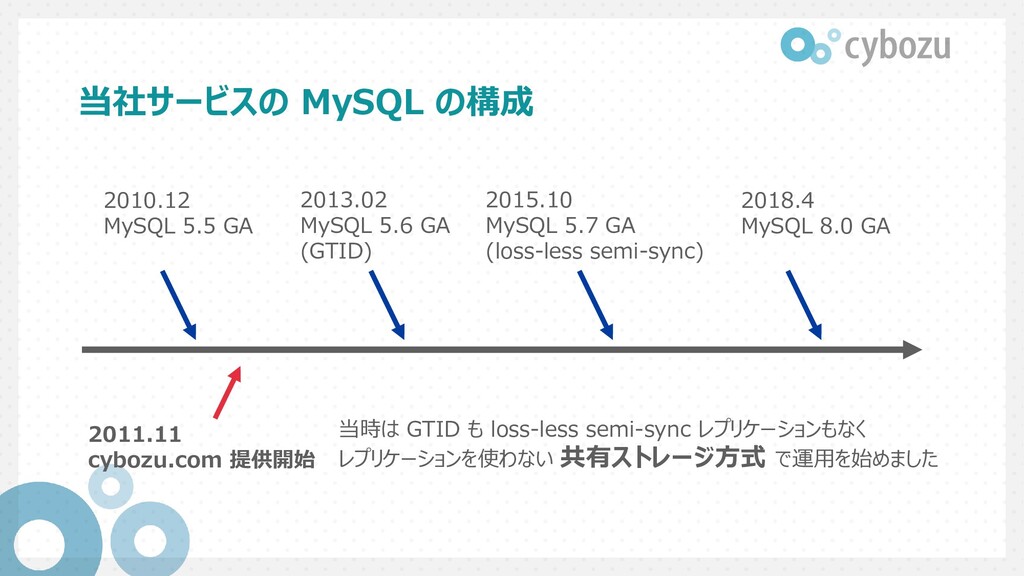
2013.02 MySQL 5.6 GA (GTID) 2015.10 MySQL 5.7 GA (loss-less semi-sync) 2018.4 MySQL 8.0 GA 当時は GTID も loss-less semi-sync レプリケーションもなく レプリケーションを使わない 共有ストレージ方式 で運用を始めました
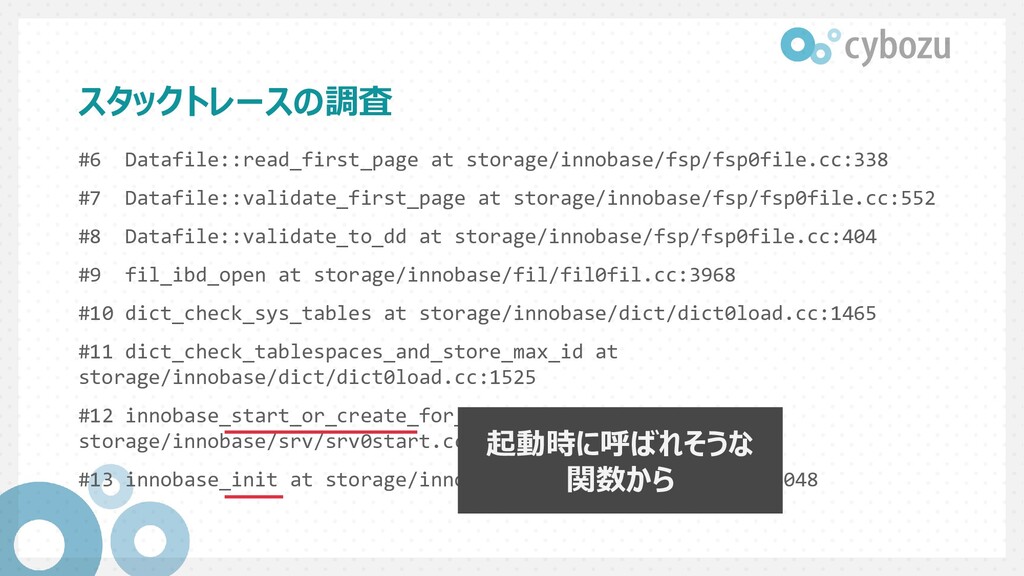
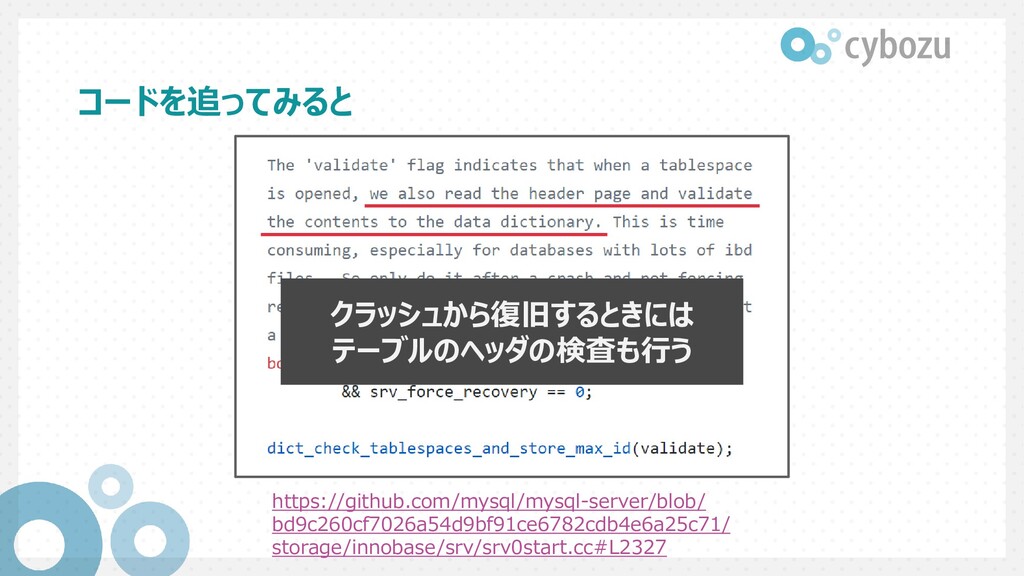
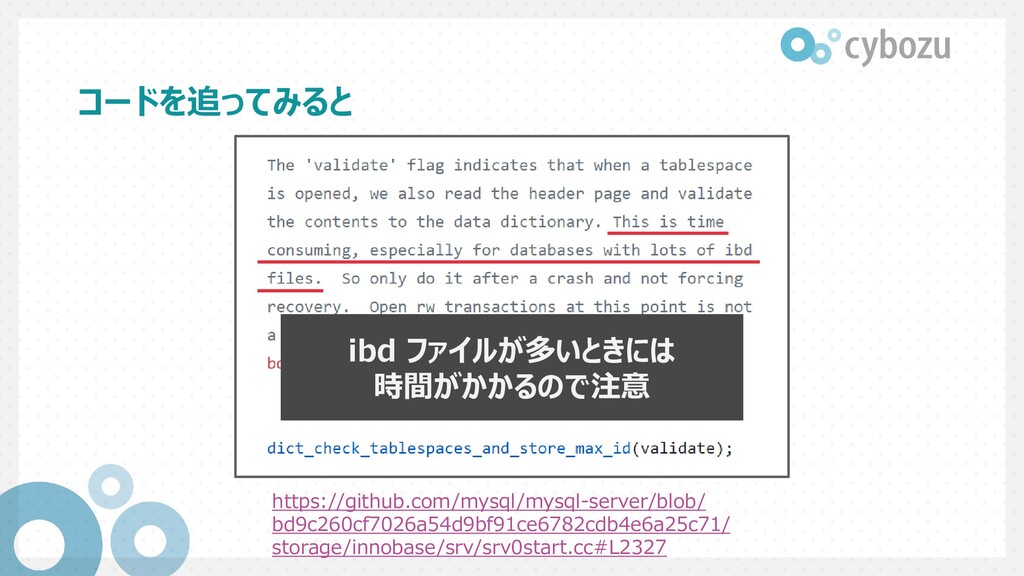
Datafile::validate_to_dd at storage/innobase/fsp/fsp0file.cc:404 #9 fil_ibd_open at storage/innobase/fil/fil0fil.cc:3968 #10 dict_check_sys_tables at storage/innobase/dict/dict0load.cc:1465 #11 dict_check_tablespaces_and_store_max_id at storage/innobase/dict/dict0load.cc:1525 #12 innobase_start_or_create_for_mysql at storage/innobase/srv/srv0start.cc:2329 #13 innobase_init at storage/innobase/handler/ha_innodb.cc:4048
Datafile::validate_to_dd at storage/innobase/fsp/fsp0file.cc:404 #9 fil_ibd_open at storage/innobase/fil/fil0fil.cc:3968 #10 dict_check_sys_tables at storage/innobase/dict/dict0load.cc:1465 #11 dict_check_tablespaces_and_store_max_id at storage/innobase/dict/dict0load.cc:1525 #12 innobase_start_or_create_for_mysql at storage/innobase/srv/srv0start.cc:2329 #13 innobase_init at storage/innobase/handler/ha_innodb.cc:4048 起動時に呼ばれそうな 関数から
Datafile::validate_to_dd at storage/innobase/fsp/fsp0file.cc:404 #9 fil_ibd_open at storage/innobase/fil/fil0fil.cc:3968 #10 dict_check_sys_tables at storage/innobase/dict/dict0load.cc:1465 #11 dict_check_tablespaces_and_store_max_id at storage/innobase/dict/dict0load.cc:1525 #12 innobase_start_or_create_for_mysql at storage/innobase/srv/srv0start.cc:2329 #13 innobase_init at storage/innobase/handler/ha_innodb.cc:4048 validate や check といった 関数が呼ばれている
(and no FRM files) https://www.percona.com/blog/2016/10/03/mysql-8-0-general- tablespaces-file-per-database-no-frm-files/ ▌One Million Tables in MySQL 8.0 https://www.percona.com/blog/2017/10/01/one-million-tables- mysql-8-0/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ある日実際に起きたフェイルオーバー時のログ 04:04:34 [Note] InnoDB: Starting crash recovery. … 04:04:45 [Note]](https://files.speakerdeck.com/presentations/9da13cf1d5b0410bb3f8d6a08b157f7b/slide_10.jpg){kind=link}
![ある日実際に起きたフェイルオーバー時のログ 04:04:34 [Note] InnoDB: Starting crash recovery. … 04:04:45 [Note]](https://files.speakerdeck.com/presentations/9da13cf1d5b0410bb3f8d6a08b157f7b/slide_11.jpg){kind=link}
![ある日実際に起きたフェイルオーバー時のログ 04:04:34 [Note] InnoDB: Starting crash recovery. … 04:04:45 [Note]](https://files.speakerdeck.com/presentations/9da13cf1d5b0410bb3f8d6a08b157f7b/slide_12.jpg){kind=link}
![ある日実際に起きたフェイルオーバー時のログ 04:04:34 [Note] InnoDB: Starting crash recovery. … 04:04:45 [Note]](https://files.speakerdeck.com/presentations/9da13cf1d5b0410bb3f8d6a08b157f7b/slide_13.jpg){kind=link}
![ある日実際に起きたフェイルオーバー時のログ 04:04:34 [Note] InnoDB: Starting crash recovery. … 04:04:45 [Note]](https://files.speakerdeck.com/presentations/9da13cf1d5b0410bb3f8d6a08b157f7b/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![この発表で共有したいこと 1. 私たちを苦しめていた 謎のダウンタイム の正体 2. 復旧を高速化するためのワークアラウンド 04:04:34 [Note] InnoDB:](https://files.speakerdeck.com/presentations/9da13cf1d5b0410bb3f8d6a08b157f7b/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
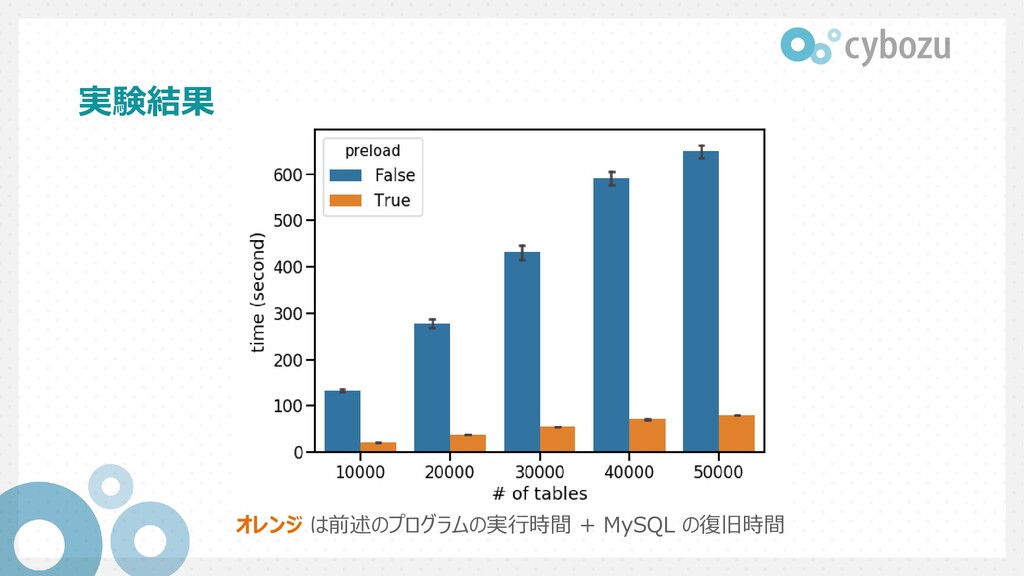{kind=link}
{kind=link}
{kind=link}