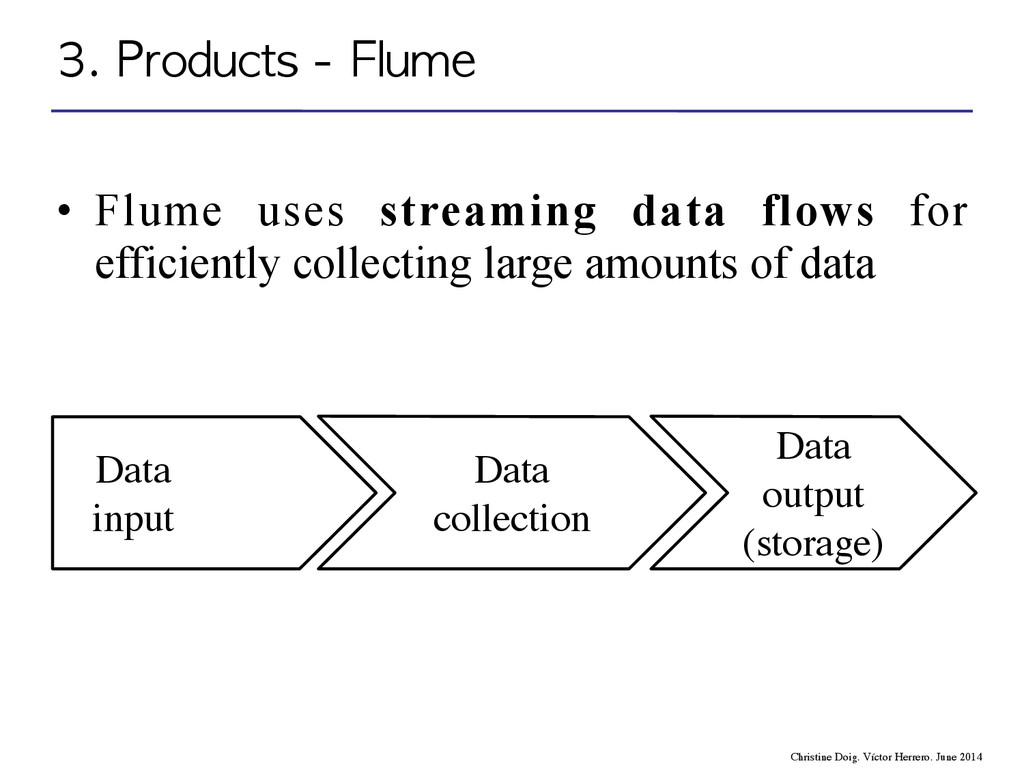
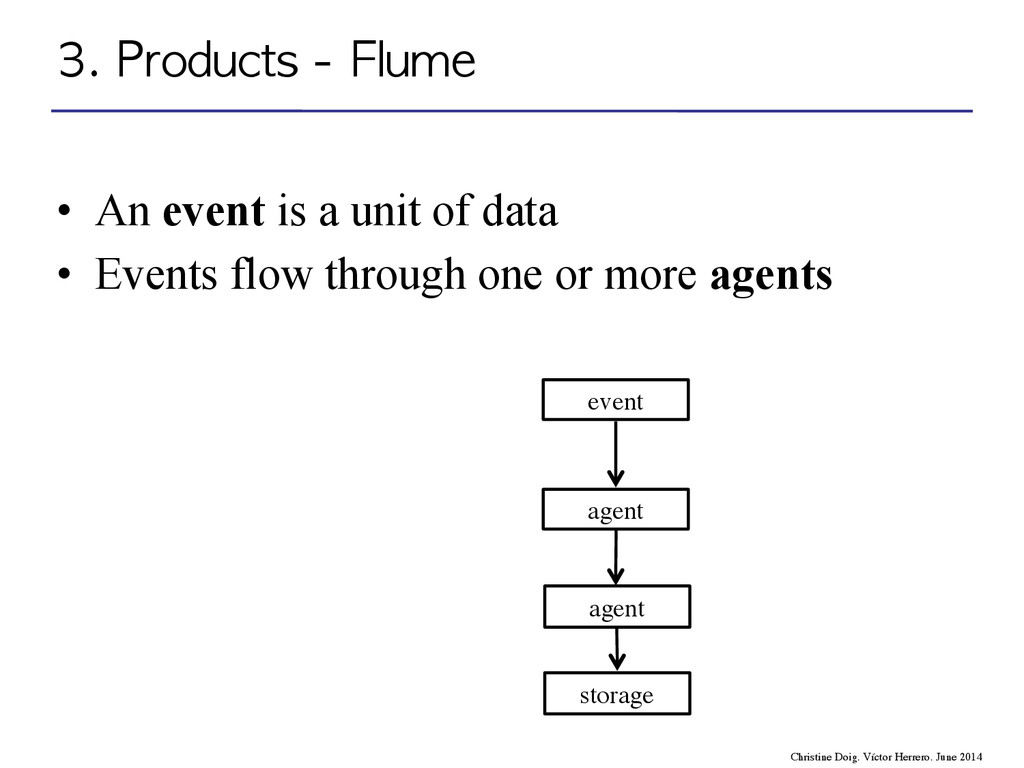
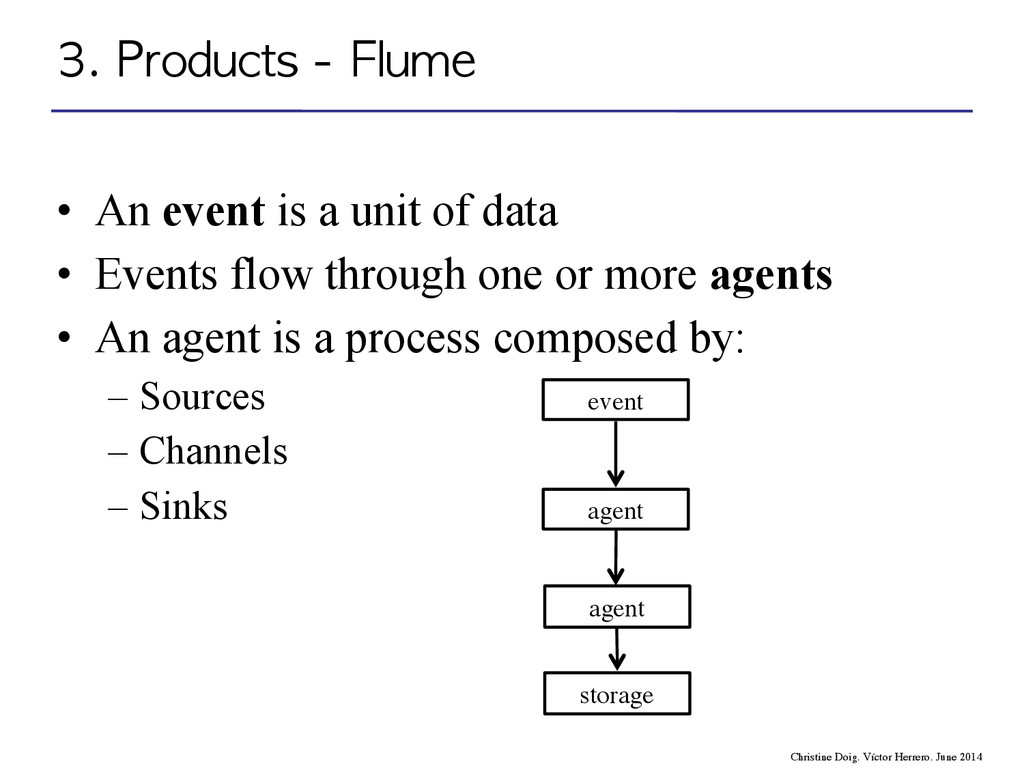
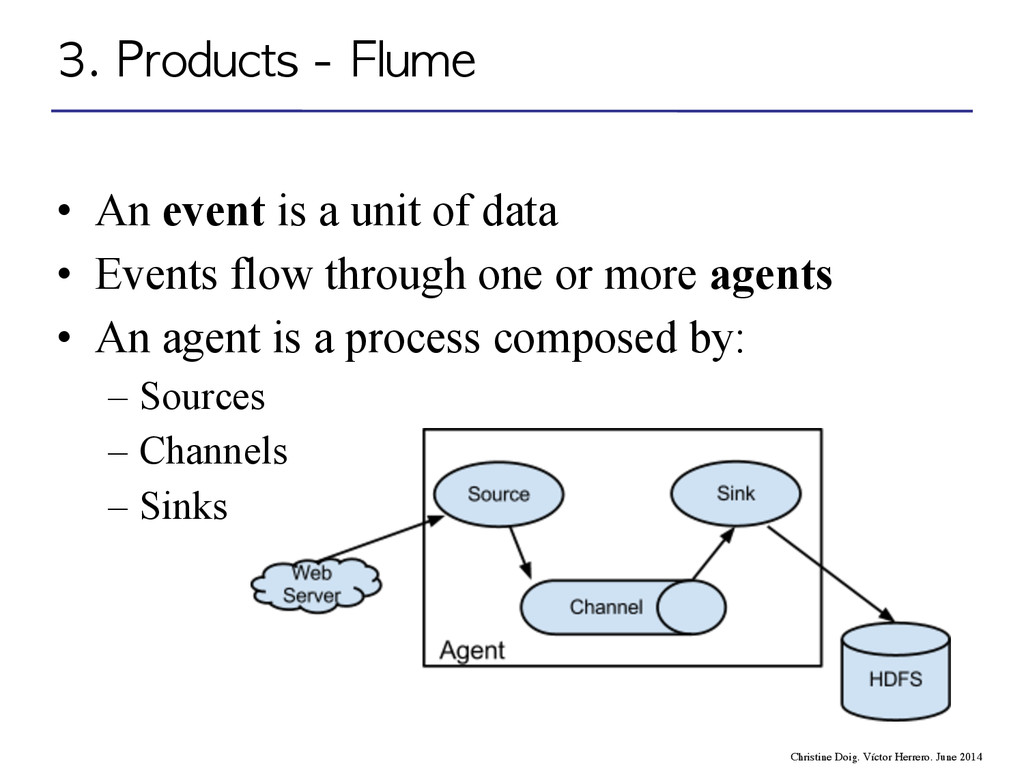
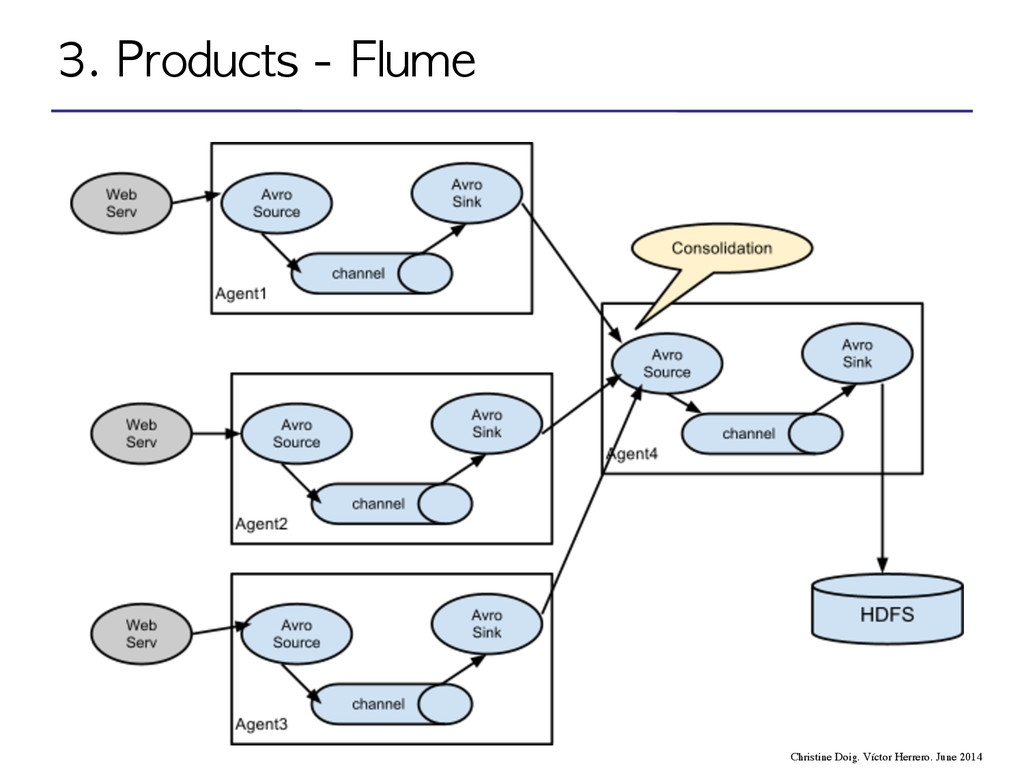
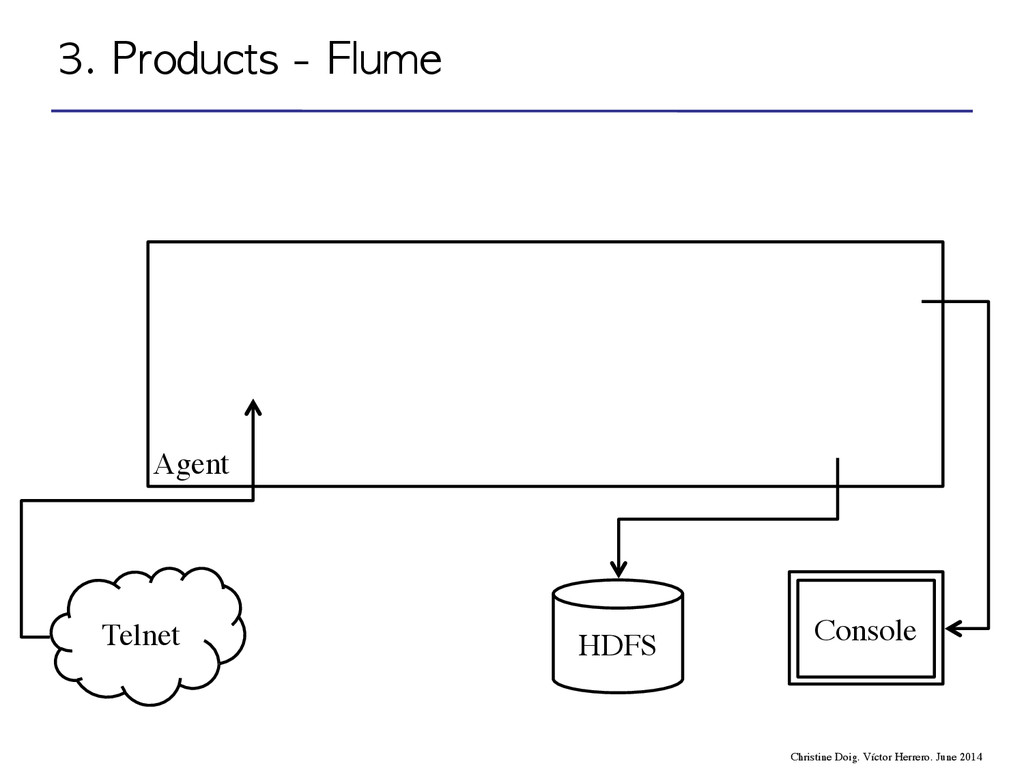
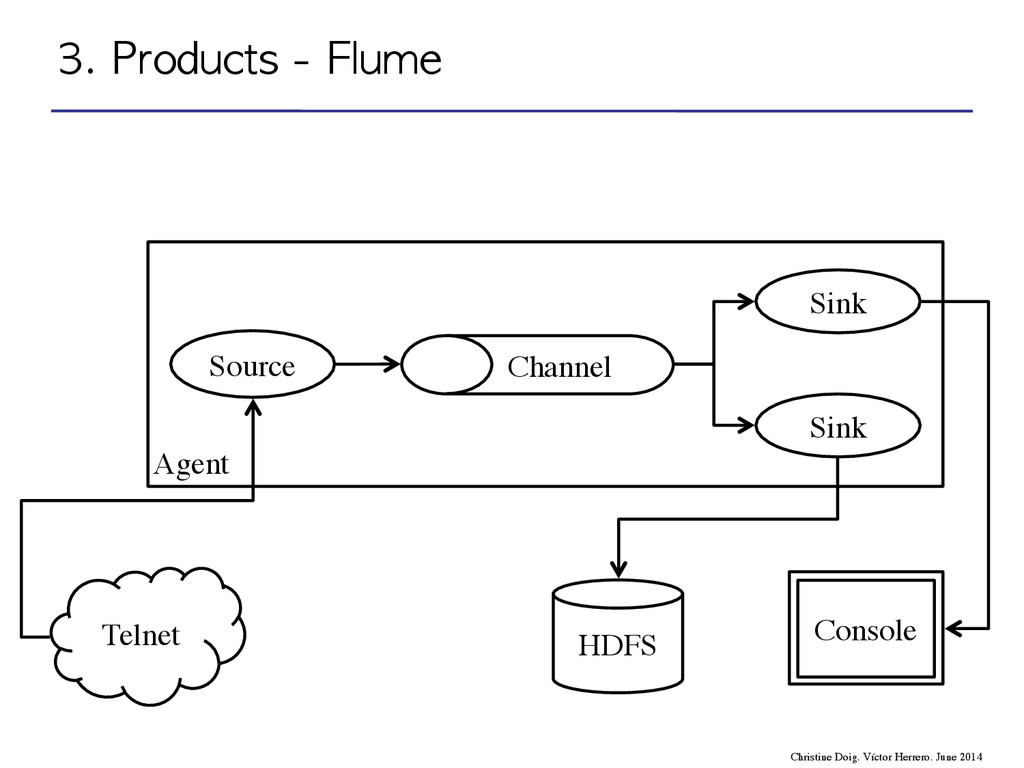
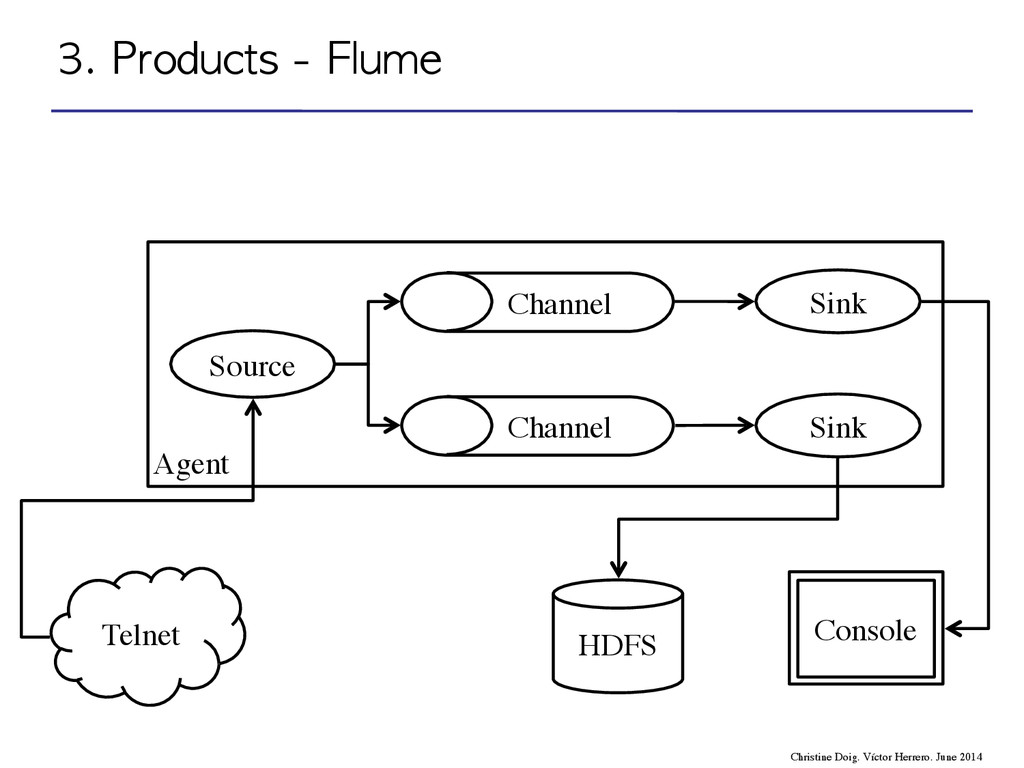
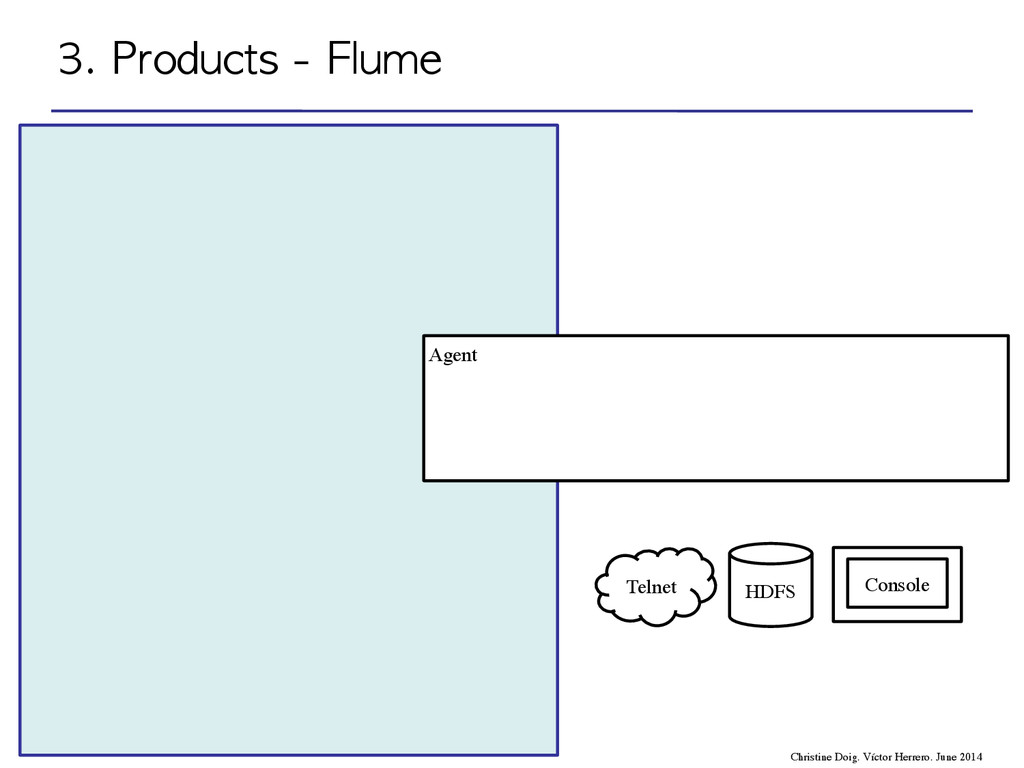
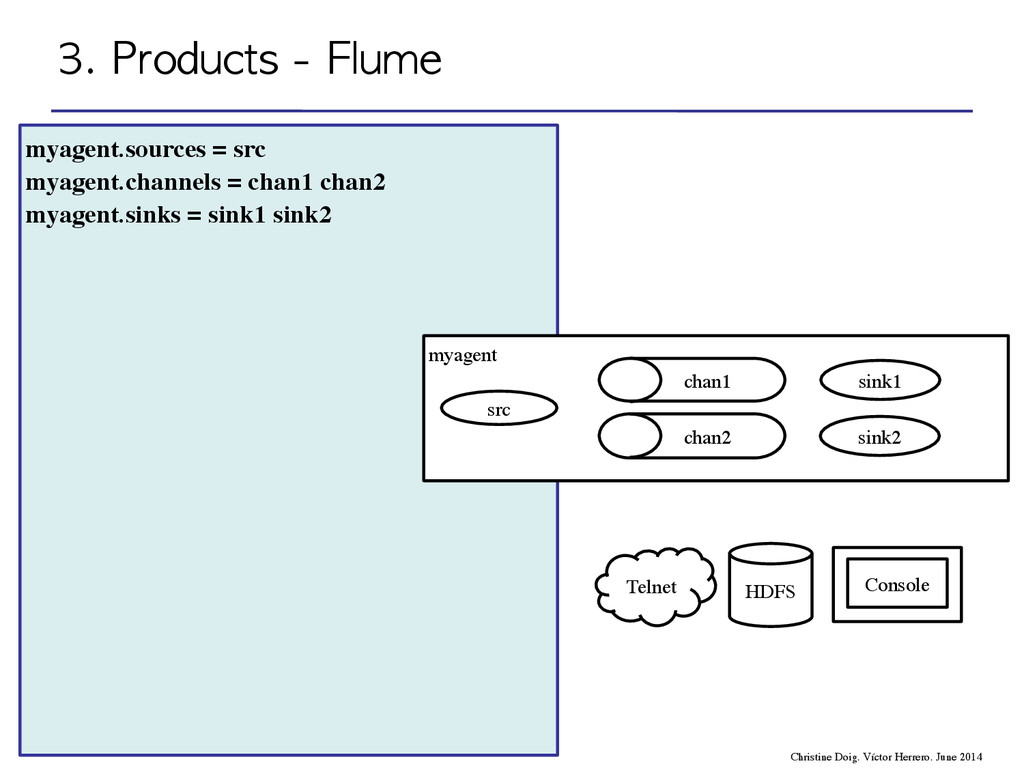
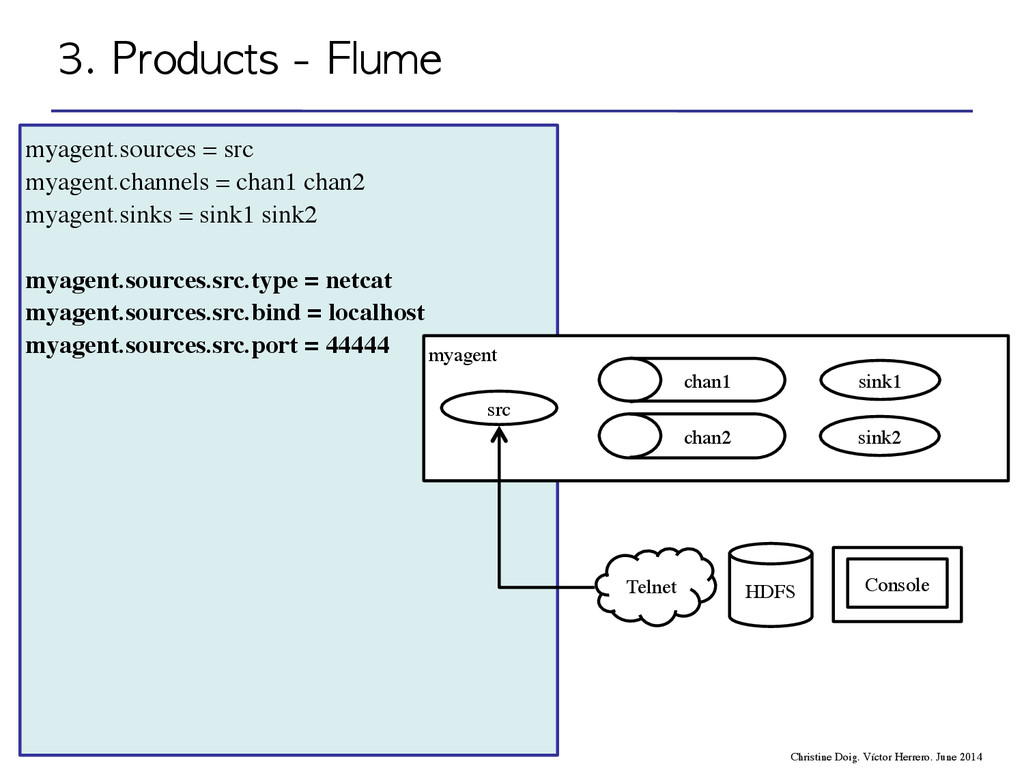
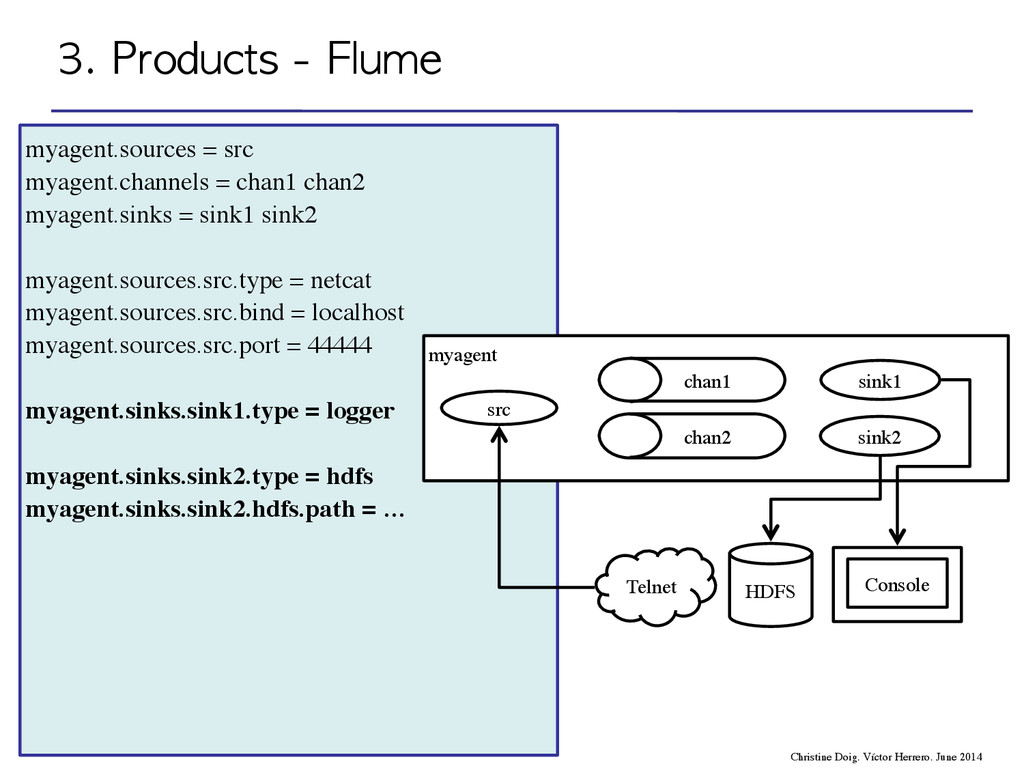
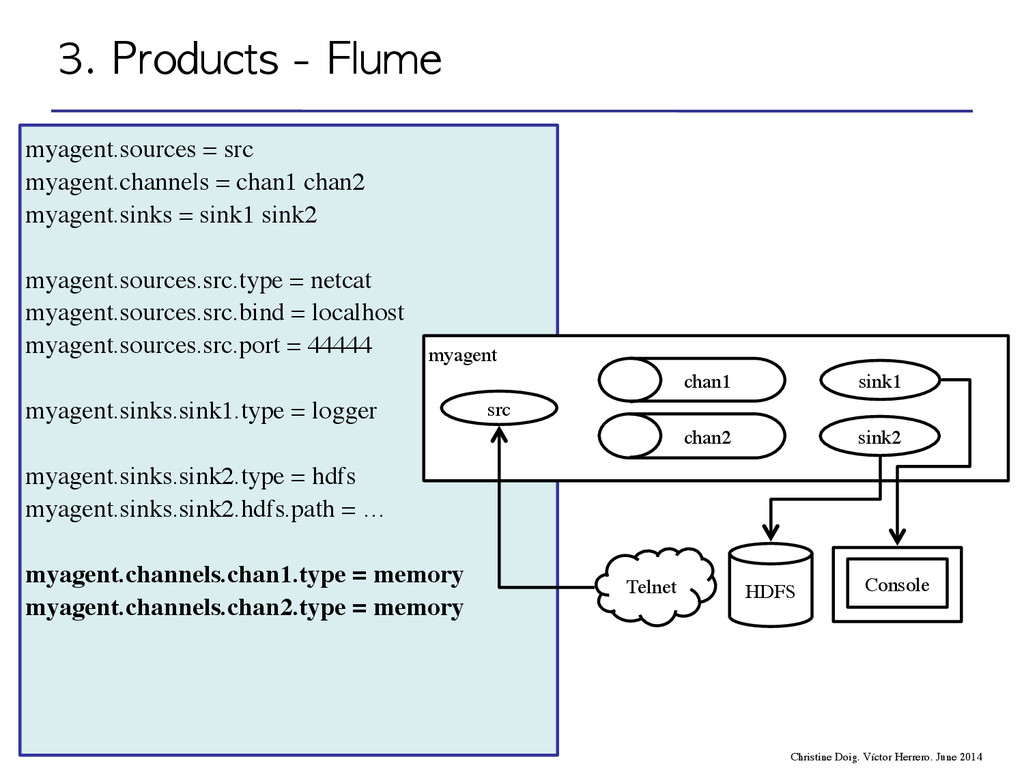
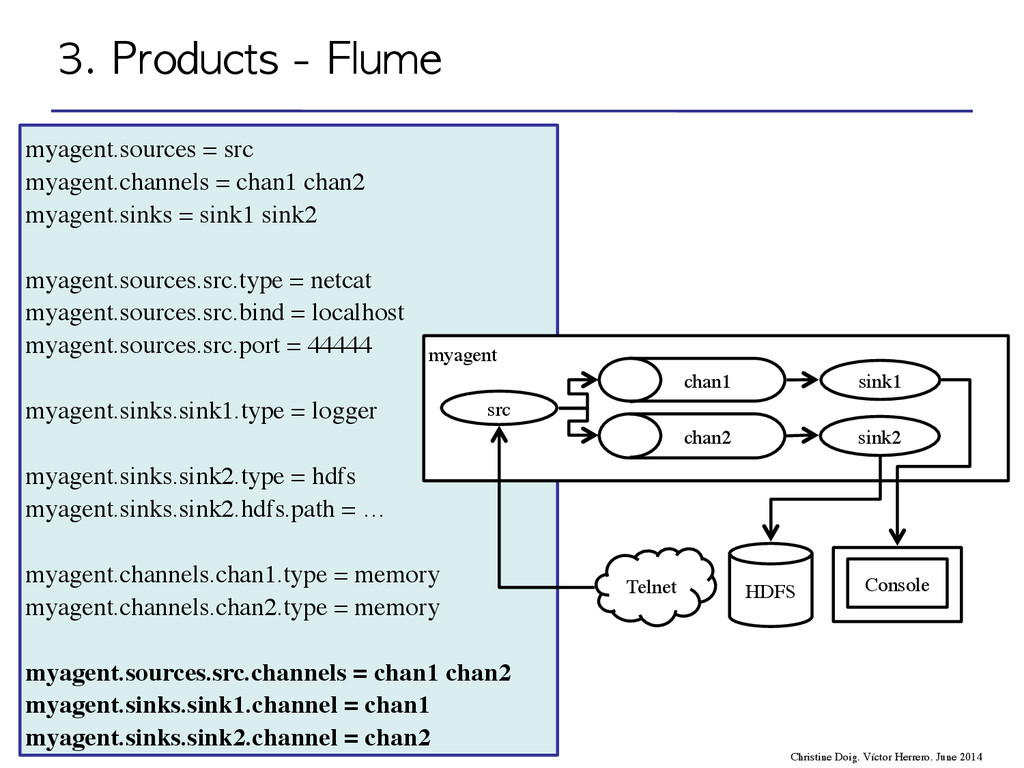
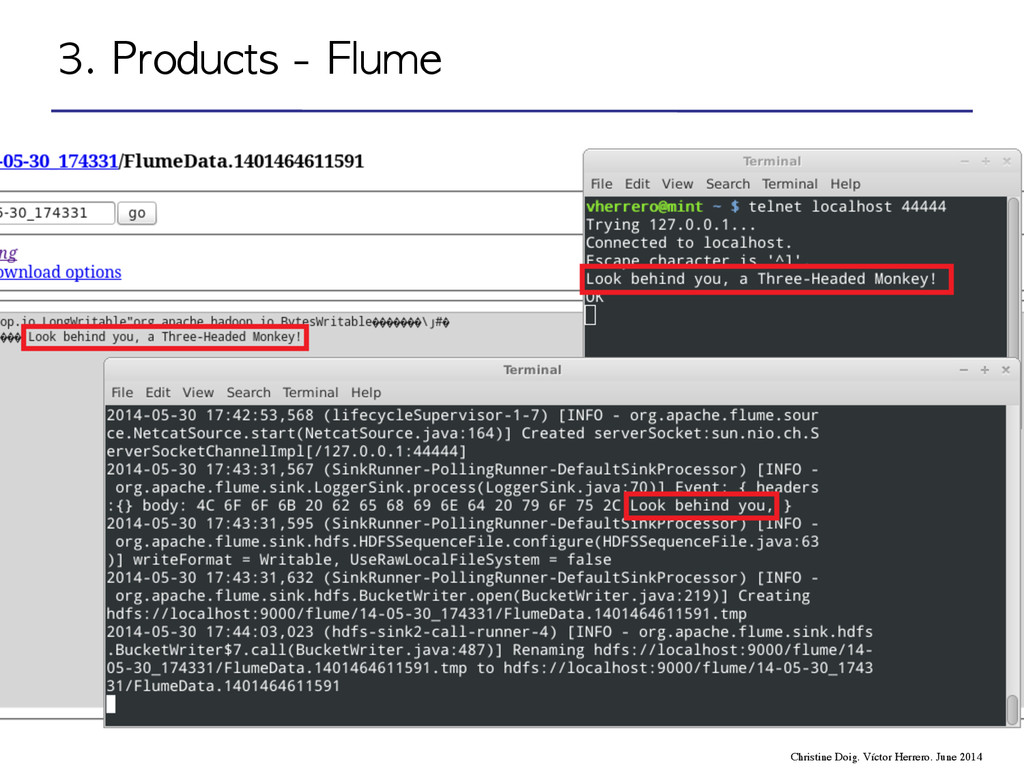
flow through one or more agents • An agent is a process composed by: – Sources – Channels – Sinks event agent agent storage 3. Products - Flume Christine Doig. Víctor Herrero. June 2014
flow through one or more agents • An agent is a process composed by: – Sources – Channels – Sinks 3. Products - Flume Christine Doig. Víctor Herrero. June 2014
computation system. ! Use cases: -Stream processing: -Real-time analytics -Online machine learning -Distributed RPC -Continuous computation ! A Storm topology consumes streams of data and processes those streams in complex ways, repartitioning the streams between each stage of the computation however needed. ! Characteristics: Free and Open Source Scalable: Routing and partitioning of streams Fault-tolerant: Monitors and reassigns failed tasks Guarantees your data will be processed: Tracking tuple trees ! Christine Doig. Víctor Herrero. June 2014 Source: http://storm.incubator.apache.org/
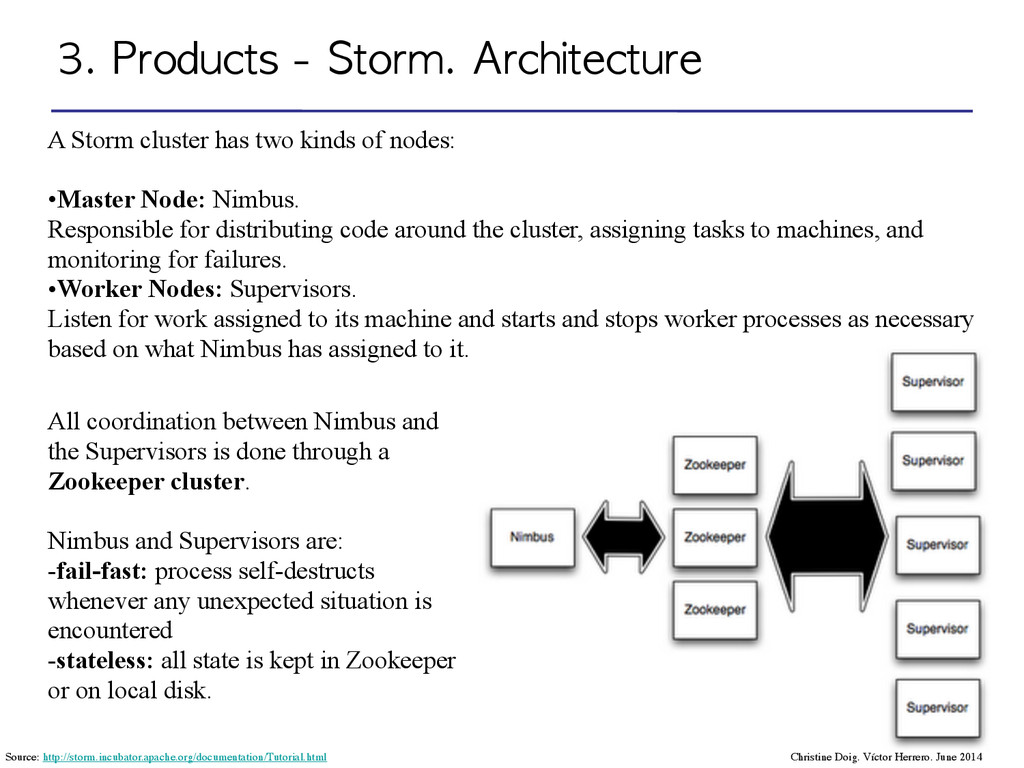
kinds of nodes: ! •Master Node: Nimbus. Responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures. •Worker Nodes: Supervisors. Listen for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it. All coordination between Nimbus and the Supervisors is done through a Zookeeper cluster. ! Nimbus and Supervisors are: -fail-fast: process self-destructs whenever any unexpected situation is encountered -stateless: all state is kept in Zookeeper or on local disk. Christine Doig. Víctor Herrero. June 2014 Source: http://storm.incubator.apache.org/documentation/Tutorial.html
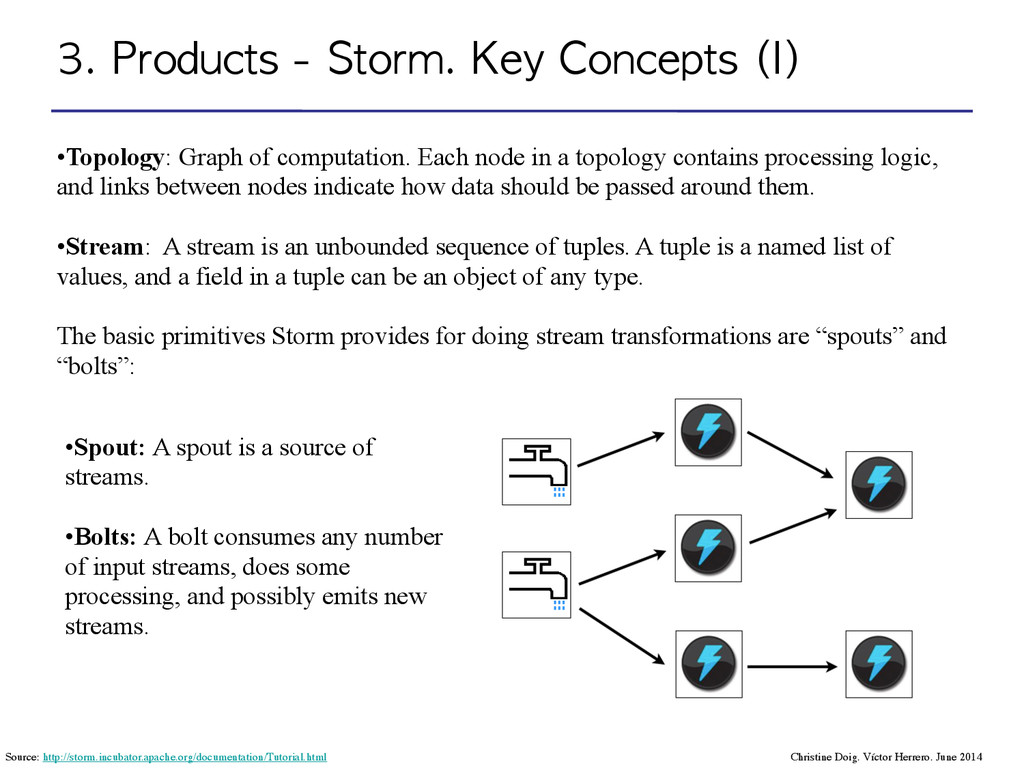
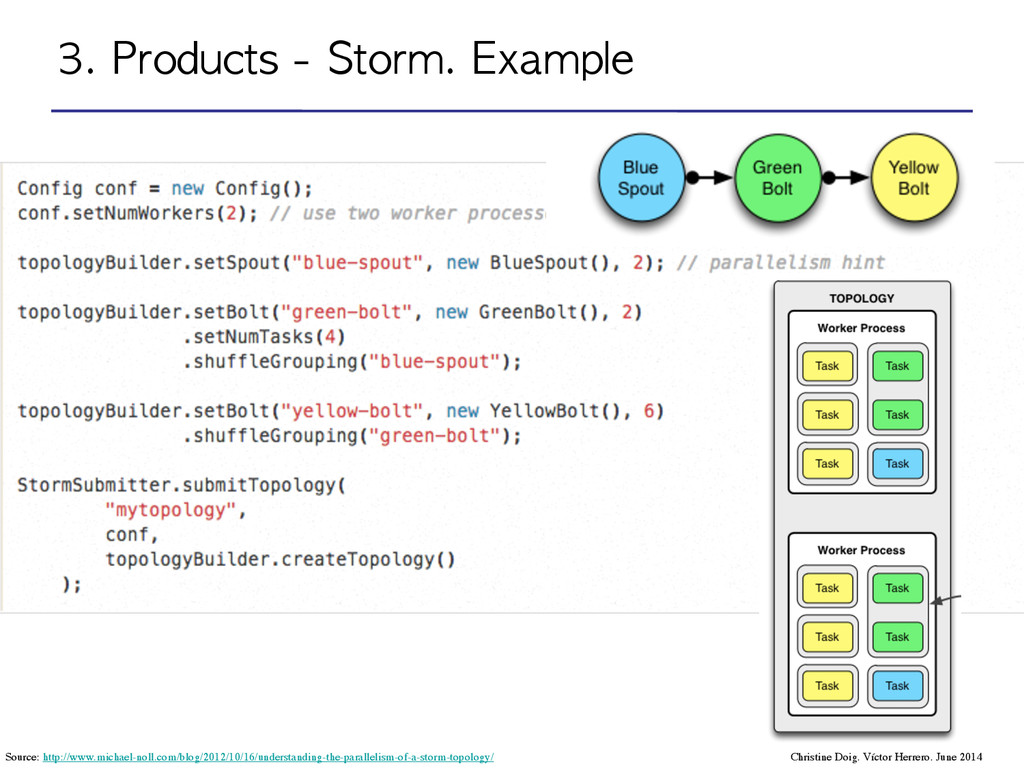
computation. Each node in a topology contains processing logic, and links between nodes indicate how data should be passed around them. ! •Stream: A stream is an unbounded sequence of tuples. A tuple is a named list of values, and a field in a tuple can be an object of any type. ! The basic primitives Storm provides for doing stream transformations are “spouts” and “bolts”: •Spout: A spout is a source of streams. •Bolts: A bolt consumes any number of input streams, does some processing, and possibly emits new streams. Source: http://storm.incubator.apache.org/documentation/Tutorial.html Christine Doig. Víctor Herrero. June 2014
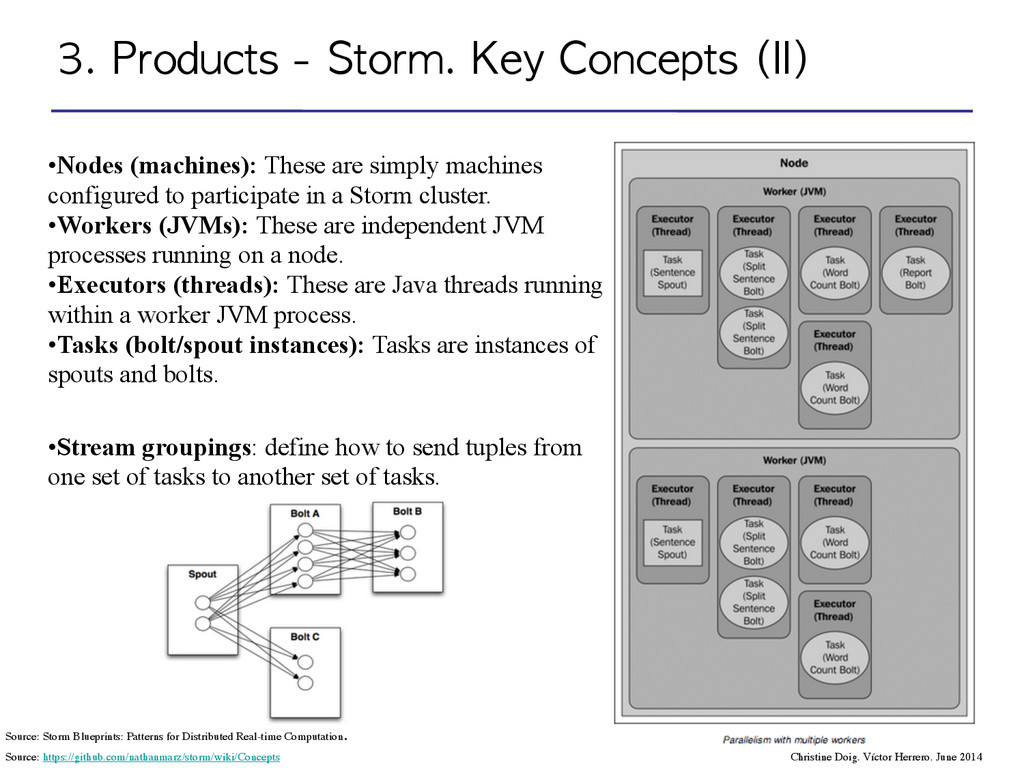
Herrero. June 2014 Source: https://github.com/nathanmarz/storm/wiki/Concepts •Stream groupings: define how to send tuples from one set of tasks to another set of tasks. •Nodes (machines): These are simply machines configured to participate in a Storm cluster. •Workers (JVMs): These are independent JVM processes running on a node. •Executors (threads): These are Java threads running within a worker JVM process. •Tasks (bolt/spout instances): Tasks are instances of spouts and bolts. Source: Storm Blueprints: Patterns for Distributed Real-time Computation .
June 2014 Guaranteeing message processing ! Storm’s basic abstractions provide an at-least-once processing guarantee, the same guarantee you get when using a queueing system. Using Trident, a higher level abstraction over Storm’s basic abstractions, you can achieve exactly-once processing. ! ! ! ! ! ! Source: Storm Blueprints: Patterns for Distributed Real-time Computation . Each bolt in the tree can either acknowledge (ack) or fail a tuple. ! -> If all bolts in the tree acknowledge tuples derived from the trunk tuple, the spout's ack method will be called to indicate that message processing is complete. ! ->If any of the bolts in the tree explicitly fail a tuple, or if processing of the tuple tree exceeds the time-out period, the spout's fail method will be called.
June 2014 Fault tolerance ! •Worker dies: the supervisor will restart it. If it fails, Nimbus will reassign the worker to another machine. •Node dies: Nimbus will reassign those tasks to other machines. •Nimbus or Supervisor dies: They restart. State is in Zookeeper ! What happens while Nimbus is down? Is Nimbus a Singular Point of Failure? If you lose the Nimbus node, the workers will still continue to function. Additionally, supervisors will continue to restart workers if they die. However, without Nimbus, workers won't be reassigned to other machines when necessary (like if you lose a worker machine). ! ! ! ! !
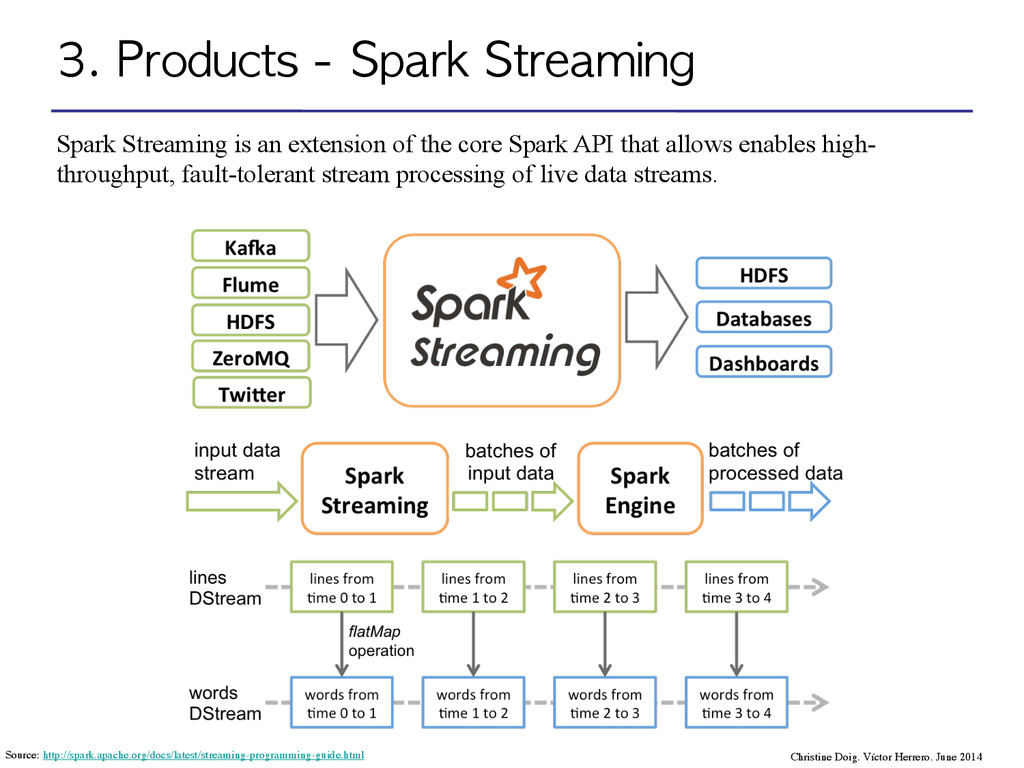
an extension of the core Spark API that allows enables high- throughput, fault-tolerant stream processing of live data streams. Christine Doig. Víctor Herrero. June 2014
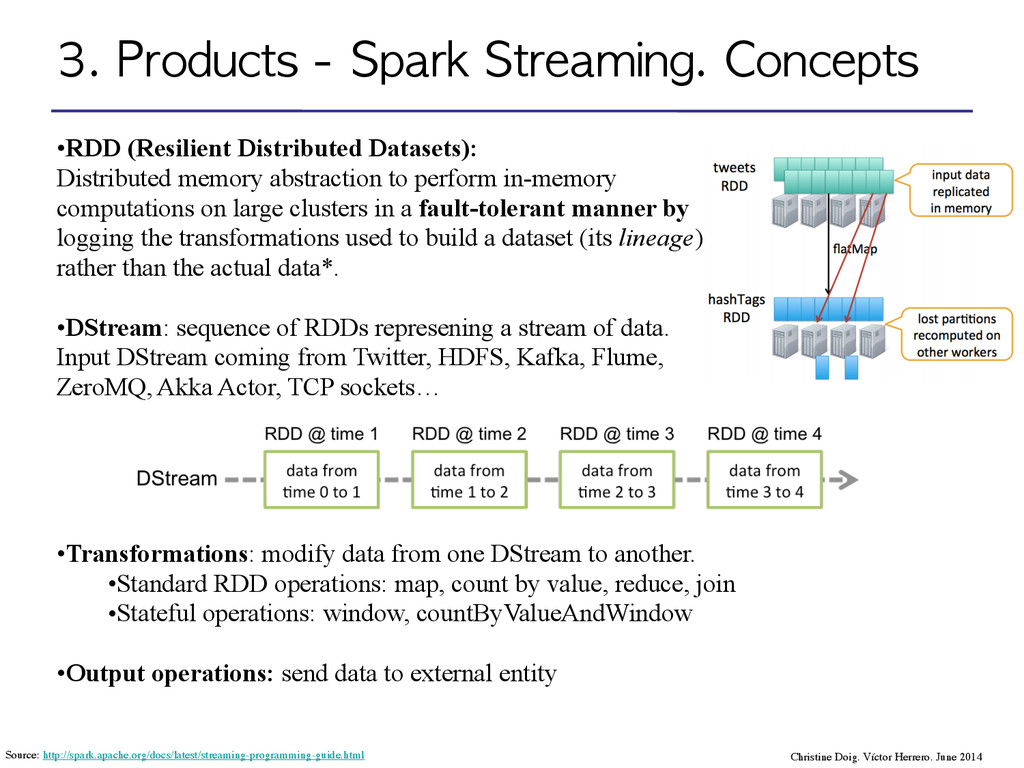
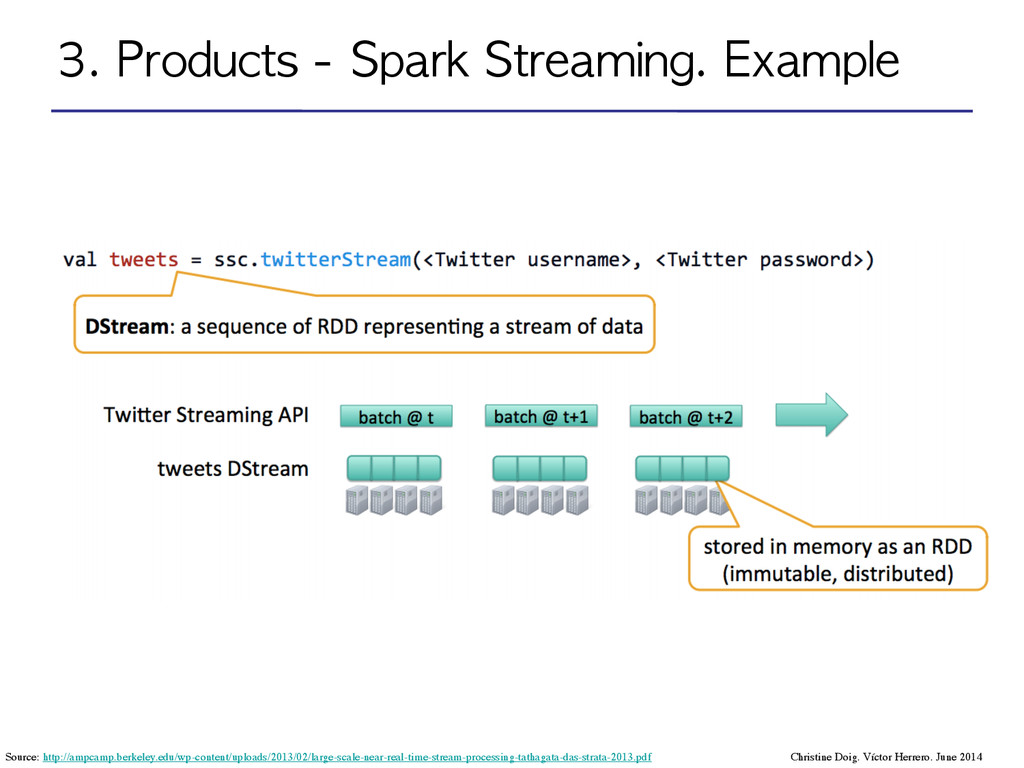
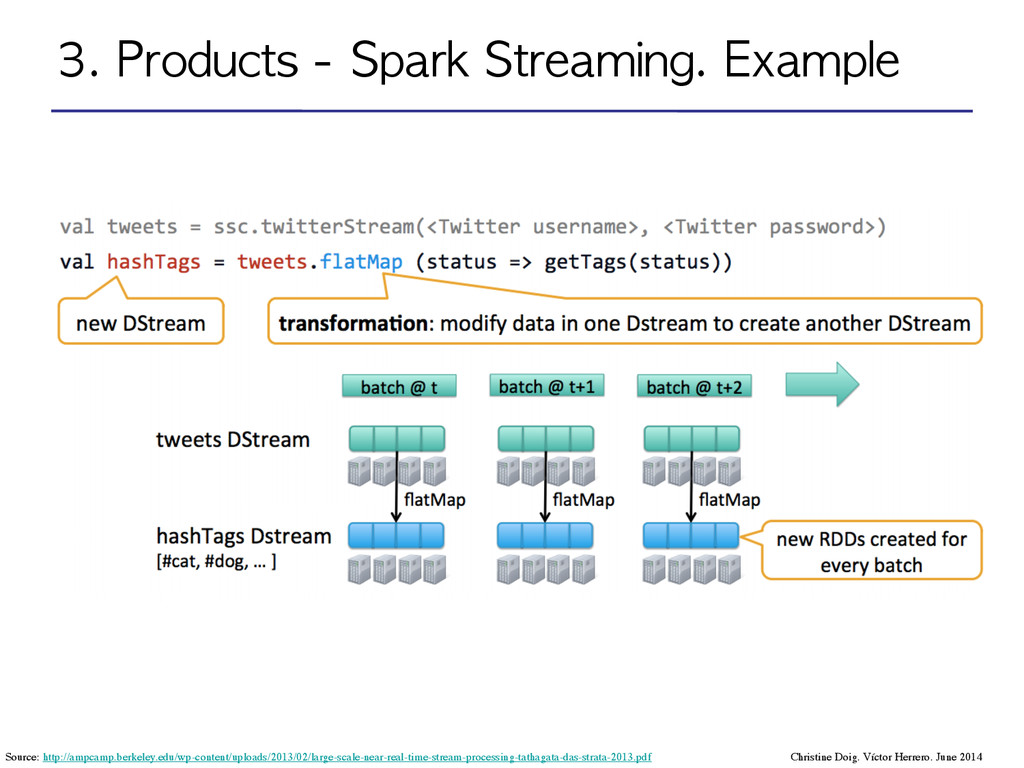
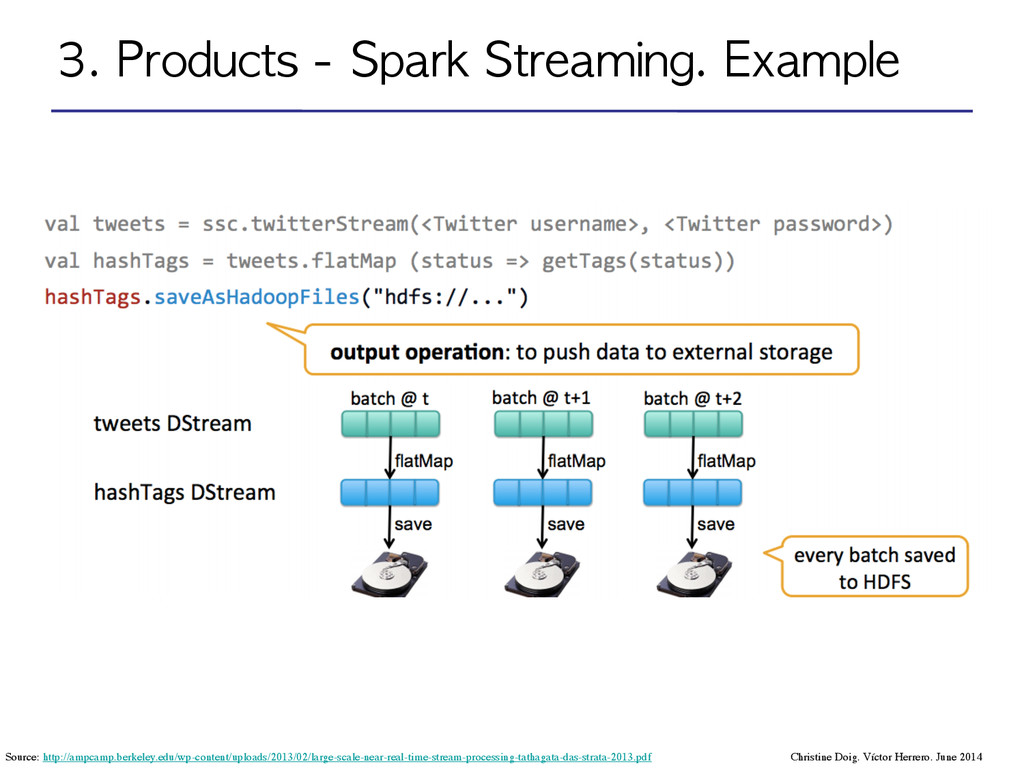
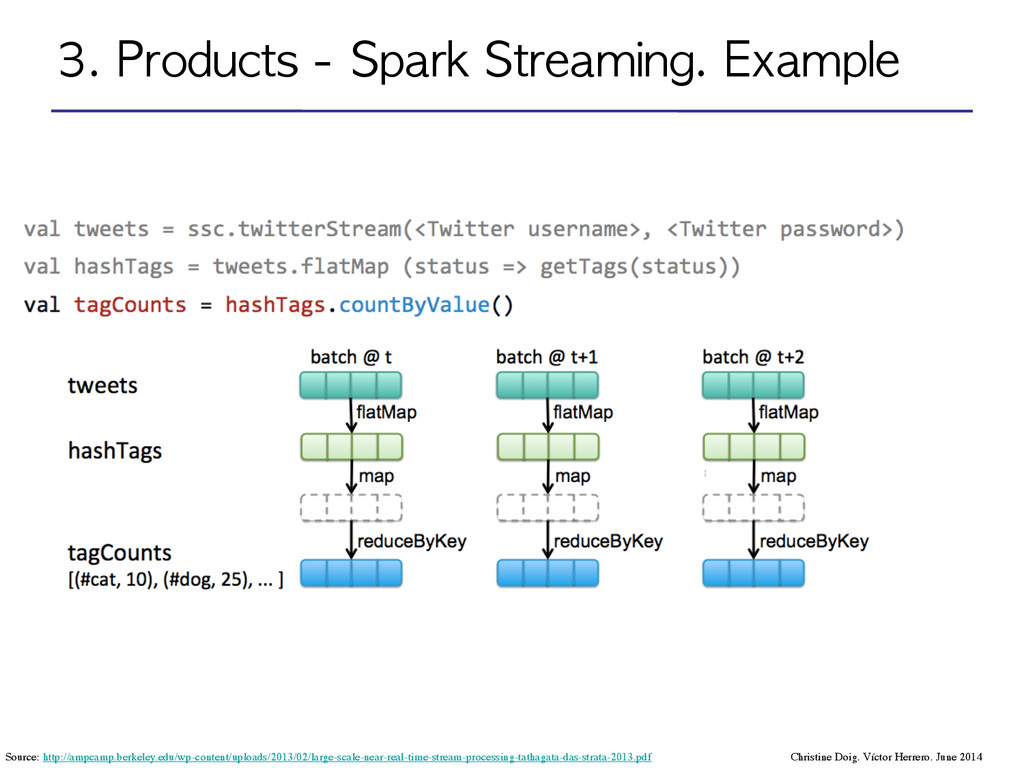
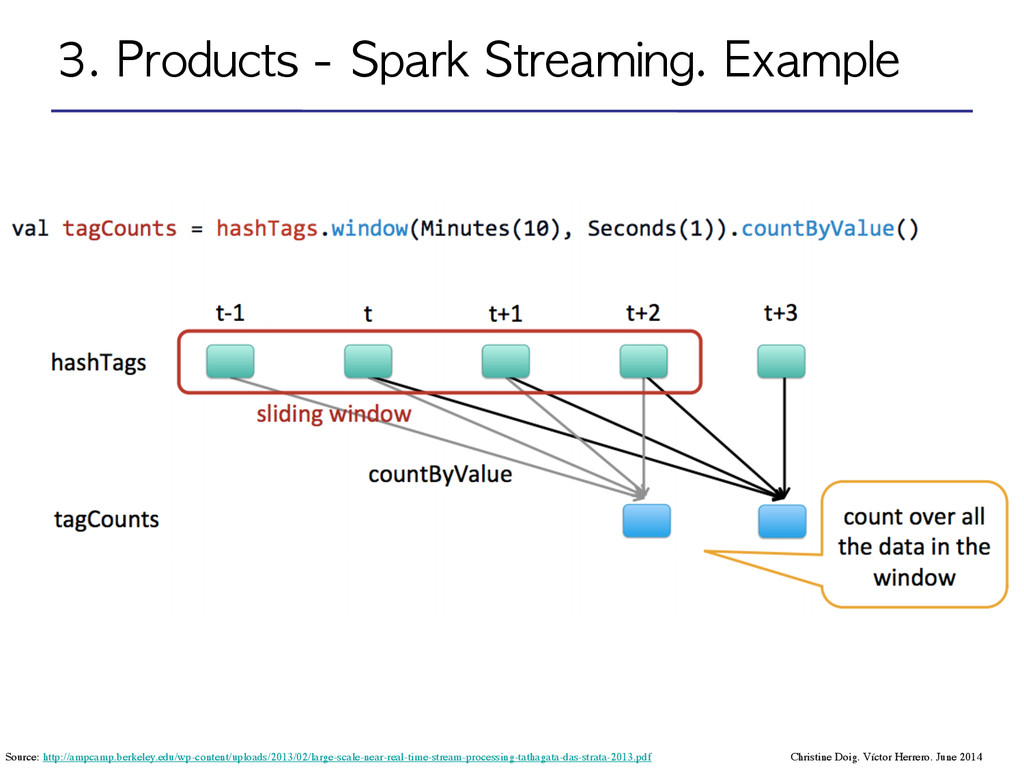
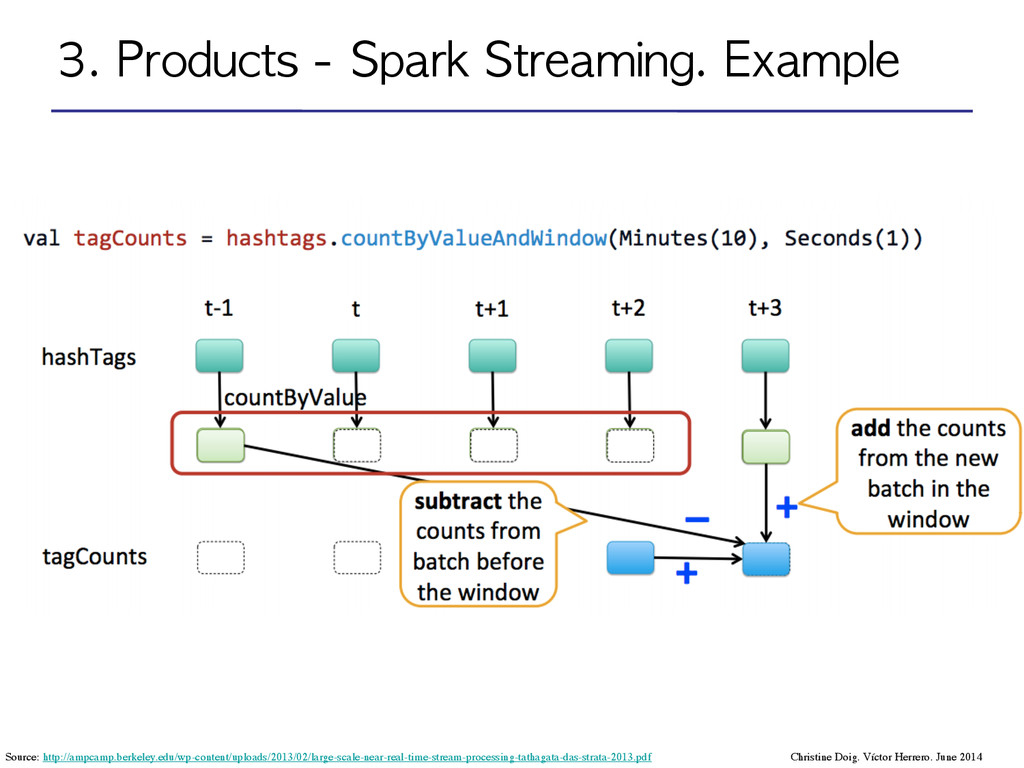
Distributed Datasets): Distributed memory abstraction to perform in-memory computations on large clusters in a fault-tolerant manner by logging the transformations used to build a dataset (its lineage) rather than the actual data*. ! •DStream: sequence of RDDs represening a stream of data. Input DStream coming from Twitter, HDFS, Kafka, Flume, ZeroMQ, Akka Actor, TCP sockets… ! ! ! ! •Transformations: modify data from one DStream to another. •Standard RDD operations: map, count by value, reduce, join •Stateful operations: window, countByValueAndWindow ! •Output operations: send data to external entity Christine Doig. Víctor Herrero. June 2014
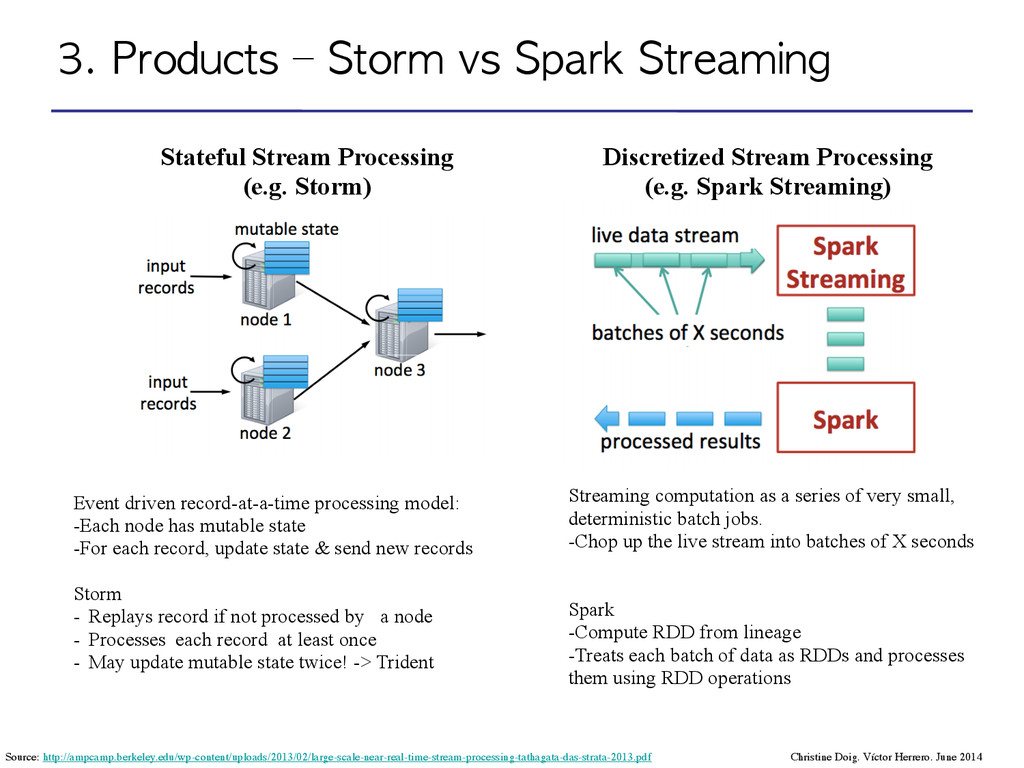
(e.g. Storm) Streaming computation as a series of very small, deterministic batch jobs. -Chop up the live stream into batches of X seconds ! Spark -Compute RDD from lineage -Treats each batch of data as RDDs and processes them using RDD operations Event driven record-at-a-time processing model: -Each node has mutable state -For each record, update state & send new records ! Storm - Replays record if not processed by a node - Processes each record at least once - May update mutable state twice! -> Trident Discretized Stream Processing (e.g. Spark Streaming) Source: http://ampcamp.berkeley.edu/wp-content/uploads/2013/02/large-scale-near-real-time-stream-processing-tathagata-das-strata-2013.pdf Christine Doig. Víctor Herrero. June 2014
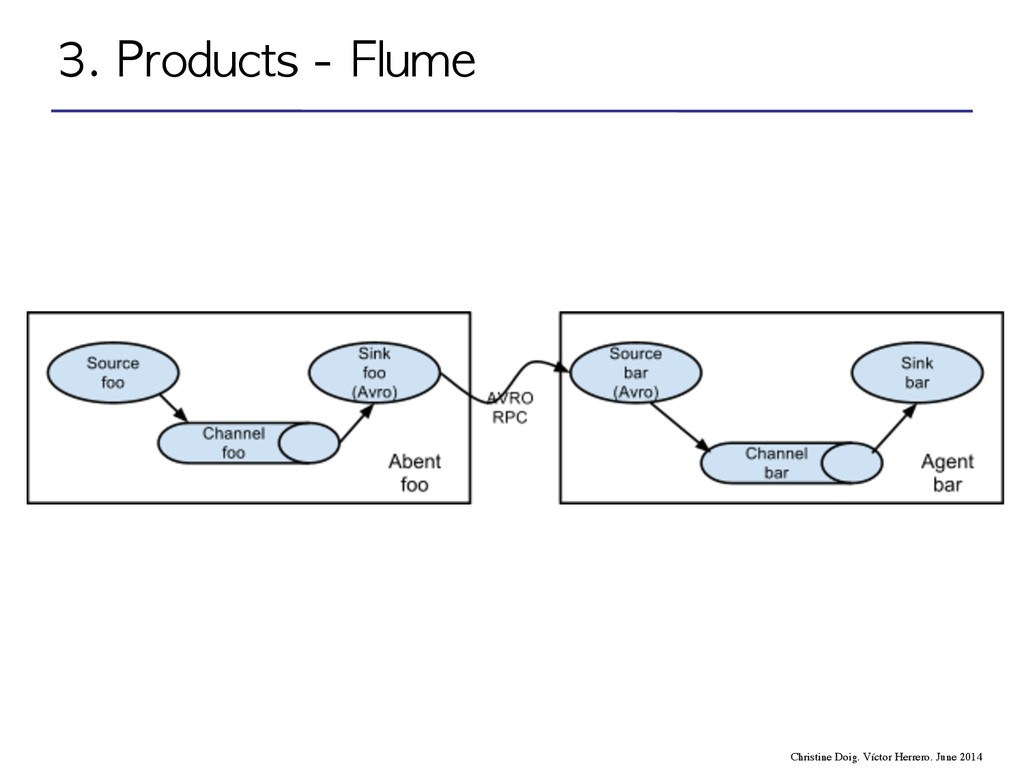
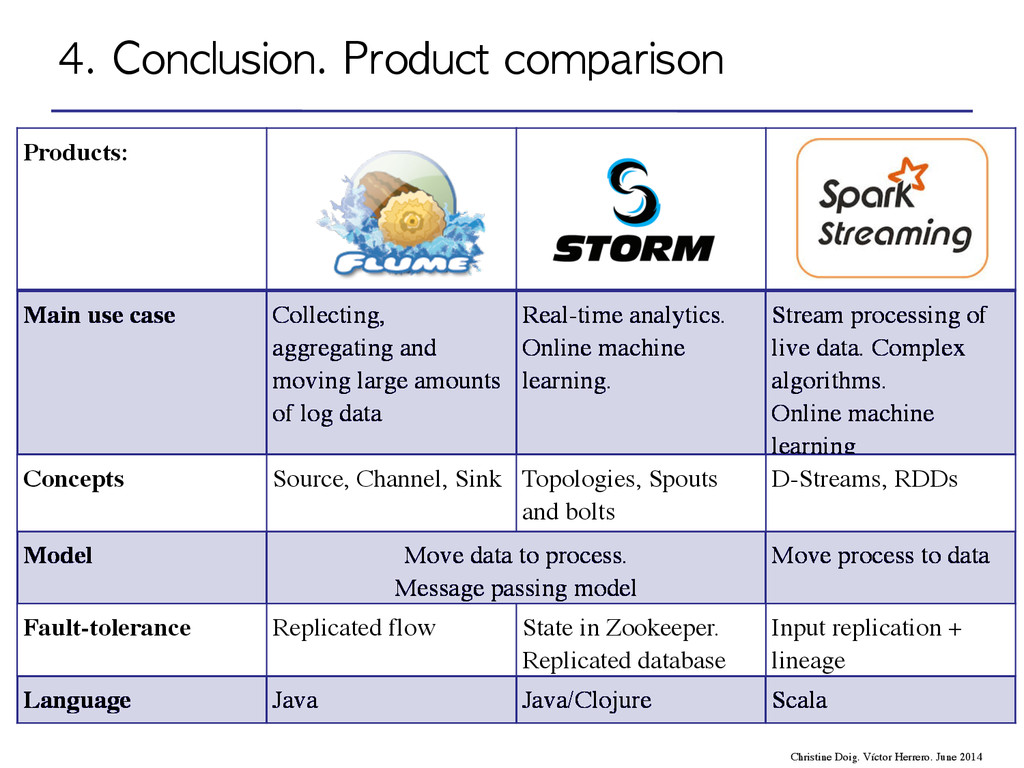
and moving large amounts of log data Real-time analytics. Online machine learning. Stream processing of live data. Complex algorithms. Online machine learning Concepts Source, Channel, Sink Topologies, Spouts and bolts D-Streams, RDDs Model Move data to process. Message passing model Move process to data Fault-tolerance Replicated flow State in Zookeeper. Replicated database Input replication + lineage Language Java Java/Clojure Scala Christine Doig. Víctor Herrero. June 2014
architecture: http://lambda-architecture.net/ •Book (not fully released yet): Big Data – Principles and best practices of scalable real-time data systems: http://www.manning.com/marz/BDmeapch1.pdf ! Flume Online Documentation: http://flume.apache.org/ Real time Data Ingest into Hadoop using Flume: http://events.linuxfoundation.org/sites/ events/files/slides/RealTimeDataIngestUsingFlume.pdf ! Storm Online Documentation: http://storm.incubator.apache.org/ Source code: https://github.com/nathanmarz/storm Book: Storm Processing Cookbook by Quinton Anderson Tutorial: http://hortonworks.com/hadoop-tutorial/processing-streaming-data-near-real-time- apache-storm/ ! ! Christine Doig. Víctor Herrero. June 2014
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}