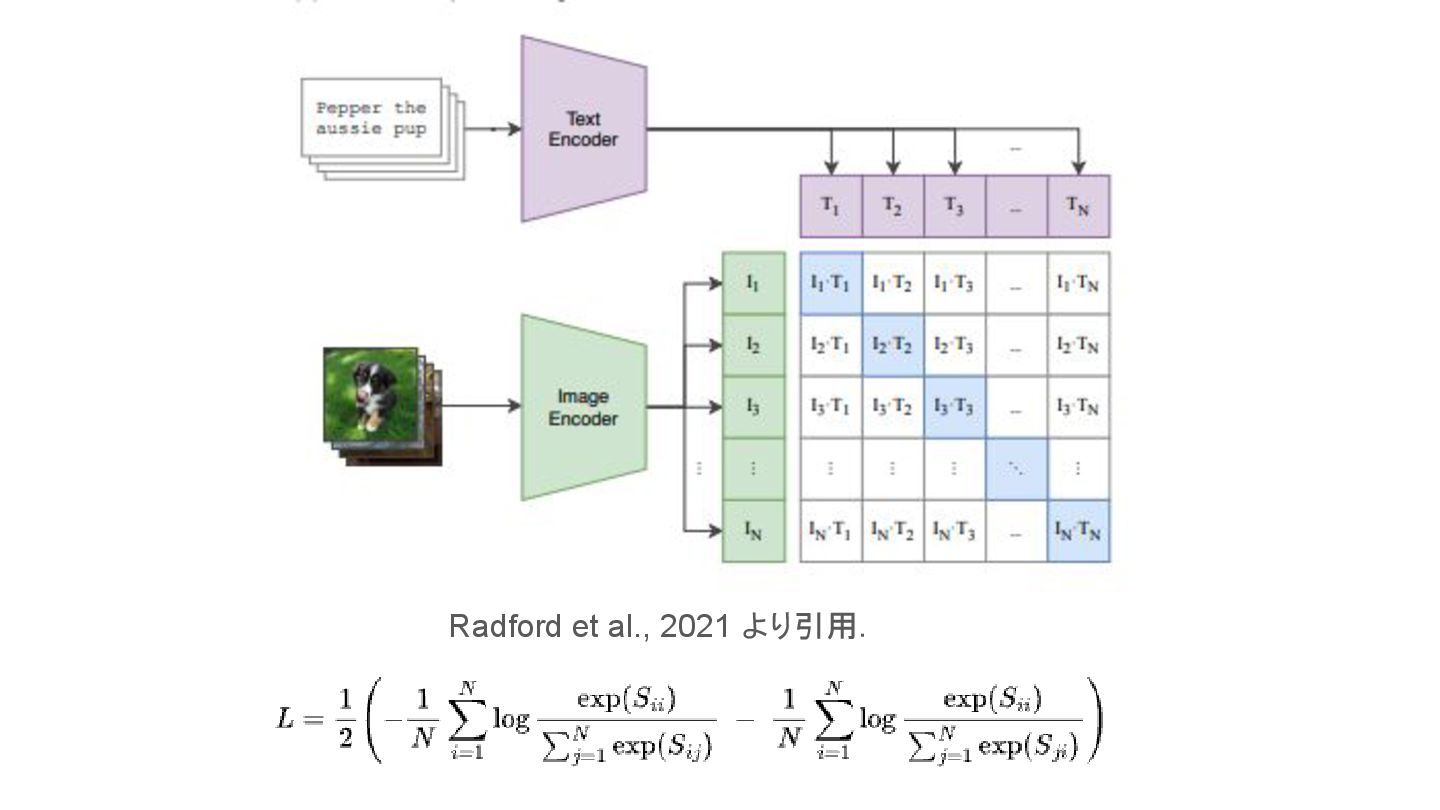
▪ 原論文(Radford et al., 2021.)から引用 CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N*N − N incorrect pairings. 背景
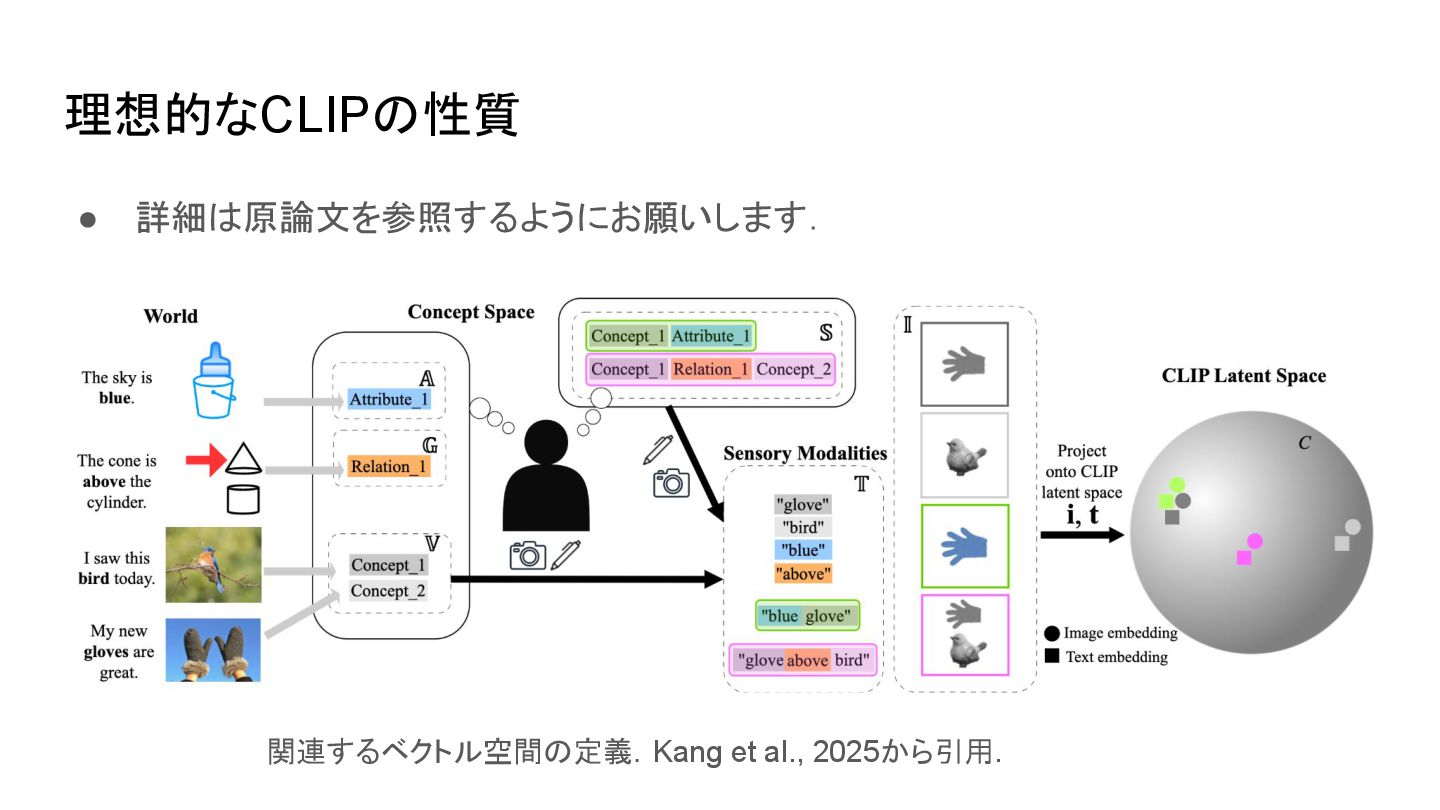
cone is above the cylinder • the cone is below the cylinderにも高スコアを返す場合あり • 位置関係や語順の違いを反映できない ▪ 例: I saw this bird today • 特定の鳥であることの考慮がされずに鳥全般に反応する場合あり ◦ attribute bindings ▪ 例: sky is blue • sky is orangeにも高スコアを返す場合がある • 対象と属性の対応づけが曖昧
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
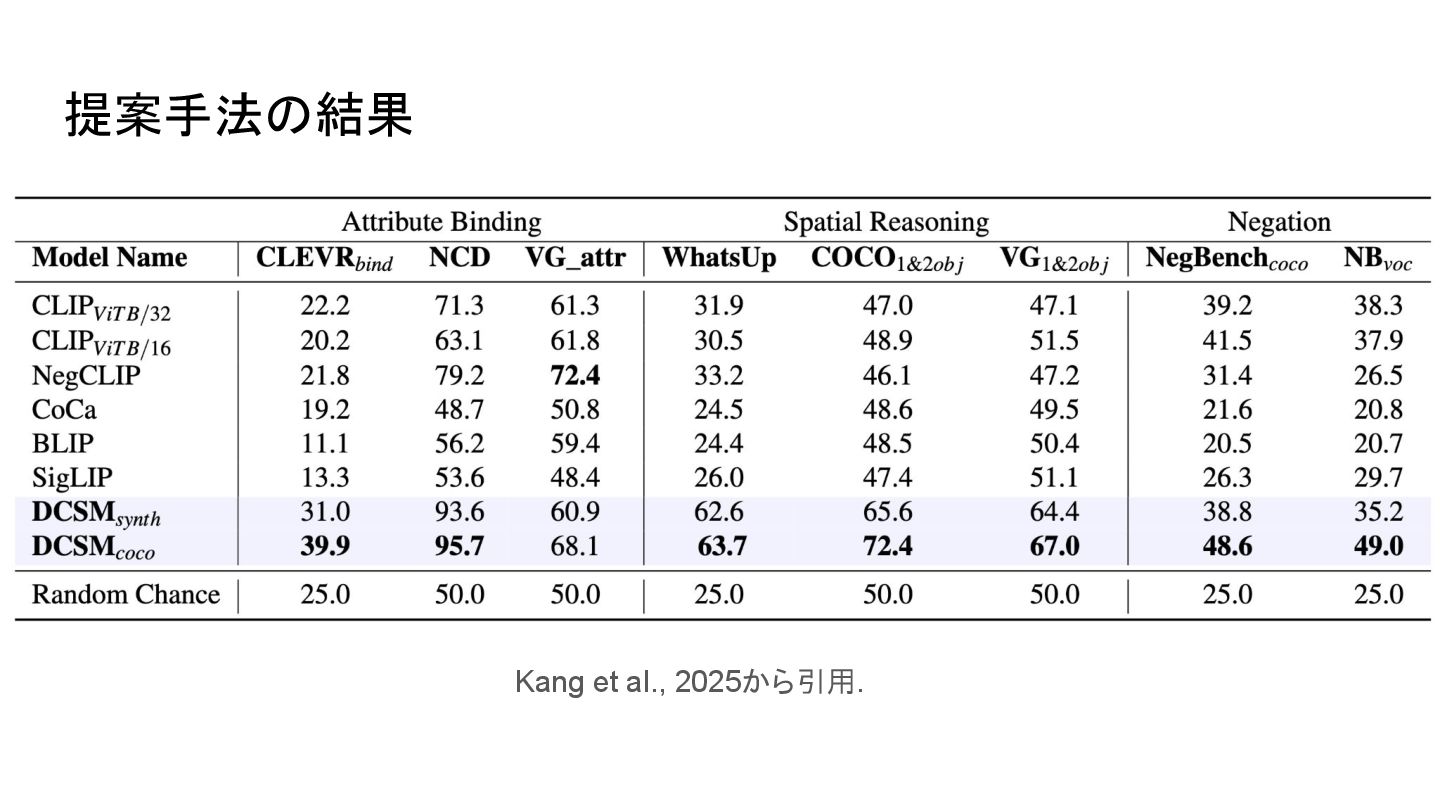{kind=link}
{kind=link}