Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
計算量の話
Search
Catupper
September 16, 2013
1.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
計算量の話
競プロの第一歩
Catupper
September 16, 2013
More Decks by Catupper
See All by Catupper
ants' roots
catupper
1
2.6k
Trianguler
catupper
0
210
sort conference
catupper
2
120
Graph is Fun
catupper
0
170
About累積和
catupper
0
1.6k
For You
catupper
1
170
Featured
See All Featured
Context Engineering - Making Every Token Count
addyosmani
9
1k
Bash Introduction
62gerente
615
220k
Designing for Timeless Needs
cassininazir
1
370
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Everyday Curiosity
cassininazir
0
260
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
Transcript
計算量の話
計算量とは • ある問題の答えを出すためにどれくらい計算 を行うか • O(計算量)という表記をする – O(100,000), O(N), O(log
N) – O(2^N), O(1), O(Nα(N))
例 • 問:1 ~ Nまでの整数の総和を求めよ – 普通に計算する → N-1回足し算 →
O(N-1) – 公式を使う → 足し算と掛け算と割り算 → O(3) • 計算の仕方によって計算量が違うことがある
いくつかのルール • O記法の中身は一番大きな規模だけ残す • 係数は1にする • 例 – O(N-1) →
O(N) – O(4N^2 + 2N) → O(N^2) – O(N^2 + M^2) → NとMが独立なのでこれ以上無理 – O(2^N + N^2) → O(2^N) – O(3) → O(1)
なぜか • 中の変数が非常に大きな値になった時のことを考える • O(5N^2 + 100N + 4)の場合 –
N = 1 → 109 – N = 100→ 60004 – N = 10000 → 501000004 – N = 100000000 → 50000010000000004 • ほとんどO(5N^2)と変わらなくなる • O(N^2)との相対誤差は常にたったの5だから無視できる
演習:素数判定 ある整数Nが素数か判定するアルゴリズムを考えてそれ の計算量を答えよ – 高速じゃなくてもOKです – ちなみに論理的に最速なのはO((log N)^7.5)くらいの やつです •
AKS素数判定法って言います • おもいつくわけがない
予想される解答 • N未満の自然数全てについて割れるかどうか試す – O(N) – おそい • √N未満の自然数全てについて割れるかどうか試す –
O(√N) – これが思いつけば十分
そんなのありかよ • 素数表をあらかじめ用意しておく – O(1) – 柔軟な発想である • しかし欠点がある –
素数表は非常に大きくなる – 少なくとも予想されるNより小さい整数について知っ て居る必要がある – ようは覚えるためにメモリをめっちゃ食う
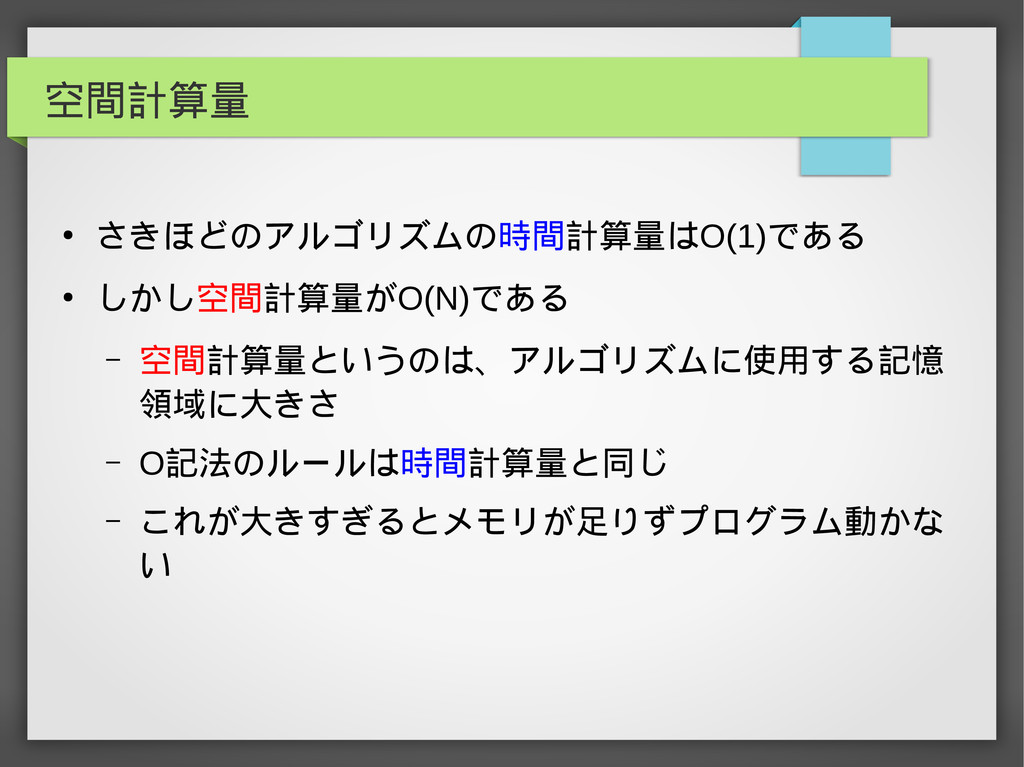
空間計算量 • さきほどのアルゴリズムの時間計算量はO(1)である • しかし空間計算量がO(N)である – 空間計算量というのは、アルゴリズムに使用する記憶 領域に大きさ – O記法のルールは時間計算量と同じ
– これが大きすぎるとメモリが足りずプログラム動かな い
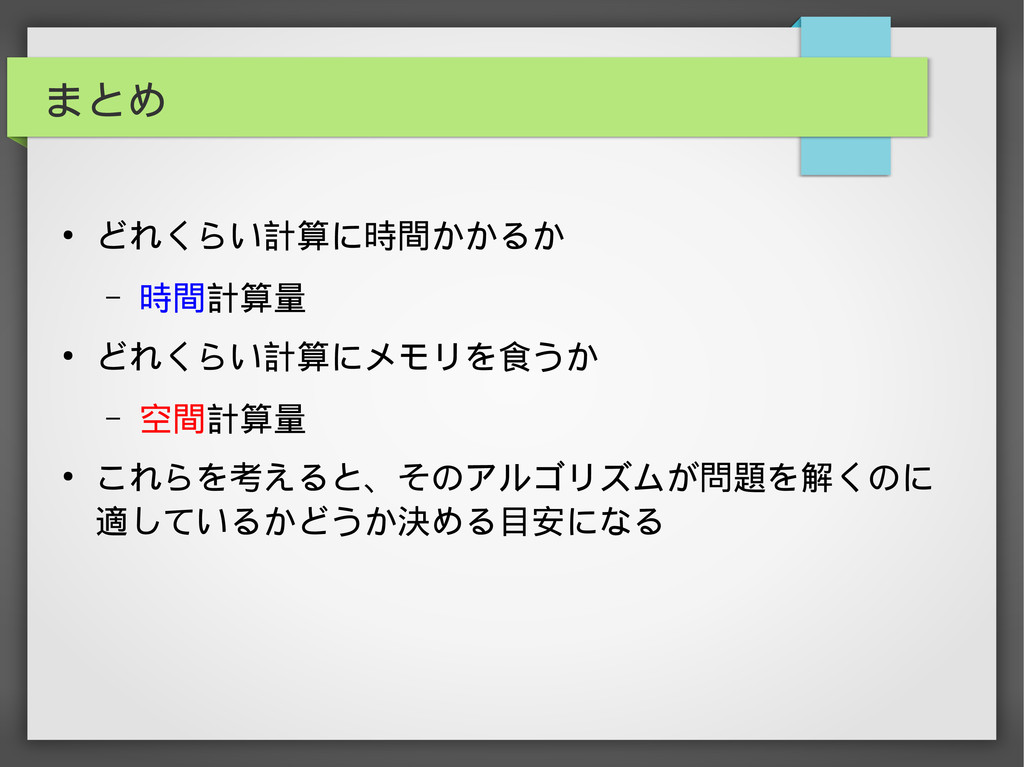
まとめ • どれくらい計算に時間かかるか – 時間計算量 • どれくらい計算にメモリを食うか – 空間計算量 •
これらを考えると、そのアルゴリズムが問題を解くのに 適しているかどうか決める目安になる
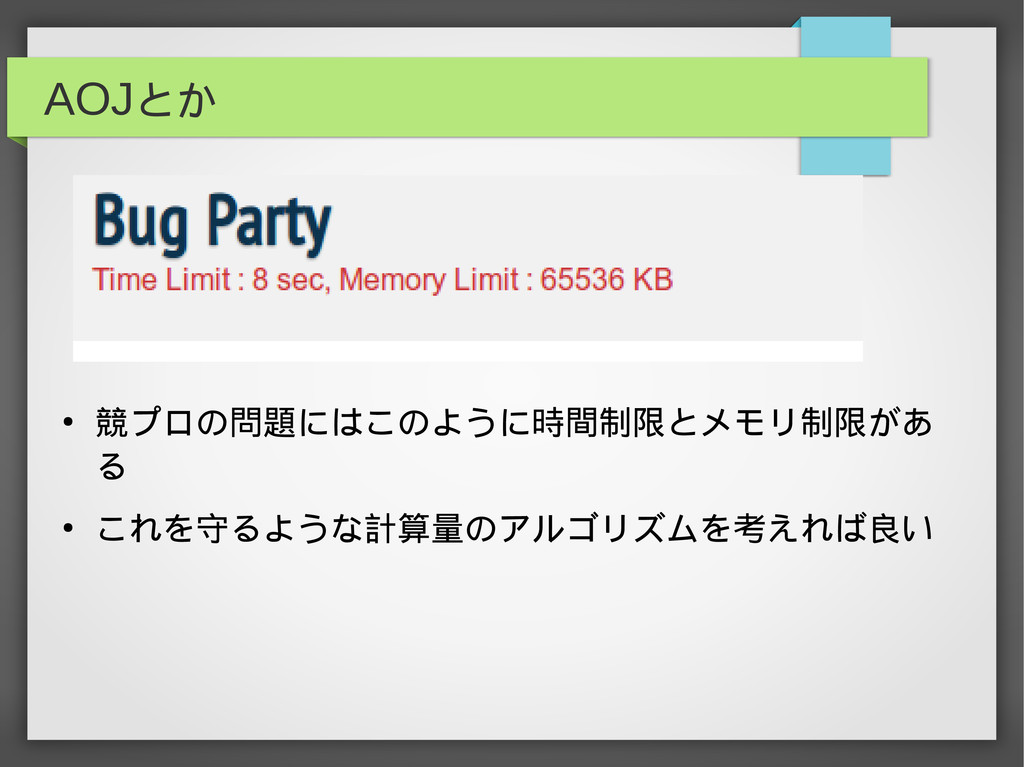
AOJとか • 競プロの問題にはこのように時間制限とメモリ制限があ る • これを守るような計算量のアルゴリズムを考えれば良い
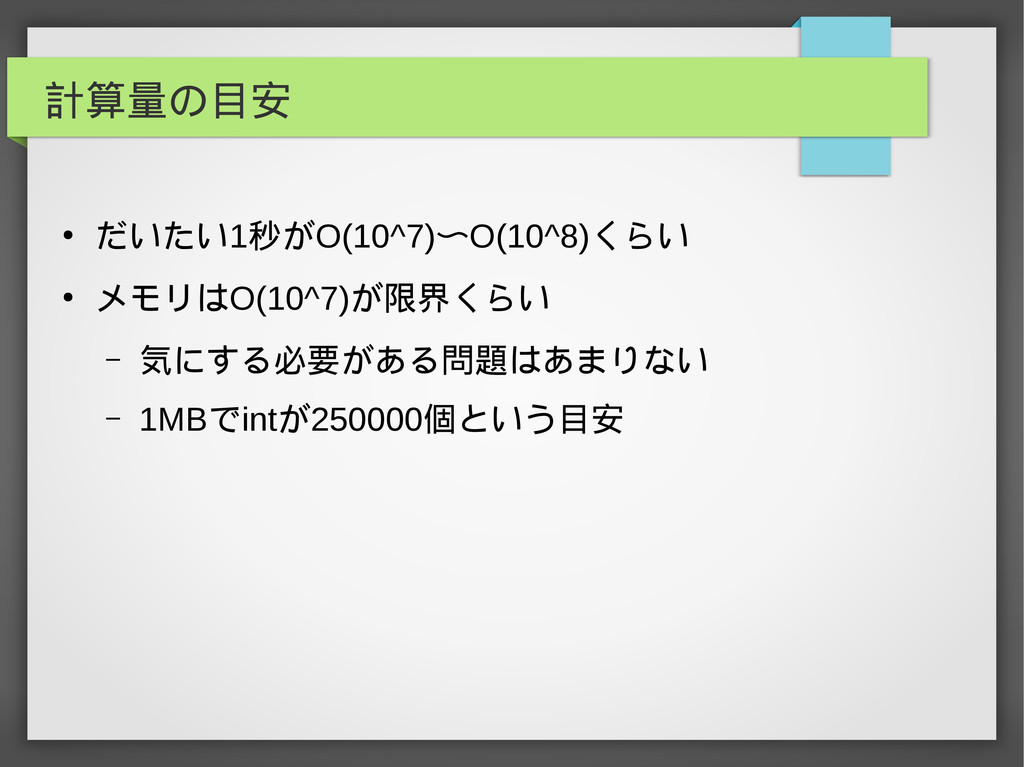
計算量の目安 • だいたい1秒がO(10^7)〜O(10^8)くらい • メモリはO(10^7)が限界くらい – 気にする必要がある問題はあまりない – 1MBでintが250000個という目安
計算量は一つの糸口 • 問題の変数の制約からアルゴリズムの計算量の見当がつ く – ↑だいたいO(NlogN)かなー
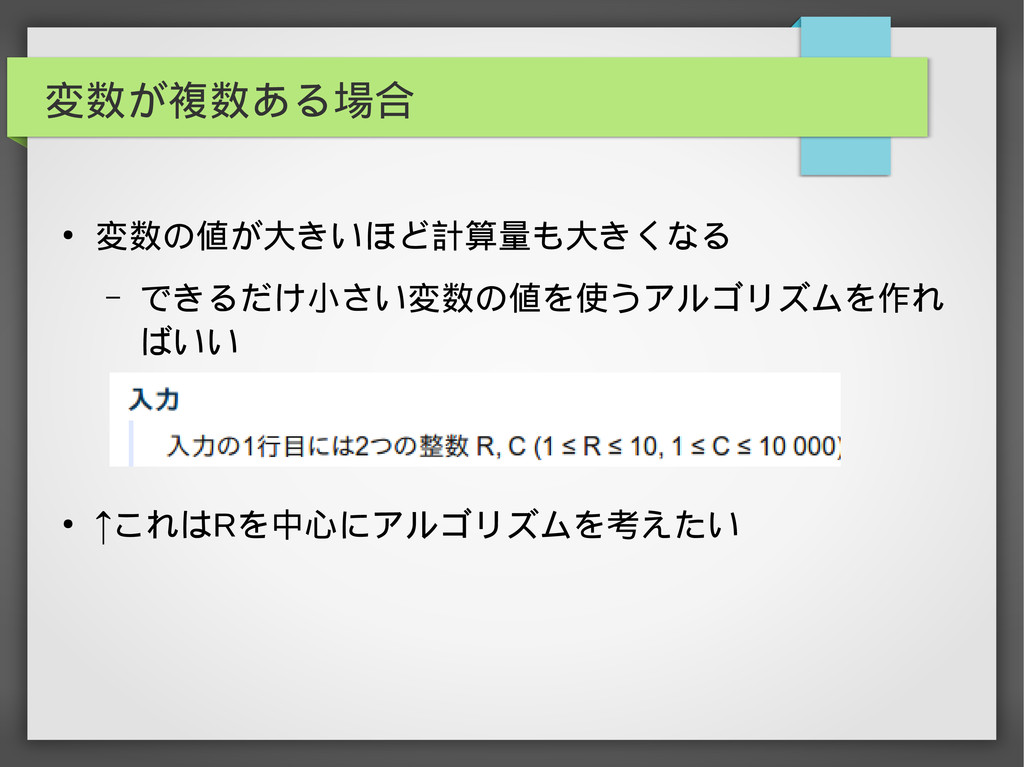
変数が複数ある場合 • 変数の値が大きいほど計算量も大きくなる – できるだけ小さい変数の値を使うアルゴリズムを作れ ばいい • ↑これはRを中心にアルゴリズムを考えたい
制限からの計算量予想 • N 10^6 → O(N) ≦ もしくは O(N log
N) • N 10^5 → O(N log N) ≦ もしくは O(N log^2 N) • N 3000 → O(N ^ 2) ≦ • N 500 → O(N ^ 3) ≦ の中でも早いもの • N 100 → O(N ^ 3) ≦ • N 50 → O(N ^ 5) ≦ くらいまでいける • N 20 → O(2 ^ N) ≦ もしくは O(N * 2 ^ N)
アルゴリズムのご紹介
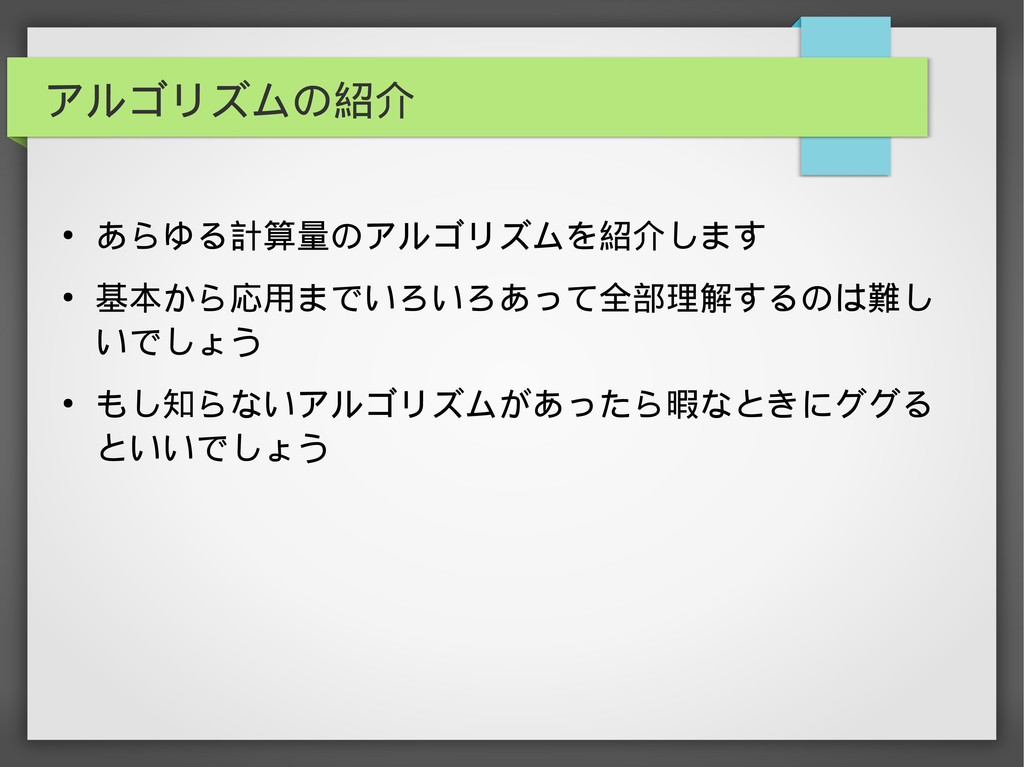
アルゴリズムの紹介 • あらゆる計算量のアルゴリズムを紹介します • 基本から応用までいろいろあって全部理解するのは難し いでしょう • もし知らないアルゴリズムがあったら暇なときにググる といいでしょう
O(N) • 貪欲法 – ただひたすらにminとかmaxとか条件に合うものを選 ぶアルゴリズム • しゃくとり法 – 左端と右端を決めてちょっとずつ右に動きながら適切
な範囲を決めるアルゴリズム • 木構造関係の前処理 – 深さ、部分木のサイズ、重心、DFS、BFS
O(N) • 累積和の前処理、いもす法の後処理 – ともに連続した区間の総和を扱うことで、連続した区 間に対するクエリを高速(だいたい定数)で処理する もの。総和をとったりする前処理や後処理がO(N) • エラトステネスのふるい –
素数表を作る – メビウス関数表も同時に作れる
O(N) • 1~Nまでの数字の逆元の取得 – inv[x] = -inv[MOD % x] *
(MOD / x); – という漸化式を使う方法 – 組み合わせ関係の式の前処理において多用 • aho corasick法による文字列探索 – 探索対象文字列から文字列群の各要素を検出するアル ゴリズム
O(N) • グラフの閉路判定 – 無向グラフの木状判定、有向グラフのDAG判定 – DFSするだけ • グラフの強連結成分分解 –
強連結成分とはその中でどの頂点対間にも両方向にパ スがある誘導グラフ – 強連結成分を圧縮するとDAGになる
O(N) • DAGのトポロジカルソート – 辺が全て小さい番号から大きい番号に伸びているよう に頂点を番号付けする – O(辺の数)です • DAGに変換した後にDP
– あらゆるDPはDAGの問題に変換可能です – 変換後の辺の数をNとするとそのDPはO(N)で溶ける 可能性が高いです
O(N^2) • 全頂点対の走査 – グラフを作る段階に行う、あらゆるアルゴリズム – 平面上の全頂点間の辺の列挙等 • ベルマンフォード法 –
単一始点最短経路を求めるアルゴリズム – 負の閉路があっても大丈夫 – 特殊な線形計画問題の双対である(牛ゲー)
O(N^3) • ワーシャルフロイド法 – 全点対間最短経路を求める方法 – 実装が非常に楽 しかも定数が軽い • 二部グラフの最大マッチング –
安定結婚問題みたいな奴 – 詳しくはマッチングでぐぐれ – O(V(V+E))だったりする
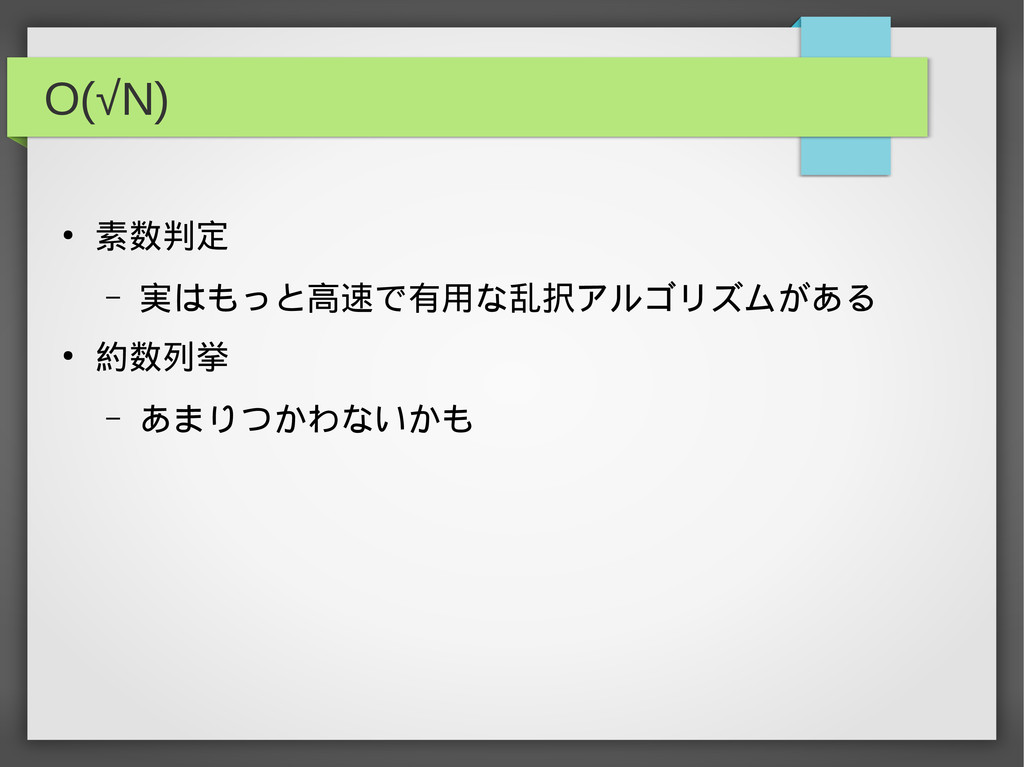
O(√N) • 素数判定 – 実はもっと高速で有用な乱択アルゴリズムがある • 約数列挙 – あまりつかわないかも
O(log N) • 二分探索 – 答えが探索範囲の中点についてどちら側にあるか調べ る方法を繰り返す探索方法 • ユークリッドの互除法 –
最大公約数をもとめたり、逆元を求めたりできる • 繰り返し2乗法 – X^NをO(log N)でもとめる – 行列に使えば、漸化式を高速に解いたりできる
O(log N) • std:set, std:map, std:priority_queueのクエリ – C++のライブラリから得られる便利なデータ構造 – 順序付き集合、辞書、順序付きキュー
• 平衡二分探索木のクエリ – 探索、質問、更新、追加、削除、併合、分割 – 右に行くほど実装が重い
O(NlogN) • ダイクストラ法 – 本当はO((辺の数 + 頂点の数) log 頂点の数) –
単一始点最短経路のアルゴリズム – 負閉路があると動かない • エンベロープによる走査 – 複数の一次式に対して、最小値や最大値をなぞる方法 – グラフの下端や上端をなぞる感じ
O(NlogN) • ソート – データを順序付きに並び替えること – 超頻出アルゴリズム • ダイクストラ法 –
本当はO((辺の数 + 頂点の数) log 頂点の数) – 単一始点最短経路のアルゴリズム – 負閉路があると動かない
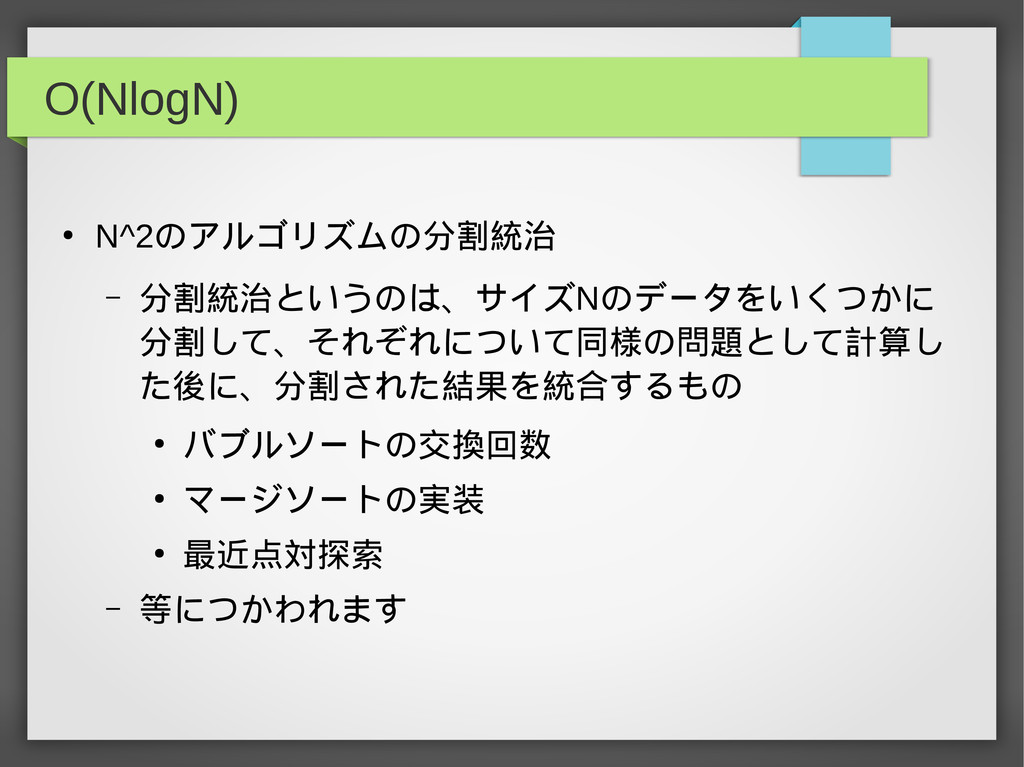
O(NlogN) • N^2のアルゴリズムの分割統治 – 分割統治というのは、サイズNのデータをいくつかに 分割して、それぞれについて同様の問題として計算し た後に、分割された結果を統合するもの • バブルソートの交換回数 •
マージソートの実装 • 最近点対探索 – 等につかわれます
O(NlogN) • ダブリングの初期化 – ランダムアクセスできない順序付きのものにたいして log(N)でアクセスするためのデータ構造 – 各ノードにたいして2^x個次を持つ • エンベロープによる走査
– 複数の一次式に対して、最小値や最大値をなぞる方法 – グラフの下端や上端をなぞる感じ
O(Nα(N)) • UnionFind – ばらばらの集合を統合する処理を高速にするアルゴリ ズム • ※αはアッカーマン関数の逆関数 – 詳しくは知る必要は全くない
– とりあえずすごく小さい値とだけ覚えておいて
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![O(N) • 1~Nまでの数字の逆元の取得 – inv[x] = -inv[MOD % x] *](https://files.speakerdeck.com/presentations/af623980011e0131d5db6e6f67efc930/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}