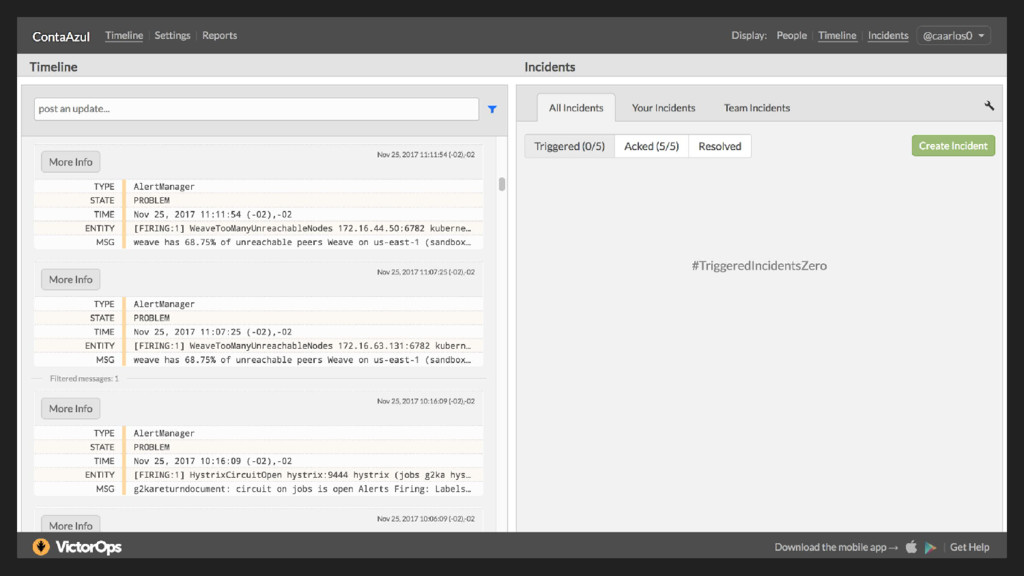
de 1m atendimento já recebia ligações dos usuários - Librato nos alertava depois de 5m+ - Falta de padrões (nomenclatura e etc) - Alertas criados (ou não) manualmente para cada serviço - Shells aleatórios espalhados aleatoriamente em lugares aleatórios - Queries esquecidas - Muitos falsos positivos - Não tinha prioridade, todos os alertas eram critical
segundo projeto a fazer parte da CNCF (junto com k8s) - Granularidade de 1s - Sugerido pelos engenheiros da Google no "SRE bible" - Simples e robusto - Padrões já definidos - Extensível por meio de custom exporters - Service discovery - Federation
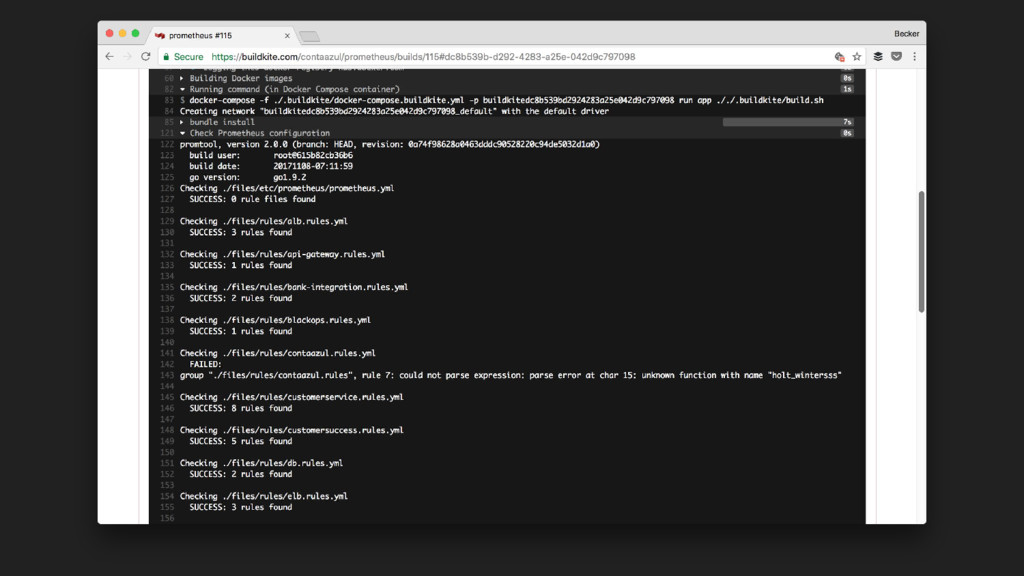
de pull-request + code review - CI/CD de toda a infraestrutura de monitoramento - Formatação padrão de regras - Mais robustez na definição de alertas e rotas
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
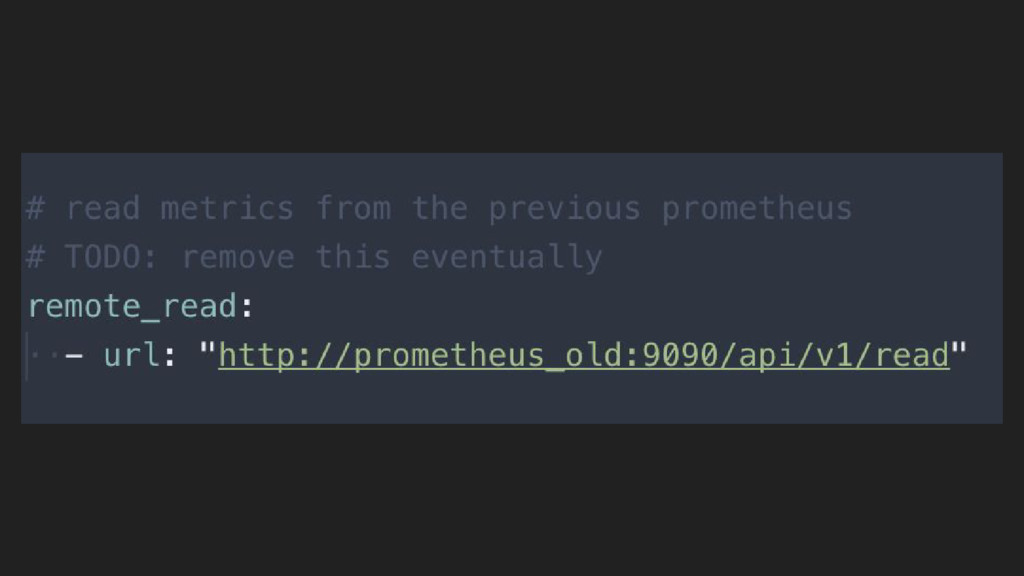{kind=link}
{kind=link}
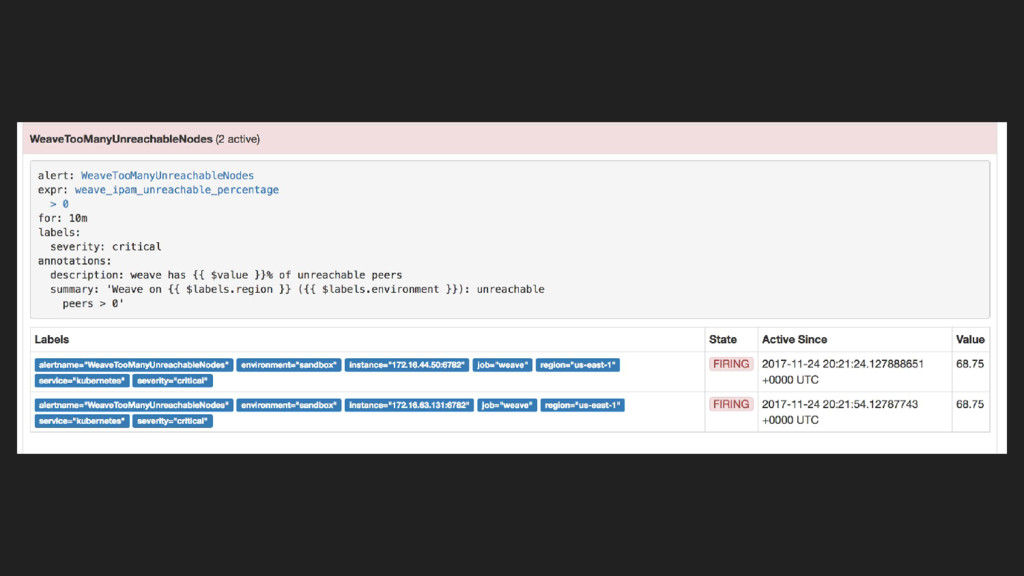{kind=link}
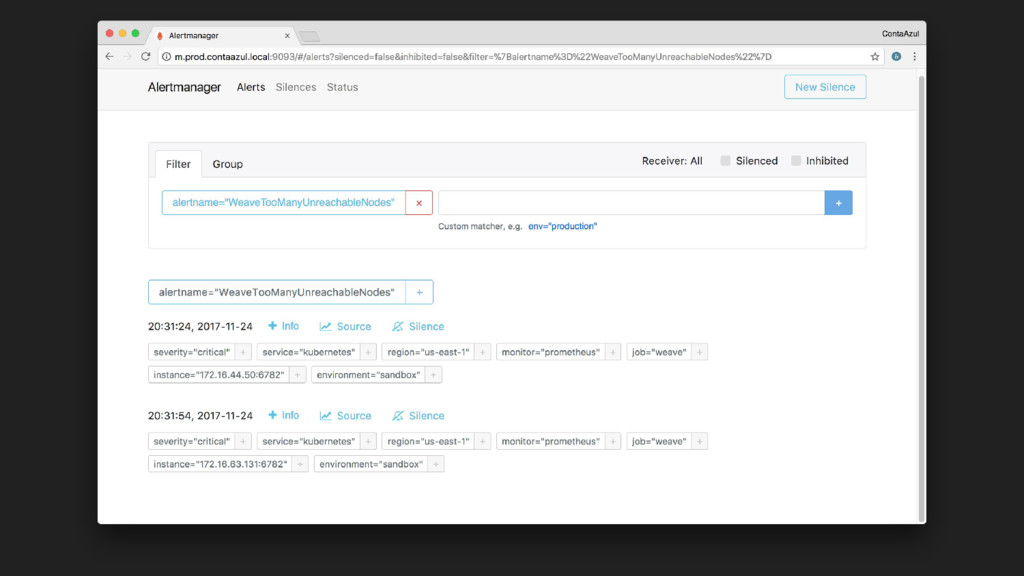{kind=link}
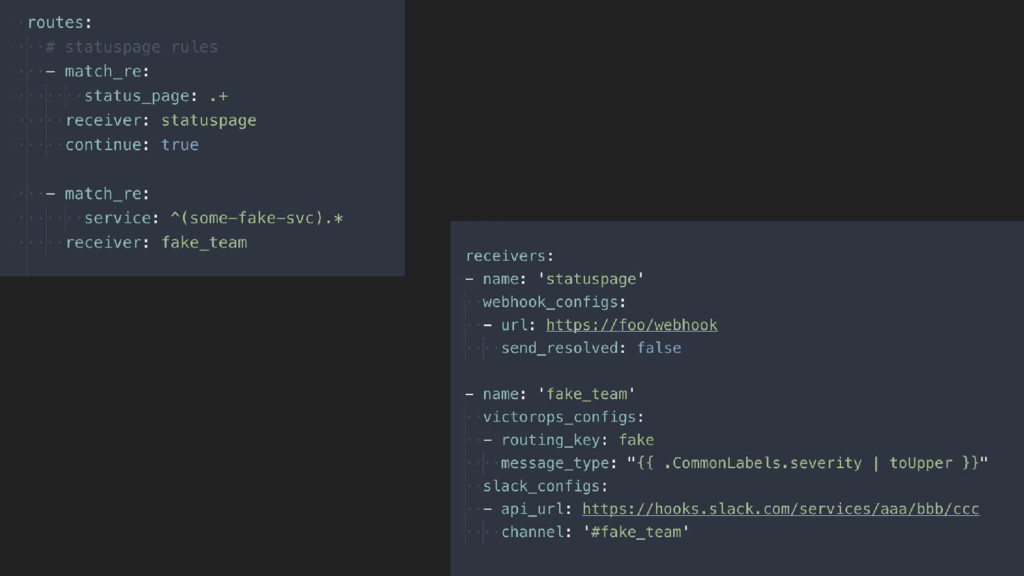{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}