HBaseCon 2015
May 7
San Francisco
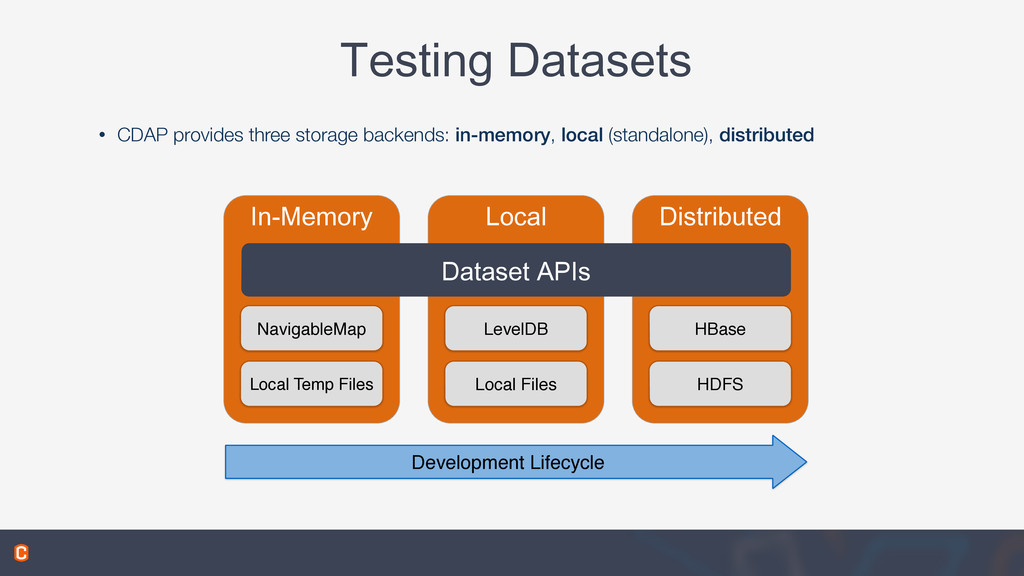
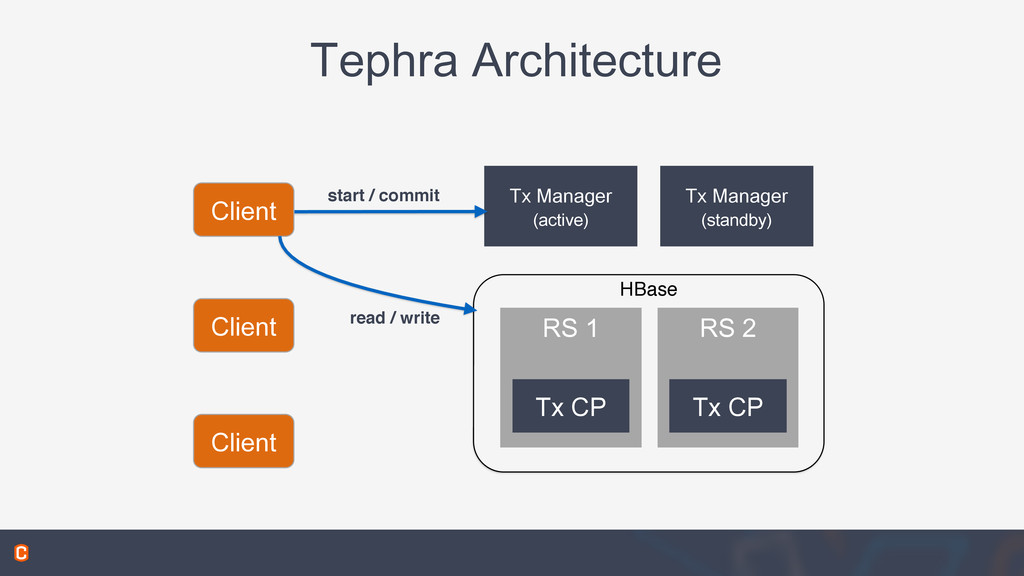
This talk covered Datasets, part of the open source Cask Data Application Platform (CDAP), which provide reusable implementations of common data access patterns. You also learn how Datasets provide a set of common services that extend the capabilities of HBase: global transactions for multi-row or multi-table updates, read-less increments for write-optimized counters, and support for combined batch and real-time access.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}