on mobile apps : Air France, SeLoger, L'Oréal, Louis Vuitton, ING Direct, DirectAssurance, ... _type = < FactoricsProject > - Collect and store trafic data (anonymous) for all apps in Elasticsearch cluster - Serve and display data on web backoffice - Use collected data to create (re)targeted in-app or push notification campaigns _index = < MyStudioFactory >
Software - 7 nodes Lead Dev Elasticsearch - MyStudioFactory - 1 node (365 documents *7) - Integration and management of Exalead - Migration from Exalead to Elasticsearch - Migration from Mysql (as analytics server) to Elasticsearch - I proposed and built Elasticsearch stable cluster design for real time analytics (logstash, kafka...) - Push campaigns using ES to filter and get mobile device tokens [email protected]
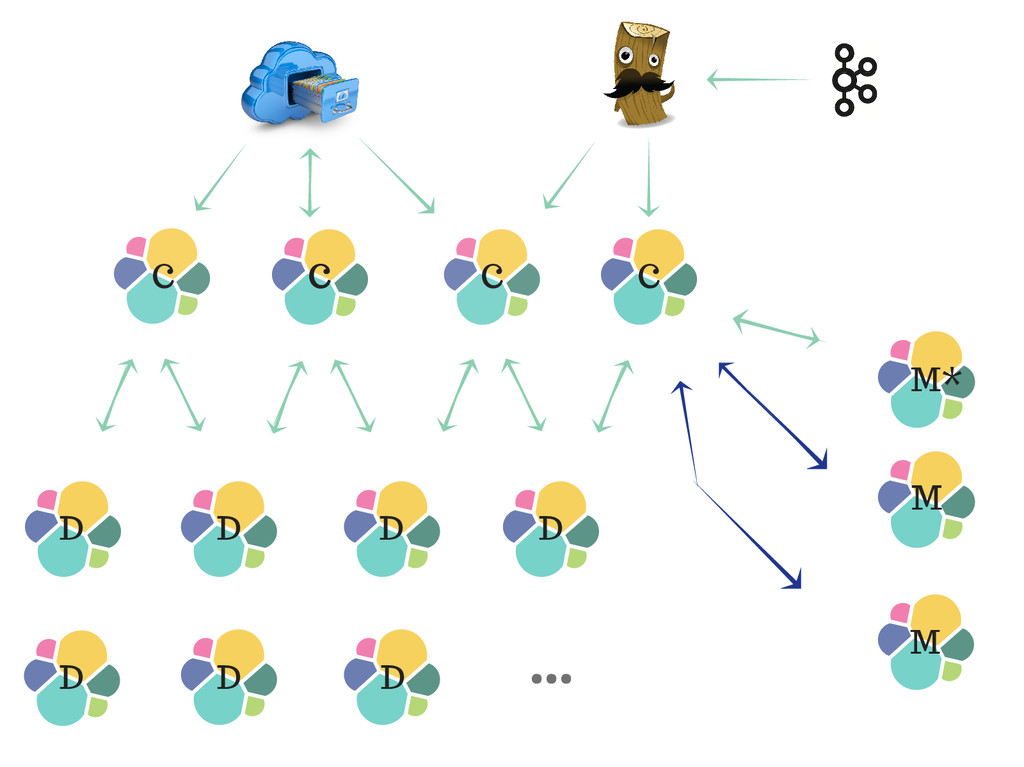
v e r 2 S e r v e r 3 C-D-(M) C-D-(M) C-D-M* C = Client D = Data M* = elected Master M = eligible as Master for server 1, 2 and 3 : CPU : 10 physical cores @ 2.80GHz RAM : 256GB or more... Disques : SSD 300GB or more...
To avoid this we have to change the infrastructure & requests, to keep our forum on Earth - Increase in garbage collection activity causing increased CPU usage
several seconds and our node was the master, a new election needs to happen, and the same issue can happen immediately after on the newly elected master, this could lead to a lot of instability in the cluster *even if it is not the master node that goes down, the rebalancing could take time and make your cluster sweat.
collect, and this can cause cluster instability. ... Divide and conquer - don’t Cross 32 GB limit for heap memory! - set cluster.routing.allocation.same_shard.host
Master node : Data nodes : - they know where data is stored and can query the right shards directly and merge the results back - it is the source of truth of the cluster and manages the cluster state - the only node type who stores data, they are used for both indexing and search *D'ont use master as a client, that can result in unstable state after big aggregations, heavy sorting/scripts... - they keep data nodes protected behind a firewall with only client nodes being allowed to talk to them
to 2, the cluster will still be able to work in case of a loss of one of the master nodes - Leave half of the system's memory for the filesystem cache - Set small heap size (eg. 1GB might be enough) for dedicated master nodes so that they don't suffer from garbage collection pauses. - If HTTP module is not disabled in the master eligible nodes, they can also serve as result servers, collect shard responses from other nodes for sending the merge result back to clients, without having to search or index
so that the hardware handling it will cope. There is no technical limit on the size of a shard, there is a limit to how big a shard can be with respect to your hardware - In our example we are going to keep each shard's size between 1 & 4GB, this allow's us to have fast queries and quickly resharding after restart or node goes down - If the shards grow too big, you have the option of rebuilding the entire Elasticsearch index with more shards, to scale out horizontally or split your index (per time period, per user...) Attention, once you're dealing with too many shards, the benefits of distributing the data gets pitted against the cost of coordinating between all of them, and it incurs a significant cost.
aggregations & scripts, and can take a lot of RAM so it makes sense to disable field data loading on fields that don’t need it, for example those that are used for full-text search only - The results of each request is cached and is reused for future requests improving query performance, but building up and evicting filters over and over again for a continuous time period can induce to some very long garbage collections - But in Elasticsearch 2.0 filter caching changed, and it keeps track of the 256 most recently used filters, and only caches those that appear 5 times or more, ES 2.0 prefers to be sure filters are reused before caching them - If there are filters that you do not reuse, turn off caching explicitly
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}