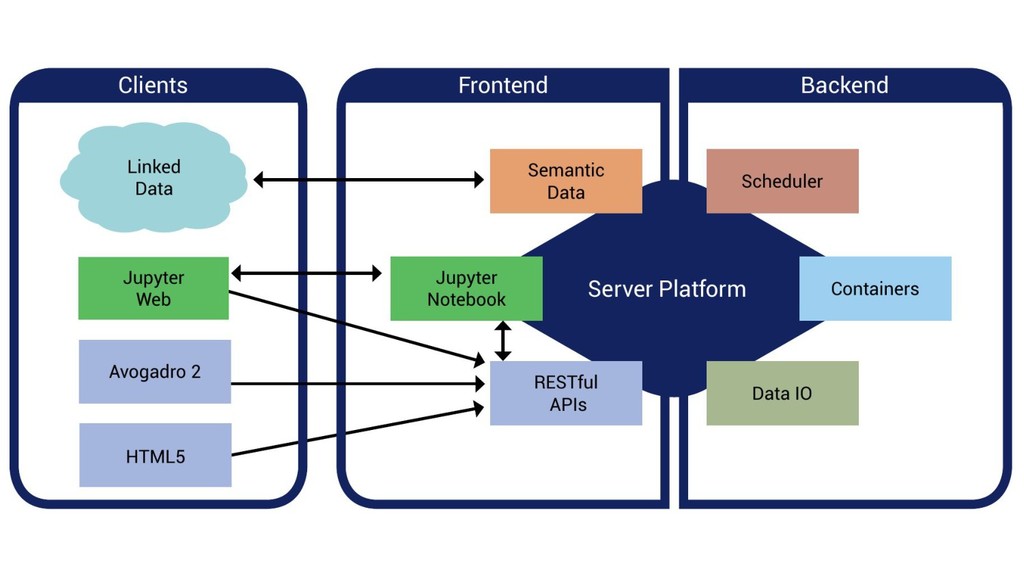
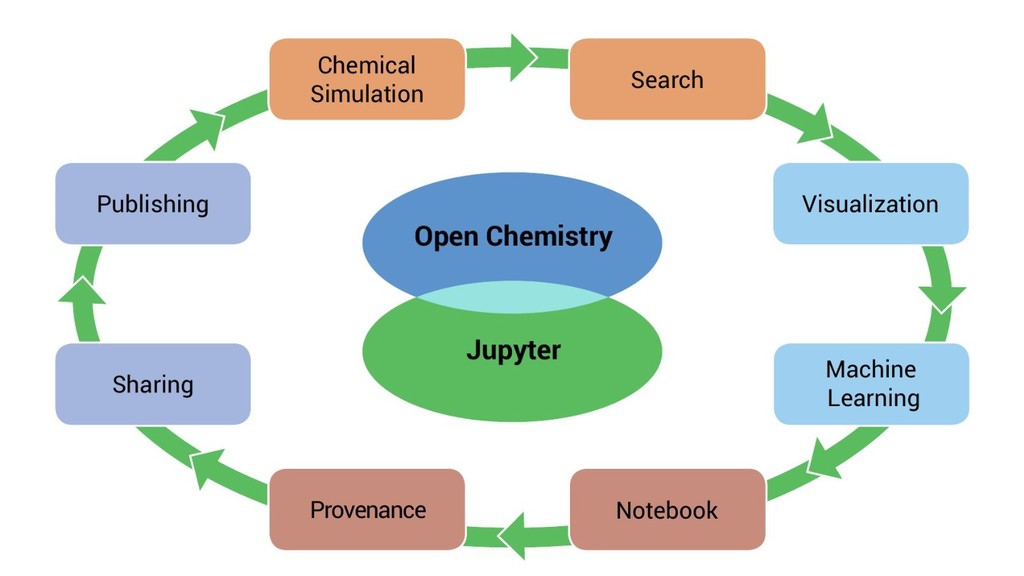
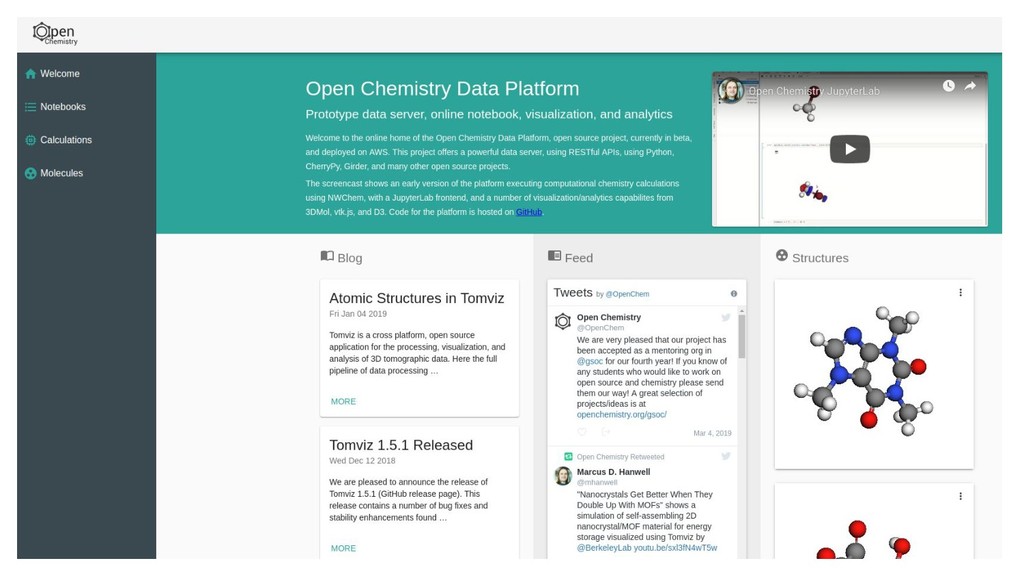
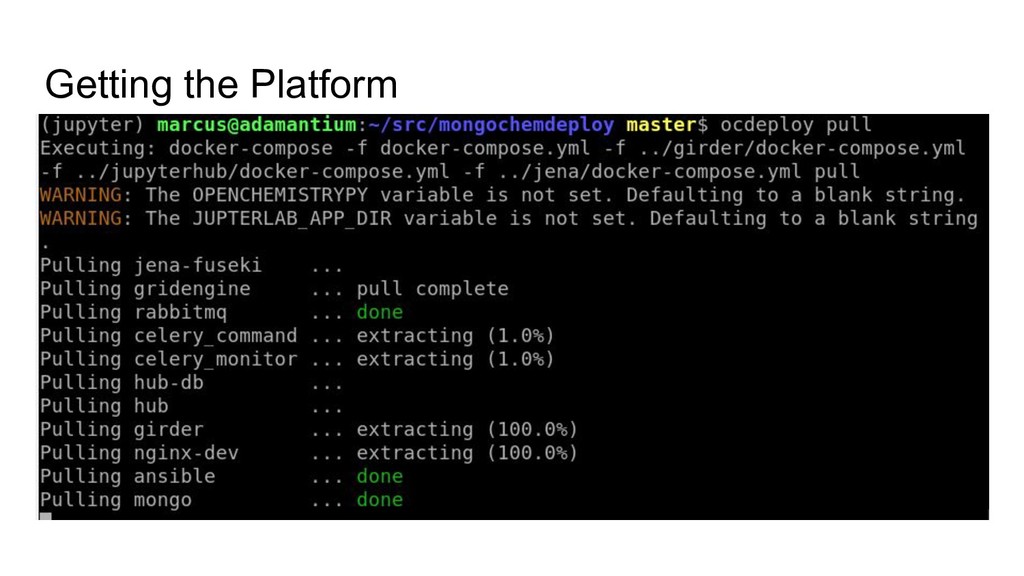
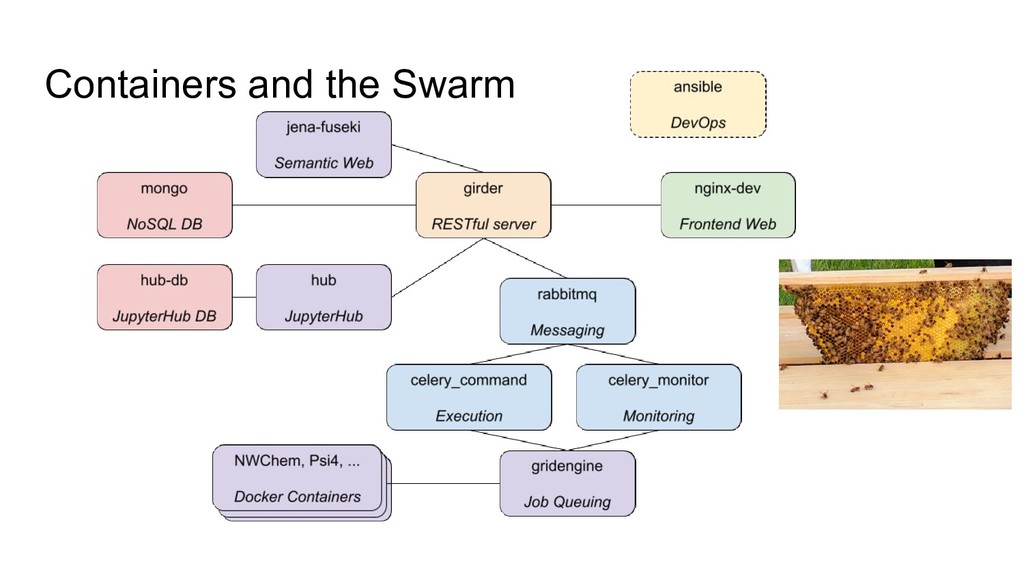
The Open Chemistry project is developing an ambitious platform to facilitate reproducible quantum chemistry workflows by integrating the best of breed open source projects currently available in a cohesive platform with extensions specific to the needs of quantum chemistry. The core of the project is a Python-based data server capable of storing metadata, executing quantum chemistry calculations, and processing the output. The platform exposes RESTful endpoints using programming language agnostic web endpoints, and uses Linux container technology to package quantum codes that are often difficult to build.
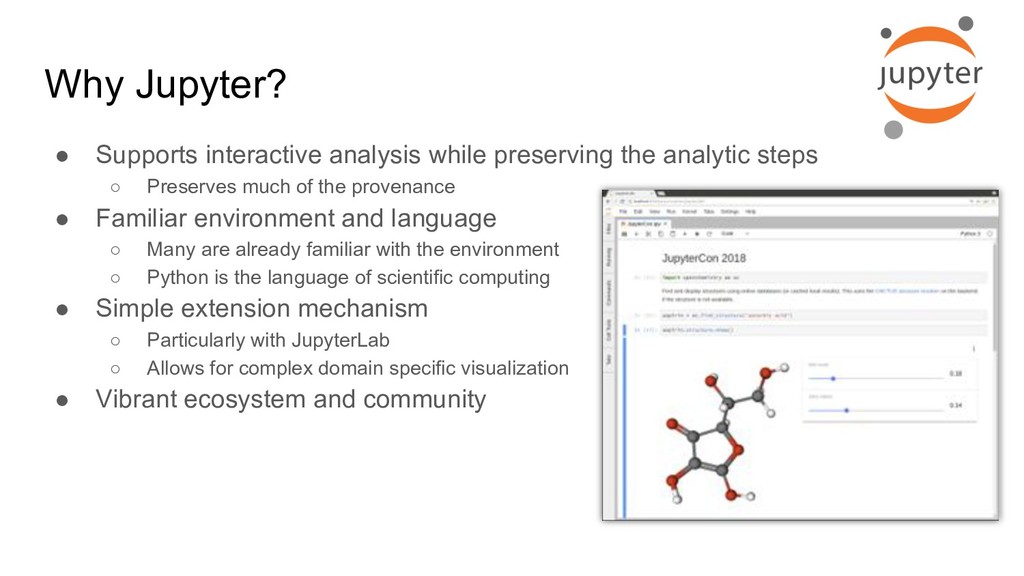
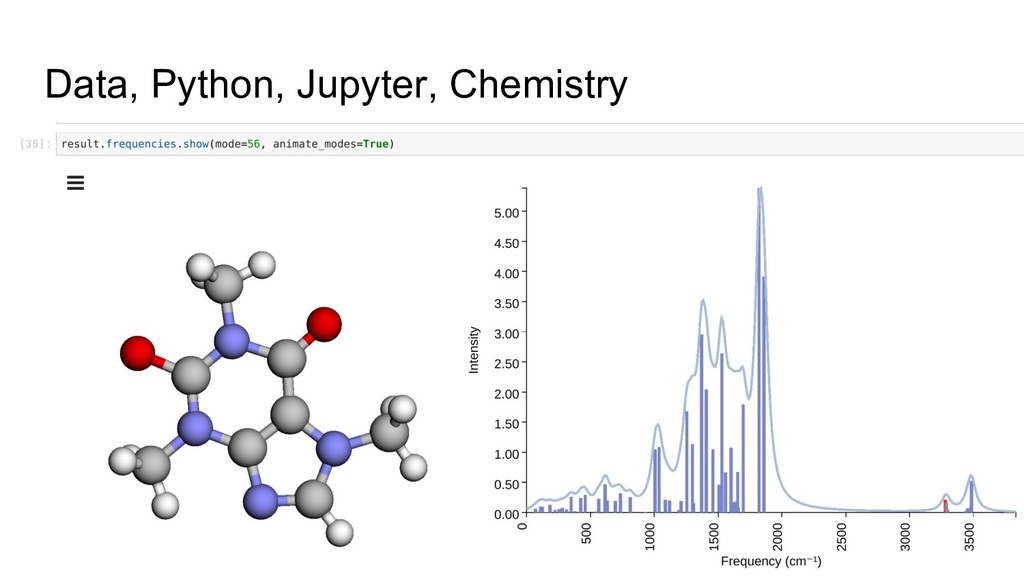
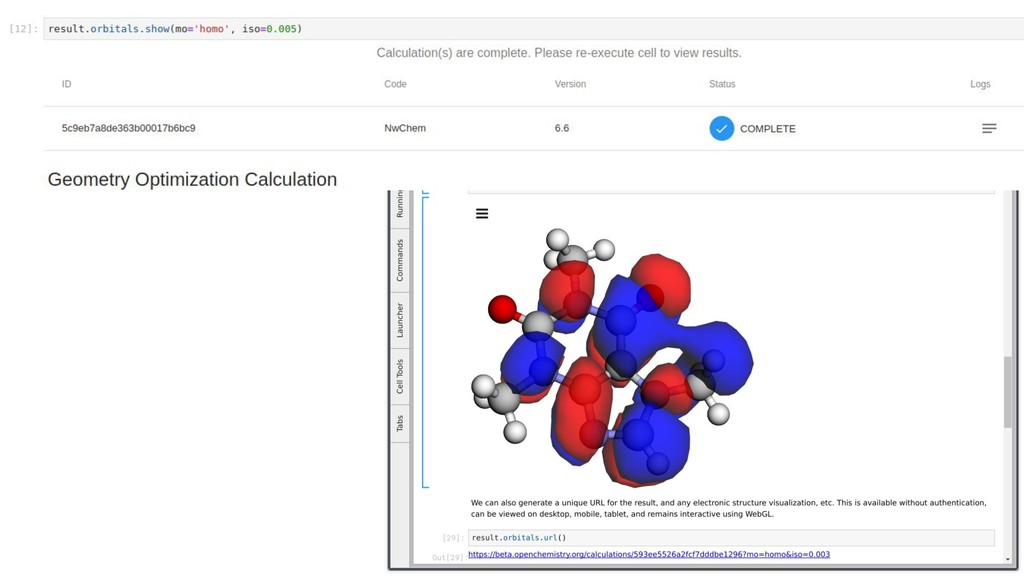
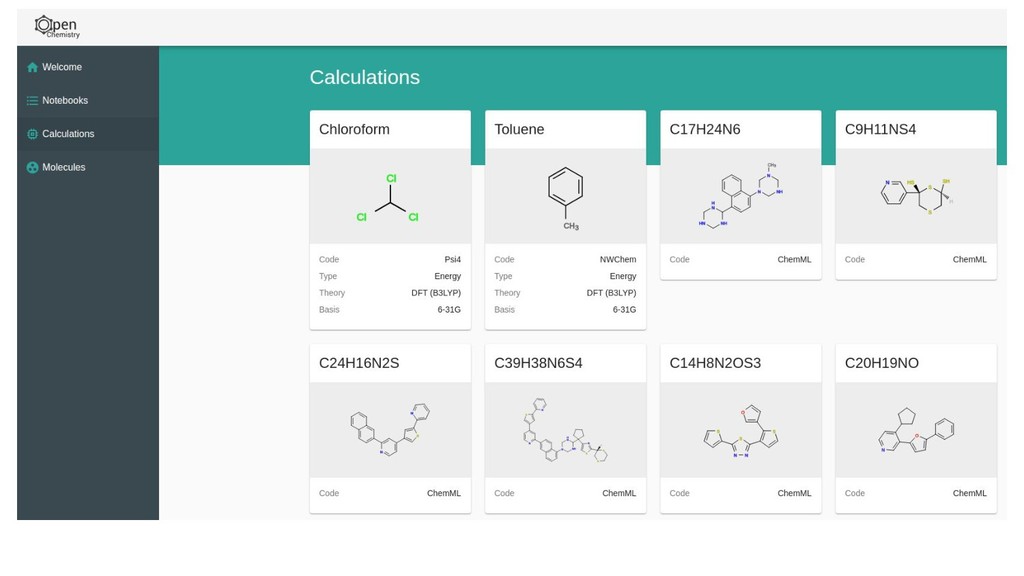
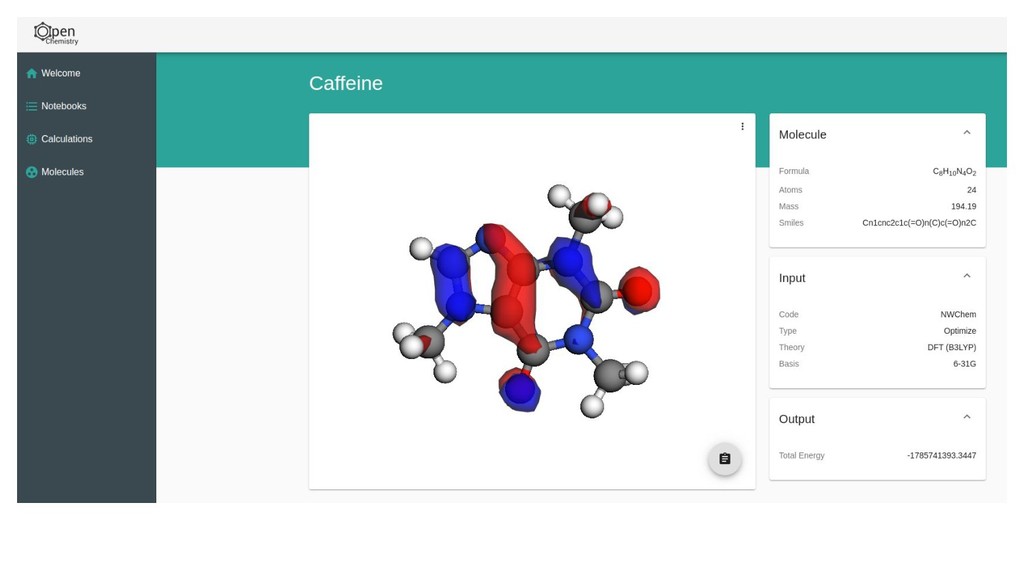
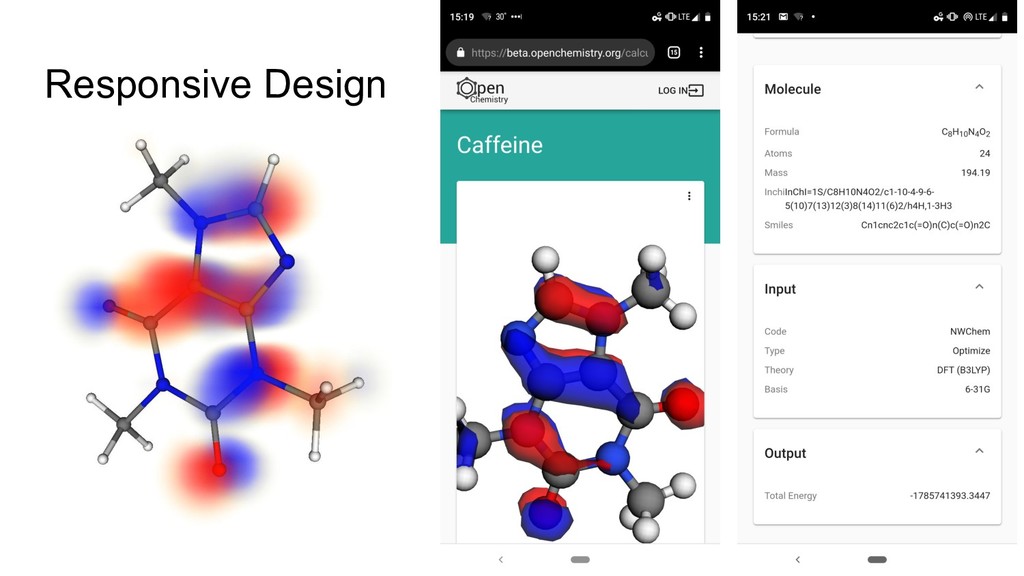
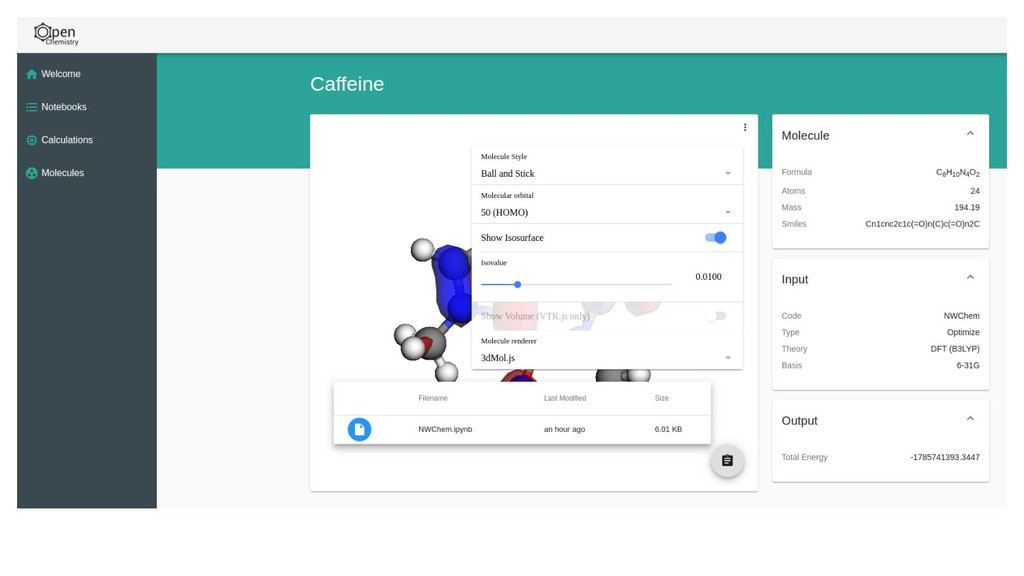
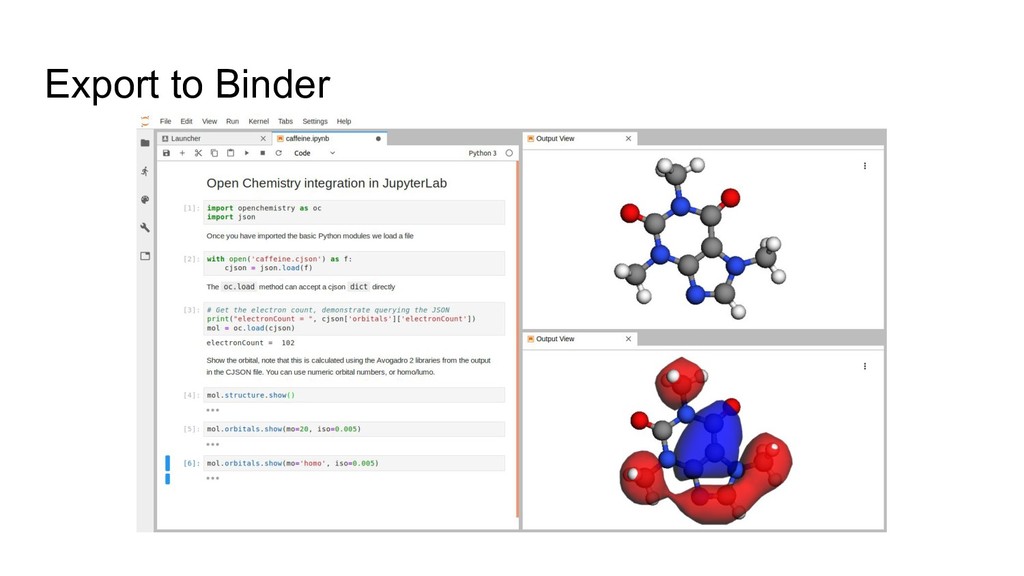
The Jupyter project has been leveraged as a web-based frontend offering reproducibility as a core principle. This has been coupled with the data server to initiate quantum chemistry calculations, cache results, make them searchable, and even visualize the results within a modern browser environment. The Avogadro libraries have been reused for visualization workflows, coupled with Open Babel for file translation, and examples of the use of NWChem and Psi4 will be demonstrated.
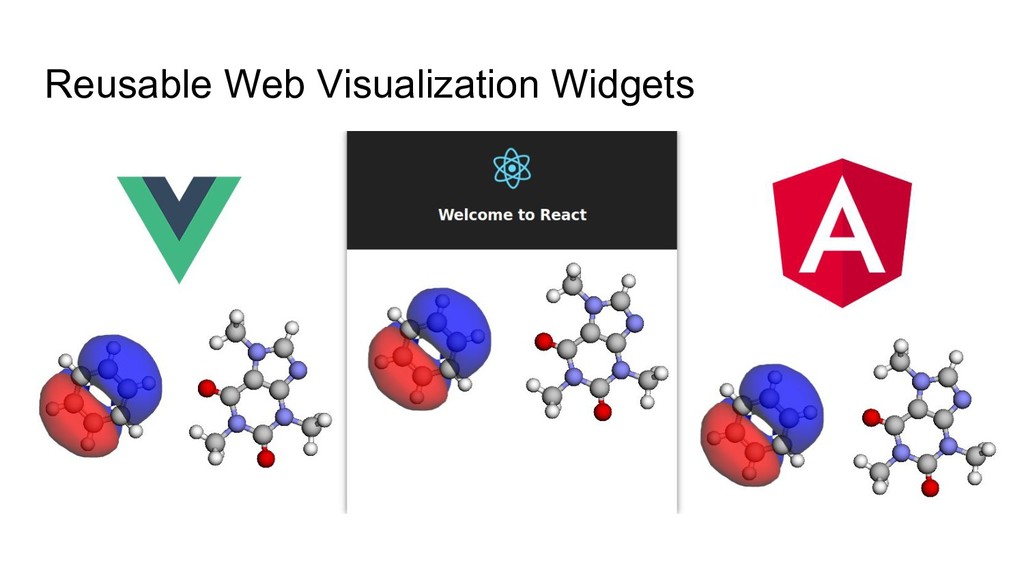
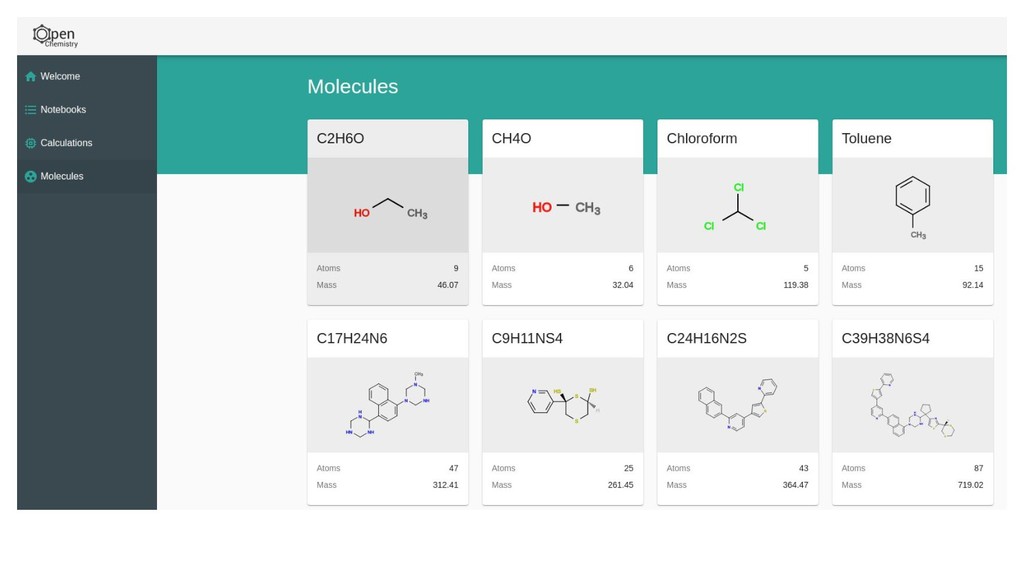
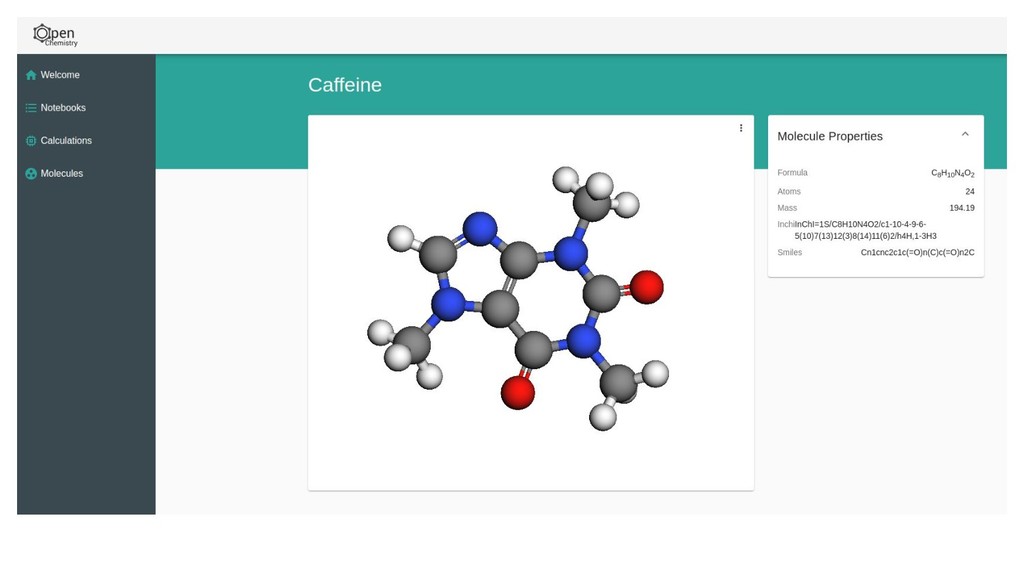
The core of the platform is developed upon JSON data standards, and encouraging the wider adoption of JSON/HDF5 as the principle storage mediums. A single page web application using React at its core will be shown for sharing simple views of data output, and linking to the Jupyter notebooks that documents how they were made. Command line tools and links to the Avogadro graphical interface will be shown demonstrating capabilities from web through to desktop.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}