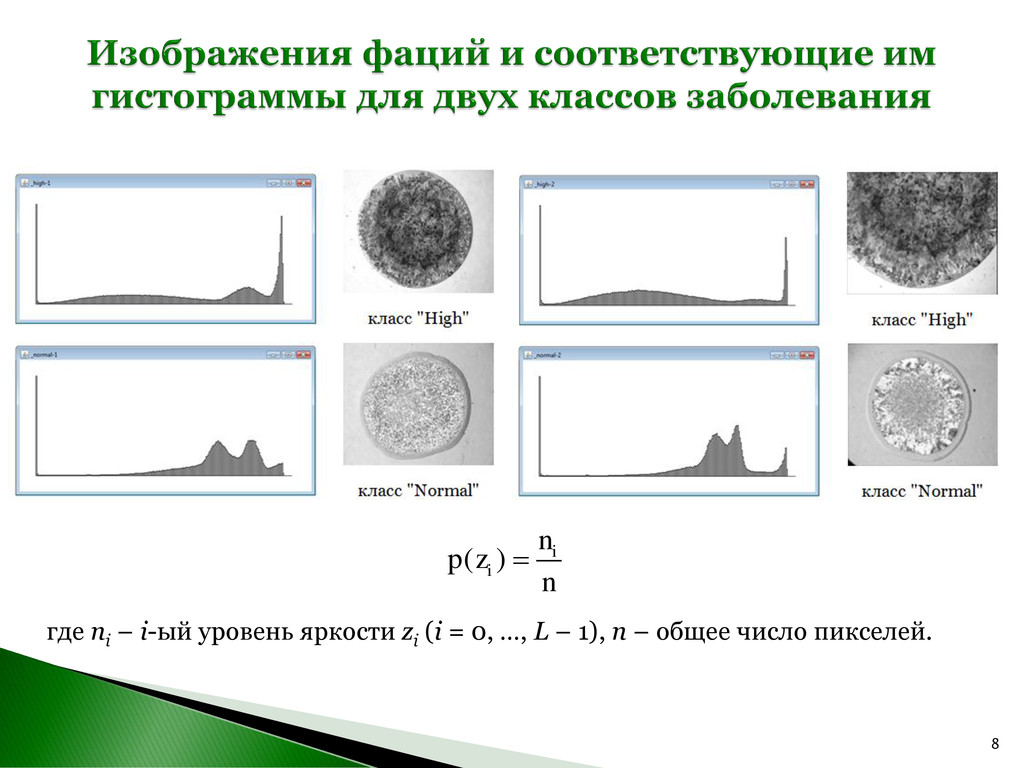
компьютерной обработки изображений к задаче диагностики мочекаменной болезни. Используемый подход основан на исследовании изображений дегидратированных образцов биологической жидкости пациентов – фаций. В первой части работы на основе статистического подхода для каждого снимка фации был сформирован вектор признаков. Для классификации изображений применялся подход, основанный на измерении ближайших расстояний между образцами. Во второй части рассматривается применение алгоритма K-means для разделения изображений фаций на две группы: снимков, принадлежащих пациентам с низкой и высокой степенями камнеобразования.
равно сумме произведений значений zi на соответствующие им вероятности p(zi ): 1 0 ( ) L i i i m z p z x2 – дескриптор относительной гладкости: 1 2 2 0 ( ) ( ) ( ) L i i i z z m p z x3 – однородность: 1 2 0 ( ) L i i U p z
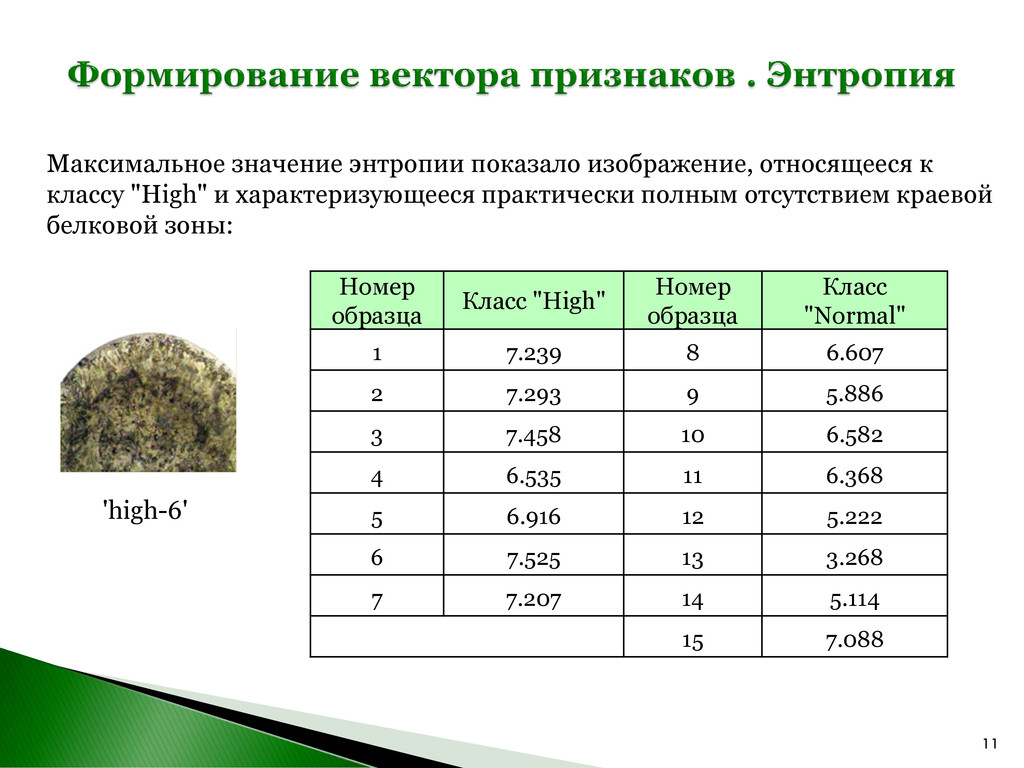
изображения, имеющего p(zi ) = const для всех значений zi , энтропия будет принимать наибольшее значение. Вид фации мочи: (слева) – при отсутствии процесса камнеобразования, (справа) – при наличии камнеобразования. 1 2 0 ( )log ( ) L i i i e p z p z
где r – отношение, в котором находятся пиксели i и j: x5 – максимум вероятности: x6 – однородность для матрицы Cr : x7 – средняя энтропия: max , max( ) ij i j p c 1 1 2 0 0 L L c ij i j U c 2 , : 1 ( , ) i j r i j z z r p z z s C 1 1 2 0 0 log L L c ij ij i j e c c
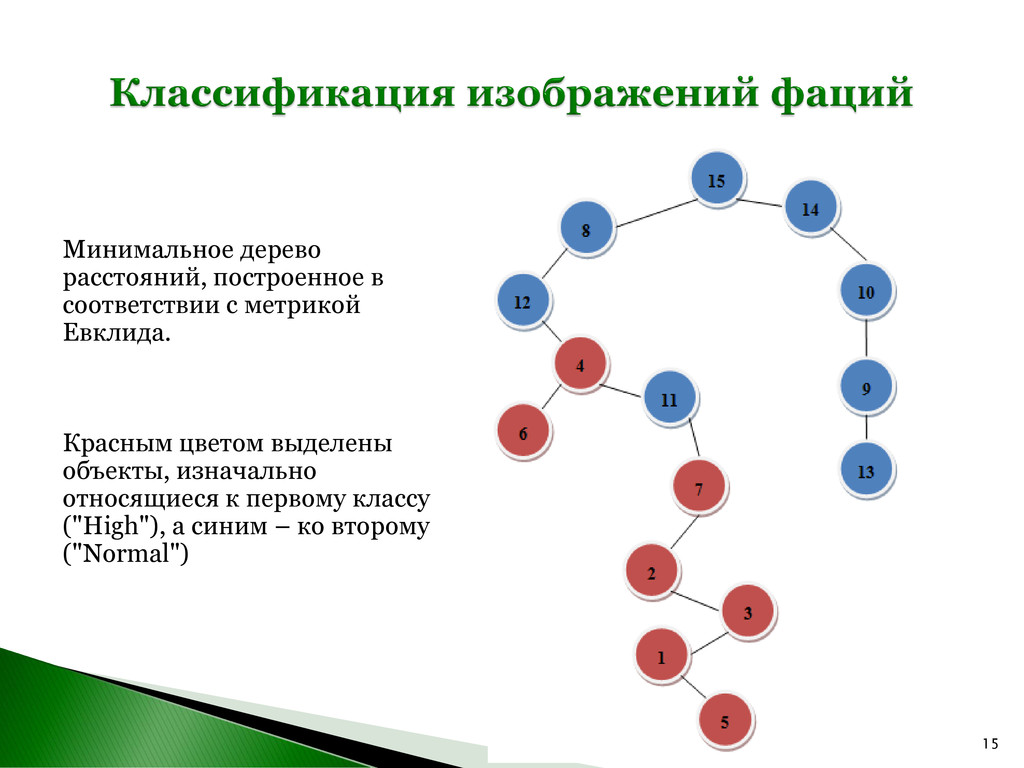
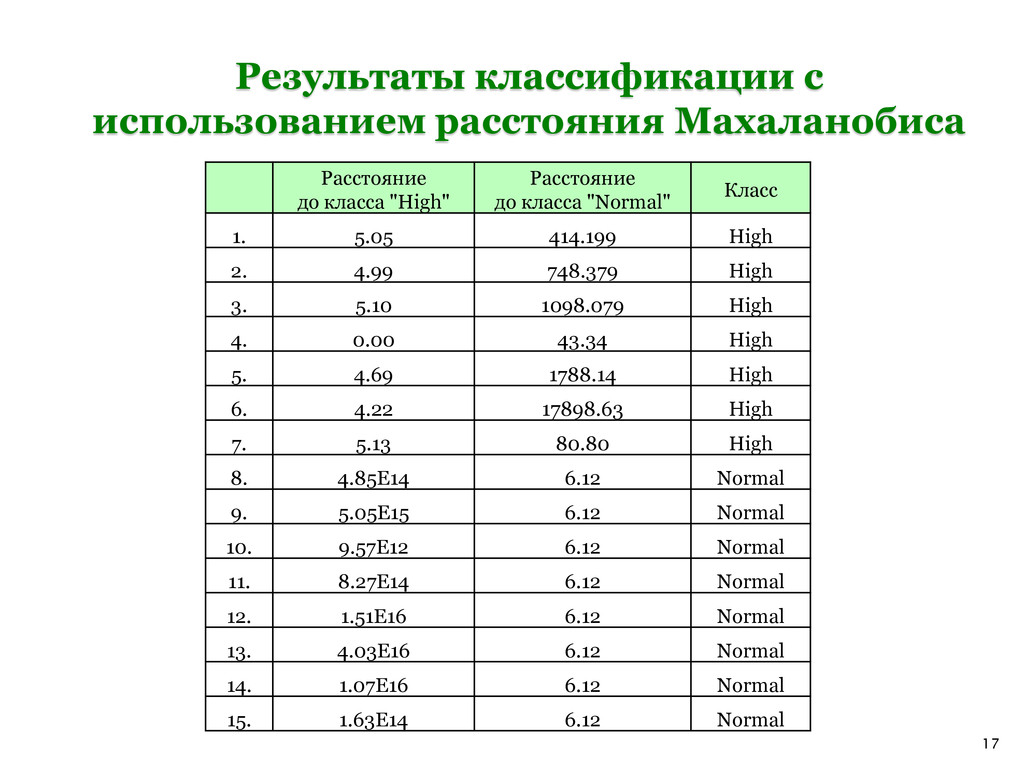
из классов, используя метрики Евклида и Махаланобиса: 1. Метрика Евклида. Нахождение минимального покрывающего дерева Расстояние Евклида между двумя точками (x1 , x2 , …, xn )T и (y1 , y2 ,, …, yn )T вычисляется по следующей формуле: На основе таблицы расстояний между имеющимися образцами фаций построим минимальное покрывающее дерево, используя алгоритм Краскала. 2 2 1 1 ( ) ( ) ( ) ( ) T E n n d x y x y x y x y
метрики Евклида, расстояние Махаланобиса учитывает корреляцию между компонентами векторов (признаками) и определяется по следующей формуле: где C – ковариационная матрица, составленная из попарных ковариаций элементов векторов (x1 , x2 , …, xn )T и (y1 , y2 ,, …, yn )T . Данная матрица представляет собой математическое ожидание произведения центрированных случайных величин: 1 ( ) ( ) T M d x y C x y cov( , ) ( )( ) C x y M x Mx y My
"High" Расстояние до класса "Normal" Класс 1. 5.05 414.199 High 2. 4.99 748.379 High 3. 5.10 1098.079 High 4. 0.00 43.34 High 5. 4.69 1788.14 High 6. 4.22 17898.63 High 7. 5.13 80.80 High 8. 4.85E14 6.12 Normal 9. 5.05E15 6.12 Normal 10. 9.57E12 6.12 Normal 11. 8.27E14 6.12 Normal 12. 1.51E16 6.12 Normal 13. 4.03E16 6.12 Normal 14. 1.07E16 6.12 Normal 15. 1.63E14 6.12 Normal
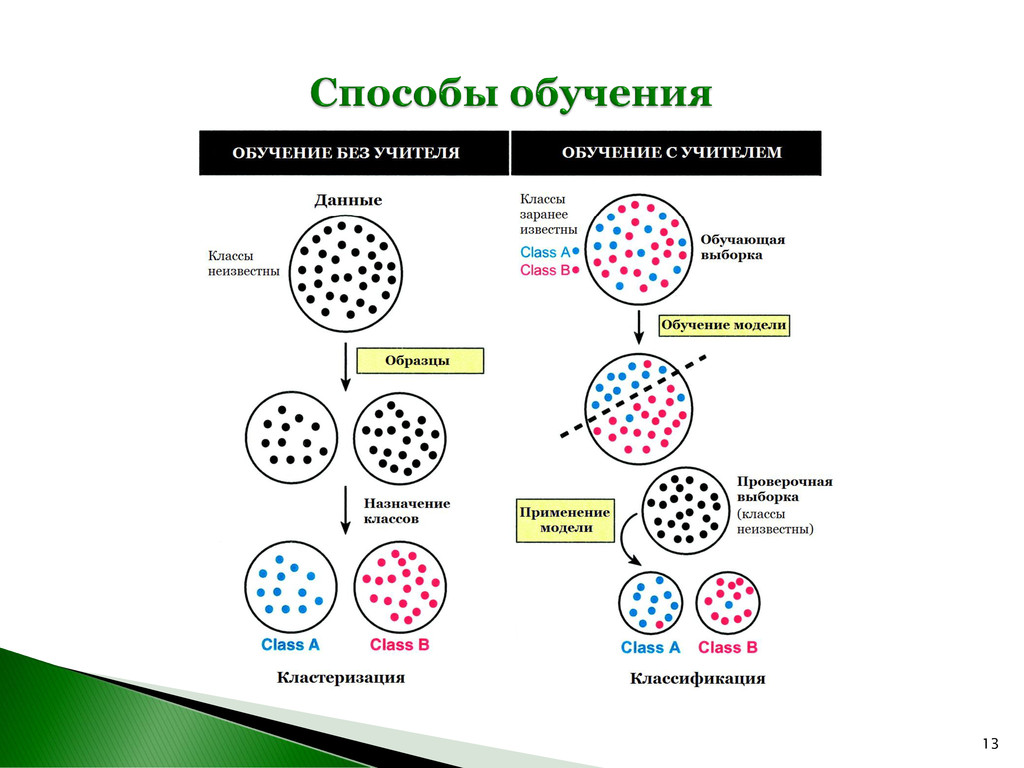
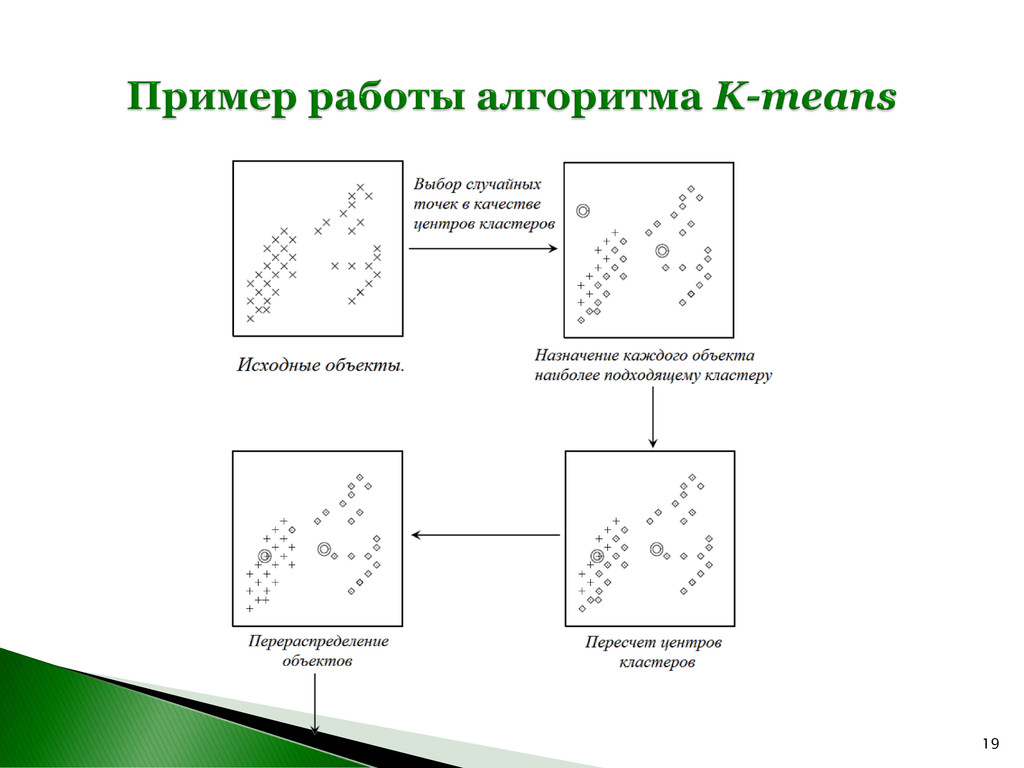
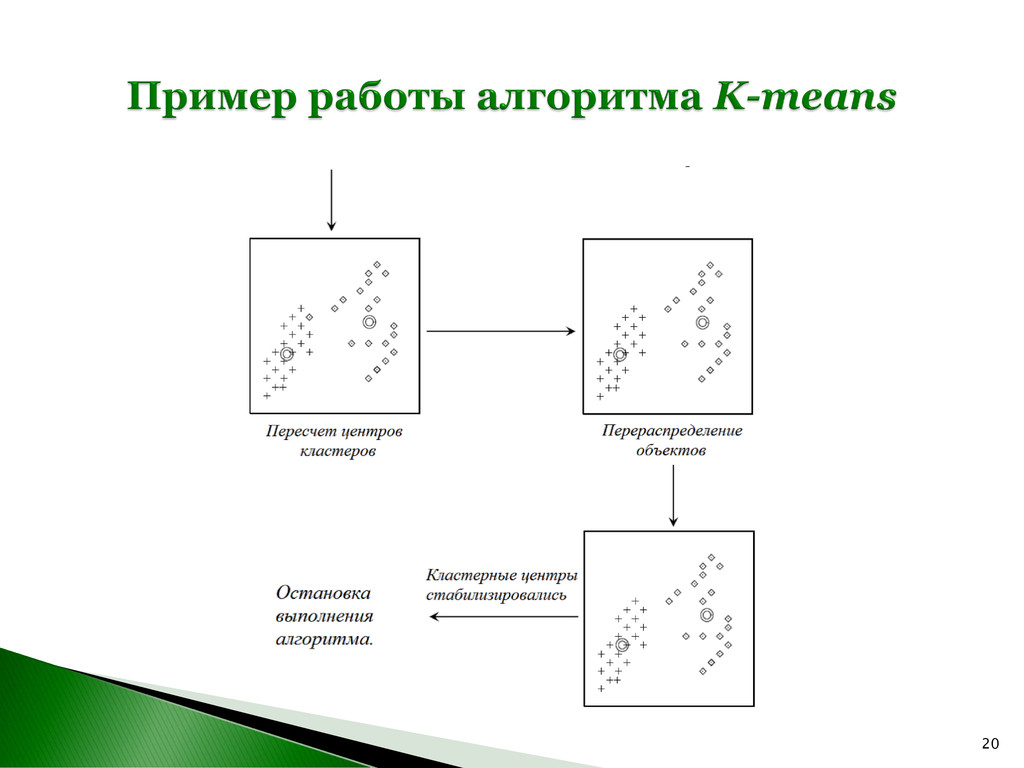
N объектов на K классов, в которых каждый из объектов относится к определенному классу исходя их близости к центру кластера. Центр кластера – математическое ожидание μi координат (признаков) всех объектов, входящих в рассматриваемый кластер. Обозначим множество искомых классов как S = {S1 , S2 , …, SK }, (K ≤ N). Шаг 1. Назначение объекта наиболее подходящему (похожему) кластеру. Шаг 2. Пересчет кластерных центров. j i j S i i S x x μ * 1 argmin ( , ) j i K j i S i S S d x x μ
изображений образцов биологической жидкости путем выявления статистических признаков. Предложен алгоритм отделения пикселей на изображении, лежащих внутри фации, от пикселей, относящихся к предметному столику микроскопа, на котором оператор размещает фацию для получения снимка. Приведено решение задачи классификации полученных характеризующих векторов. В рамках данной задачи исследована эффективность применения метрик Евклида и Махаланобиса, а также рассмотрено применение минимального дерева расстояний для решения задачи кластеризации. Во второй части работы было предложено применение алгоритма K-means для разделения исходных снимков на два класса: снимки, относящиеся к высокой и низкой степеням заболевания.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}