最先端NLP2022(2022/9/26-27開催)勉強会にて,発表に用いたスライドです.
・最先端NLP勉強会:https://sites.google.com/view/snlp-jp/home/2022?authuser=0
・論文情報
Title: DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings (NAACL 2022)
Authors: Yung-Sung Chuang, Rumen Dangovski, Hongyin Luo, Yang Zhang, Shiyu Chang, Marin Soljačić, Shang-Wen Li, Wen-tau Yih, Yoon Kim, James Glass
paper URL (OpenReview): https://openreview.net/forum?id=SzGgMLQfSb5
・発表者情報
東北大学 乾・坂口・徳久研究室
阿部 香央莉
{kind=link}
![• SimCSE [Gao+, 2021] より頑健な教師なし⽂表現学習の枠組みを 提案 • SimCSE: 最新のBERT系⽂表現モデルでとりあえずコレ,なモデル •](https://files.speakerdeck.com/presentations/55c2bb327ca14626bf9ecb45b56672eb/slide_1.jpg){kind=link}
{kind=link}
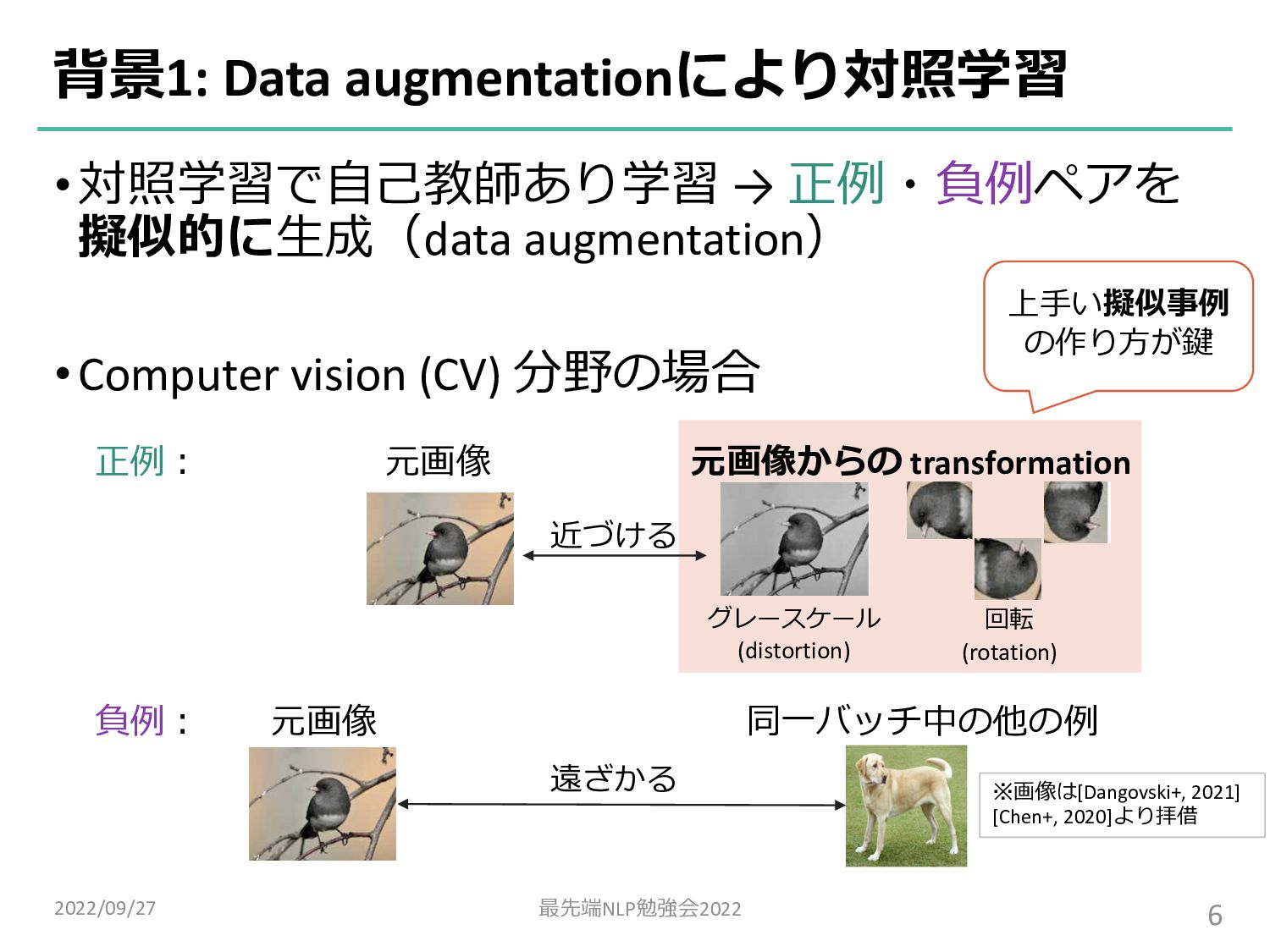
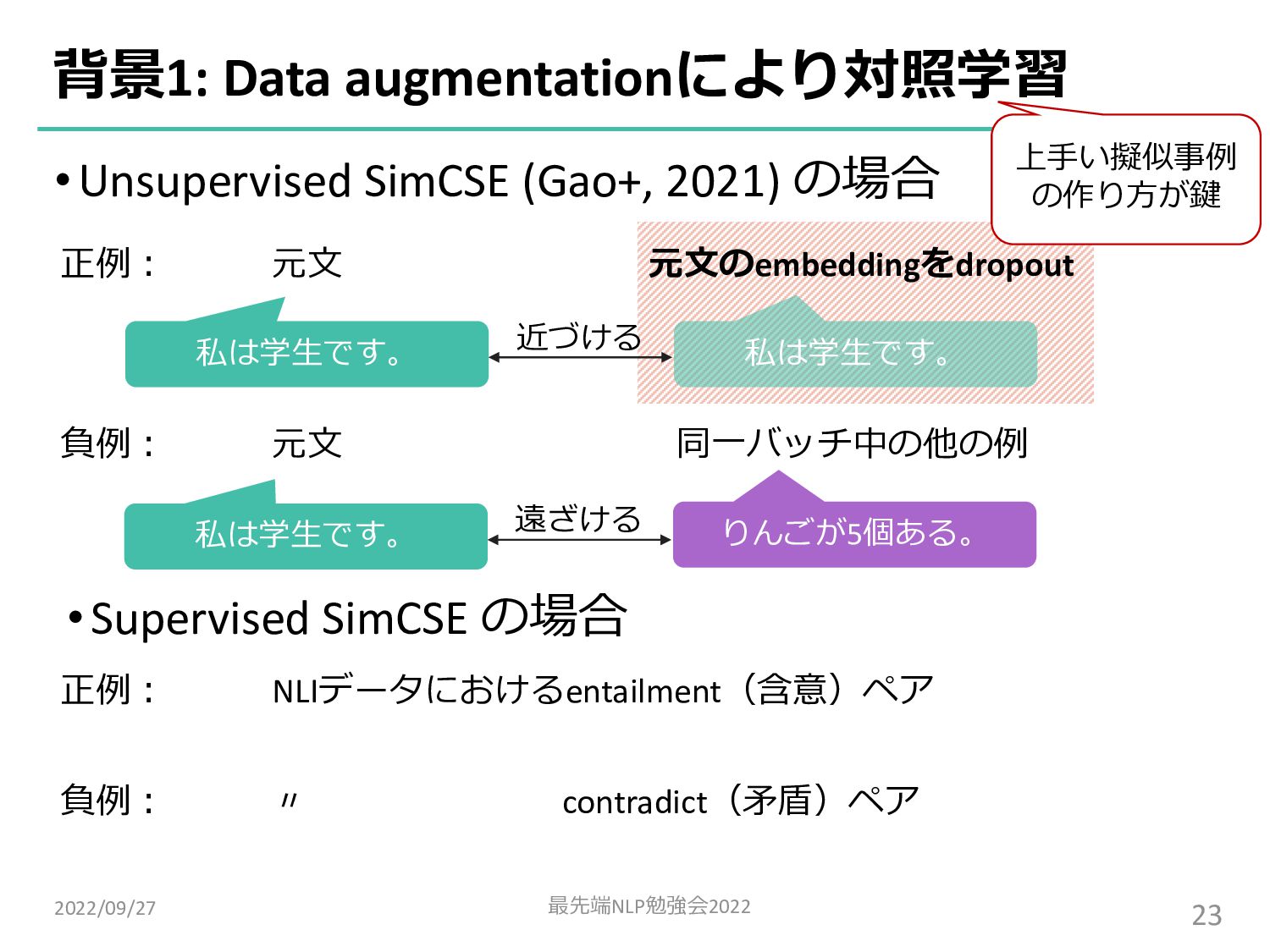
![•対照学習で⾃⼰教師あり学習 → 正例・負例ペアを 擬似的に⽣成(data augmentation) •Unsupervised SimCSE [Gao+, 2021] の場合](https://files.speakerdeck.com/presentations/55c2bb327ca14626bf9ecb45b56672eb/slide_3.jpg){kind=link}
![•対照学習で⾃⼰教師あり学習 → 正例・負例ペアを 擬似的に⽣成(data augmentation) •Unsupervised SimCSE [Gao+, 2021] の場合](https://files.speakerdeck.com/presentations/55c2bb327ca14626bf9ecb45b56672eb/slide_4.jpg){kind=link}
{kind=link}
![先⾏研究︓equivariant contrastive learning [Dangovski+, 2021] • 気持ち︓“正例” 扱いしていた擬似事例をより細かく識別しよう︕ • [Chen+,](https://files.speakerdeck.com/presentations/55c2bb327ca14626bf9ecb45b56672eb/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Ablation Study: Generatorのサイズ 2022/09/27 最先端NLP勉強会2022 18 ELECTRA [Clark+, 2020] :](https://files.speakerdeck.com/presentations/55c2bb327ca14626bf9ecb45b56672eb/slide_17.jpg){kind=link}
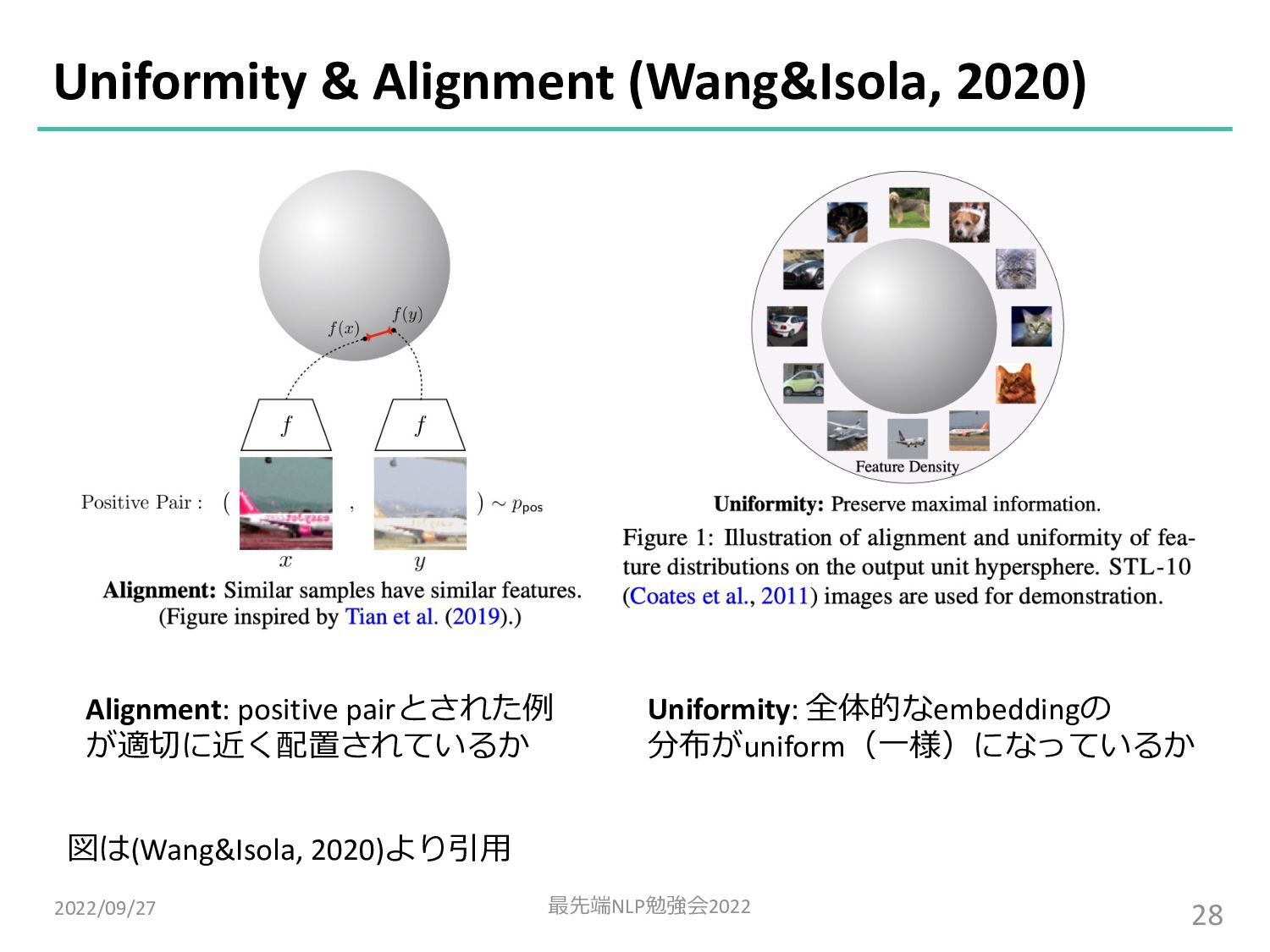
![Analysis: Uniformity & Alignment 2022/09/27 最先端NLP勉強会2022 19 SimCSEはUniformity,DiffCSEはAlignmentの観点でそれぞれ優れている [Wang&Isola, 2020]](https://files.speakerdeck.com/presentations/55c2bb327ca14626bf9ecb45b56672eb/slide_18.jpg){kind=link}
![Analysis: 出⼒される類似度の分布 2022/09/27 最先端NLP勉強会2022 20 DiffCSEの⽅が⾼い値に 寄っている → [Meng+, 2021]らが⾔及](https://files.speakerdeck.com/presentations/55c2bb327ca14626bf9ecb45b56672eb/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Ablation Study 3: [MASK]する割合・lossの重みλ 2022/09/27 最先端NLP勉強会2022 25 • [MASK]する割合は30%が最も良いが,⼤きな変化はない (個⼈的にはちょっと意外)](https://files.speakerdeck.com/presentations/55c2bb327ca14626bf9ecb45b56672eb/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}