당연한것이다. 모니터링, 에러감지, 장애복구 등이 필수적이다. file size는 엄청나게 커졌다. I/O와 block size를 다시 생각해봐야 한다. 대부분 file은 append만 발생하며, in-place update는 거의 발생하지 않는다. 대부분 sequential read 이다. 따라서 write가 아닌 append를 최적화해야한다. application, file system을 함께 design하는것은 전체 system에 이득이 된다.
작은 파일도 들어가지만 최적화 할필요는 없다. large streaming read는 한번에 100KB-1MB 정도의 data를 읽는다. 한 client에서 연속되는 operation은 sequential read를 수행한다. small random read는 10KB 미만의 크기를 읽는다. workload는 large, sequential write을 한다. write operation의 크기는 read와 비슷하며 한번 write된 file은 수정되지 않는다. 여러 client가 동시에 append하는경우 효율적으로 동작해야 한다. 수백개의 producer가 동시에 append할때 atomicity overhead는 작아야한다. low latency보다 high bandwidth가 훨씬 중요하다
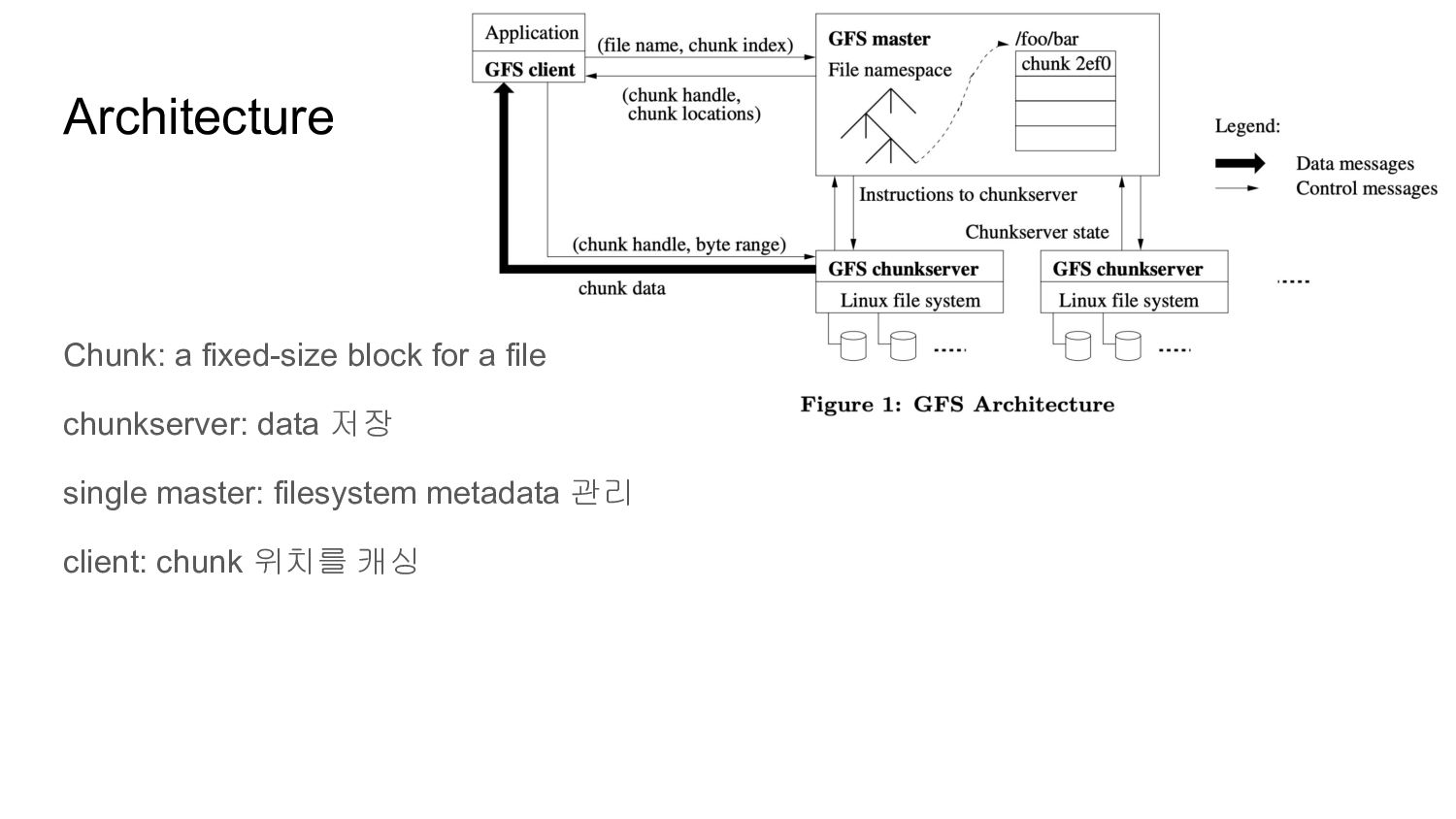
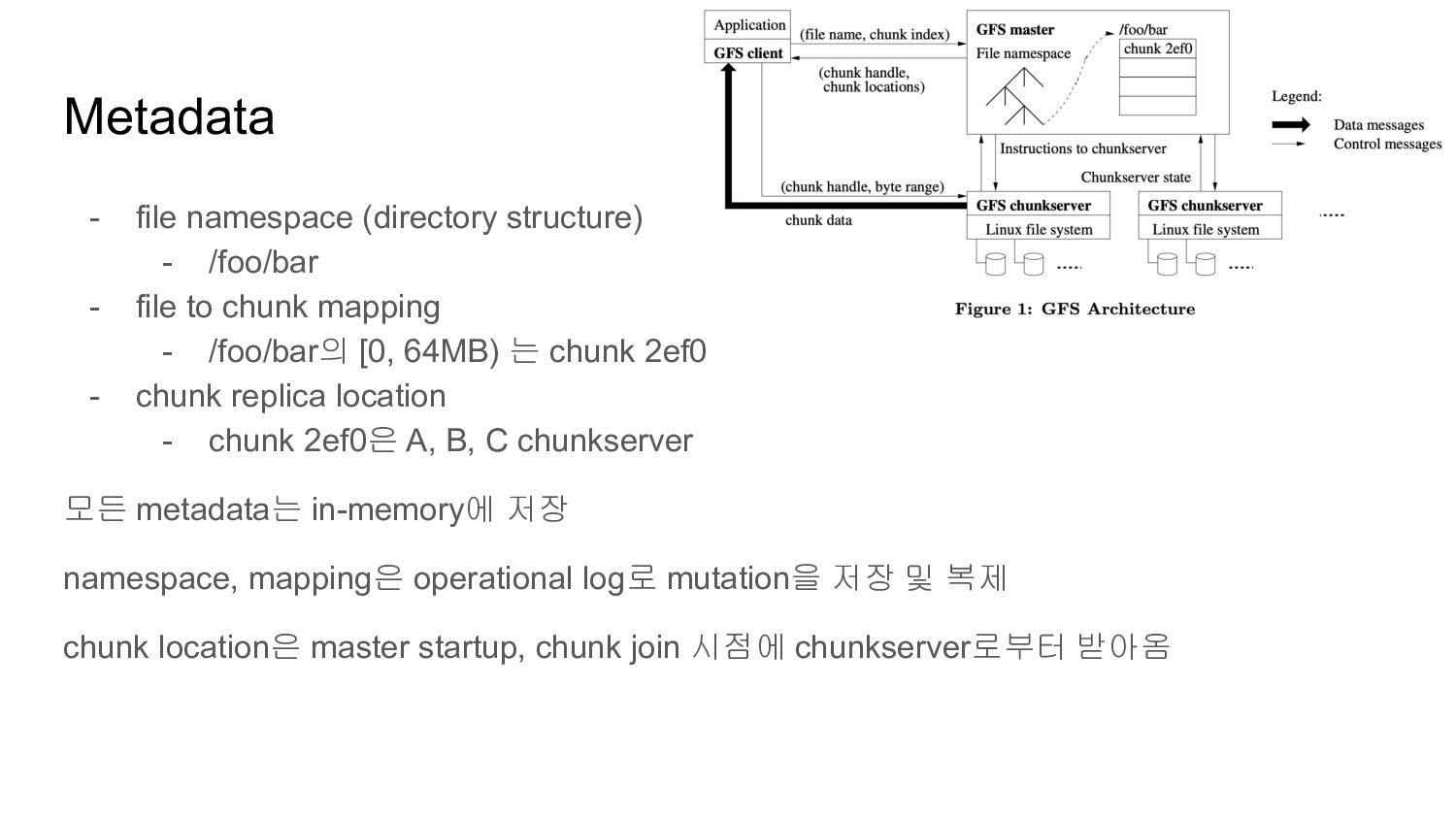
to chunk mapping - /foo/bar의 [0, 64MB) 는 chunk 2ef0 - chunk replica location - chunk 2ef0은 A, B, C chunkserver 모든 metadata는 in-memory에 저장 namespace, mapping은 operational log로 mutation을 저장 및 복제 chunk location은 master startup, chunk join 시점에 chunkserver로부터 받아옴
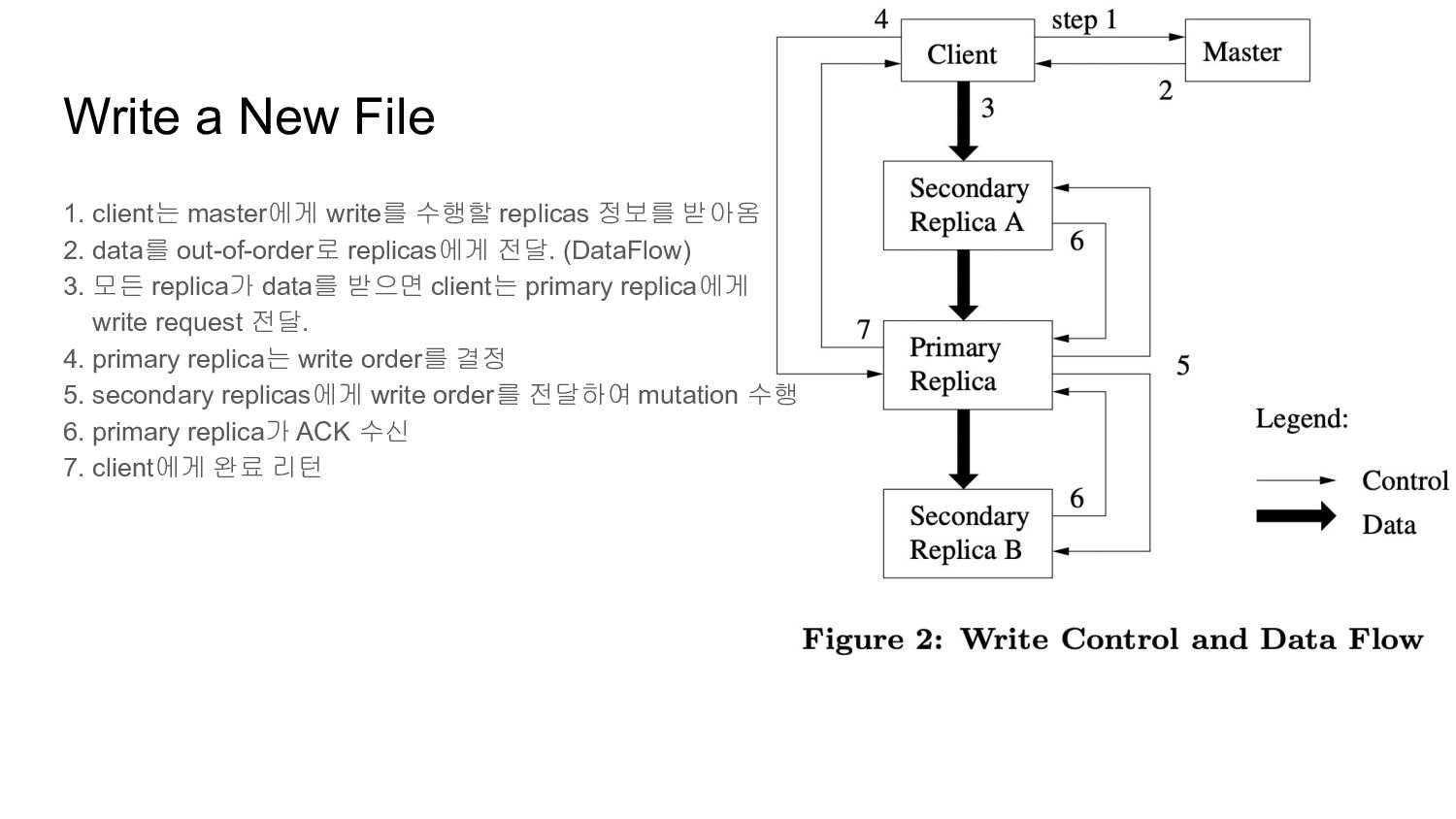
줄일 수 있음 client는 가장 가까운 replica에게만 전달 pipelining을 통해 overall latency를 줄임 record-append data는 동시에 들어오지만 primary가 append순서를 결정함 data가 chunk size를 넘는경우 chunk에 padding을 넣고 재시도를 하도록 함
table로 표현함 lookup table의 각 record는 read/write lock을 가짐 /d1/d2/…/dn/leaf 라는 path가 있을경우 /d1, /d1/d2, …, /d1/…/dn 까지 순서대로 read lock (deadlock을 피하기위한 순서) /d1/d2/…/dn/leaf 는 read or write lock 같은 directory에 대해 여러 file을 contention없이 동시에 생성할 수 있음 반면 inode는 contention이 발생함 directory는 read-lock으로 delete, rename, snapshot을 실행하지 못하게 함 file은 write-lock으로 같은 file name으로 file을 생성하지 못하게 함
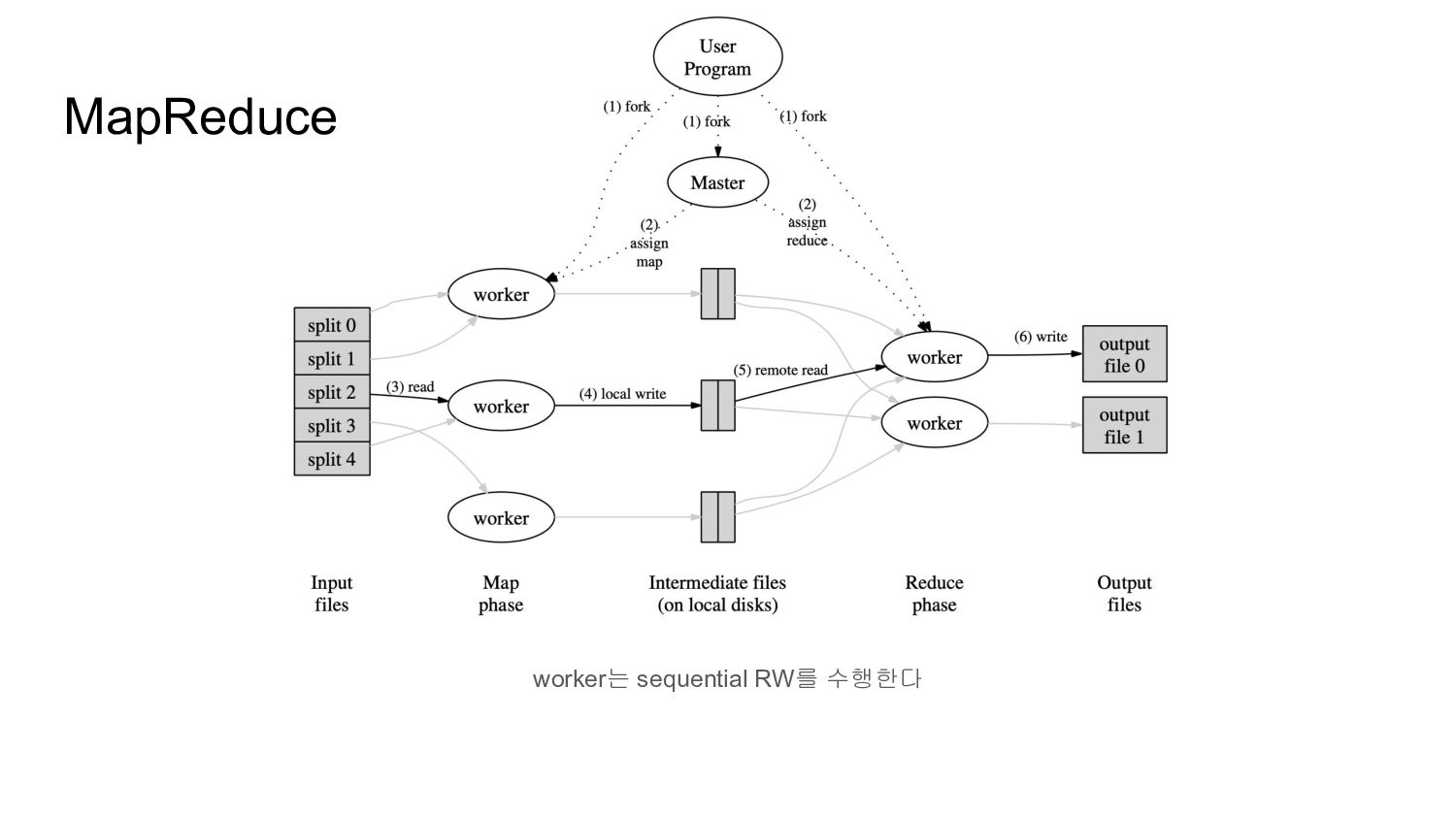
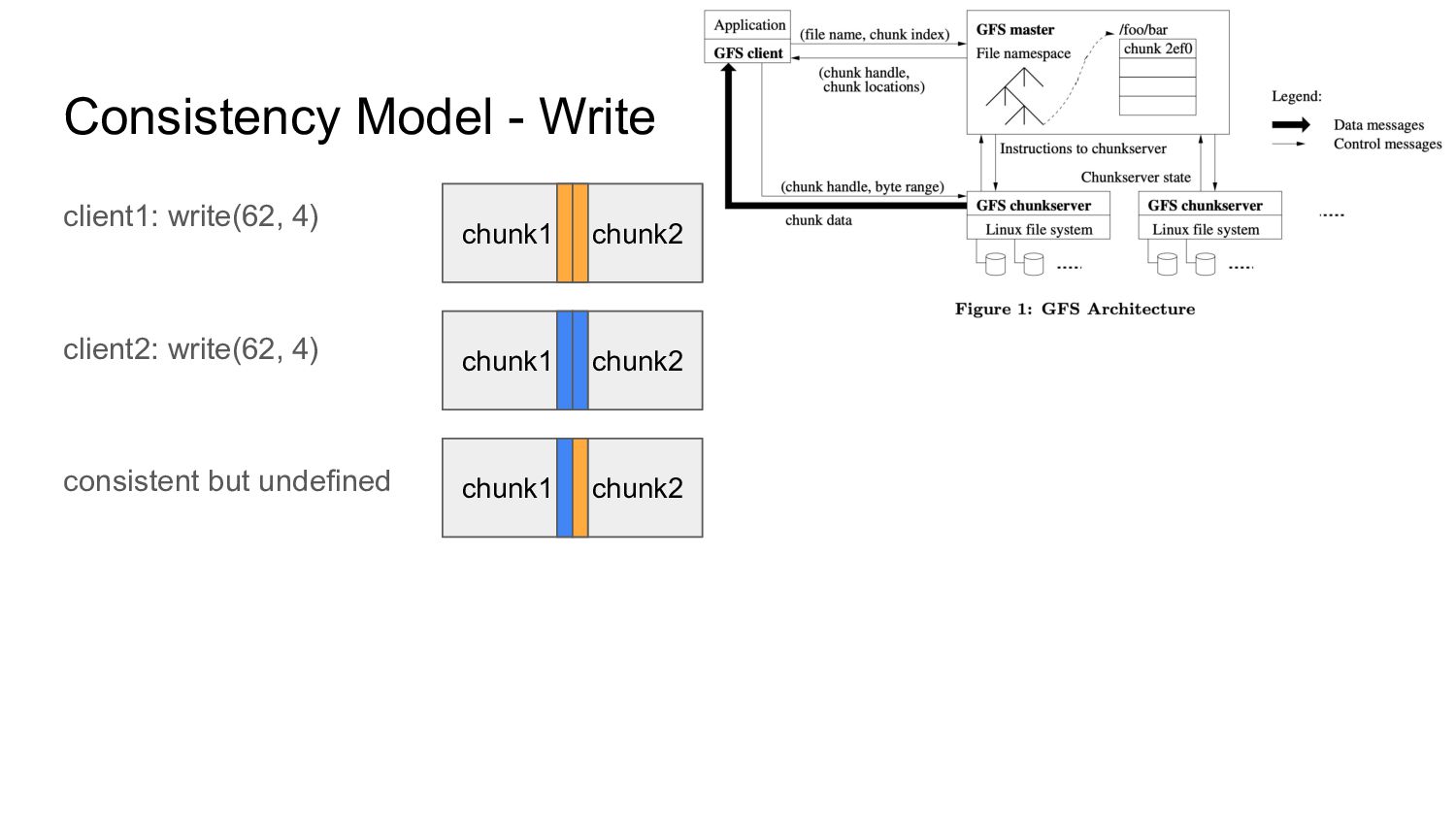
sequential RW에 대해 최적화 single master는 control plane으로 data path에 관여하지 않음 application(library)과 filesystem API를 같이 디자인 → weaker consistency model → append 성능 극대화
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}