(МГУА) восстанавливает зависимость между входными и выходной переменными по выборкам наблюдений. МГУА был предложен Алексеем Григорьевичем Ивахненко в конце 60-х годов и в настоящее время рассматривается как один из разделов прикладного статистического анализа. Ивахненко А.Г. (1913-2007)
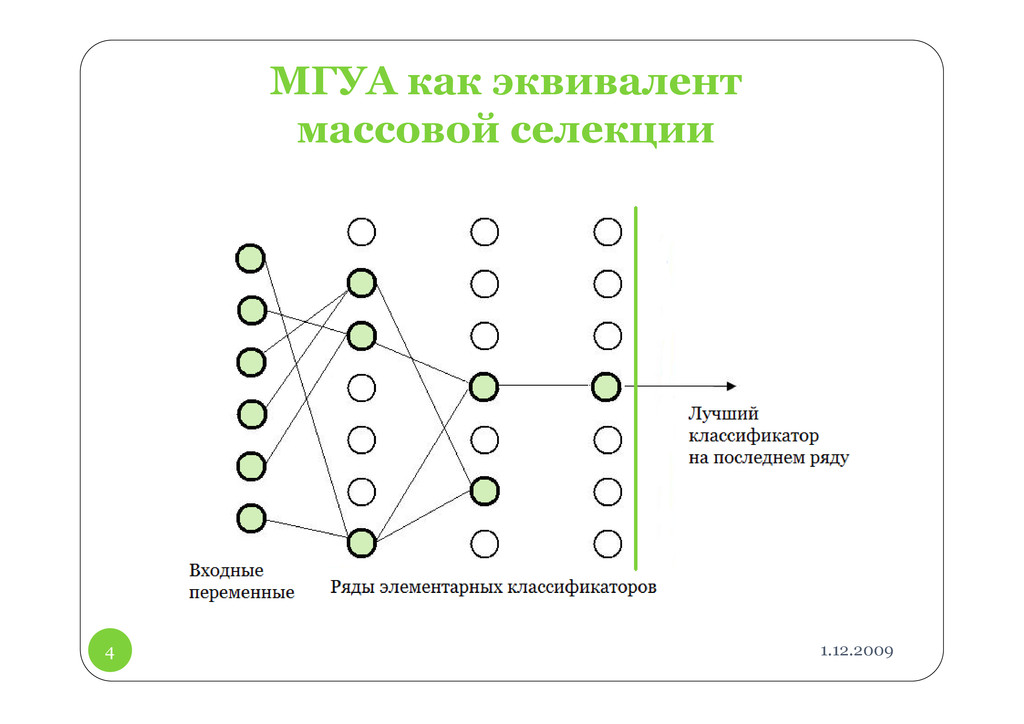
селекции, используемой в агротехнической практике. Принцип селекции в биологии обеспечивает постепенное изменение вида, генетически обусловленное и адекватное внешнему миру.
каждый из которых характеризуется вектором признаков и номером класса Функция, аппроксимирующая зависимость выходной величины от входных переменных называется «полным описанием объекта» и представляется в виде полинома:
основе исходных данных строятся частные описания от всех парных комбинаций исходных аргументов: – входной вектор; – вектор полиномиальных коэффициентов. Уравнения для «частных» описаний первого ряда имеют вид:
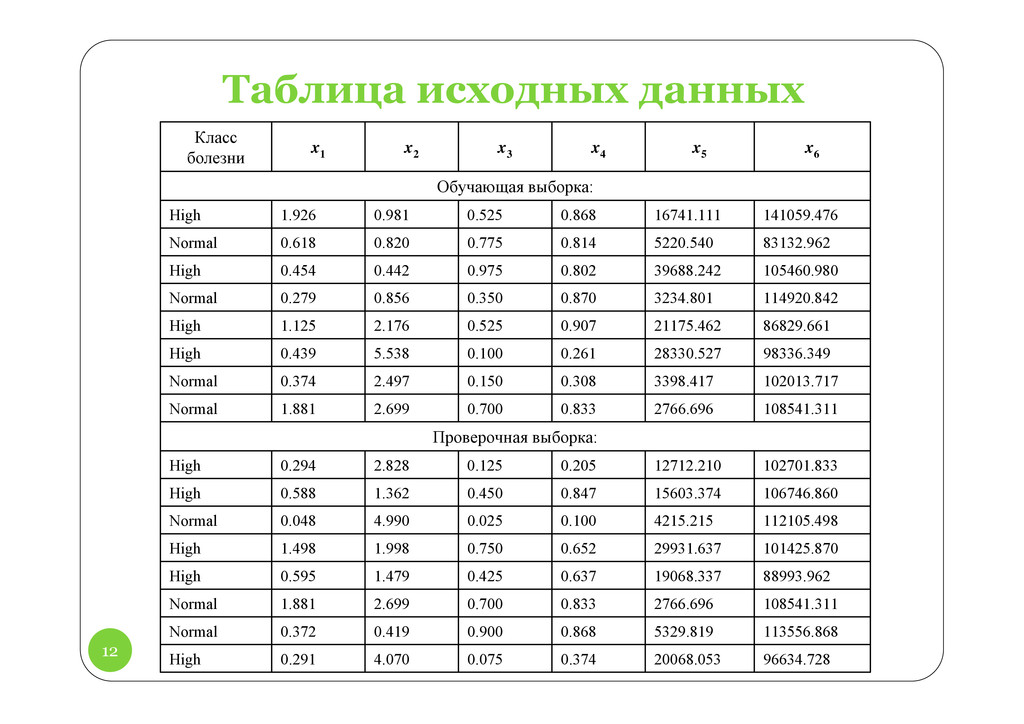
описания определяются по методу наименьших квадратов на образцах из обучающей выборки: где – целевой вектор желаемых выходов, соответствующий образцам из обучающей выборки.
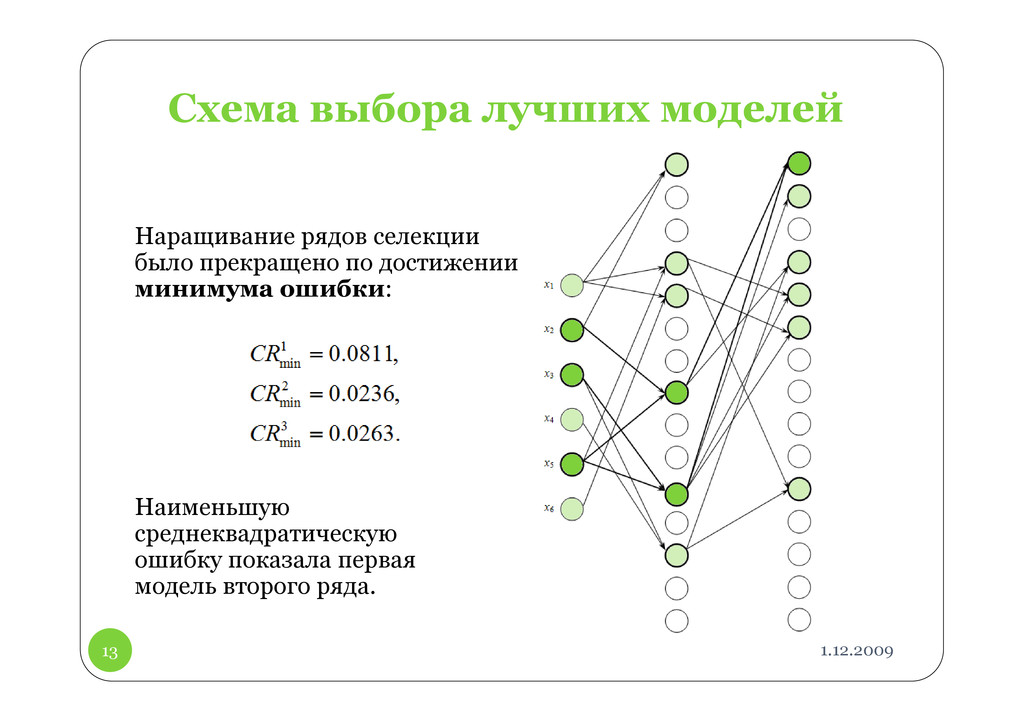
каждом ряду r алгоритма вычисляются ошибки, составляющие отклонение выхода полученной функции от значений эталонного вектора: Ошибку ряда составляет наименьшая ошибка по всем частным моделям:
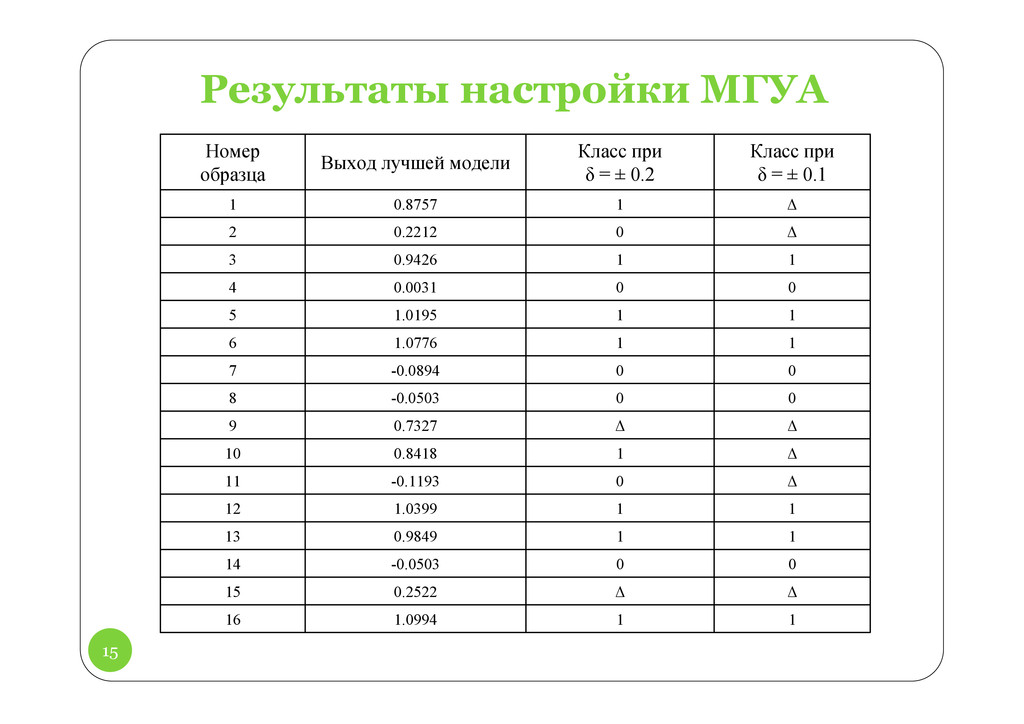
1 – ошибка на точках проверочной выборки имеет минимум, который можно использовать для выбора оптимальной модели; 2 – ошибка на проверочной выборке падает до нуля.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}