• Use SQL-like language called HiveQL • Access data in HDFS • Query execution via MapReduce • Best use for batch jobs or ETLs • Functionality can be extended via User Defined Functions (UDF) • Can be accessed via command line or Hue
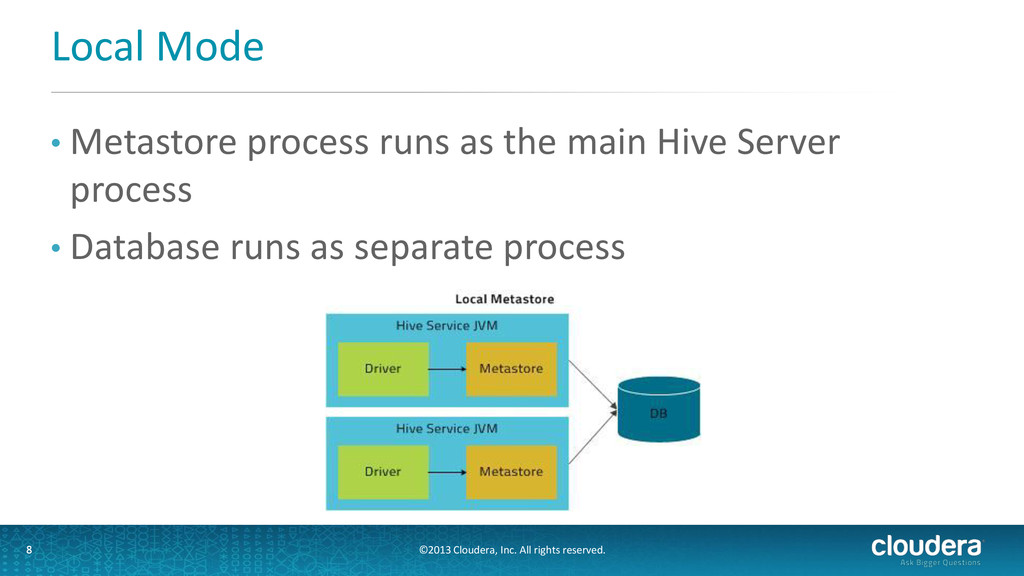
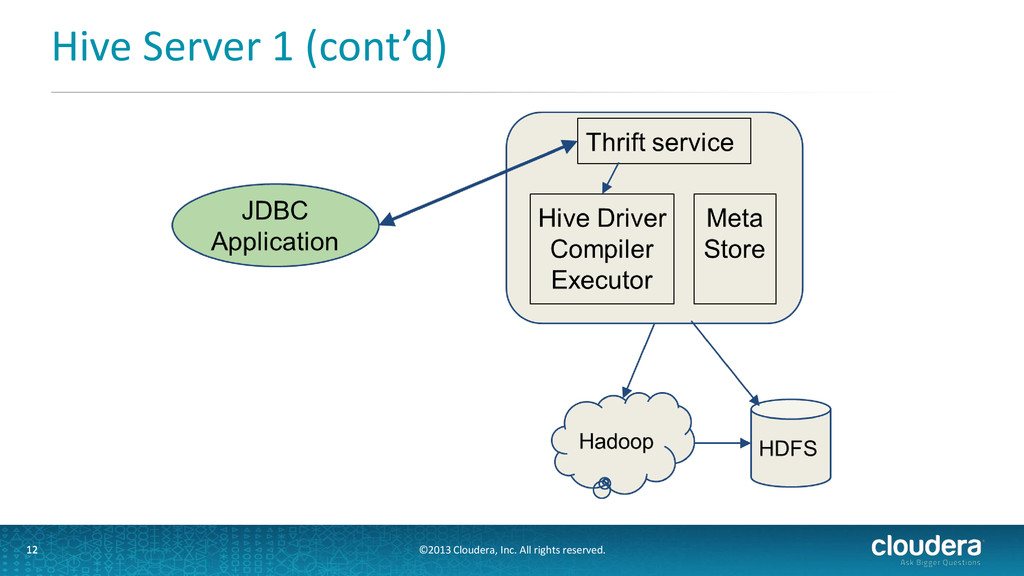
know about the tables? Hive Metastore 5 • Needs to have a backing database • Stores the metadata for Hive tables and partitions in a relational database (mysql, postgres, etc) • Provides clients (including Hive) access via the metastore service API
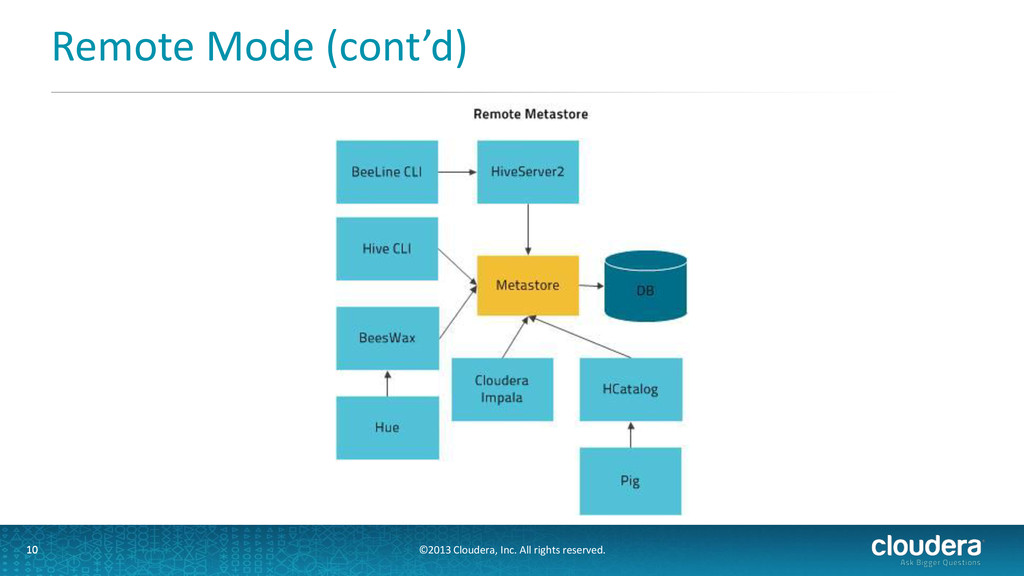
• Metastore runs in its own JVM process • HiveServer2, HCatalog, Cloudera Impala™, and other processes communicate with it via the Thrift • Does not require client to know metastore db credentials • Supports security (kerberos, user impersonation) • Recommended
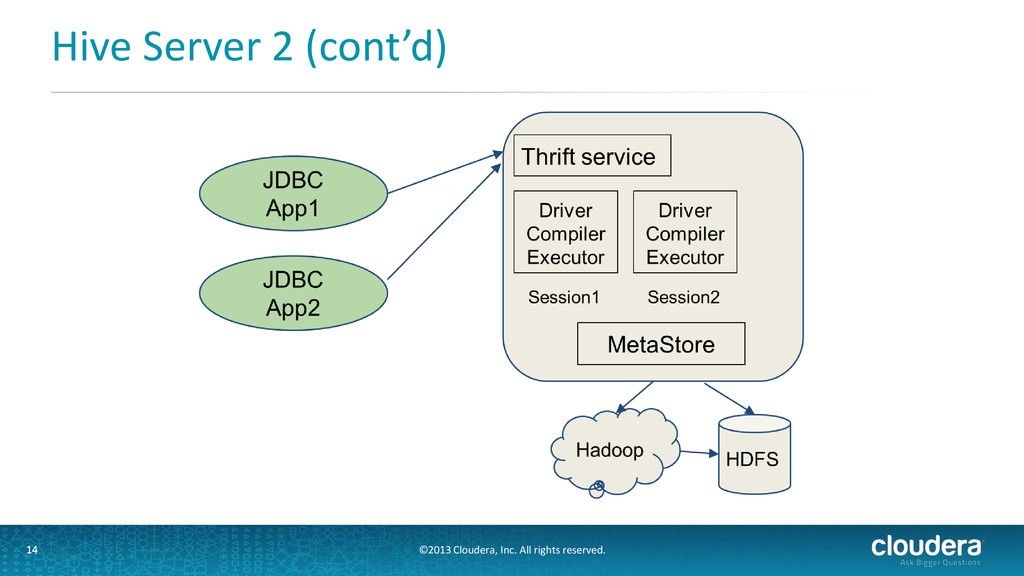
13 • Available since Hive 0.10 • Better JDBC/ODBC support • Multiple client concurrency • Security (kerberos support) • Uses Metastore like Hive Server 1 • Allows new types of Hive clients (e.g. beeline)
SQL directly on data in HDFS / HBase • Open source under Apache license • Leverages Hive metadata • Same SQL as HiveQL (Create, Alter, Insert, Select, Join, Subqueries) • JDBC/ODBC drivers, Hue interface • Support for variety of data formats • Hadoop native (Apache Avro, SequenceFile, RCFile with Snappy, GZIP, BZIP, or uncompressed); text (uncompressed or LZO- compressed); and Parquet (Snappy or uncompressed)
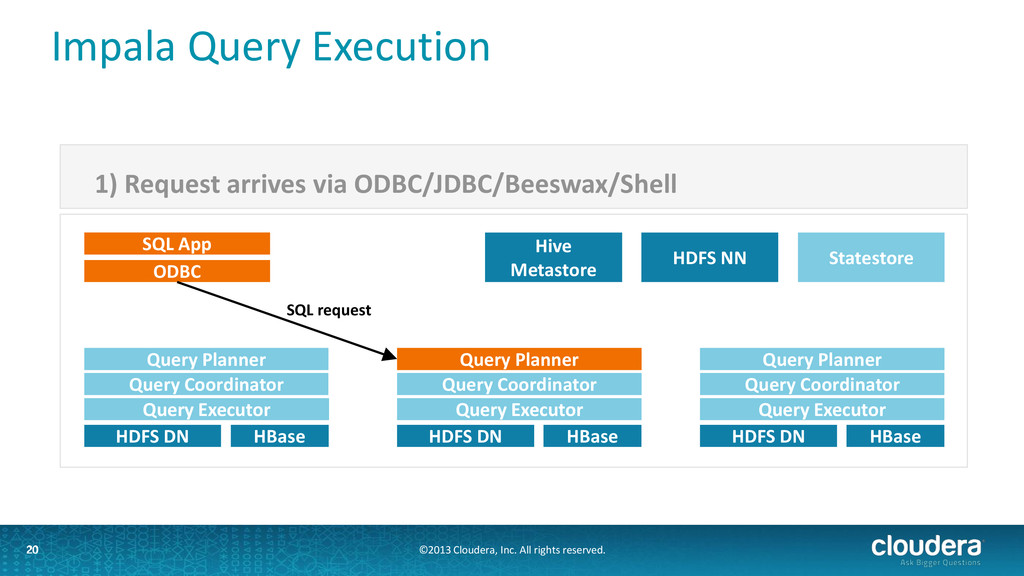
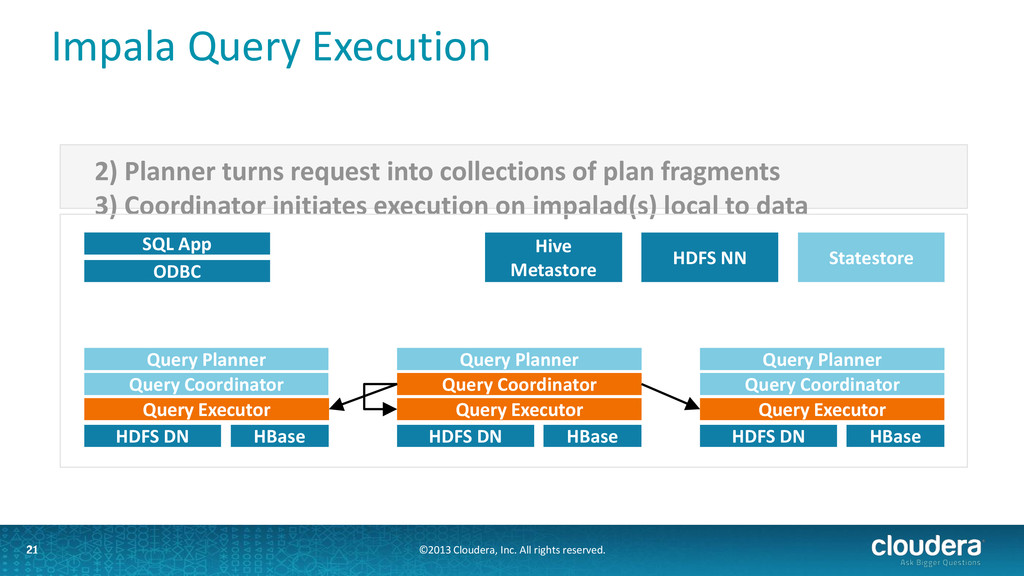
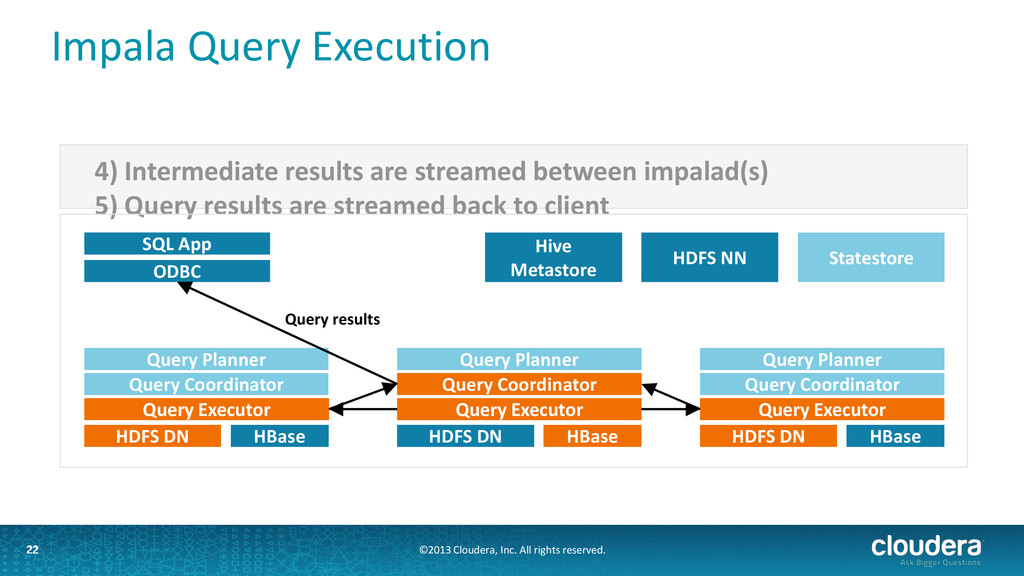
Impala • Runs as a distributed service in cluster: one Impala daemon on each node with data • User submits query via ODBC/Beeswax Thrift API to any of the daemons • Query is distributed to all nodes with relevant data • If any node fails, the query fails • Impala uses Hive's metadata interface, connects to Hive's metastore 18
Two binaries: impalad and statestored • Impala daemon (impalad) • handles client requests and all internal requests related to query execution • Exports Thrift services for these two roles • State store daemon (statestored) • provides name service and metadata distribution • also exports a Thrift service 19
• Patterned after Hive's version of SQL • Limited to Select, Project, Join, Union, Subqueries, Aggregation and Insert • Only equi-joins; no non-equi joins, no cross products • Order By only with Limit 23
• HBase has its own storage format (HFile) • Need to map HBase table to Hive table • Create table in HBase shell: • create 'hbasealltypessmall', 'bools', 'ints', 'floats', 'strings' • enable 'hbasealltypessmall' 24
• No support for maps, arrays, structs • No custom UDFs, custom file formats, custom SerDes • No UDAFs and UDTFs • No multiple DISTINCT clauses • No MapReduce features in Hive (SORT BY, CLUSTER BY) • Not all HiveQL statements are supported (e.g. SHOW CREATE TABLE) • Tables of certain file formats (avro, RCFile, sequence file) need to be loaded in Hive 27
• Open source, columnar file format developed by Cloudera and Twitter • Supports storing each column in a separate file • Supports fully shredded nested data • Native type support • Type-specific value encodings (saves space) • Supports index for fast lookups • Allows nesting of data • Supports for multiple programming languages 32
(cont’d) • Row Groups: A group of rows in columnar format ‣ Max size buffered in memory while writing ‣ One (or more) per split while reading ‣ About 50MB < row group < 1GB • Columns Chunk: Data for one column in row group ‣ Column chunks can be read independently for efficient scans • Page: Unit of access in a column chunk ‣ Should be big enough for efficient compression ‣ Min size to read while accessing a single record ‣ About 8KB < page < 1MB
Borrowed from Google Dremel’s ColumnIO file format • Schema is defined in a familiar format • Supports nested data structures • Each cell is encoded as triplet: repetition level, definition level, and the value • Level values are bound by the depth of the schema • Stored in a compact form 36
• Field types are either group or primitive type with repetition of required, optional or repeated • exactly one, zero or one, or zero or more • Various encoding schemes: • Bit packing: good for small integers • Run length encoding: allows compression • Dictionary encoding • Extensible 37
Hive • Impala uses Snappy compression by default with Parquet tables • Starting in Impala 1.1.1 you can use Parquet data in Hive • ALTER TABLE table_name SET FILEFORMAT PARQUETFILE; 39
On (cont’d) • Bring up impala shell (impala-shell command) • Execute ‘invalidate metadata’ statement (or refresh if impala version < 1.1) • Execute ‘show tables;’ statement and you should see the tables • Execute more queries near the bottom on the blog page http://blog.cloudera.com/blog/2013/06/quickstart-vm- now-with-real-time-big-data/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}