"Systems fail all the time" goes the popular mantra in Reliability and Resilience engineering fields. Given this premise, industry leading organisations' practices have accelerated and matured several degrees to where we were even a few years ago. Organisations are beginning to stretch beyond their homegrown approaches to building organisational resilience to leveraging the expertise within the industry, and integrating approaches directly into the software deployment lifecycle through commoditised Chaos services.
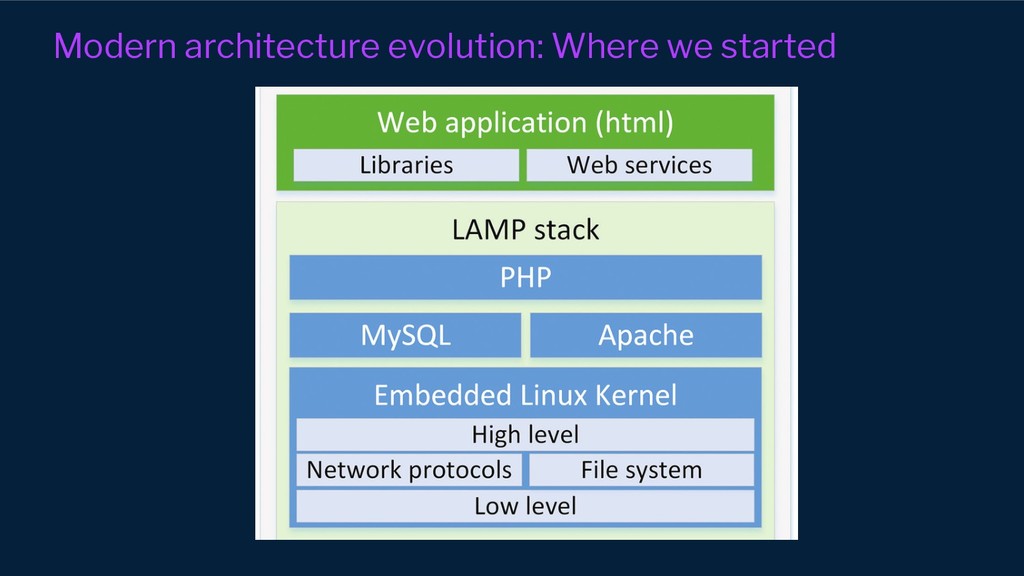
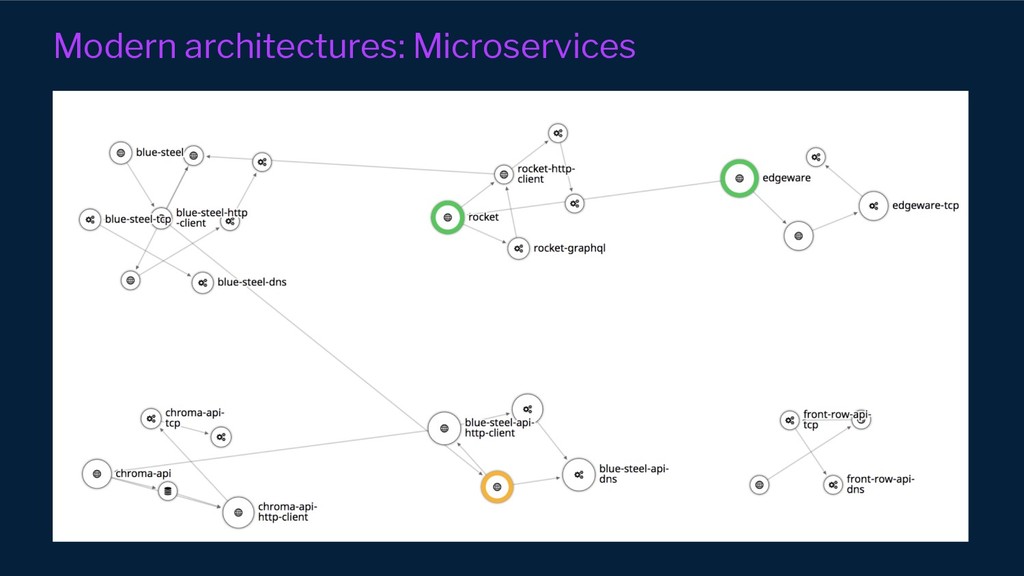
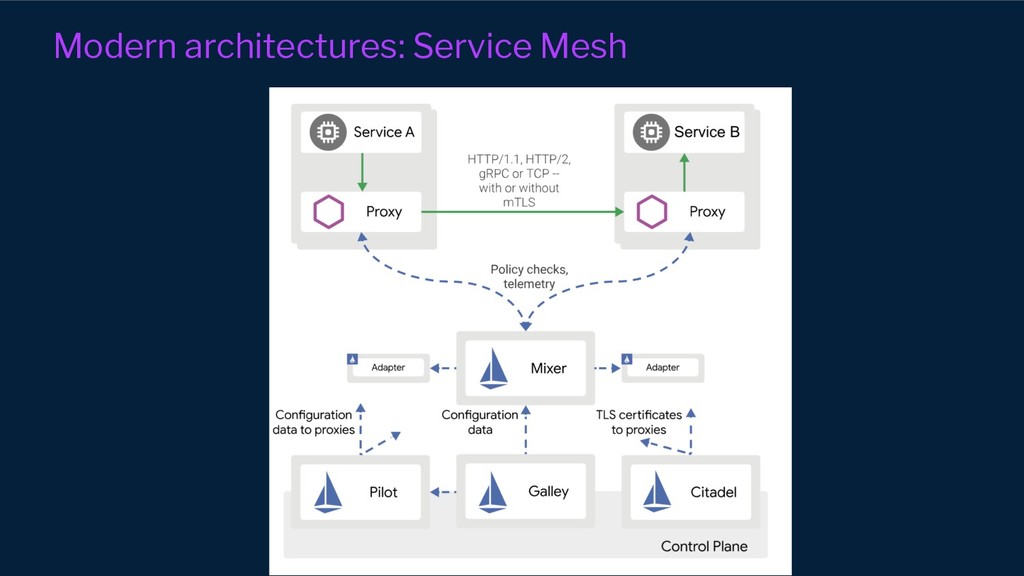
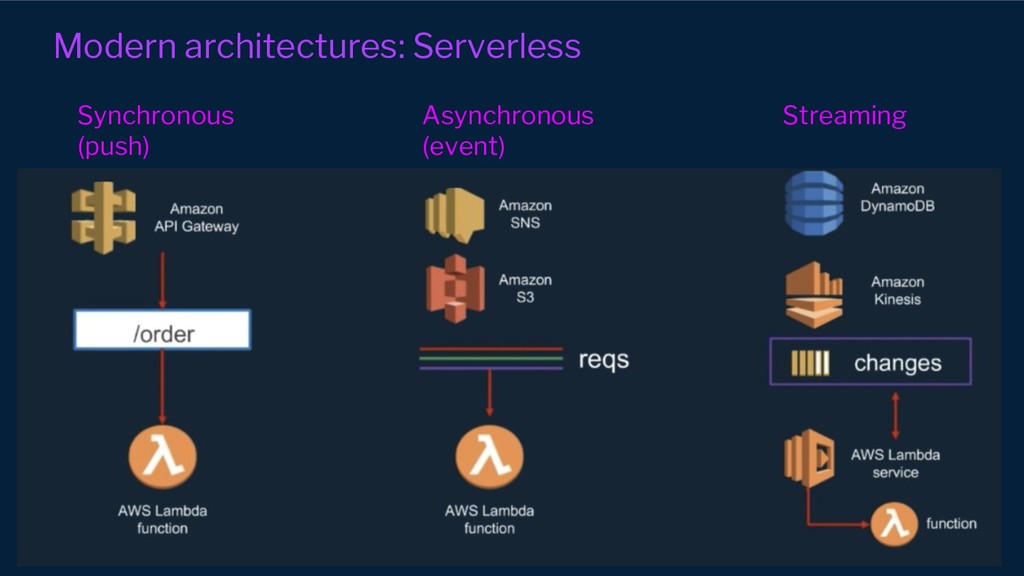
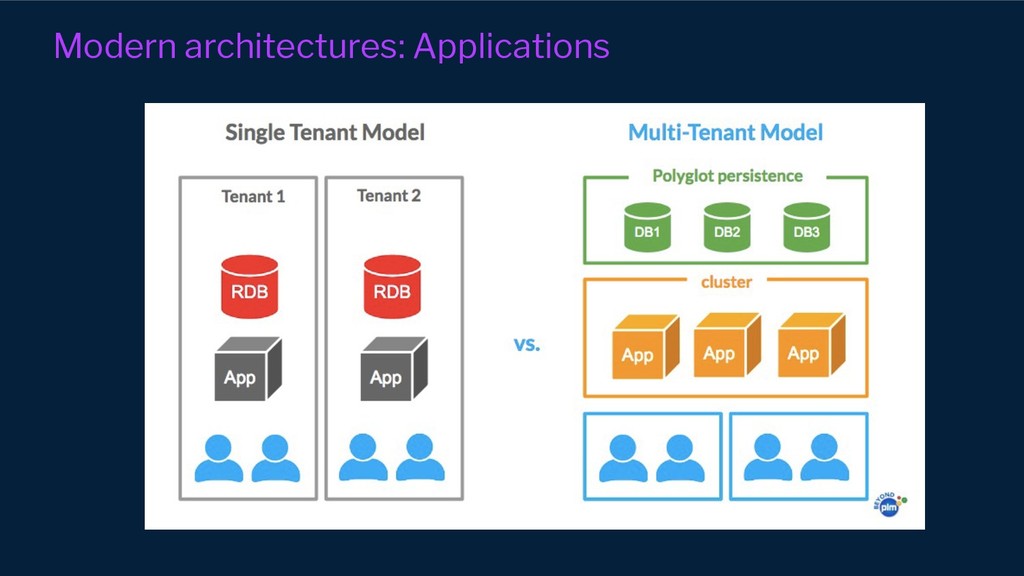
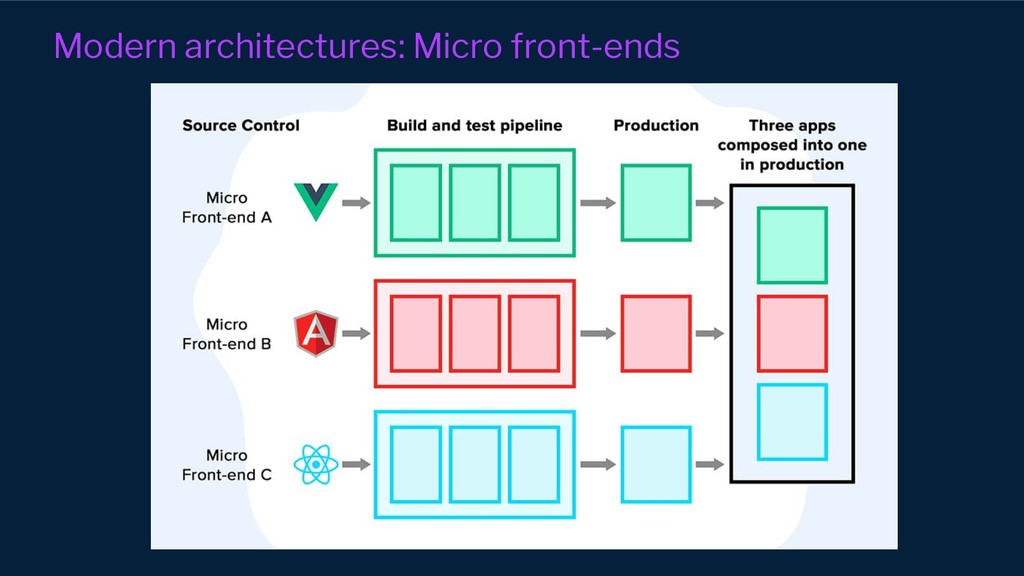
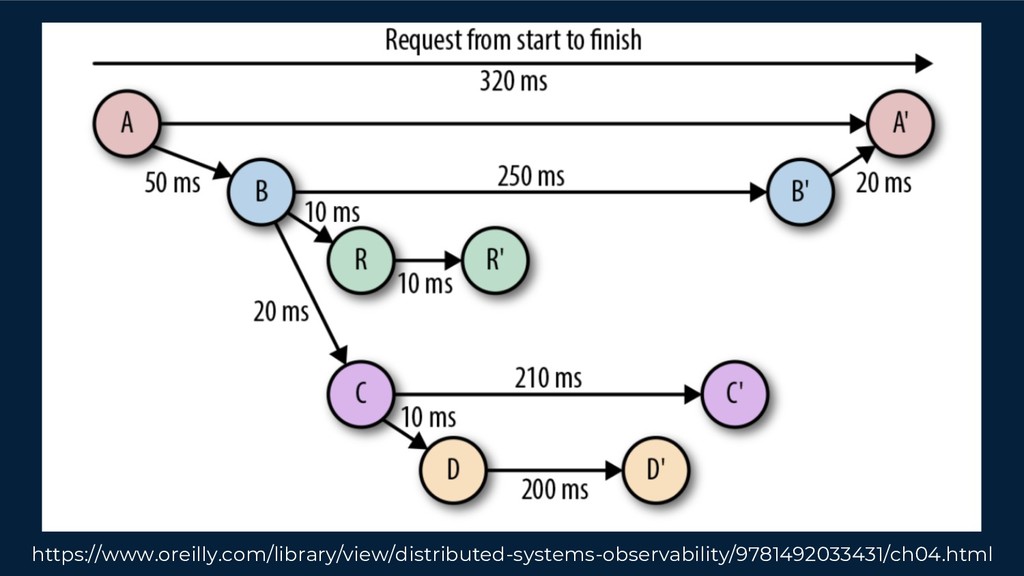
However, our systems and organisations keep growing in complexity under the ever-increasing pressure for efficiency and scale. Our architectural approaches and paradigms keep shifting to cope with the complexity of distributed system domains such as wide adoption of microservices, Serverless, multi-tenancy and micro front-ends development approaches.
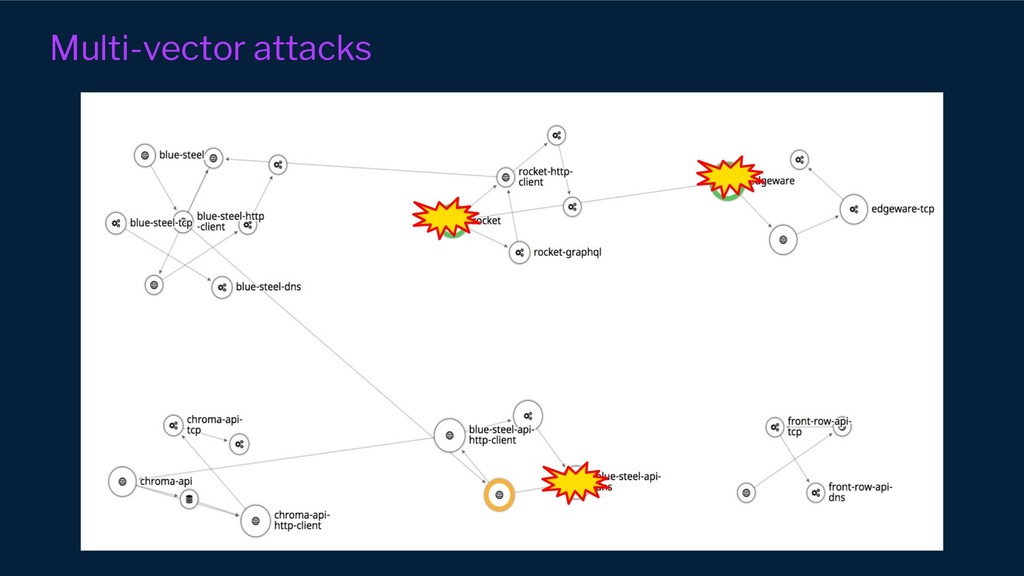
A current limiting factor in running Chaos experiments is their contrived nature - we must think ahead what could go wrong. Is this true to experience? What about the sense of surprise that usually pervades failure situations? How can we facilitate more random, generative experiments?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
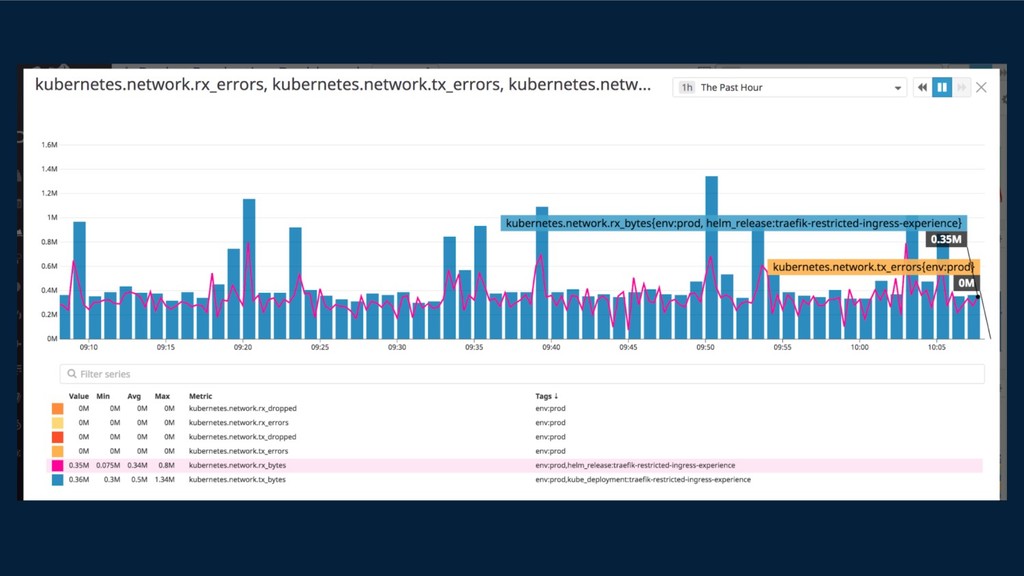{kind=link}
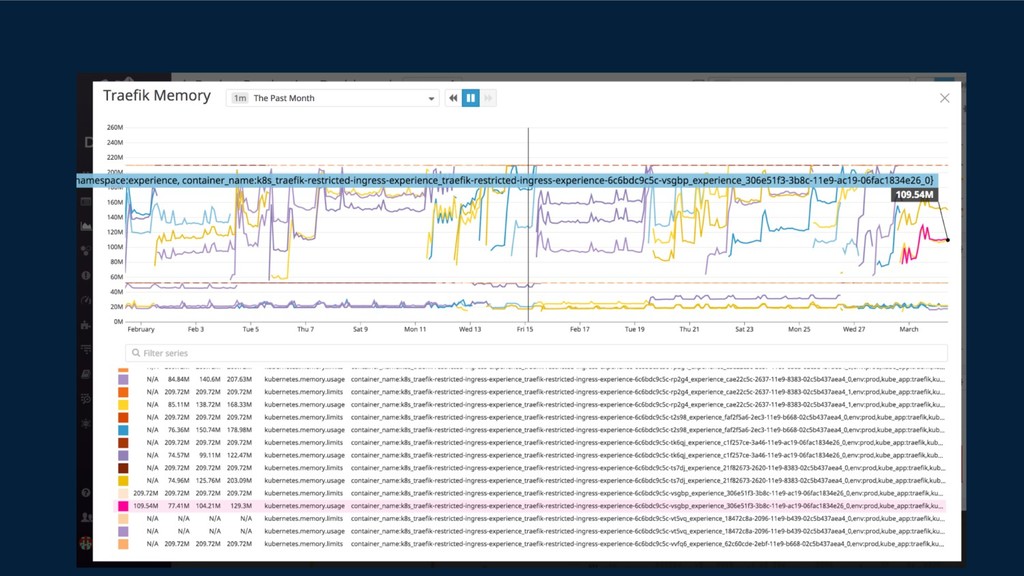{kind=link}
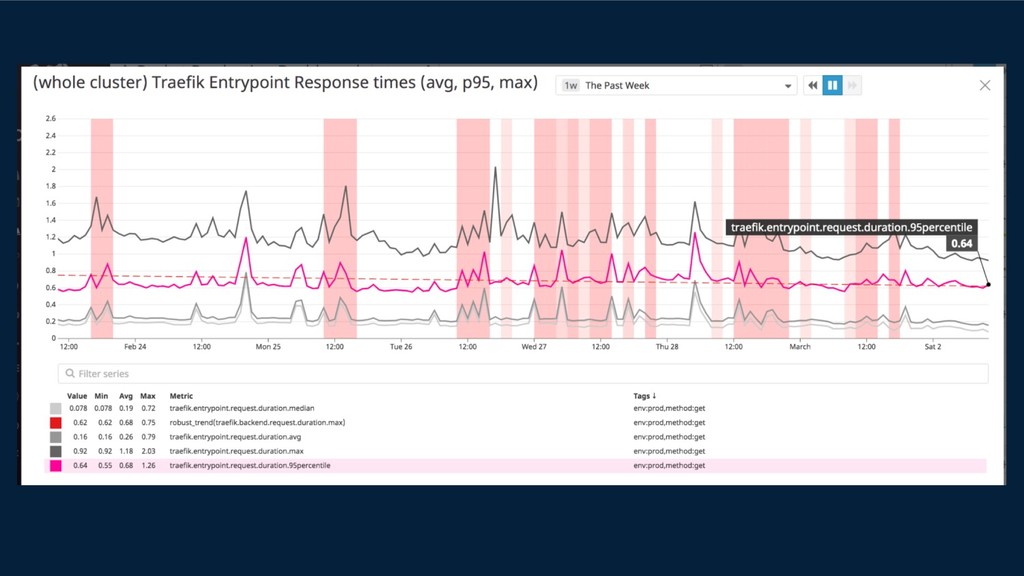{kind=link}
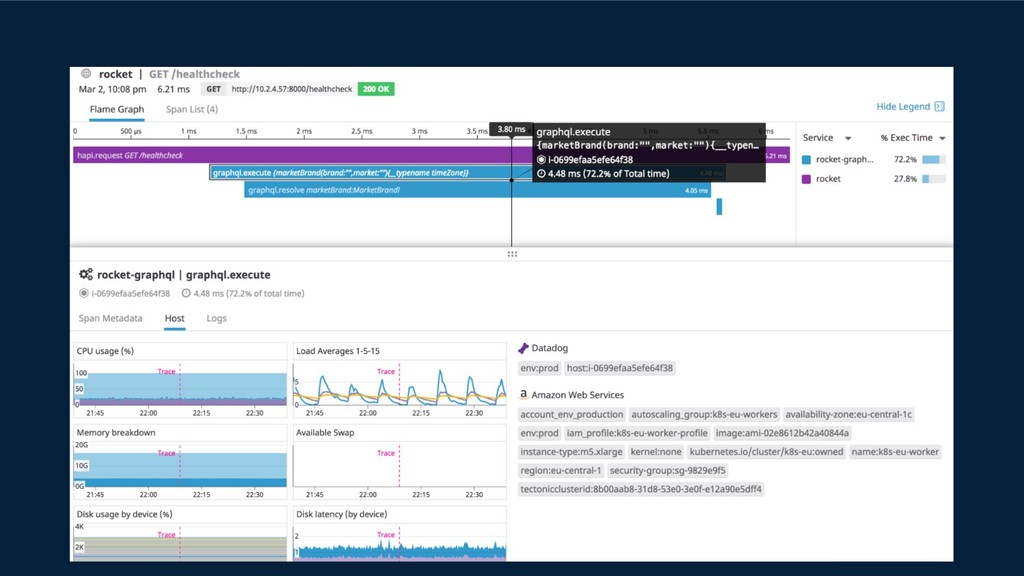{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}