is a REST interface Frontend uses ES6 and React/Redux 100% Open Source components Development infrastructure Self hosted Gitlab (git, issues, Docker registry) Jenkins - Builds are executed on DigitalOcean and pushed to the Docker registry 6
Reliability, Isolation − Operational complexity starjack communicates with many different 3rd party systems Uses multiple protocols like REST and SOAP Used to isolate services from each other If one service has problems or is down not everything is affected Should one service get compromised an attacker does not get access to all data Reduces complexity of individual services It’s easier to manage 12 services with 2k LOC than 1 service with 24k LOC When you change one system you can only break so much 8
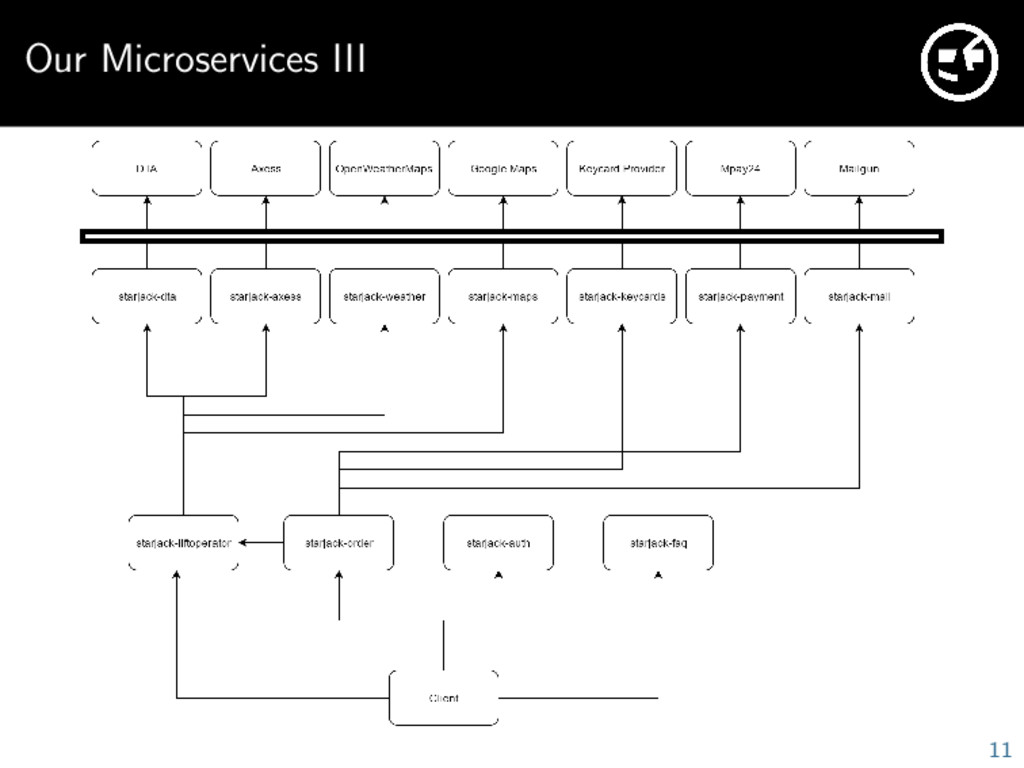
starjack-dta Gets tickets from lift operators using the DTA interface from SkiData AG starjack-axess Gets tickets from lift operators using the Axess interface from Axess AG starjack-liftoperator Manages our lift operators and works as a facade for dta and axess starjack-order Verifies and processes customer orders. Creates invoices and sends emails starjack-payment Handles payments with the Mpay24 PSP 9
party supplier and updates status once produced starjack-weather Retrieves current weather for lift operators, currently using OpenWeatherMaps starjack-maps Used to get map locations for lift operators and for travel duration estimation. Uses Google Maps starjack-faq Used to manage FAQ entries starjack-mail Sends mails using Mailgun mail service As the system grows we will have more services instead of growing one monolithic system without bounds 10
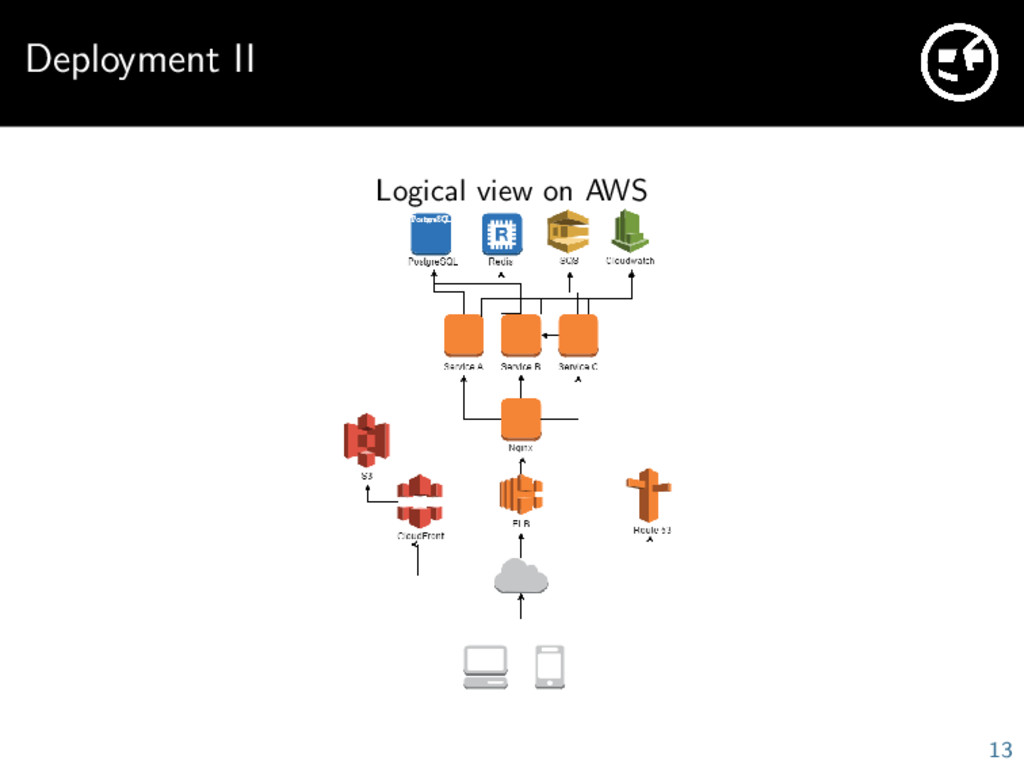
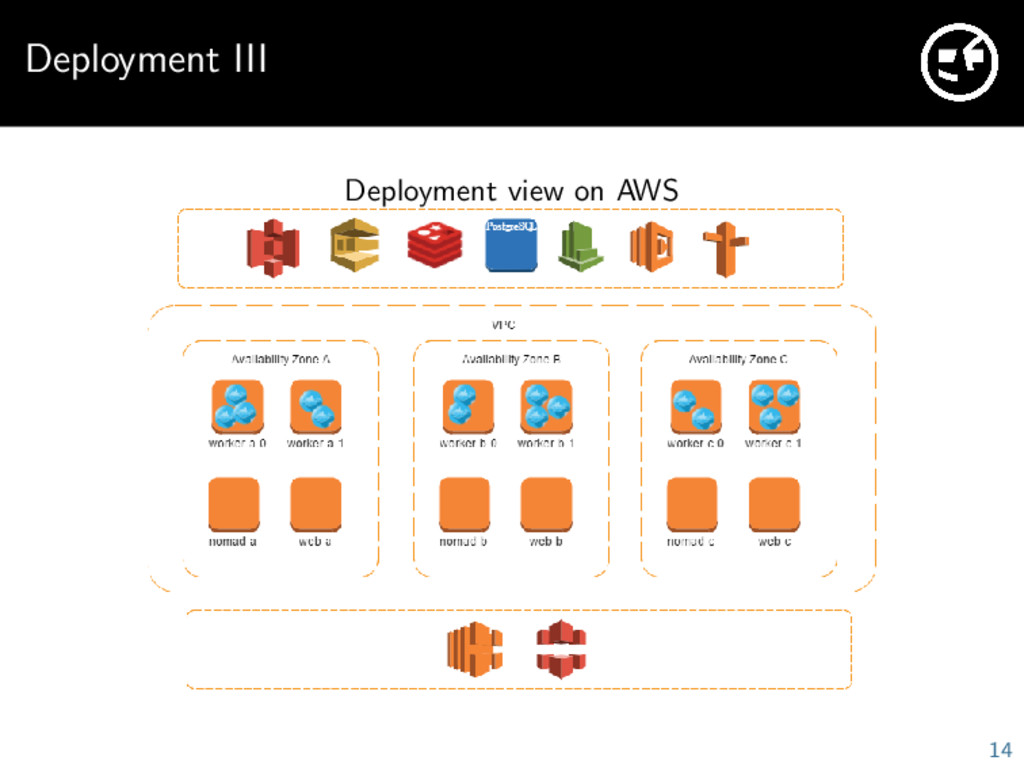
tons of services, everything is fully automatable Very high reliability possible if your architecture supports it Great security properties because you get your own software defined network Everything is deployed in three availability zones We use many AWS services: EC2, S3, CloudFront, RDS, ElastiCache, SQS, Route53, CloudWatch, . . . 12
with a microservices architecture? Very good fully automated infrastructure management is key, see Martin Fowler’s “You need to be this tall to use microservices” Fowler says you need to be able to rapidly provision servers have very good monitoring and logging infrastructure have deployment automated Bonus points if you can programatically recreate your infrastructure from scratch 16
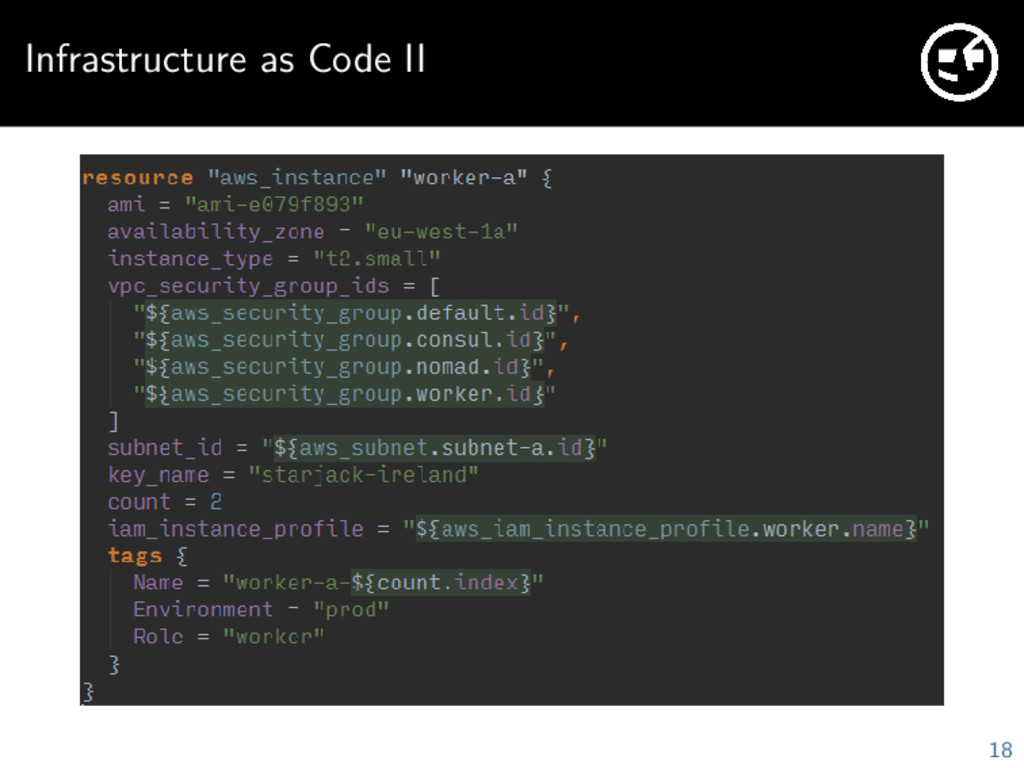
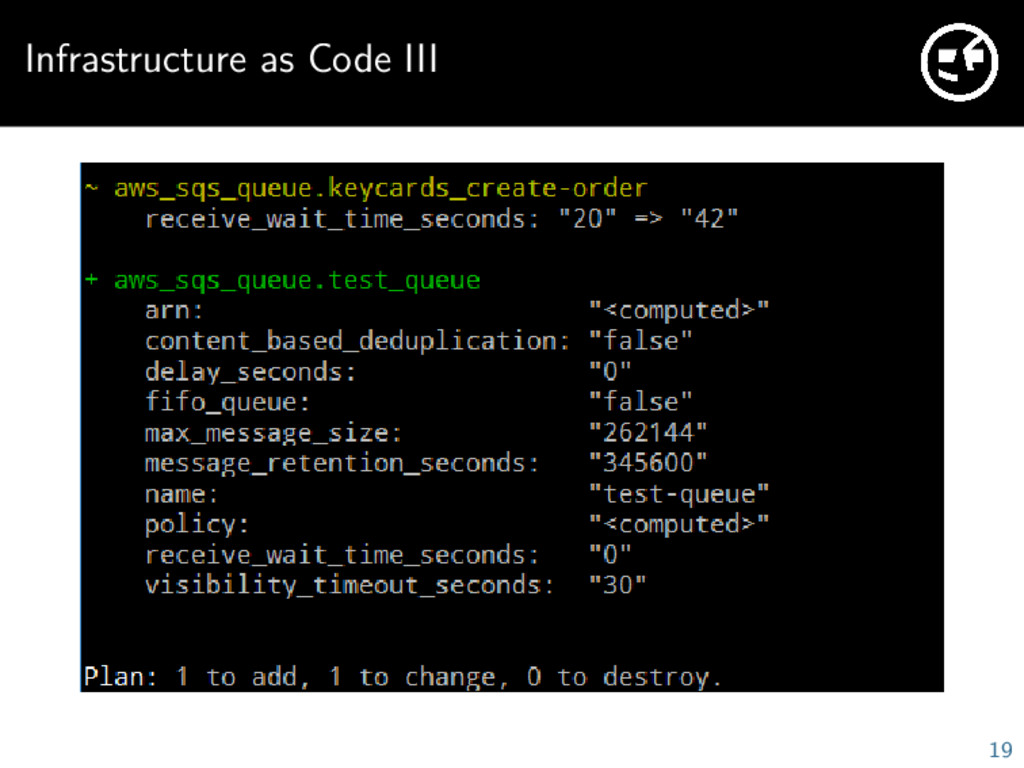
whole infrastructure as simple HCL files Supports AWS, Google Cloud, Mailgun and dozens of other services When you run Terraform it will compare your current state with the desired state and apply the needed changes Creates dependency graph between your resources and modifies them in the right order No more clicking around in AWS web console Every change is documented and versioned, manual changes will be reverted on next run 17
basic infrastructure VPC, Firewall rules EC2 instances, ELB, S3, CloudFront, Route 53, SQS RDS Cluster, Redis Cluster Mailgun Very easy to use and works really well 20
and we need to install some software on them Terraform is not a provisioner – we need another tool to automate that We chose Ansible to provision our servers Works over SSH and doesn’t have requirements for the clients besides python We tag our instances by role with Terraform. Automatic inventory file by using ec2.py Configures EC2 instances, creates databases and users, defines DigitalOcean Jenkins Slave, . . . 21
platform. A scheduler is needed to make decisions on where in your cluster your services should run. We chose Nomad In comparison to other schedulers easy to get started Just one binary to install Relatively new and not as mature as other solutions Requires three servers, should be deployed to different availability zones 22
need to find them That’s the job of a service discovery service We chose Consul because it plays well together with Nomad Whenever a new service is deployed with Nomad it will register its endpoints in Consul A tool called consul-template updates the nginx configuration file as soon as changes happen and reloads nginx 23
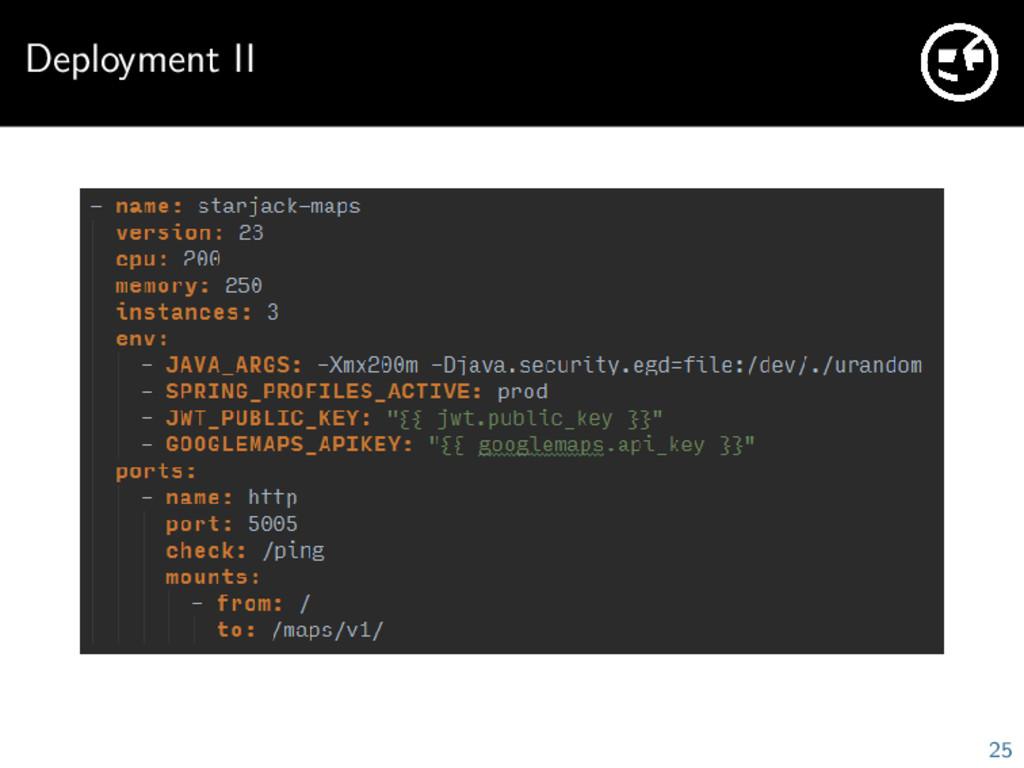
what to schedule where Nginx needs to be configured so it knows which endpoints should be routed to which services We deploy our services using our small custom YAML DSL which is processed by Ansible 24
Trigger deployment with Ansible 3 Creates Nomad job specification files and triggers scheduling 4 Nomad does a rolling update of the services 5 Nomad worker nodes pull new Docker images and start them 6 As new versions are rolled out Consul and Nginx get updated 26
on spring-boot & Hibernate Each service has its own git repository One common library which services can use Be careful not to introduce unwanted dependencies between services! Treat as API and don’t break it Only used for cross cutting concerns Communication between microservices by using REST for synchronous and a queue for asynchronous communication Not covered in detail, your implementation will be different anyways :) 29
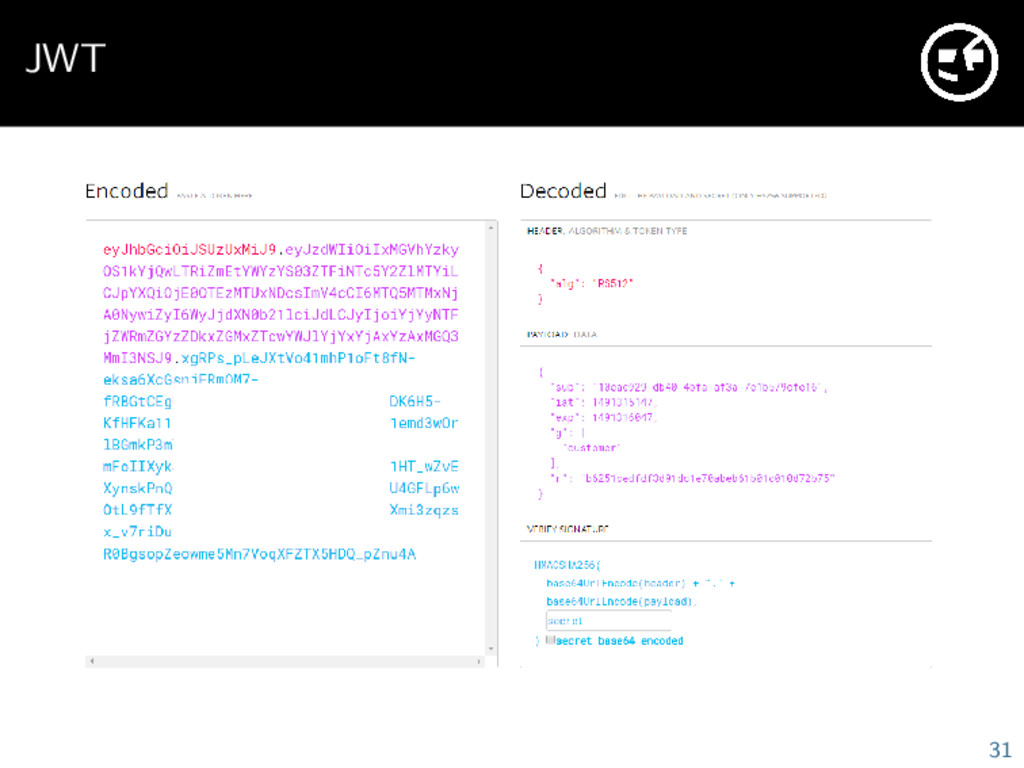
query the authentication service for every request Would create a lot of load and a potential bottleneck Instead we use JSON Web Tokens (JWT) Authentication service creates cryptographically signed token for the user using its private key Services have a public key and can check whether the token is legitimate Since there’s no invalidation of a token we use a low TTL and a refresh mechanism 30
simply done via REST HTTP requests Passes Authentication header if it’s required to identify the user For asynchronous communication we use a queue Decouples services Messages don’t get lost if other service is down Automatic retries Increases reliability of your system Coordination between multiple instances of the same type is done with Redis 32
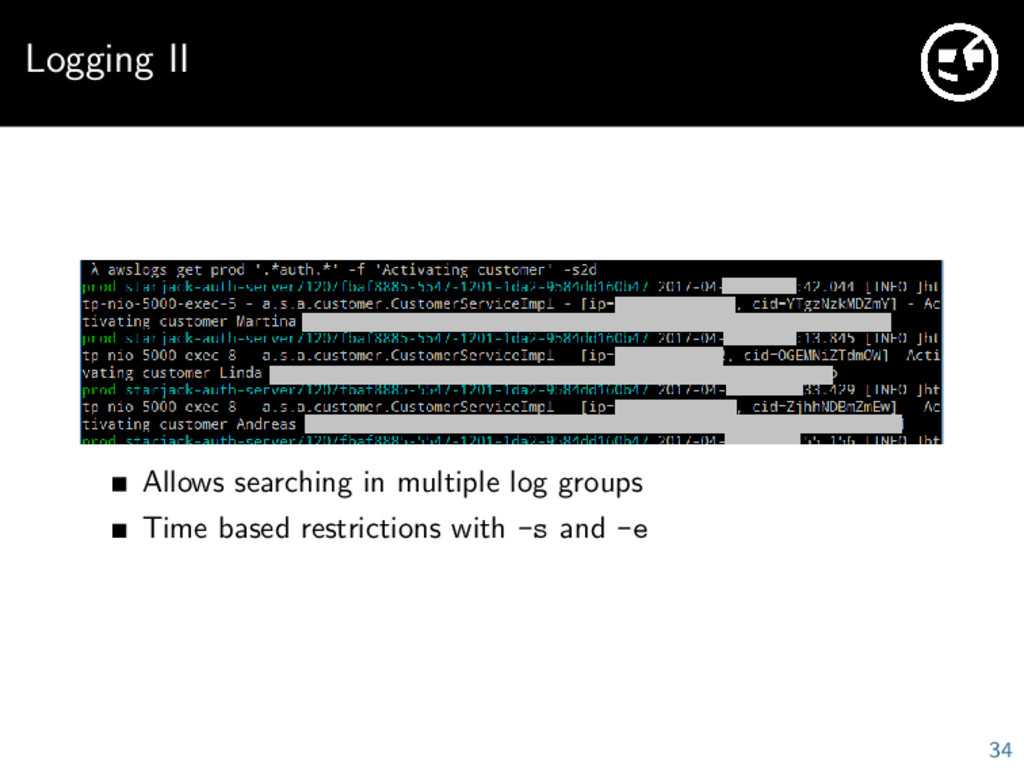
need a good centralized logging solution AWS offers CloudWatch Logs Docker can natively log to CloudWatch Every log message should only be one event (one line) We use awslogs as a “remote grep” tool for CloudWatch 33
You need a quick overview and notifications for errors We have an AWS Lambda function which subscribes to our application logs Filters logs for events we are interested in Errors and warnings Whitelisted info events Uses slack API to push log messages to Slack Different channels based on severity and type Adds Slack notifications for errors 35
a system is down We expose simple status endpoints from our services and let StatusCake monitor those If a service is unreachable StatusCake uses Pushover to send us a push notification 37
to debug the problem It helps to log as much as you can Application logs Web server access/error logs Queue messages Linux system logs Frontend logs For application logs think about how you will search for messages later, i.e. include relevant data For system logs use blacklists for messages you are not interested in, get notified for everything you don’t expect 39
you’d think, see “Fallacies of Distributed Computing” Even when something has a failure likelihood of << 1% if that runs thousands of times it will eventually go wrong Expect that things will go wrong and make your system as robust as possible 40
the limit is reached you won’t get a new connection Think about how many connections you will have, it might be more than you think connections = services × instances × poolsize 41
beforehand Services will probably consume more resources than you assume as they also need to have their runtime environment in memory No memory sharing/deduplication if you use Docker Be careful if you do hard memory limit enforcement 42
once Makes development and evolution of your system easier Dramatically reduces complexity of individual services You get rewarded with a distributed highly reliable system 44
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![End Thanks for your attention Questions? Contact me at [email protected]](https://files.speakerdeck.com/presentations/ad45db6870e84140aacc47937c836387/slide_45.jpg){kind=link}
{kind=link}