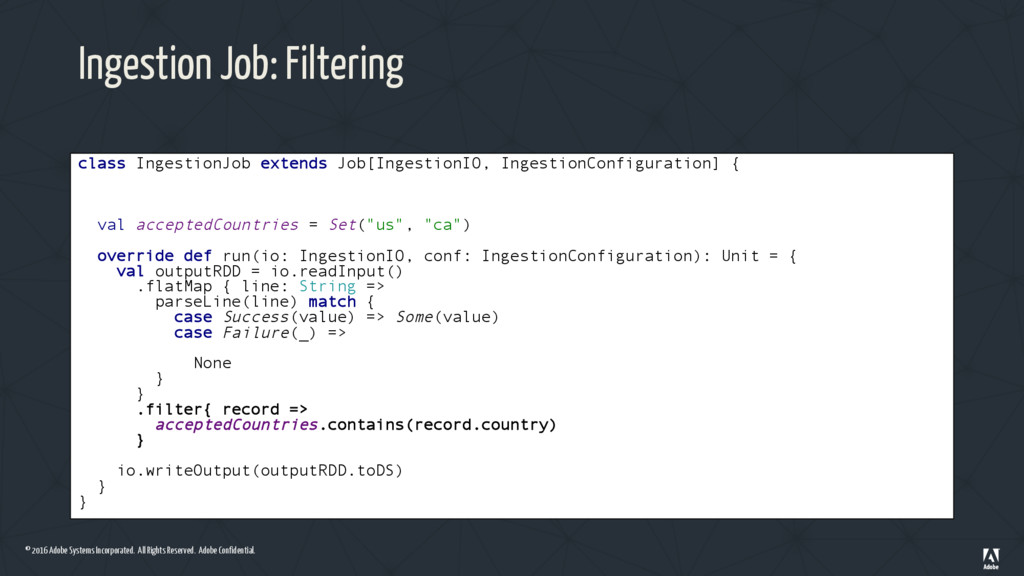
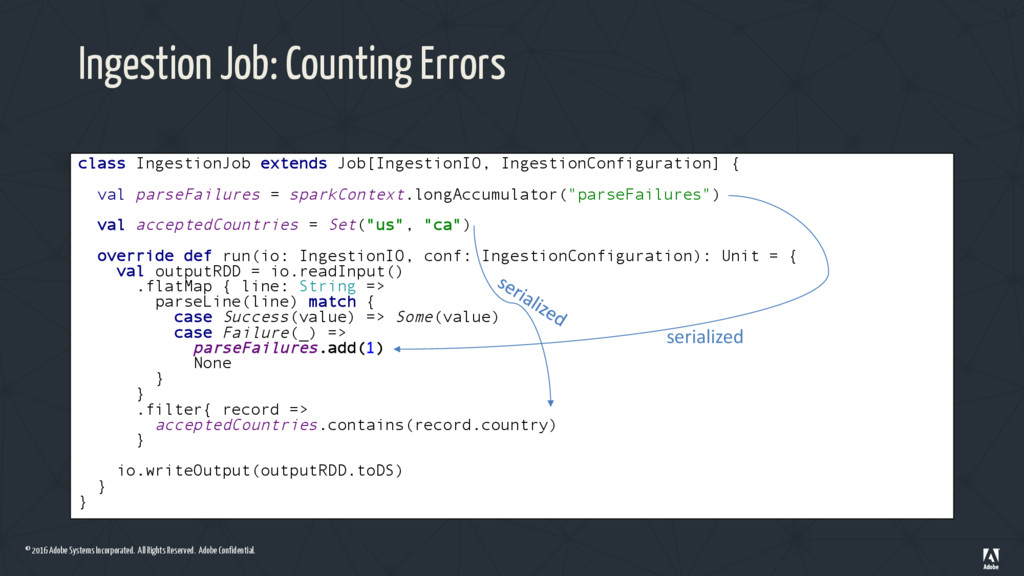
Ingestion Job: Using a Metrics Container class IngestionJob extends Job[IngestionIO, IngestionConfiguration] { val acceptedCountries = Set("us", "ca") override def run(io: IngestionIO, conf: IngestionConfiguration): Unit = { val outputRDD = io.readInput() .flatMap { line: String => parseLine(line) match { case Success(value) => Some(value) case Failure(_) => IngestionMetrics.parseFailures.add(1) None } } .filter{ record => acceptedCountries.contains(record.country) } io.writeOutput(outputRDD.toDS) } } FAILURE! • Accumulators need to be instantiated on the Driver • When the Scala app starts an IngestionMetrics instance will be created on each Spark process from each machine • Not what we want!
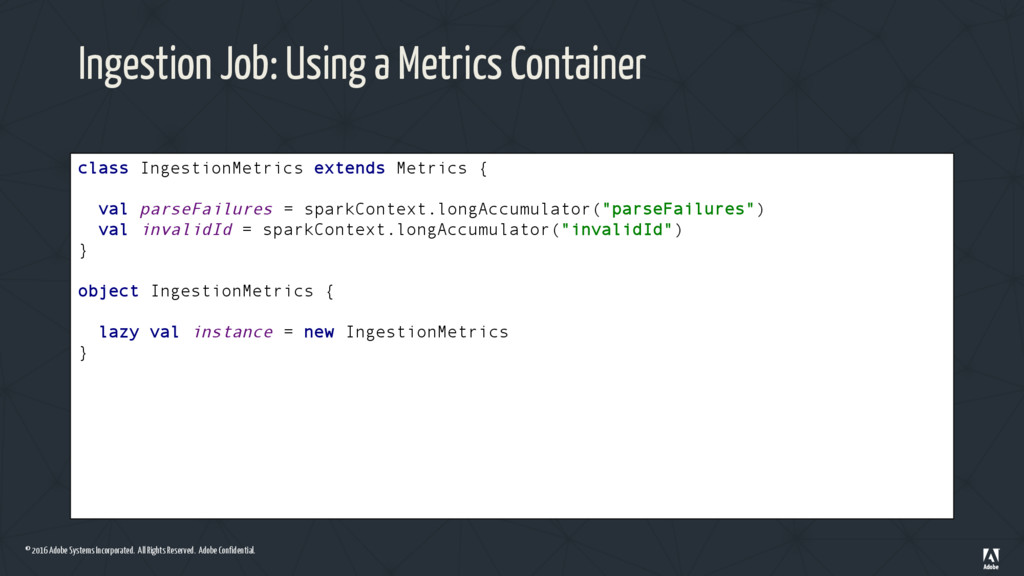
Ingestion Job: Using a Metrics Container class IngestionMetrics extends Metrics { val parseFailures = sparkContext.longAccumulator("parseFailures") val invalidId = sparkContext.longAccumulator("invalidId") } object IngestionMetrics { lazy val instance = new IngestionMetrics }
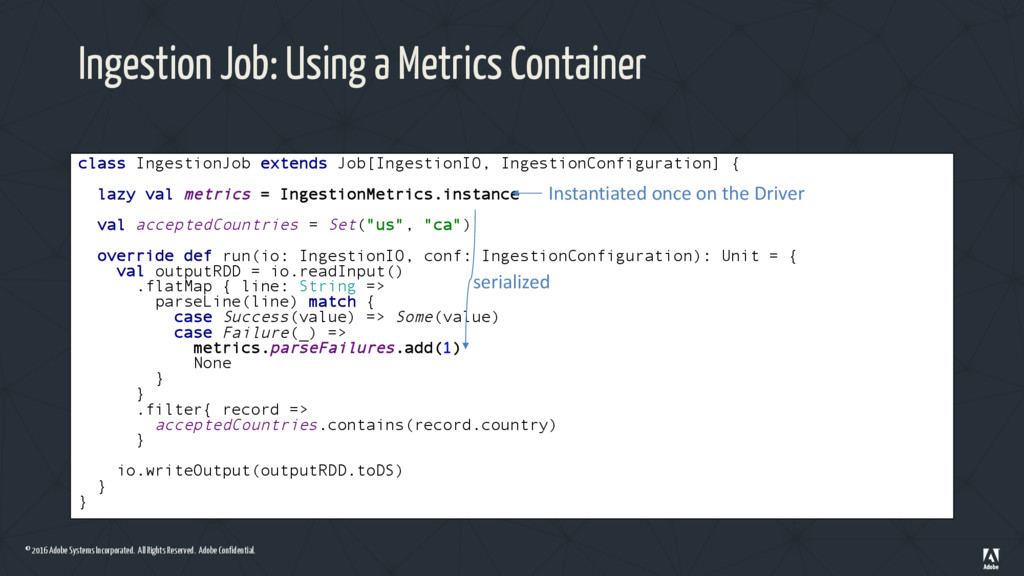
Ingestion Job: Using a Metrics Container class IngestionJob extends Job[IngestionIO, IngestionConfiguration] { lazy val metrics = IngestionMetrics.instance val acceptedCountries = Set("us", "ca") override def run(io: IngestionIO, conf: IngestionConfiguration): Unit = { val outputRDD = io.readInput() .flatMap { line: String => parseLine(line) match { case Success(value) => Some(value) case Failure(_) => metrics.parseFailures.add(1) None } } .filter{ record => acceptedCountries.contains(record.country) } io.writeOutput(outputRDD.toDS) } } Instantiated once on the Driver serialized
Conclusions • Use Immutable Infrastructure – no side effects – everything is in the Configuration • Split computation in functional & testable jobs – Extract data access from business logic • Pay attention objects blindly serialized – like Scala singleton objects • Leverage mutable state for efficiency – Use accumulators for iterative algorithms
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}