Comment.” Journal of the American Statistical Association, ( ), – . Pearl, J., Glymour, M., & Jewell, N. P. ( ). “Causal inference in statistics: A primer.” Wiley. Pearl, J., & Verma, T. ( ). Equivalence and synthesis of causal models. In B. D’Ambrosio & P. Smets (Eds.), UAI ’ : Proceedings of the seventh annual conference on uncertainty in arti cial intelligence. Morgan Kaufmann. Rubin, D. ( ). “Which ifs have causal answers (Comment on ‘Statistics and causal inference’ by Paul W. Holland).” Journal of the American Statistical Association, , – . Sesame Street - Elmo’s Sing-Along Guessing Game and Elmocize. ( , October ). Shalizi, C. R. ( ). Advanced Data Analysis from an Elementary Point of View. Sober, E. ( ). “A theory of contrastive causal explanation and its implications concerning the explanatoriness of deterministic and probabilistic hypotheses.” European Journal for Philosophy of Science, ( ), . Strotz, R. H., & Wold, H. O. A. ( ). “Recursive vs. nonrecursive systems: An attempt at synthesis (Part I of a triptych on causal chain systems).” Econometrica, ( ), . Sutton, W., & Linn, E. ( ). “Where the money was.” Broadway Books.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
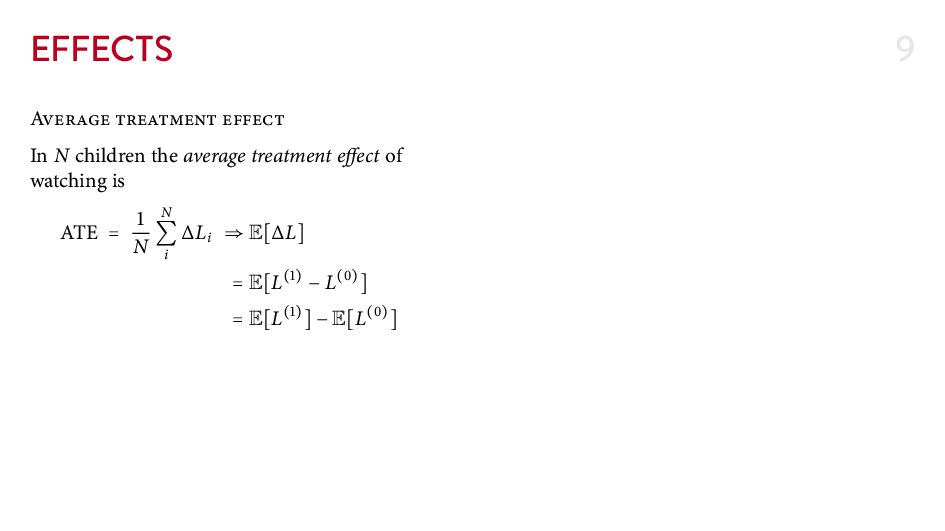{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
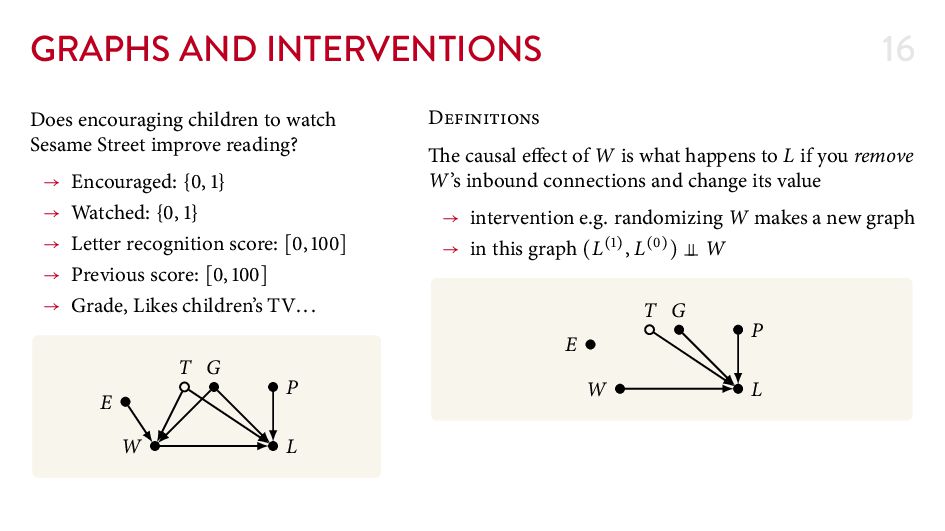{kind=link}
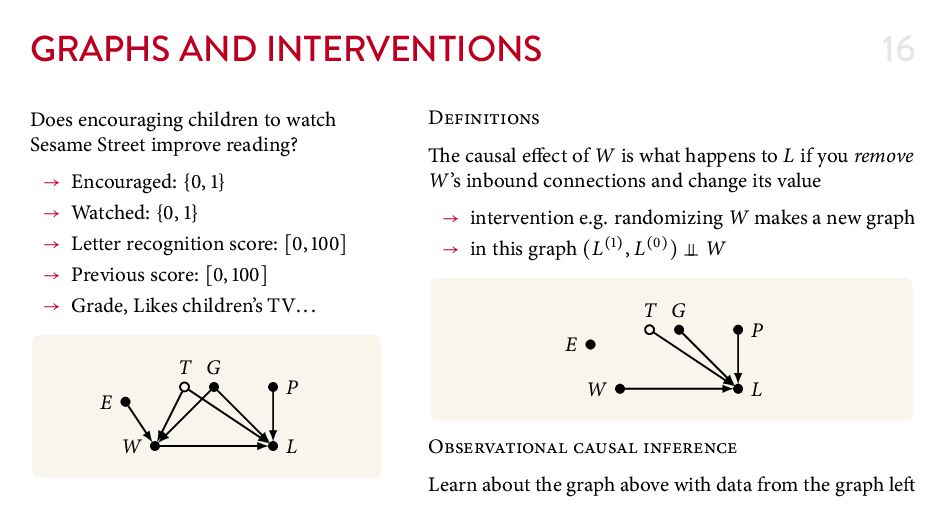{kind=link}
{kind=link}
{kind=link}
{kind=link}
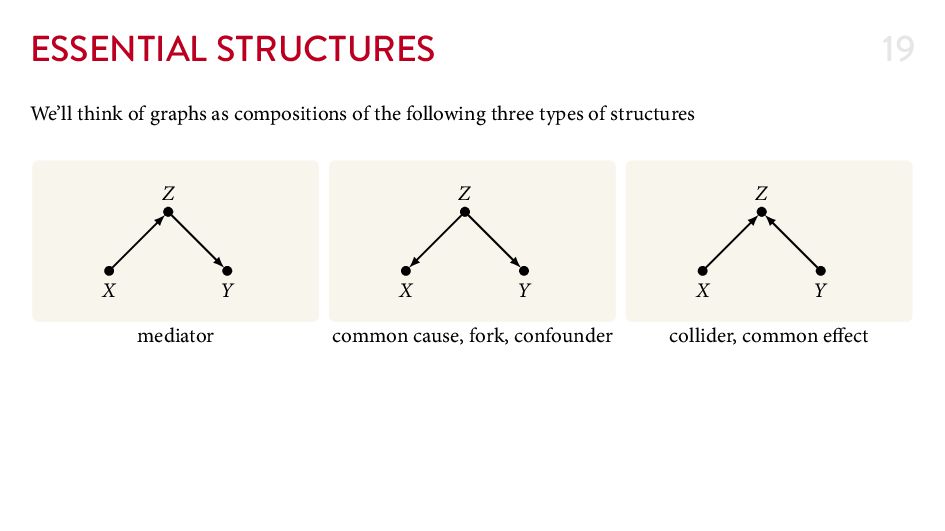{kind=link}
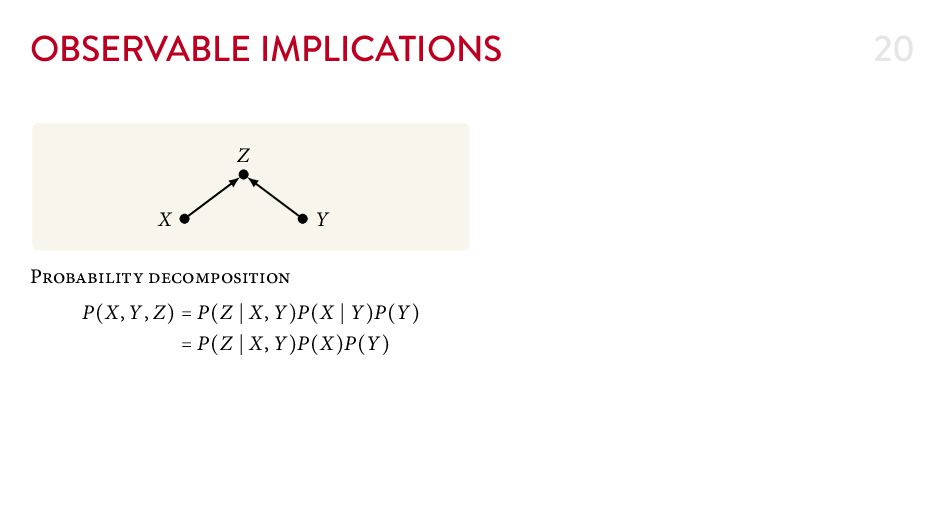{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
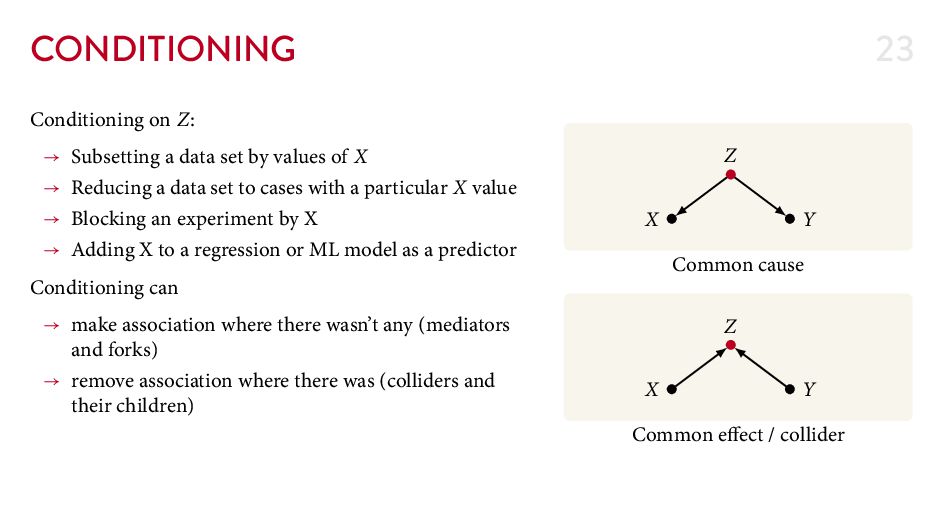{kind=link}
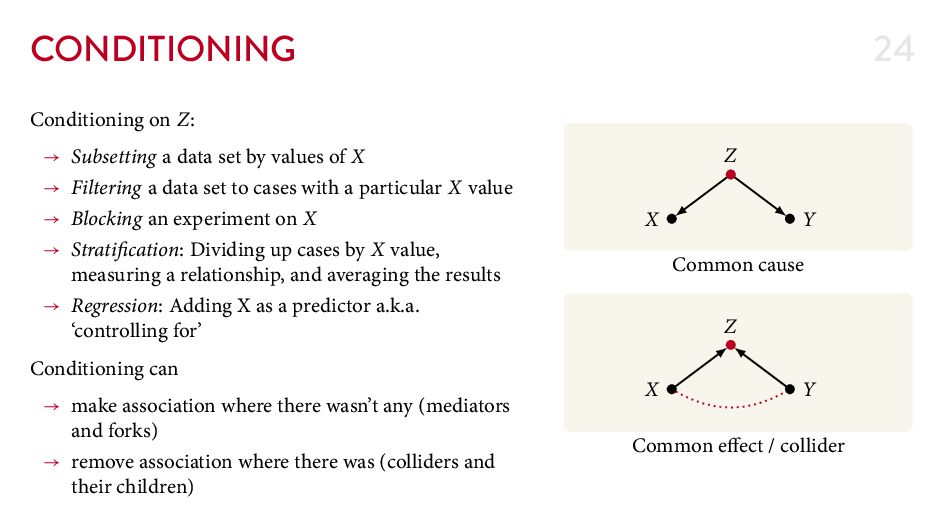{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}