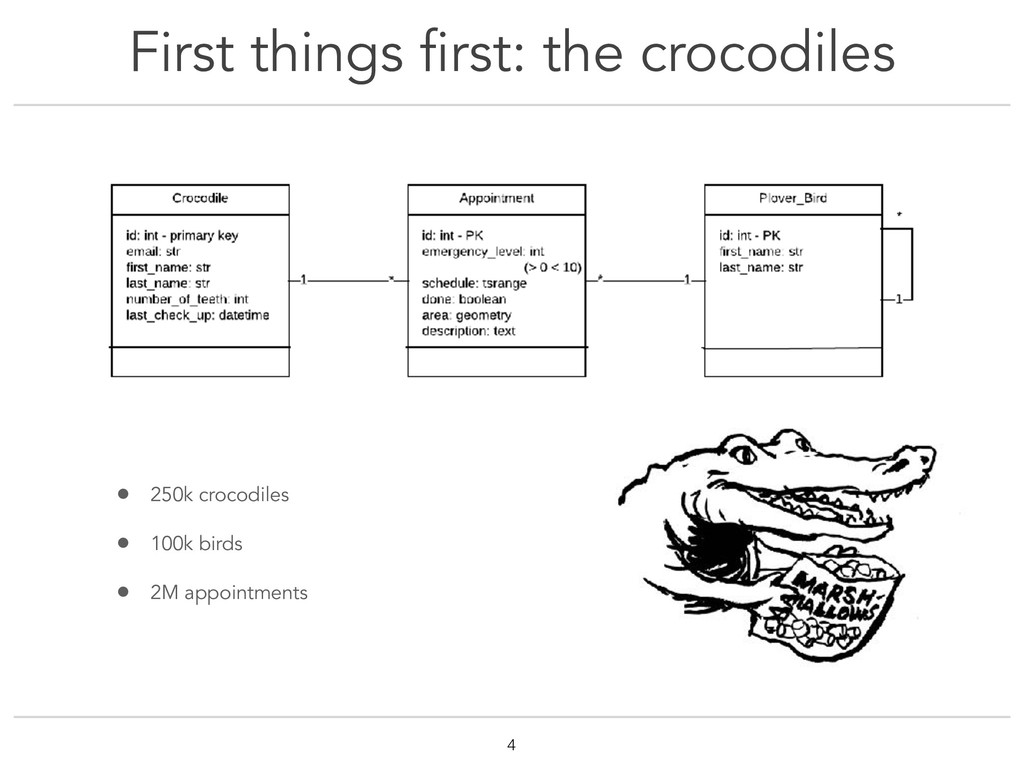
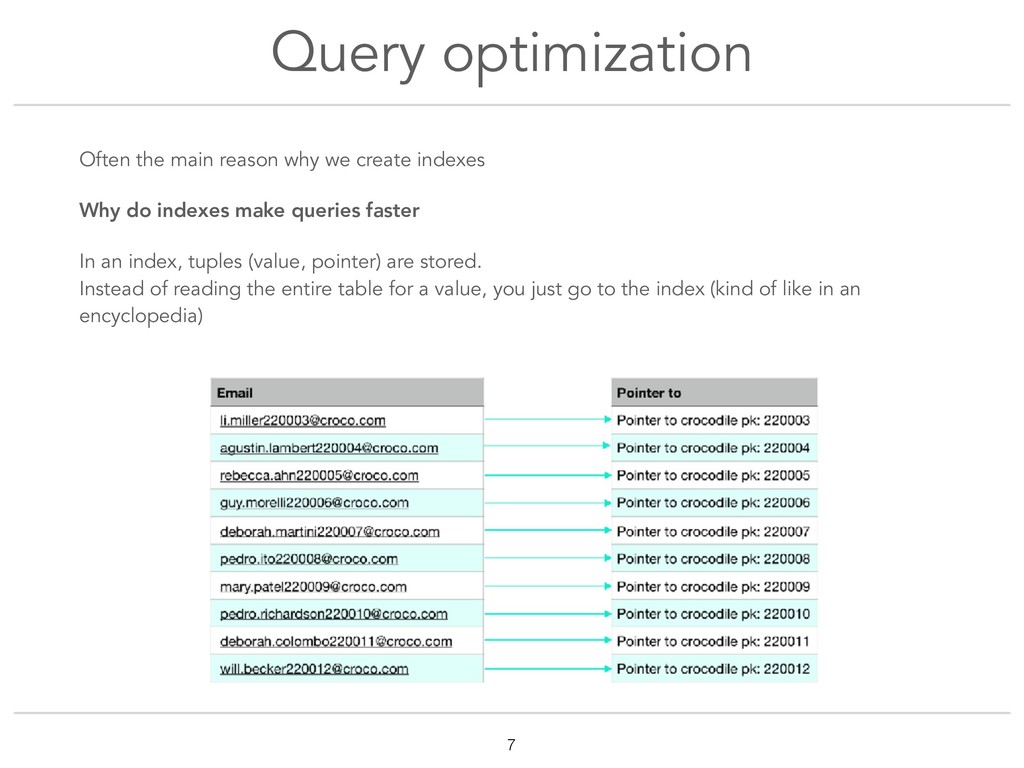
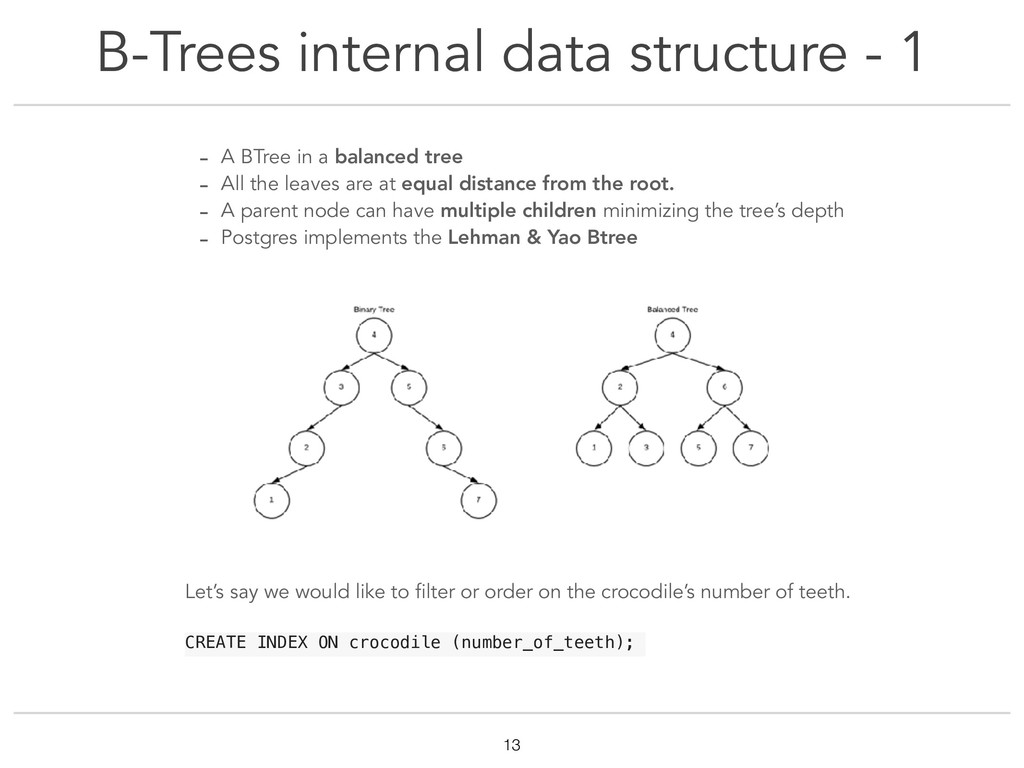
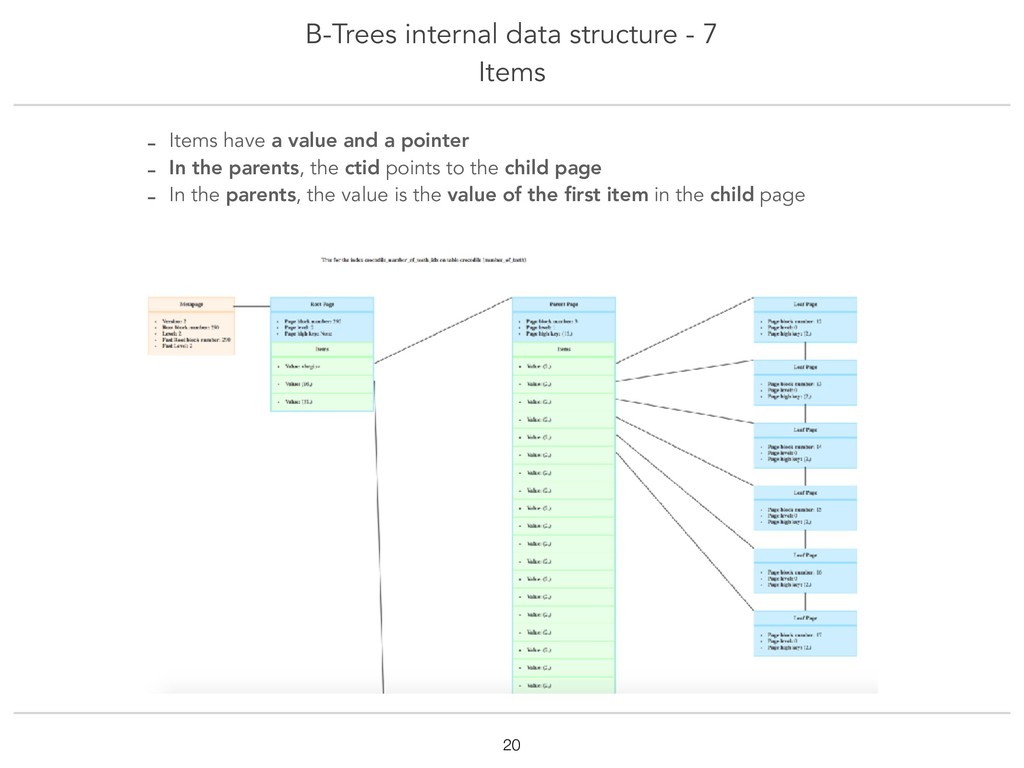
Really often, what we, developers, do something that would drive DBAs crazy: we trust our ORM to handle the creation of indexes. That's so easy ! Why not use it right? So what's the problem then ? Well most ORMs only use BTree indexes. Often, it's what we need. But why cut ourselves from all the other index types ? This talk covers PostgreSQL indexes types (B-Tree, GIN, GiST, SP-GiST, BRIN and Hash). We will take a look into how each type is implemented in Postgres source code and why it makes it more fit to certain data types. Through the very real example of an application to organise crocodiles dentist's appointments, examples of use-cases for each index type will be explained to understand how to choose the right type. At the end of the talk, you should be familiar with the internal data structure of indexes, which could help you choose the best index for you data type and query operators !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
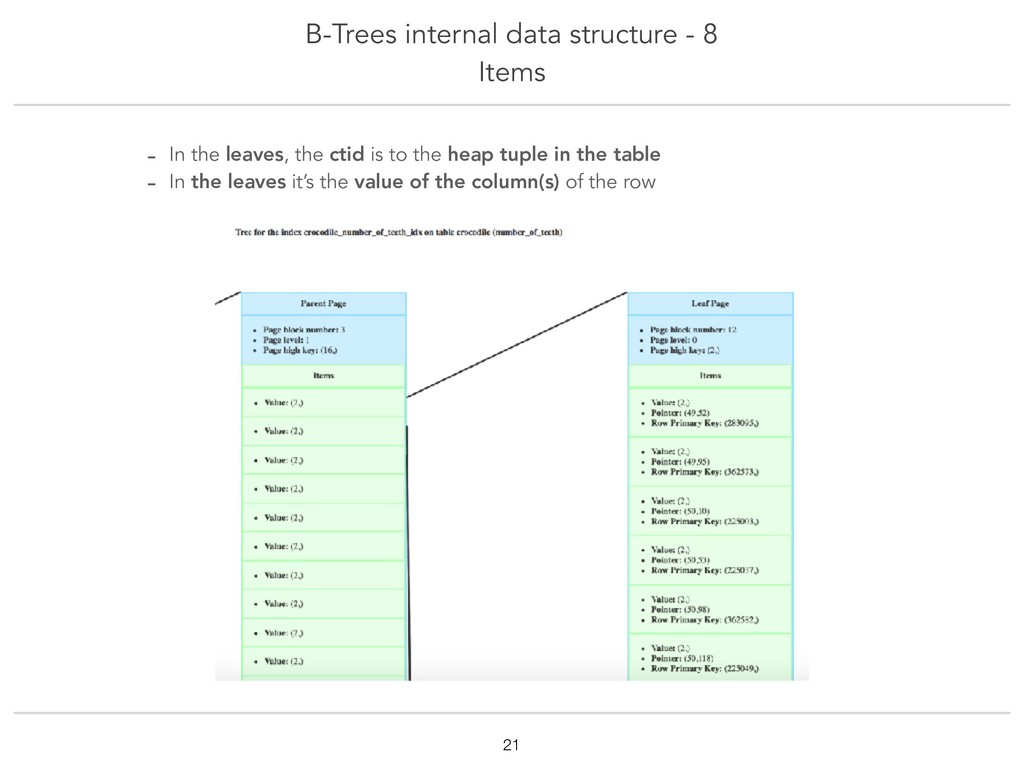{kind=link}
{kind=link}
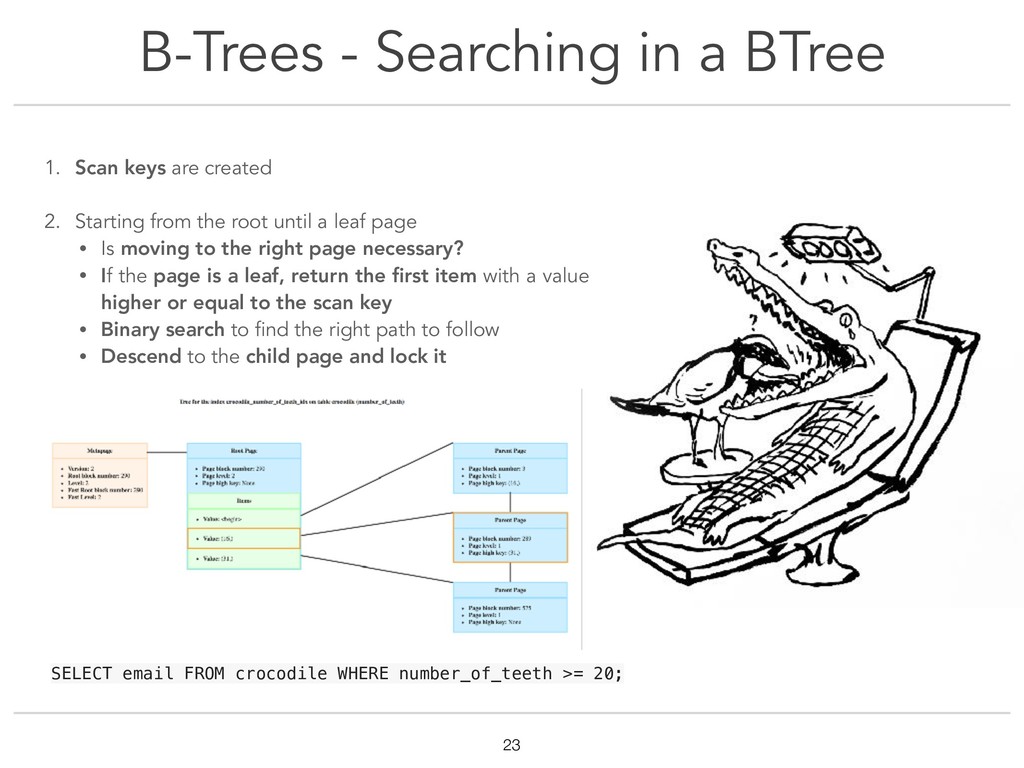{kind=link}
{kind=link}
{kind=link}
{kind=link}
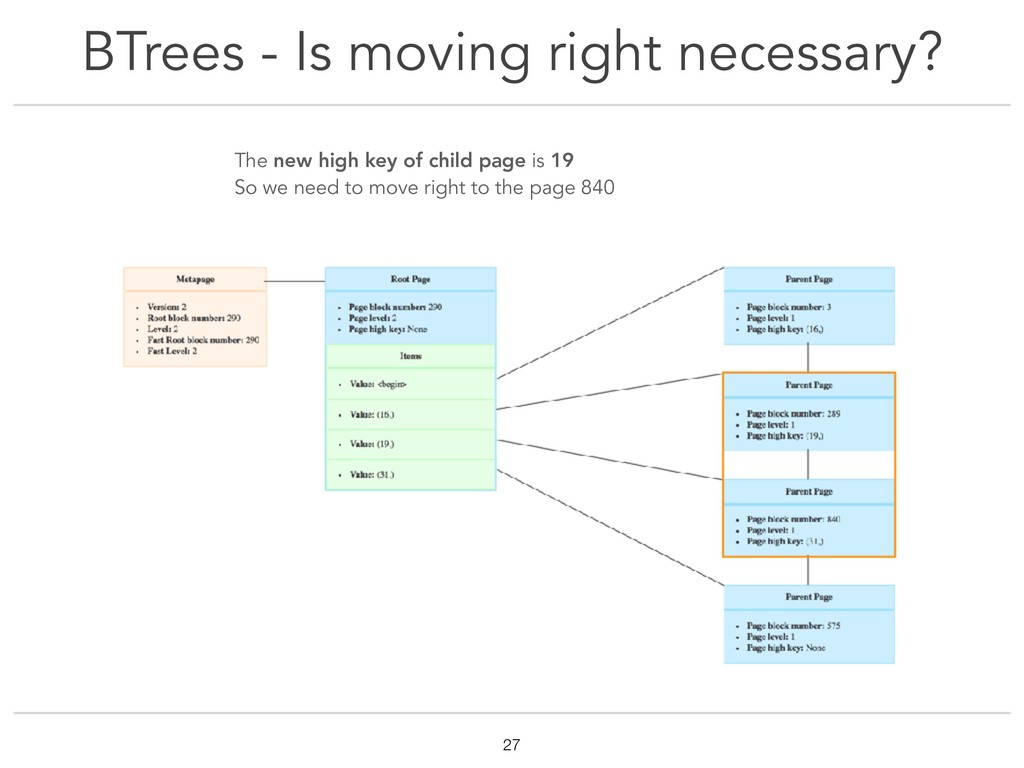{kind=link}
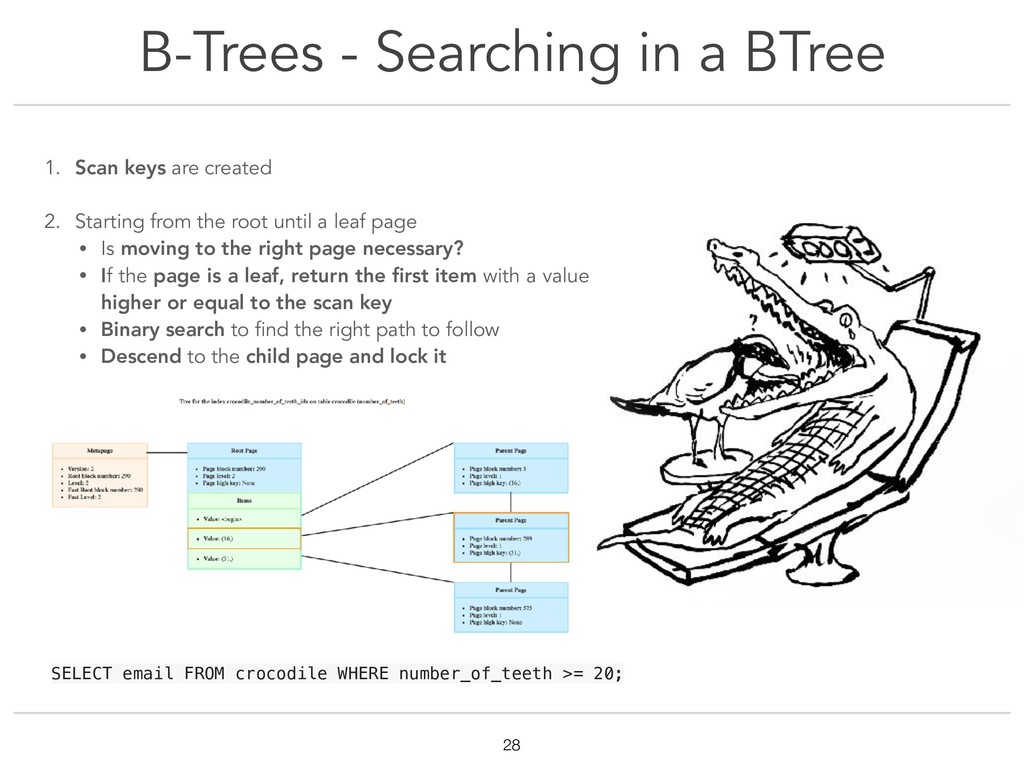{kind=link}
{kind=link}
{kind=link}
{kind=link}
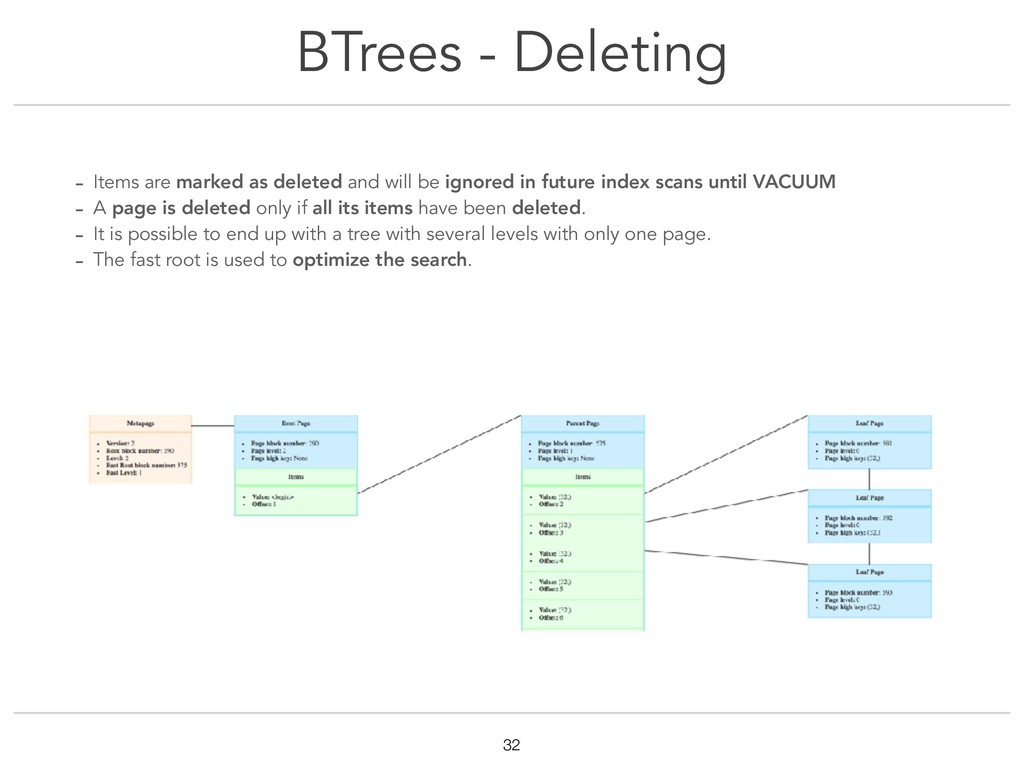{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
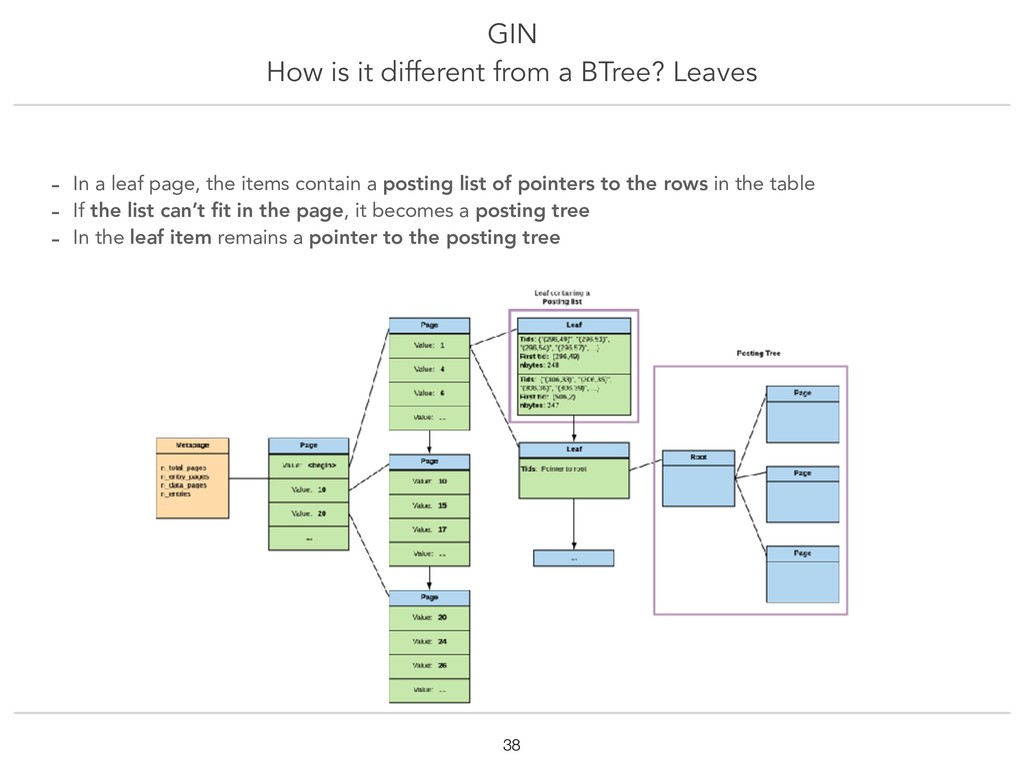{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
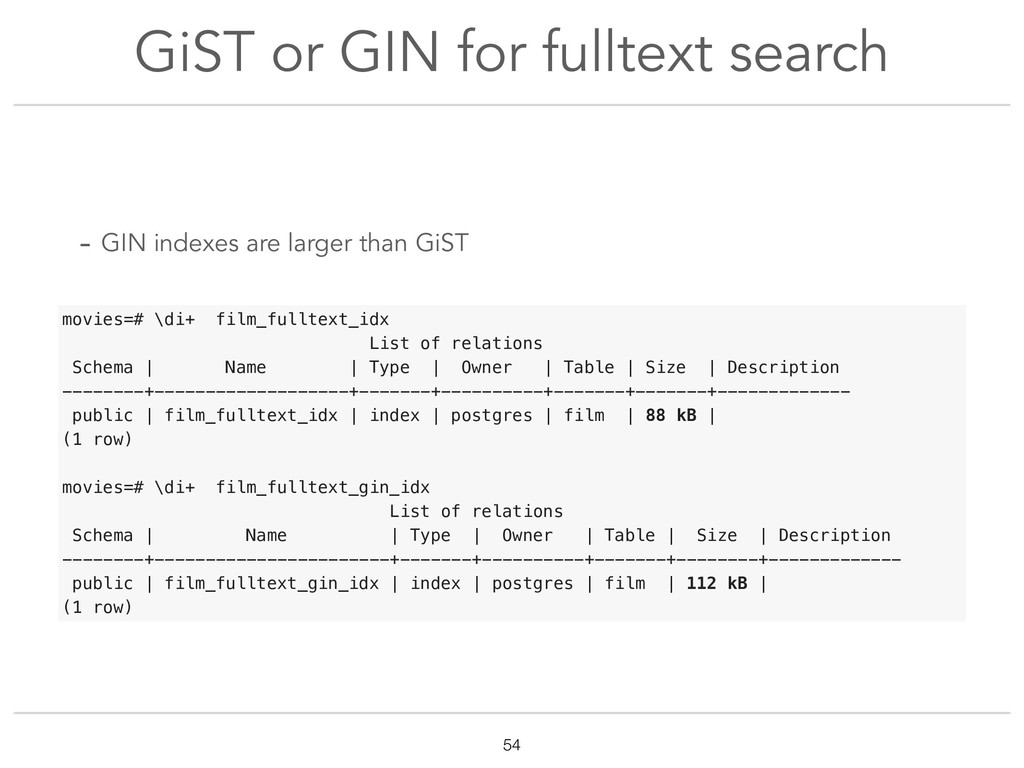{kind=link}
{kind=link}
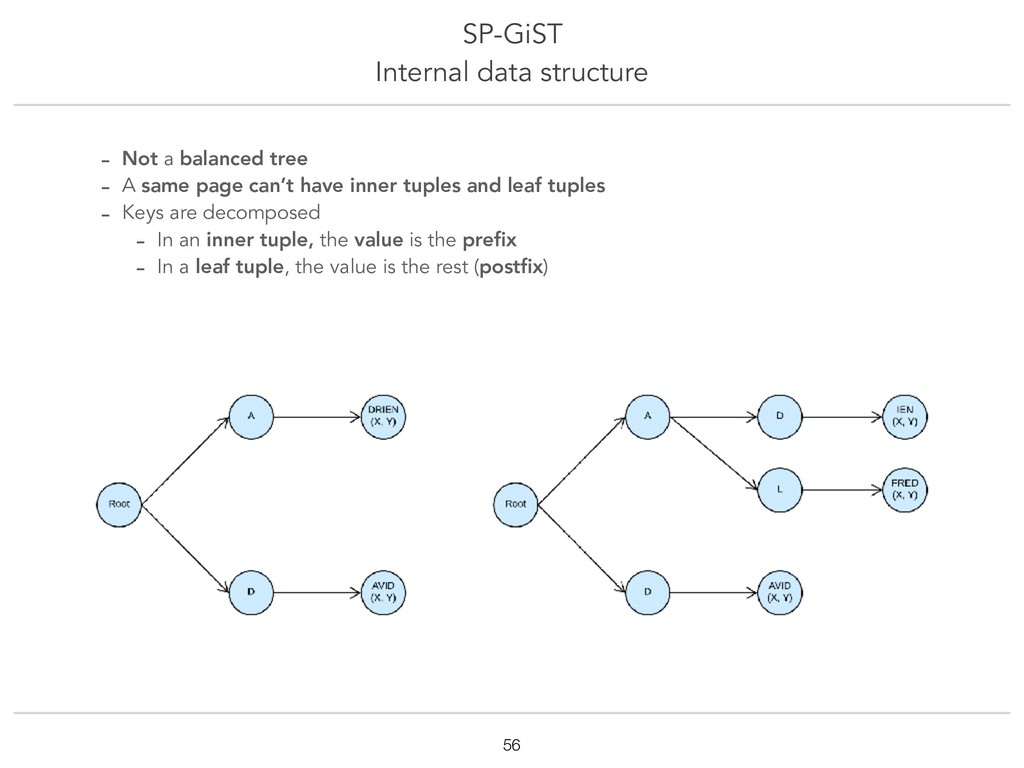{kind=link}
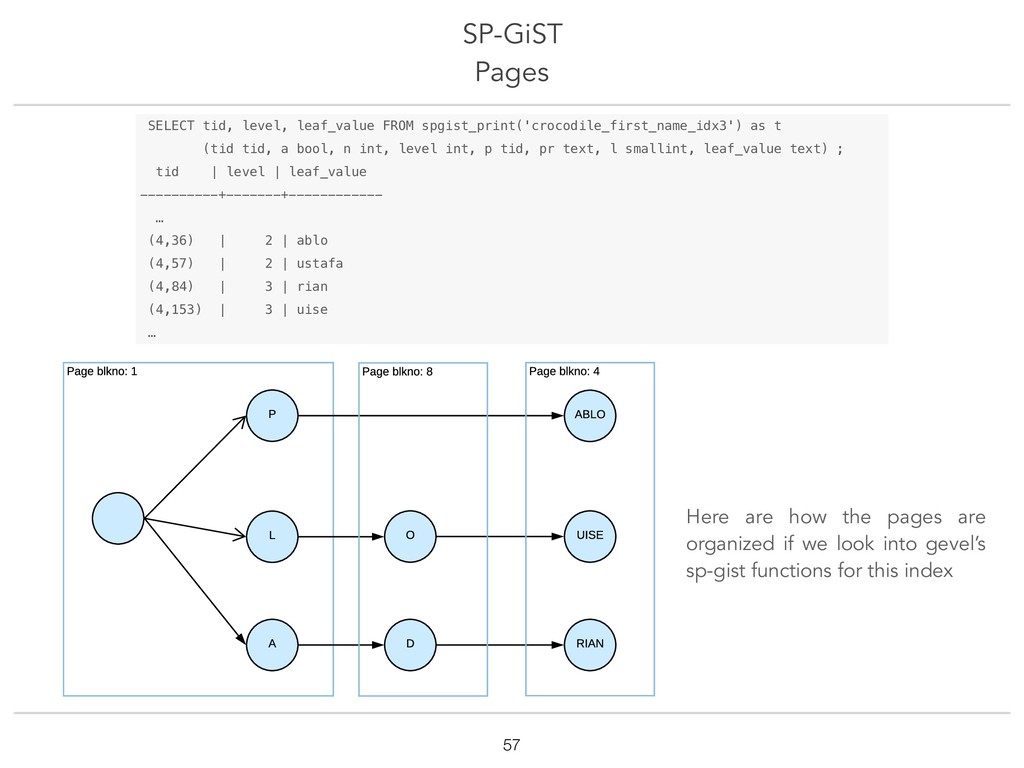{kind=link}
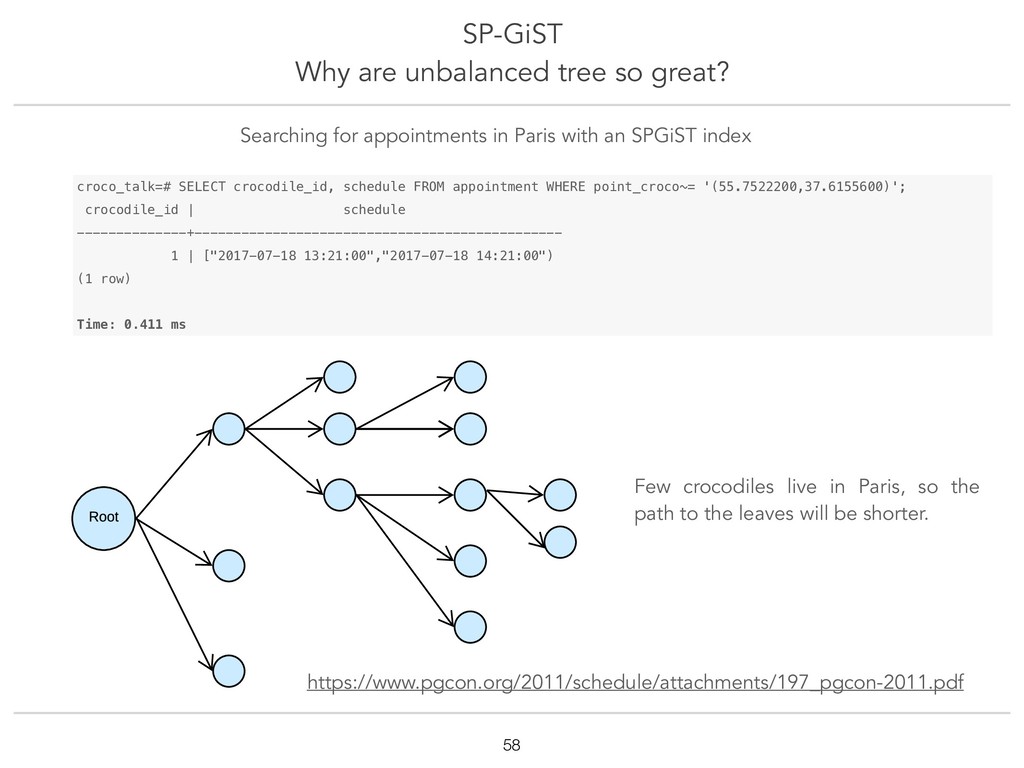{kind=link}
{kind=link}
{kind=link}
{kind=link}
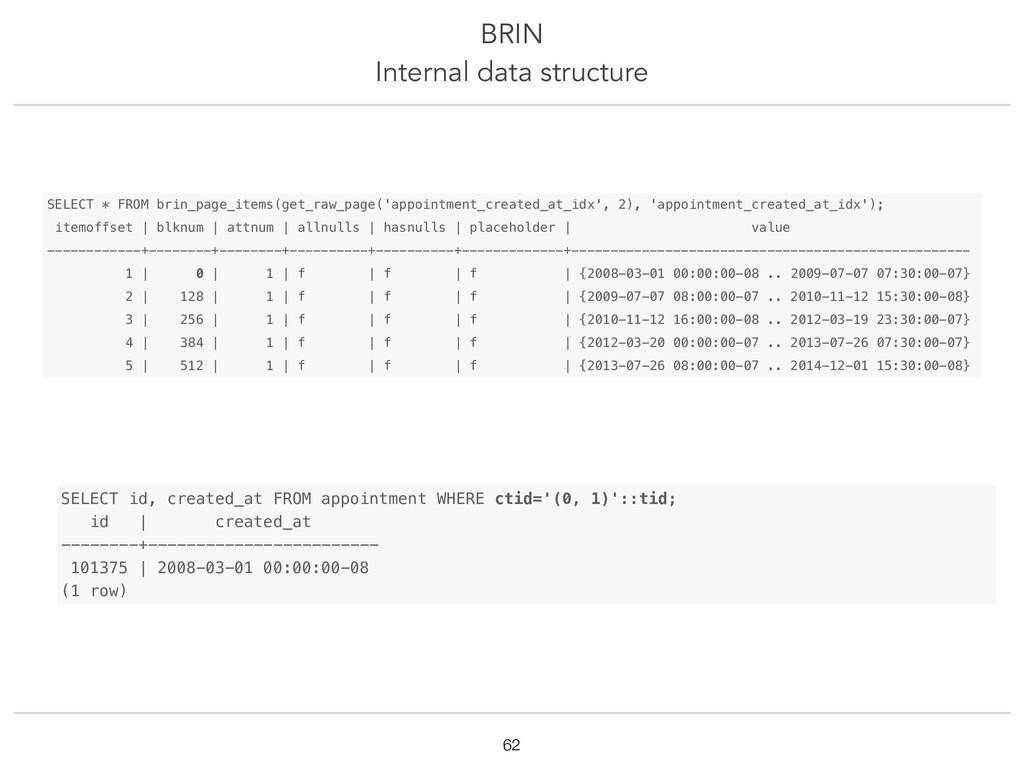{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}