• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables Monday, July 4, 2011
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” Monday, July 4, 2011
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” • Once we turn the relational data back into objects ... Monday, July 4, 2011
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” • Once we turn the relational data back into objects ... • We still need to convert it to data for our frontend Monday, July 4, 2011
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” • Once we turn the relational data back into objects ... • We still need to convert it to data for our frontend • I don’t know about you, but I have better things to do with my time. Monday, July 4, 2011
time • Applications need new fields • Applications need new indexes • Data is growing – sometimes very fast • Users need to be able to alter their schemas without making their data unavailable • The web world expects 24x7 service • RDBMSs can have a hard time doing this Monday, July 4, 2011
high read loads • Sooner or later, writing becomes a bottleneck • Sharding – partitioning a logical database across multiple database instances • Joins and aggregation become a problem • Distributed transactions are too slow for the web • Manual management of shards • Choosing shard partitions • Rebalancing shards Monday, July 4, 2011
kinds of items it can contain and how they can be retrieved • What can the system store, and what does it know about what it contains? • The relational data model is about storing records made up of named, scalar-valued fields, as specified by a schema, or type definition • What kind of queries can you do? • SQL is a manifestation of the kinds of queries that fall out of relational algebra Monday, July 4, 2011
value • The store doesn’t know anything about the the key or value • The store doesn’t know anything about the insides of the value • Operations • Set, get, or delete a key-value pair Monday, July 4, 2011
• Documents are made up of named fields • Fields may or may not have type definitions • e.g. XSDs for XML stores, vs. schema-less JSON stores • Can create “secondary indexes” • These provide the ability to query on any document field(s) • Operations: • Insert and delete documents • Update fields within documents Monday, July 4, 2011
all data for a column is kept together • An index provides a means to get a column value for a record • Operations: • Get, insert, delete records; updating fields • Streaming column data in and out of Hadoop Monday, July 4, 2011
and setting edges • Sometimes possible to annotate vertices or edges • Query languages support finding paths between vertices, subject to various constraints Monday, July 4, 2011
read scalability • Subject to coping with read-consistency issues • Sooner or later, writing becomes a bottleneck • Physical limitations (seek time) • Throughput of a single I/O subsystem Monday, July 4, 2011
Set up a duplicate system for each shard • The write-rate limitation now applies to each shard • Joins or aggregation across shards are problematic • Can the data be re-sharded on a live system? • Can shards be re-balanced on a live system? Monday, July 4, 2011
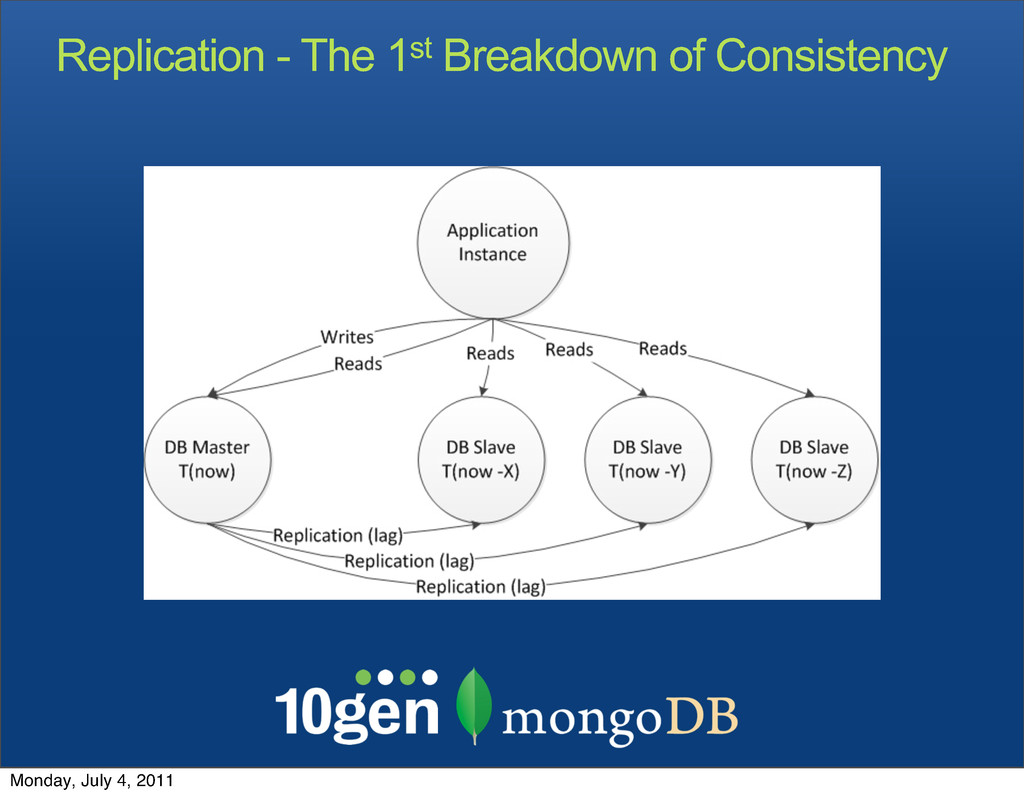
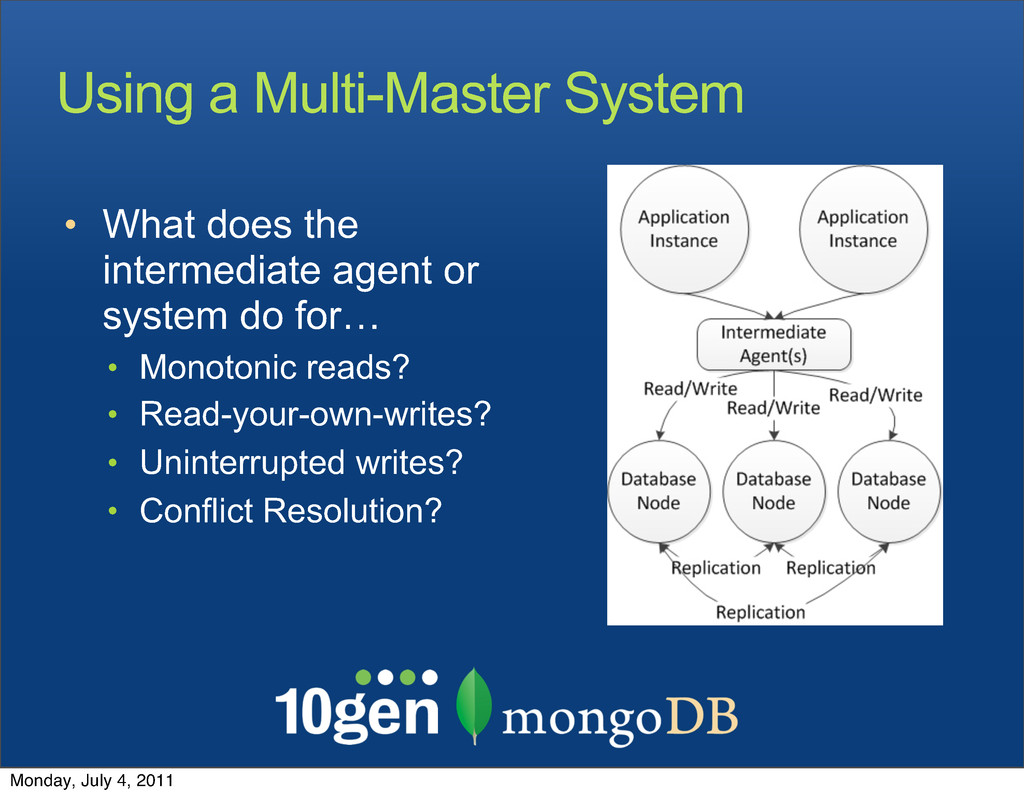
Writes can occur to any node • The same record can be updated on different nodes by different clients • All writes are replicated everywhere Monday, July 4, 2011
occur • Who wins? • A collision resolution strategy is required • Vector clocks • http://en.wikipedia.org/wiki/Vector_clock • Application access must be aware of this Monday, July 4, 2011
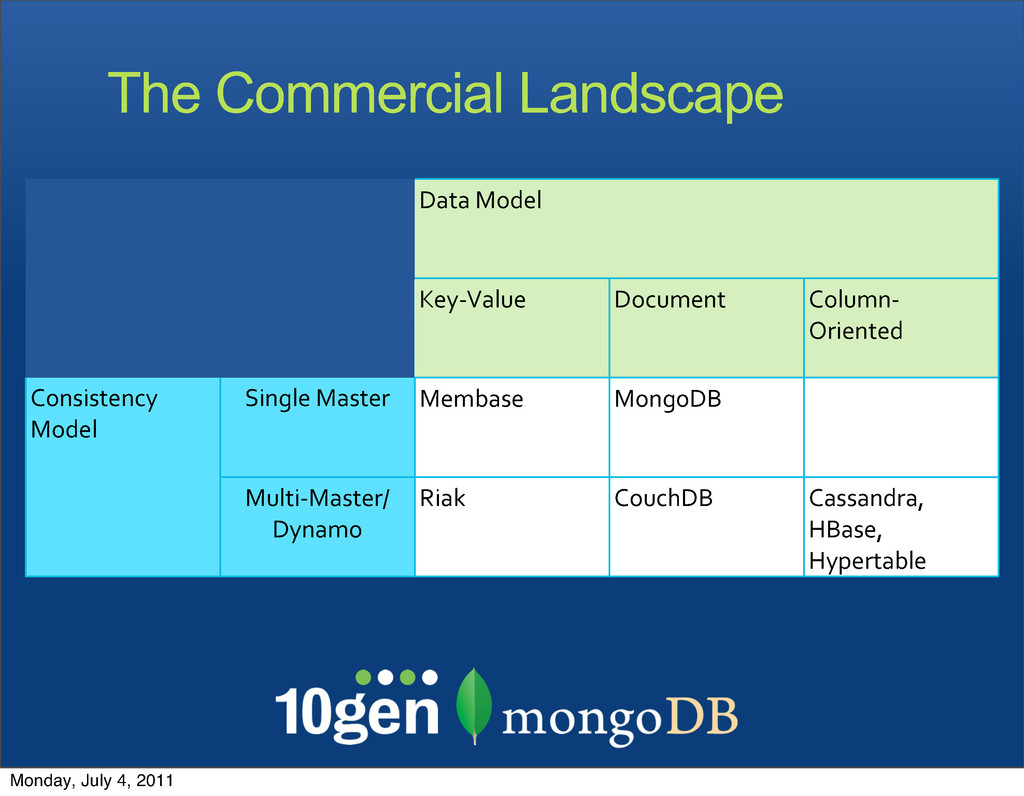
Document Column-‐ Oriented Consistency Model Single Master Membase MongoDB Consistency Model Multi-‐Master/ Dynamo Riak CouchDB Cassandra, HBase, Hypertable Monday, July 4, 2011
reads go back in time? • Read-your-own-writes • If I issue a query immediately after an insert or update, will I see my changes? • Uninterrupted writes • Am I always guaranteed the ability to write? • Conflict Resolution • Do I need to have a conflict resolution strategy? Monday, July 4, 2011
geo index • Find points near a given point, sorted by radial distance • Can be planar or spherical • Find points within a certain radial distance, within a bounding box, or a polygon • Built-in Map-Reduce • The caller provides map and reduce functions written in JavaScript Monday, July 4, 2011
by members of a “replica set” • The system elects a primary (master) • Failure of the master is detected, and a new master is elected • Application writes get an error if there is no quorum to elect a new master • Reads continue to be fulfilled Monday, July 4, 2011
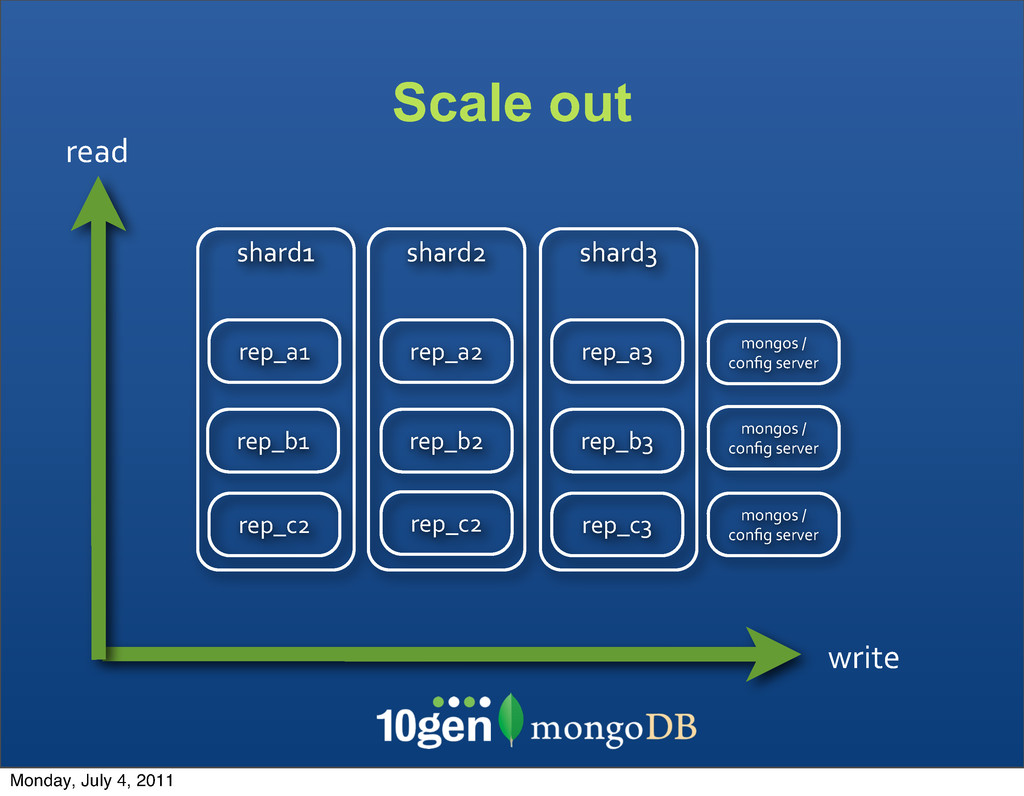
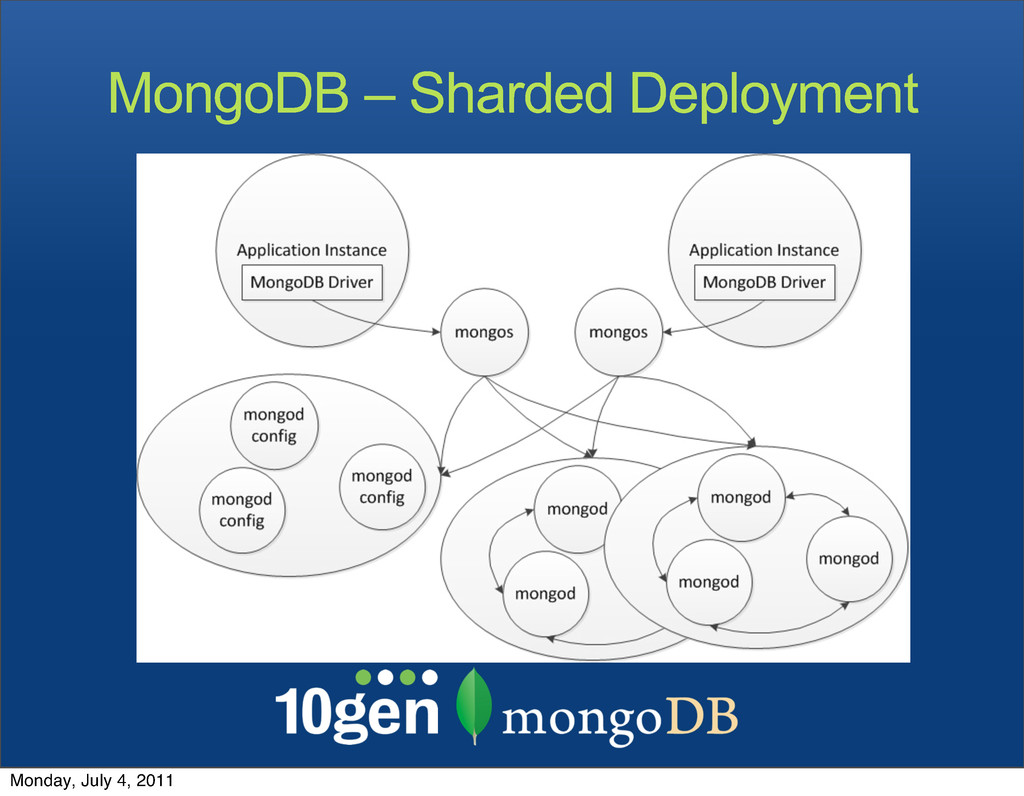
Each shard is served by its own replica set • New shards (each a replica set) can be added at any time • Shard key ranges are automatically balanced Monday, July 4, 2011
• Servers should have a lot of memory • Files are allocated as needed • Documents in a collection are kept on a list using a geographical addressing scheme • Indexes (B*-trees) point to documents using geographical addresses Monday, July 4, 2011
each other • A majority of votes is required to elect a new primary • Members can be assigned priorities to affect the election • e.g., an “invisible” replica can be created with zero priority for backup purposes Monday, July 4, 2011
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}