Covering concepts from Chaos Engineering, Resilience Engineering, observability practices and experimentation as part of the cultural norm through the entire software dev and operations lifecycle. Tooling for Chaos Engineering, architectural patterns to consider when deciding on a tooling strategy, and real world examples of making Chaos Engineering part of the Condé Nast technology culture.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
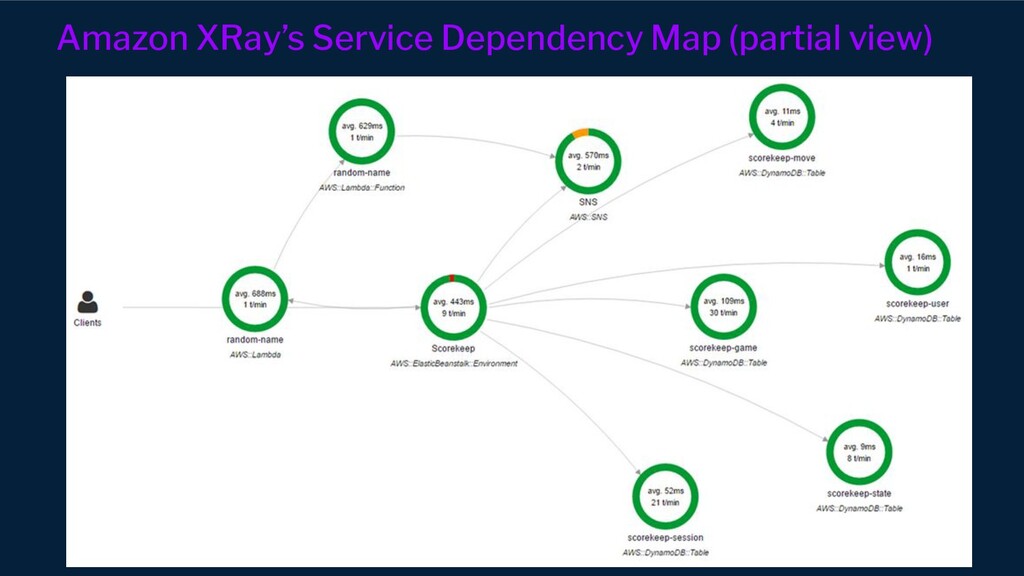{kind=link}
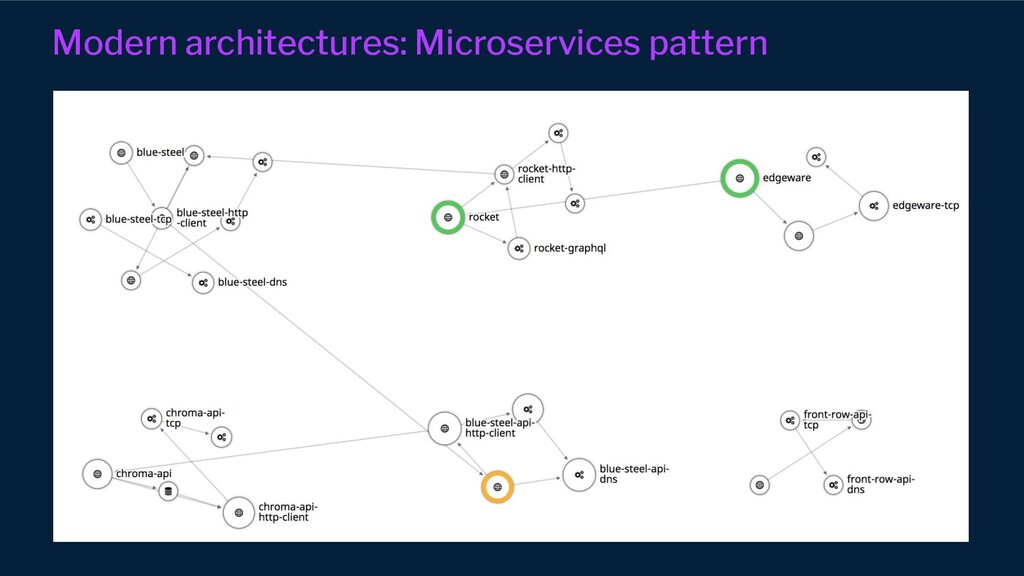{kind=link}
{kind=link}
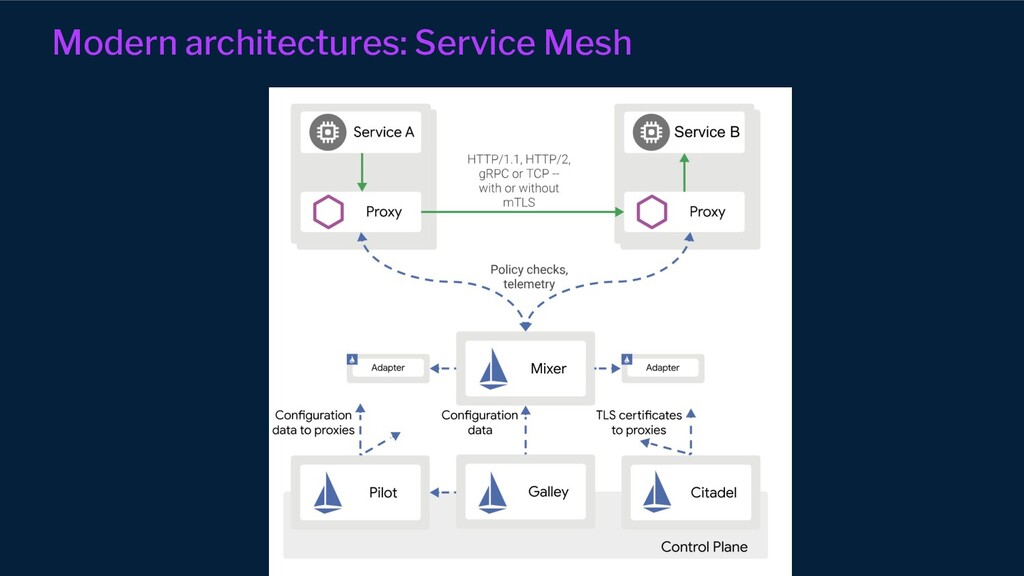{kind=link}
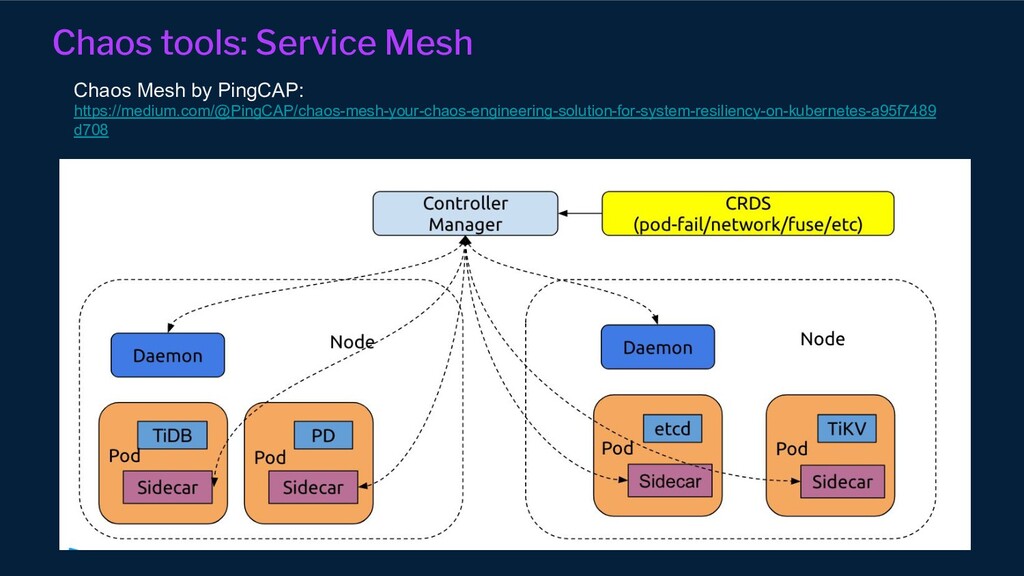{kind=link}
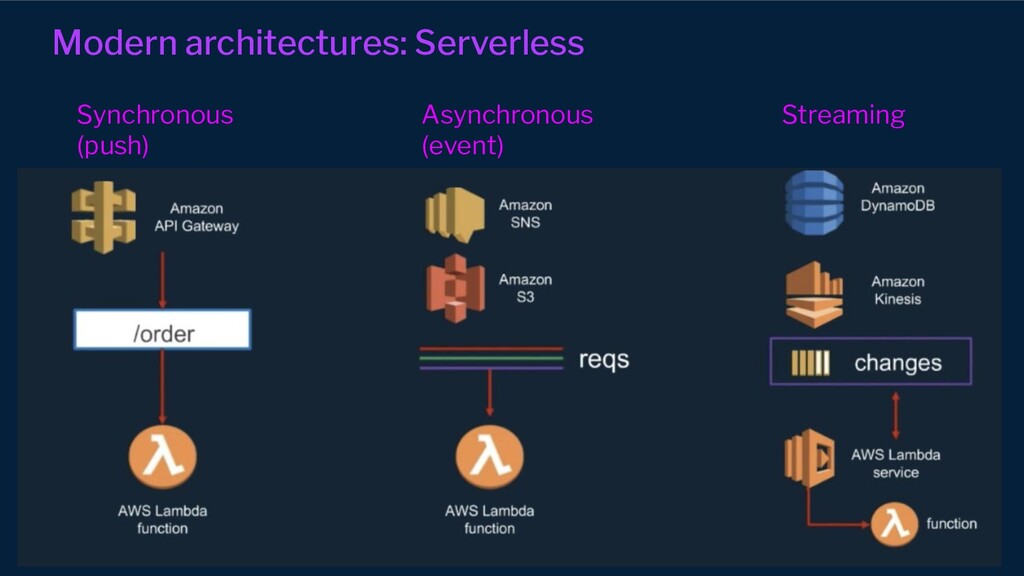{kind=link}
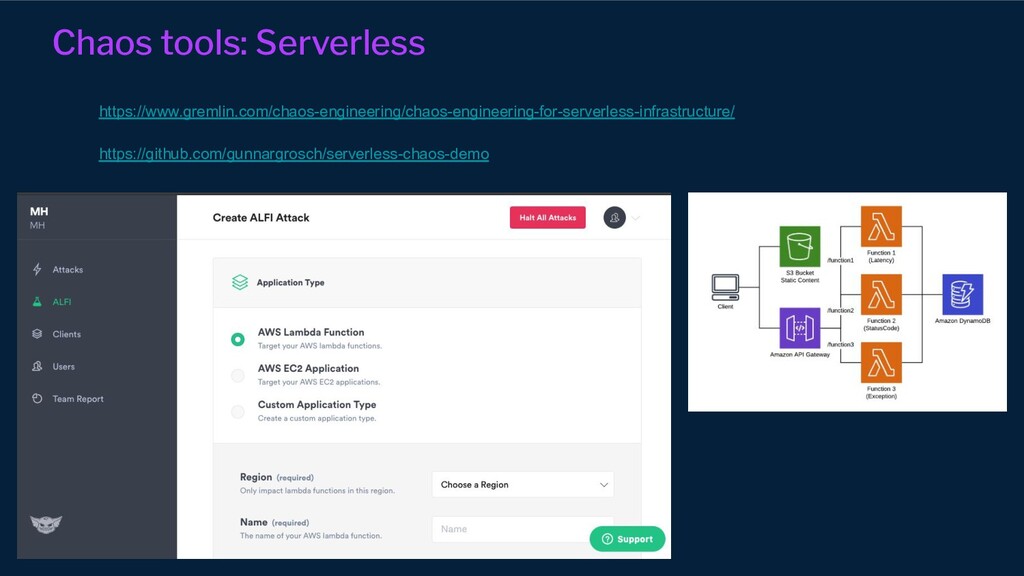{kind=link}
{kind=link}
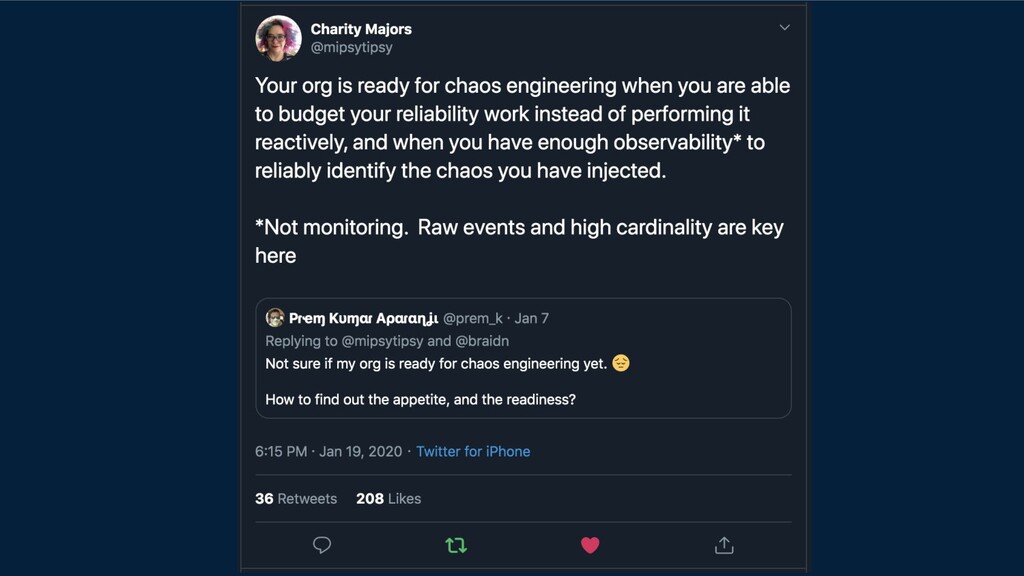{kind=link}
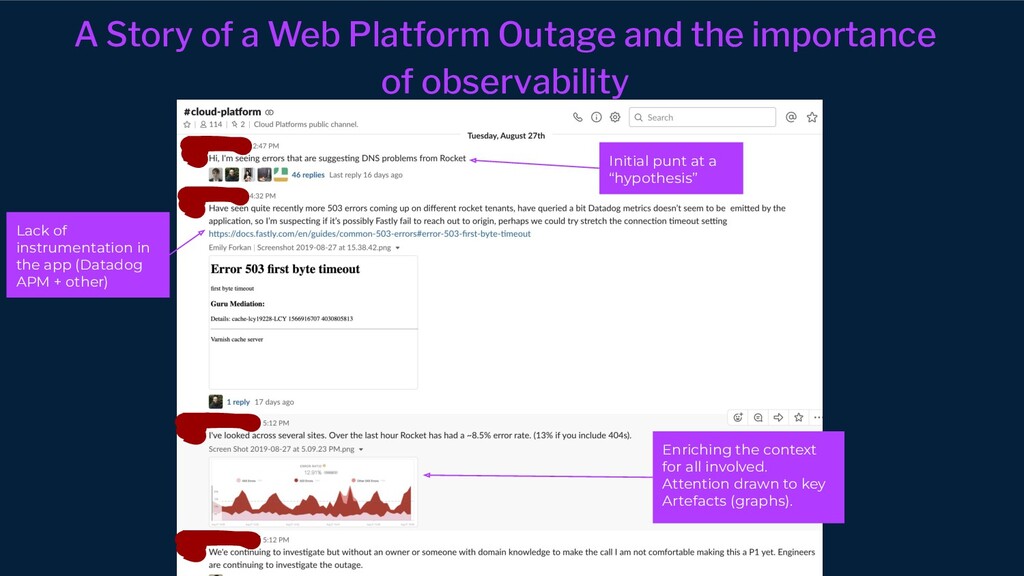{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}