you • Supports PIOPS • Handles multiple clusters, sharding, arbiters • Built-in snapshot support • Provisions new nodes automagically from latest completed RAID snapshot set for cluster Friday, July 26, 13
• run “dd” on each of the data files to pull blocks down • Always warm up a secondary before promoting • warm up both indexes and data • http://blog.parse.com/2013/03/07/techniques-for-warming-up-mongodb/ • in mongodb 2.2 and above you can use the touch command: Friday, July 26, 13
and databases • Hard on your primary, does a full table scan of all data • On > 2.2.0 you can sync from a secondary by button- mashing rs.syncFrom() on startup • Or use iptables to block secondary from viewing primary (all versions) • Resets all padding factors to 1 Friday, July 26, 13
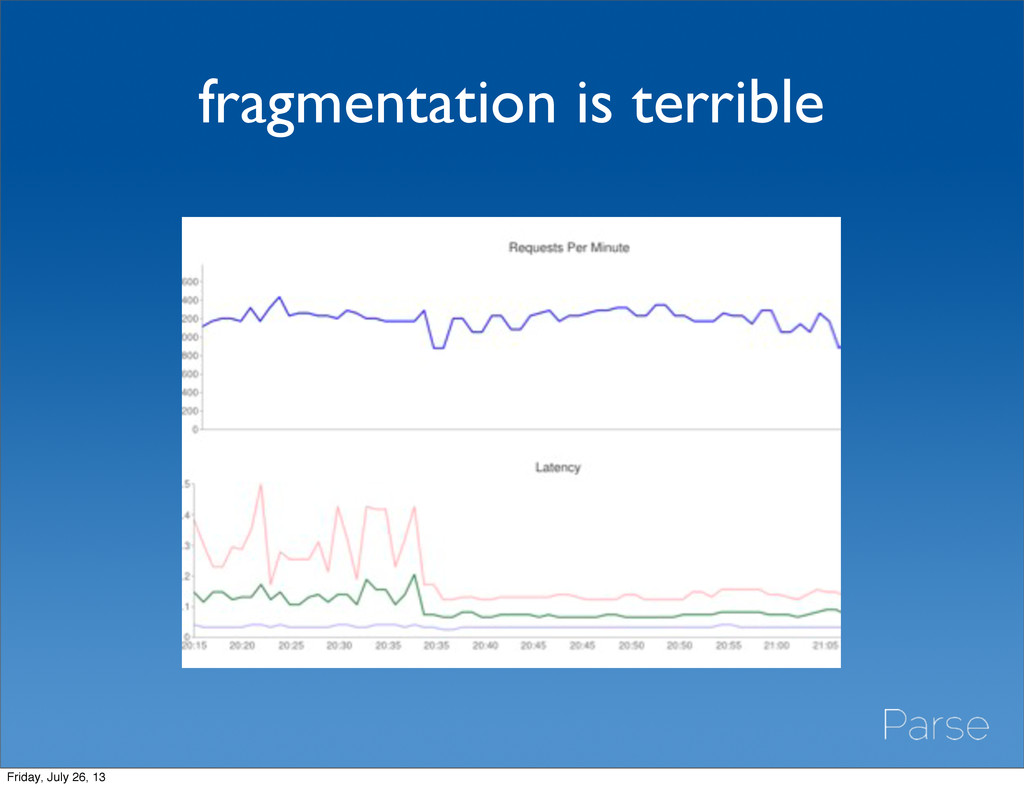
underuse of memory • Deletes are not the only source of fragmentation • Repair, compact, or resync regularly • Or consider using powerof2 padding factor Friday, July 26, 13
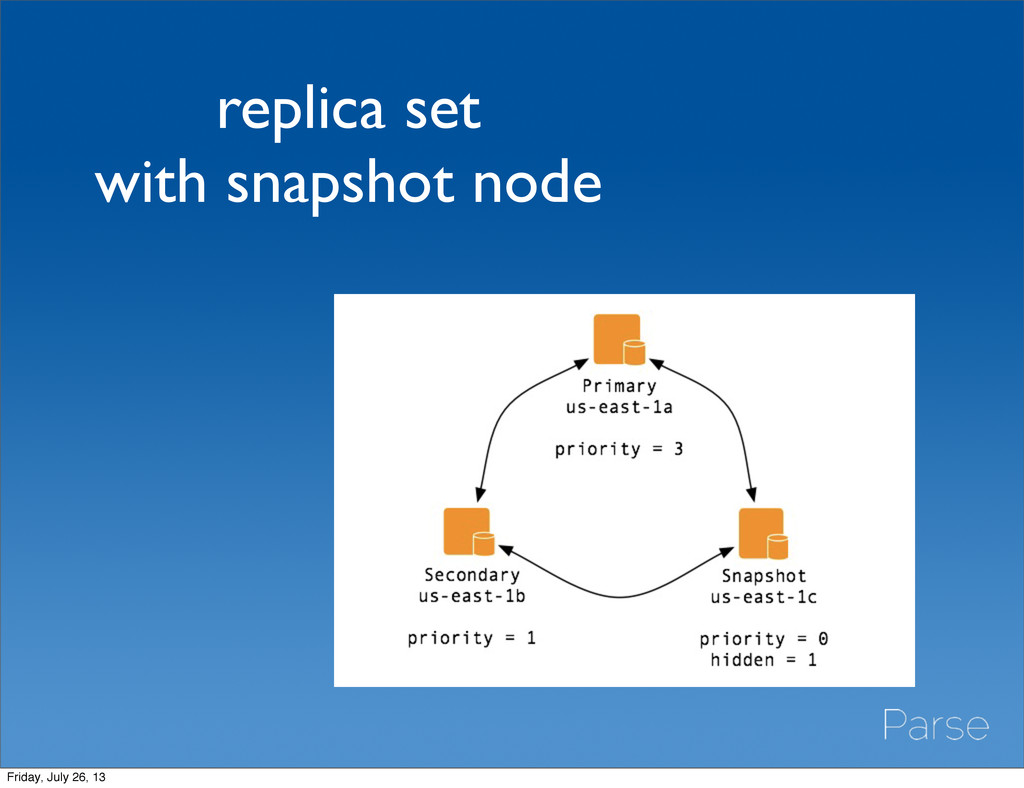
scratch • resets your padding factors • hard on your primary; rs.syncFrom() a secondary • Repair a secondary • resets your padding factors • may take longer than your oplog age • Run continuous compaction on your snapshot node • won’t reset padding factors • but it also won’t reclaim disk space Friday, July 26, 13
• Sort by num_seconds • Sort by num_yields, locktype • Consider adding comments to your queries • Run explain() on queries that are long-running Friday, July 26, 13
persist through restarts • Like mongodb.log, but queryable • Writes to this collection incur some cost • Use db.system.profile.find() to get slow queries for a certain collection, time range, execution time, etc Friday, July 26, 13
elect a new primary or restart • Do kill queries before the tipping point • Write your kill script before you need it • Don’t kill internal mongo operations, only queries. ... when queries pile up ... Friday, July 26, 13
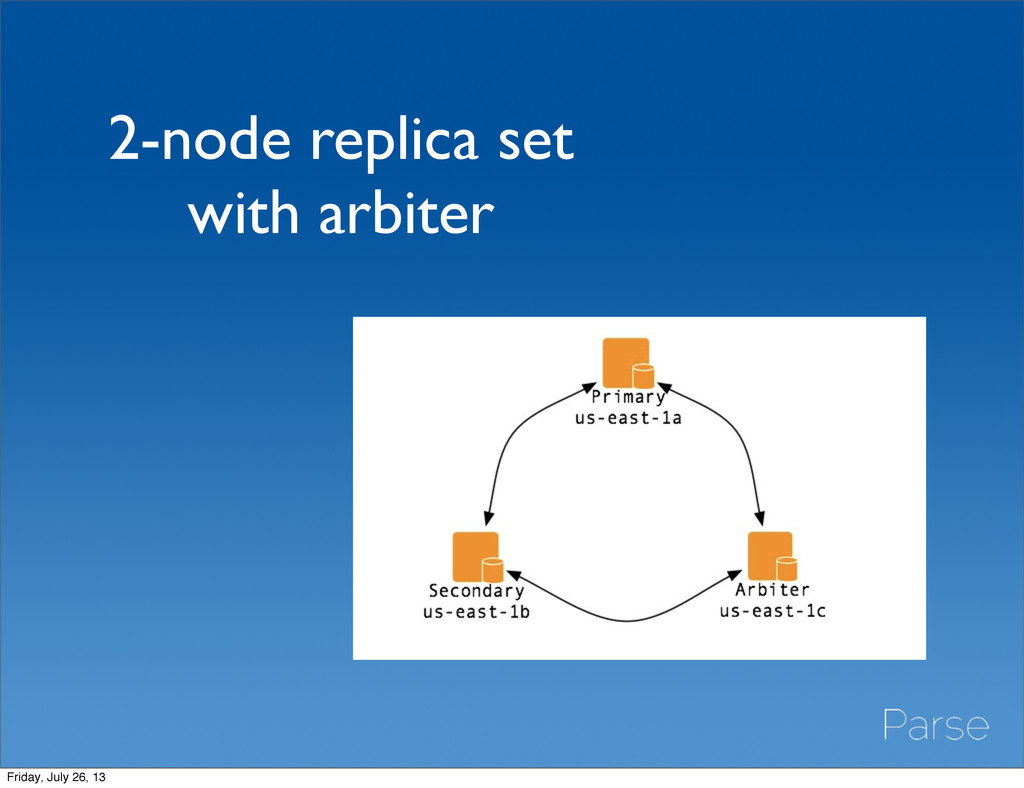
number of votes (max 7) • You need > 50% of votes to elect a primary • Set your priority levels explicitly if you need warmup • Consider delegating voting to arbiters • Set snapshot nodes to be nonvoting if possible. • Check your mongo log. Is something vetoing? Do they have an inconsistent view of the cluster state? Friday, July 26, 13
secondaries to crash unrecoverably • Never kill oplog tailers or other internal database operations, this can also trash secondaries • Arbiters are more stable than secondaries, consider using them to form a quorum with your primary Friday, July 26, 13
cause secondaries to exit without a corrupt op • The correct way to fix this is to re-snapshot off the primary and rebuild your secondaries. • However, you can sometimes *dangerously* repair a secondary: 1. stop mongo 2. bring it back up in standalone mode 3. repair the offending collection 4. restart mongo again as part of the replica set Friday, July 26, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}