main attributes – Volume: • The amount of data we work with daily is growing and is only getting larger – Variety • Data comes in all shapes, sizes, layouts, formats – often changing mid-stream – Velocity • Being collected at an astounding pace, need answers from it just as quickly
ad-hoc queries, full indexes • No multi-row transactions, no joins • Heterogeneous APIs • Dynamic schemas for iterative development • Elastic approaches to deployment
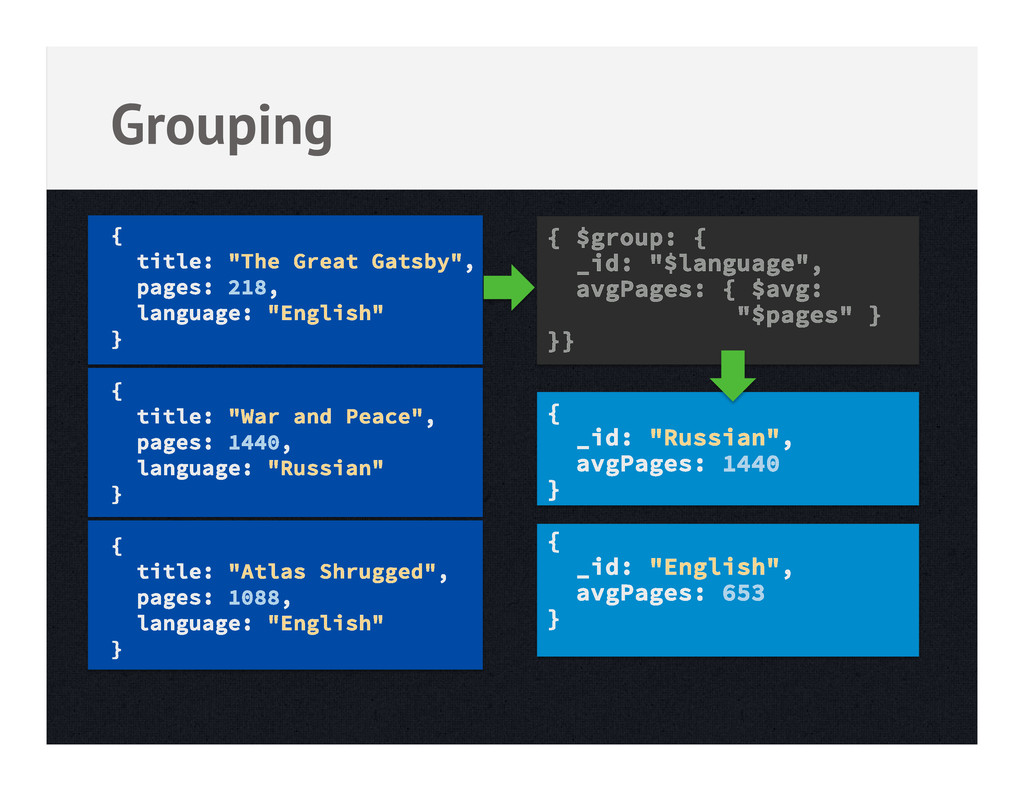
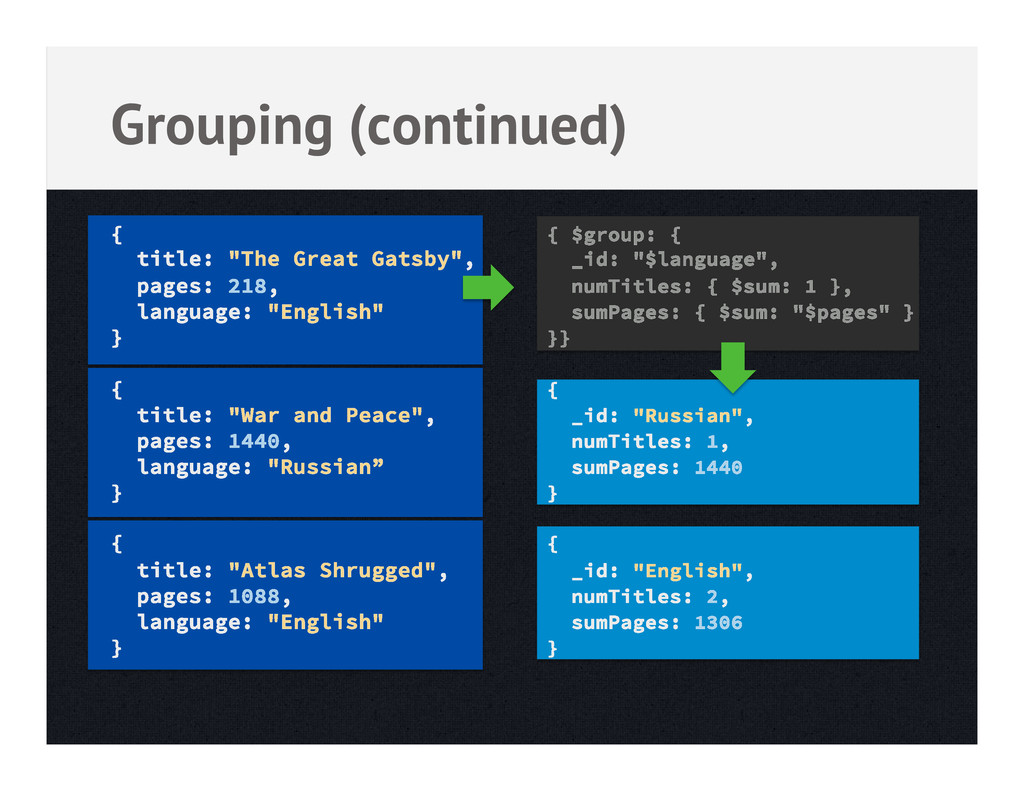
data but might not scale • Aggregation framework – Declarative, pipeline-based approach, ad-hoc • Native Map-Reduce in MongoDB – JS functions that run over your data • Other systems – Hadoop, R, ETL, Reporting
is a collection, output is a document • Pipeline is a series of operations – Filter, transform data – Output of one stage is input to the next – $ ps ax | grep mongod | head -n 1
11,000 business – 8,000 checkins – 43,000 users – 229,000 reviews • Tweaked data model a bit from original form • Script to process downloaded data – https://gist.github.com/crcsmnky/5675588
is best – Map-Reduce is slower and more work • Aggregation Framework output limited to 16MB document – Map-Reduce can output to a collection • Vote on SERVER-3253 to bring $out to aggregation
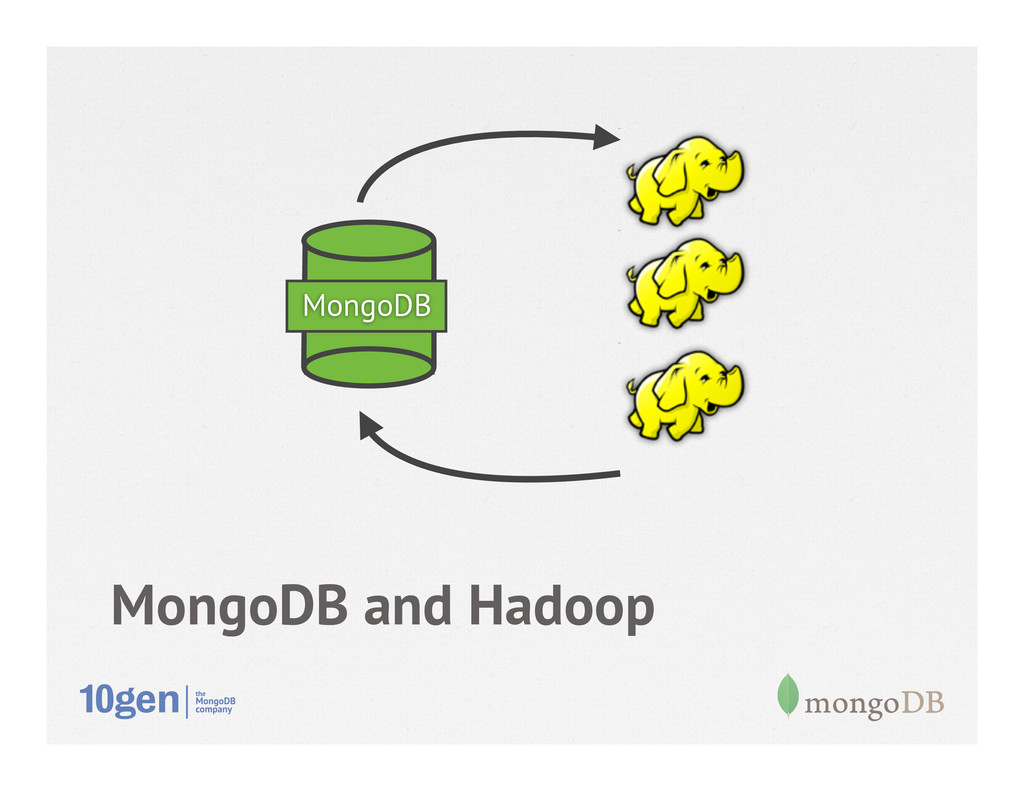
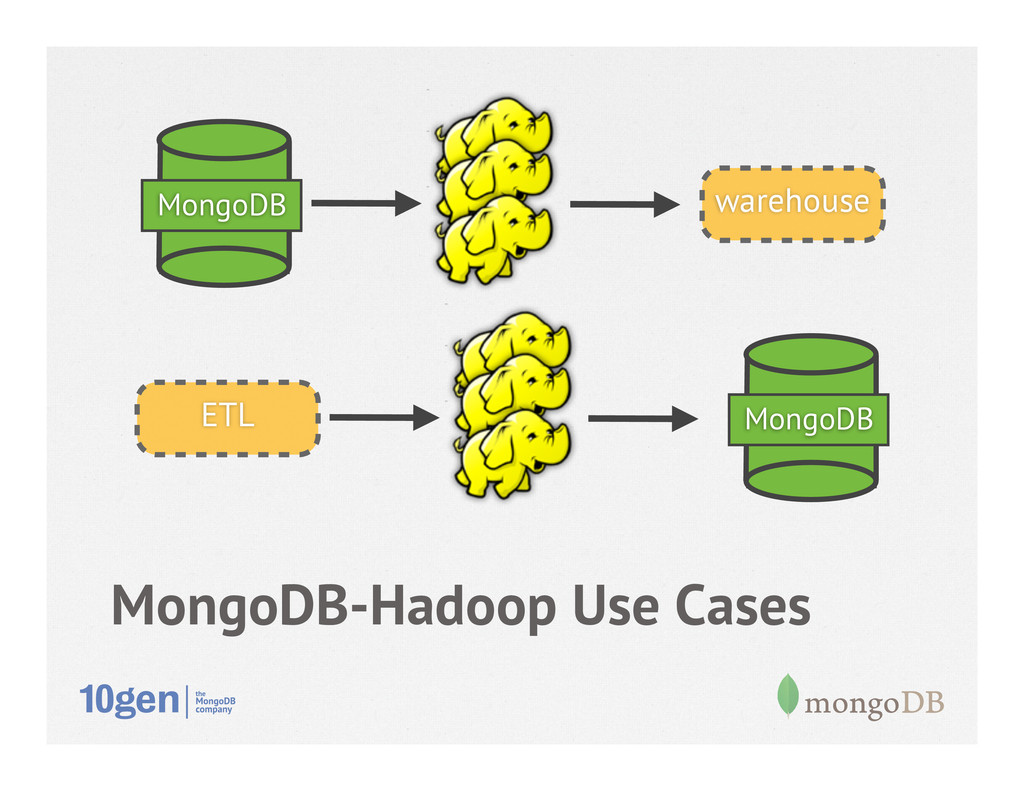
• Supports MapReduce, Pig, Streaming • Batch, offline processing • 1.0 released, 1.1 active development • Leverage Hadoop ecosystem against operational data in MongoDB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}