最先端NLP2019(2019/09/27-28開催)勉強会にて,発表に用いたスライドです.
・最先端NLP勉強会:https://sites.google.com/view/snlp-jp/home/2019?authuser=0
・論文情報
Title: Empirical Linguistic Study of Sentence Embeddings (ACL2019)
Authors: Katarzyna Krasnowska-Kieraś, Alina Wróblewska
paper URL (ACL anthology): https://aclanthology.org/P19-1573/
・発表者情報
東北大学 乾研究室
阿部 香央莉
{kind=link}
![論⽂の概要 2019/9/28 2 Sentence Embeddings(⽂ベクトル)を獲得する ⼿法は様々に考案されている[Cer+, 2018][Pagliardini+, 2018] 例)](https://files.speakerdeck.com/presentations/aa37d36841b44d7db5ed0fce2536a7a3/slide_1.jpg){kind=link}
{kind=link}
![ 例えば︓英語 (English) vs. ポーランド語 (Polish) English︓語順の制限が⾮常に厳しい Polish︓⽇本語と同様、語順の制限が緩い [仮説] 同じ⼿法で⽂ベクトルを作成しても、](https://files.speakerdeck.com/presentations/aa37d36841b44d7db5ed0fce2536a7a3/slide_3.jpg){kind=link}
![実験で扱う⽂ベクトル⼿法たち FastText BERT COMBO [Rybak and Wróblewska, 2018] Sent2Vec (NS)](https://files.speakerdeck.com/presentations/aa37d36841b44d7db5ed0fce2536a7a3/slide_4.jpg){kind=link}
![Probingタスク [Conneau+, 2018]らのProbing Taskを、 UD treebankのスキーマに準じて改変 & データ作成 データはParalera(En, Poのパラレル)コーパスを使⽤[Pęzik,](https://files.speakerdeck.com/presentations/aa37d36841b44d7db5ed0fce2536a7a3/slide_5.jpg){kind=link}
![2つの下流タスク [懸念] Probingタスクだけでは、⽂ベクトル全体 のパフォーマンスを評価することができない → 下流タスクの精度も測ろう︕ Relatedness &](https://files.speakerdeck.com/presentations/aa37d36841b44d7db5ed0fce2536a7a3/slide_6.jpg){kind=link}
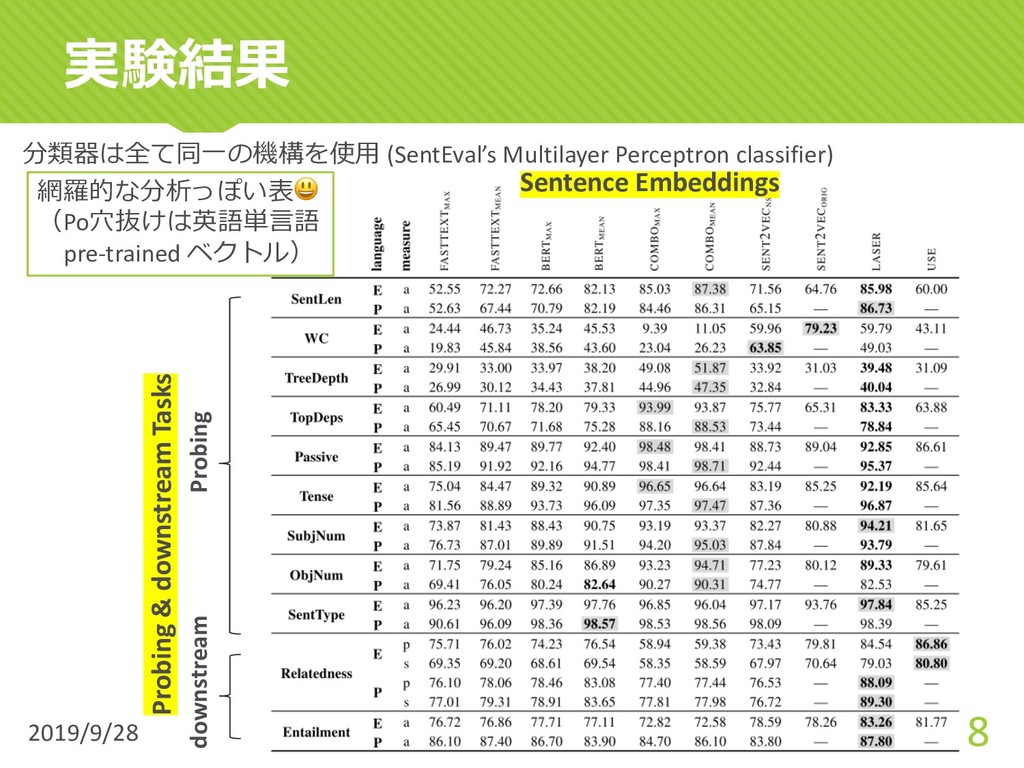{kind=link}
{kind=link}
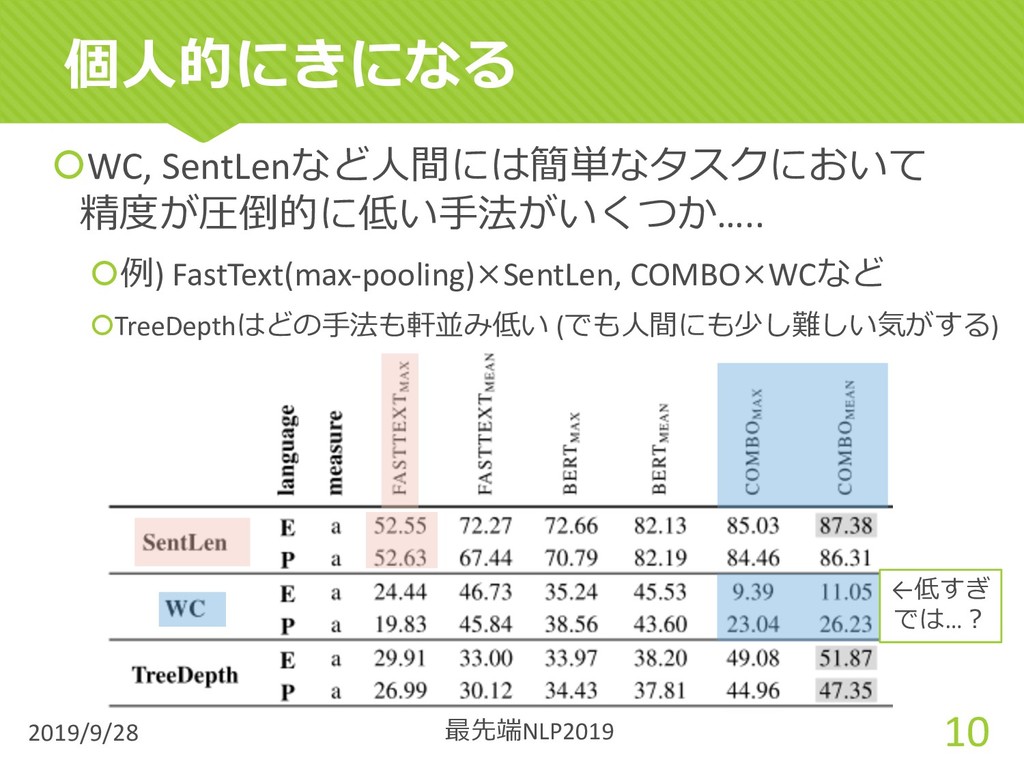{kind=link}
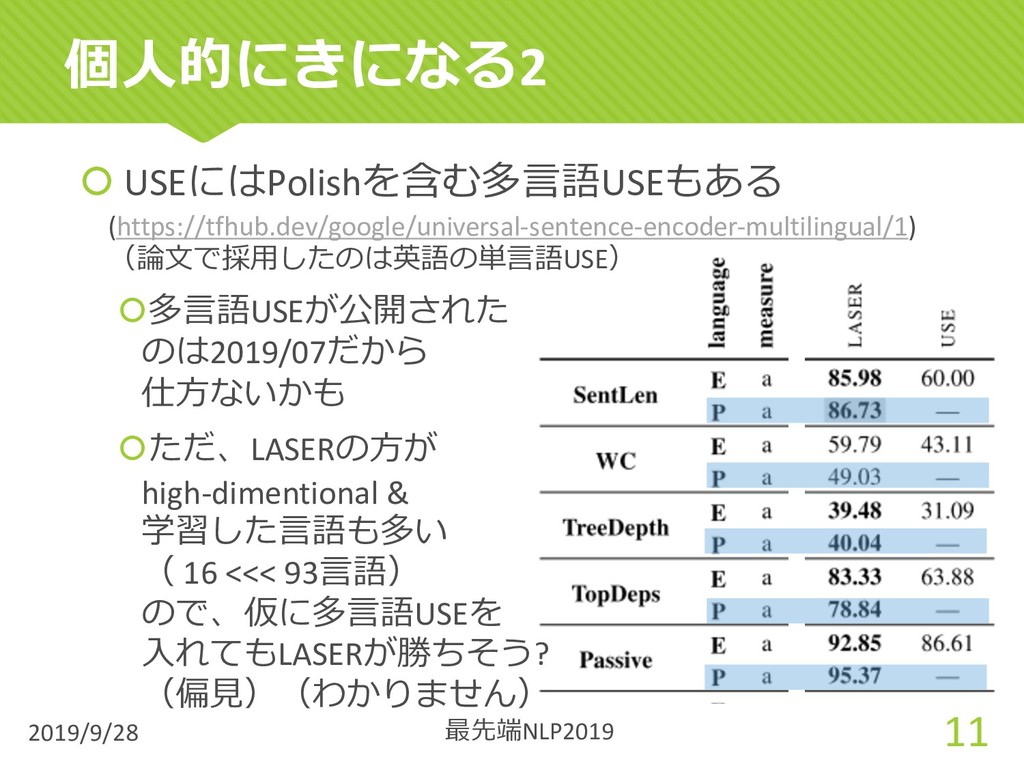{kind=link}
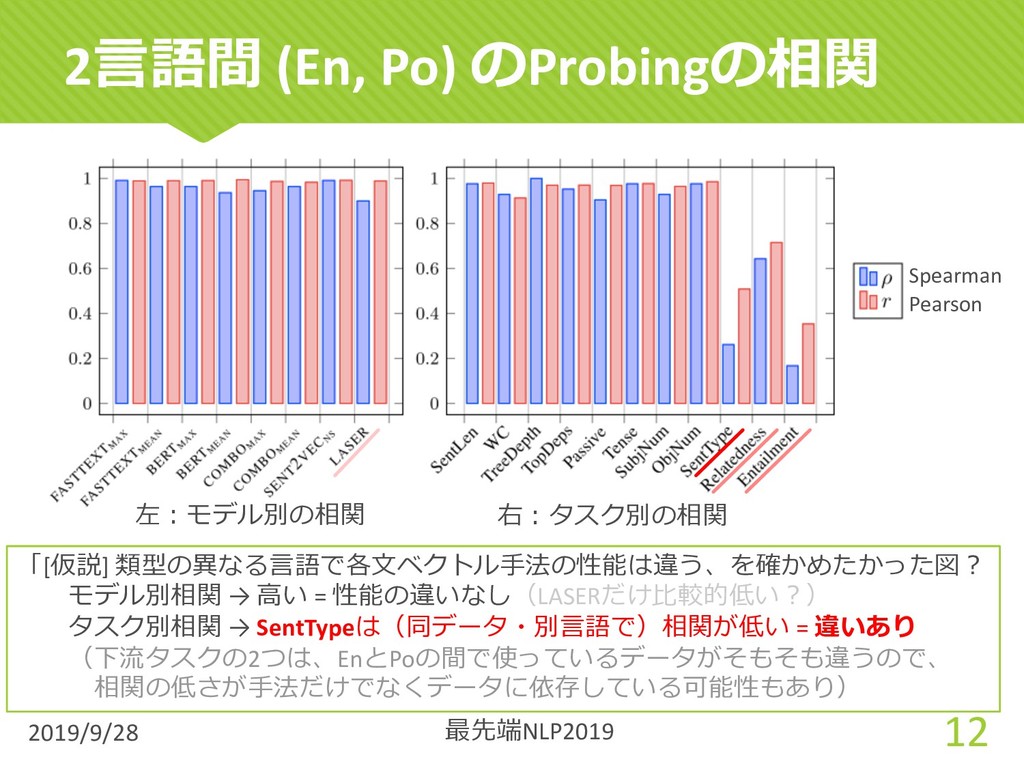{kind=link}
{kind=link}
{kind=link}
![References [Cer+, 2018] Universal Sentence Encoder for English. In Proceedings](https://files.speakerdeck.com/presentations/aa37d36841b44d7db5ed0fce2536a7a3/slide_14.jpg){kind=link}