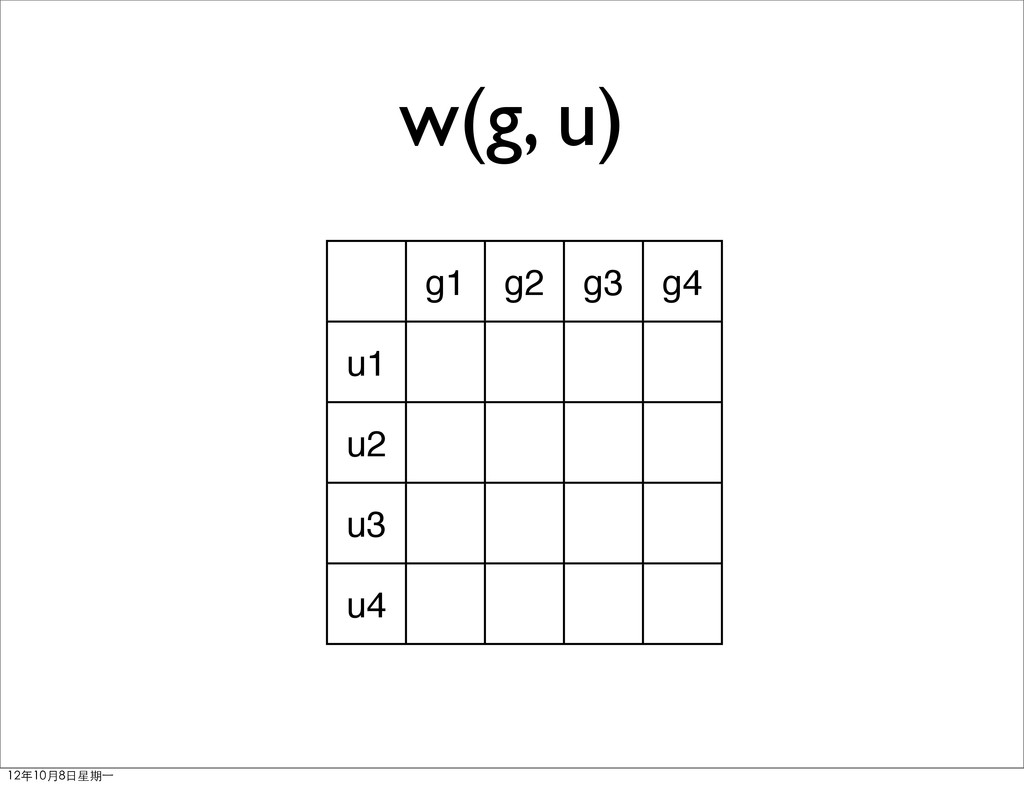
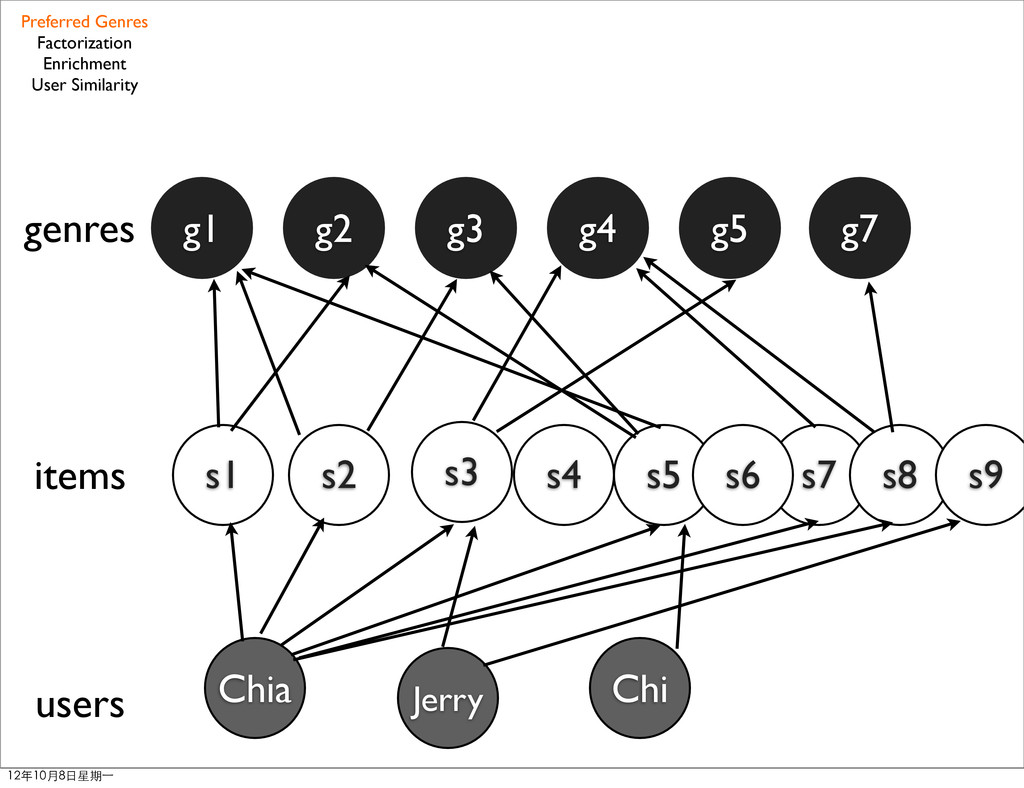
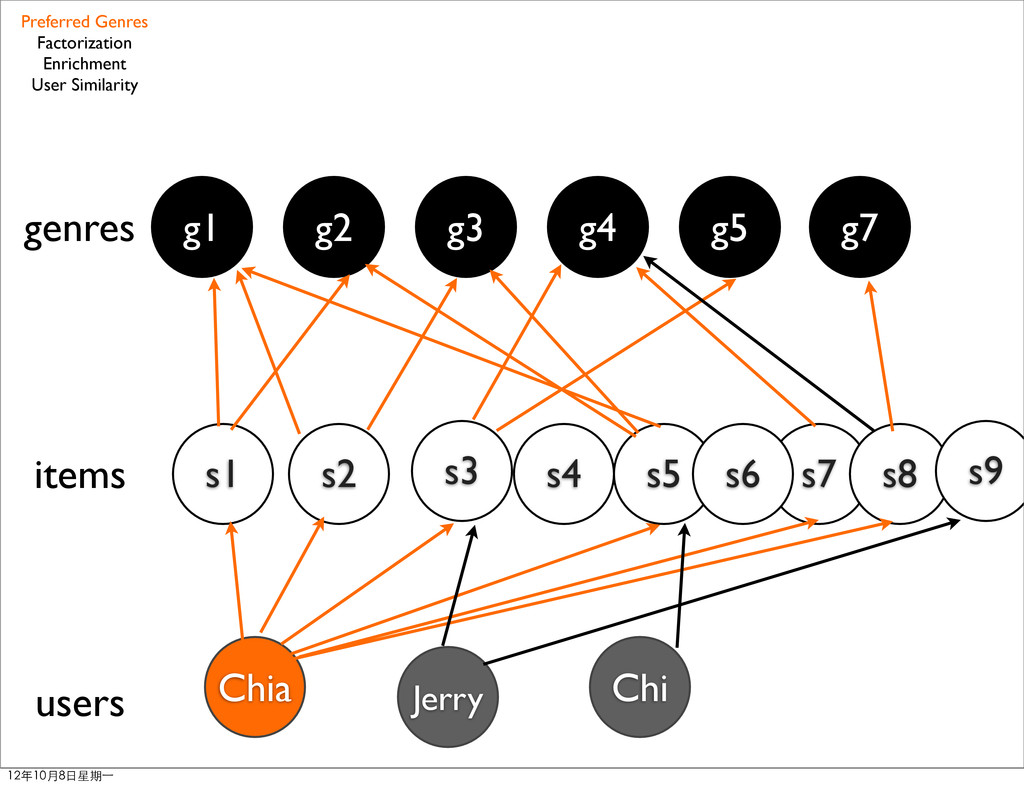
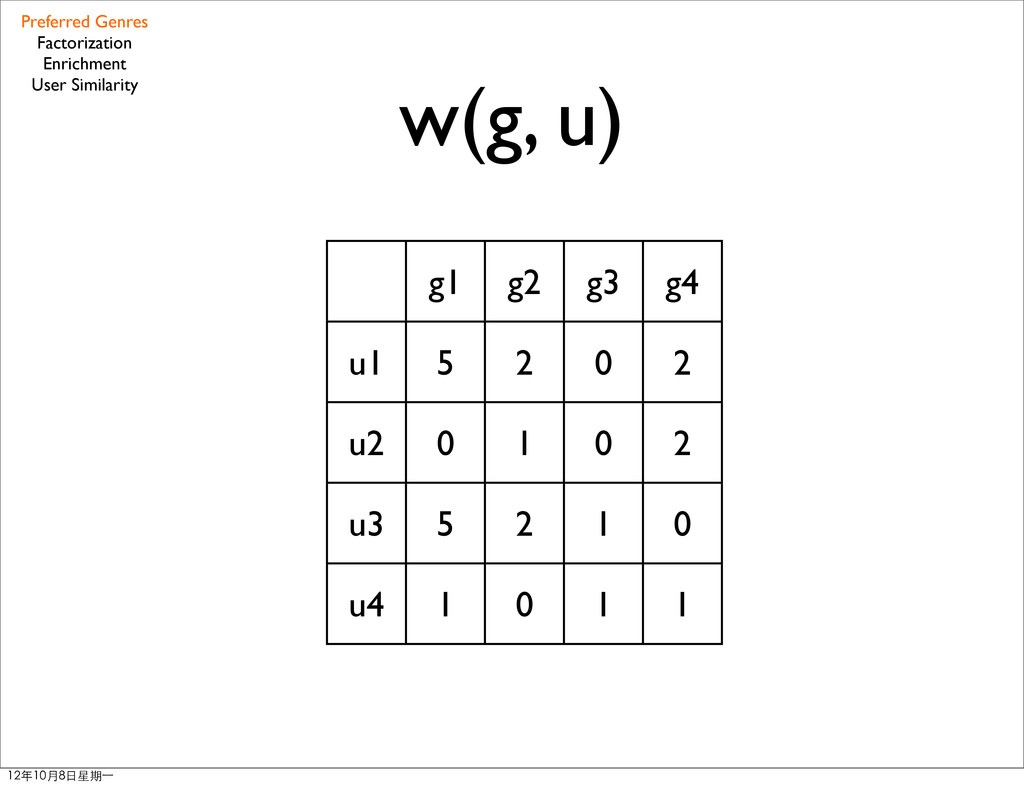
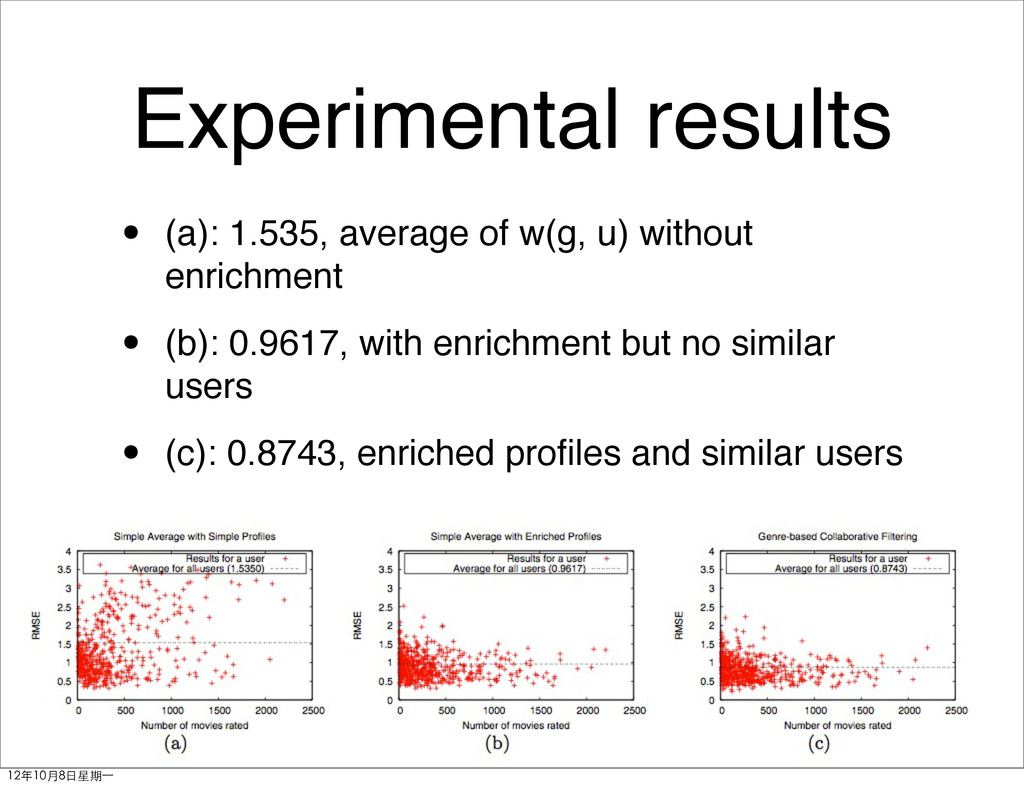
• G: genres • δu(s): the rating user u rated for item s • Su: items user rated • Gs: genres associated to items Preferred Genres Factorization Enrichment User Similarity 12年10月8日星期⼀一
g3)、s3(g4, g5)、s5(g1, g2, g3) • cloud_g(Chia, 5) = {(g1, 3), (g2, 2), (g3, 2), (g4, 1), (g5, 1)} • Chia rated 2: s7(g4)、s8(g4, g7) • cloud_g(Chia, 2) = {(g4, 2), (g7, 1)} • represents the frequency of occurrence of genre g for all items that user u has associated with rating r Preferred Genres Factorization Enrichment User Similarity 12年10月8日星期⼀一
g by user u • R(g4, Chia) = {5, 2}, |R(g4, Chia)| = 2 • tf-idf(g4, Chia, 5) = 1 * log(5/(1+2)) • the tf-idf value will reflect how important a genre is to a particular rating in the set of all ratings Preferred Genres Factorization Enrichment User Similarity 12年10月8日星期⼀一
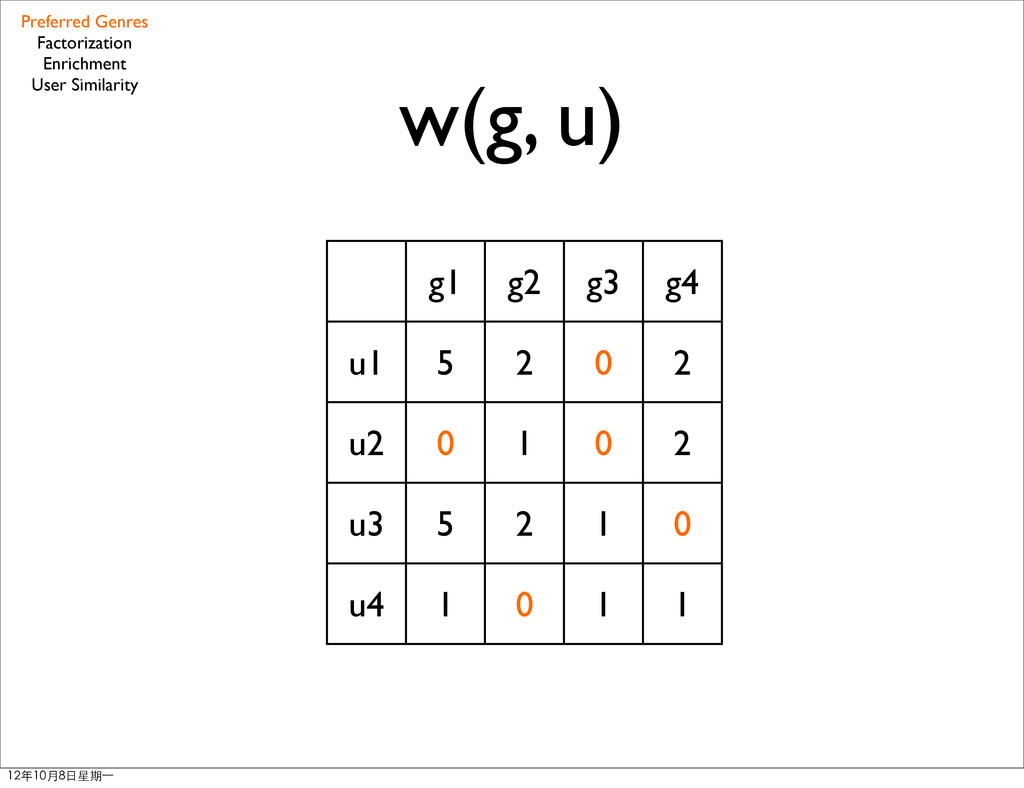
weights w(g, u) which are zero with the user average rating offset • less missing values Preferred Genres Factorization Enrichment User Similarity 12年10月8日星期⼀一
preference- relevance model • Vk:users’ interest in each of the k inferred topics • Tk:the genres’ relevance for each topic • singular values in Σ:represents the influence of a particular topic on user-genre preferences Preferred Genres Factorization Enrichment User Similarity 12年10月8日星期⼀一
of information in new user profiles • (2) adjusting the value of w(g,u) to consider the most relevant topics of interest associated to genre g • ex: an adjusted preference for science fiction will indicate the user’s interests for different topics, such as undead people, the end of the world and star wars. Preferred Genres Factorization Enrichment User Similarity 12年10月8日星期⼀一
• incorporate the topic preference-relevance model, we redefine w(g, u) as: • γ is a weighting parameter • Such values are a combination of user feedback, topic preference and relevance to associated genres Preferred Genres Factorization Enrichment User Similarity 12年10月8日星期⼀一
in order to enrich users profiles • Enrichment:adjust the user preference for a genre by considering the most relevant topics that compose the genre • less sparse because individual weights will be associated to a general information about all the content • factorization:infer latent semantics without metadata 12年10月8日星期⼀一
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}