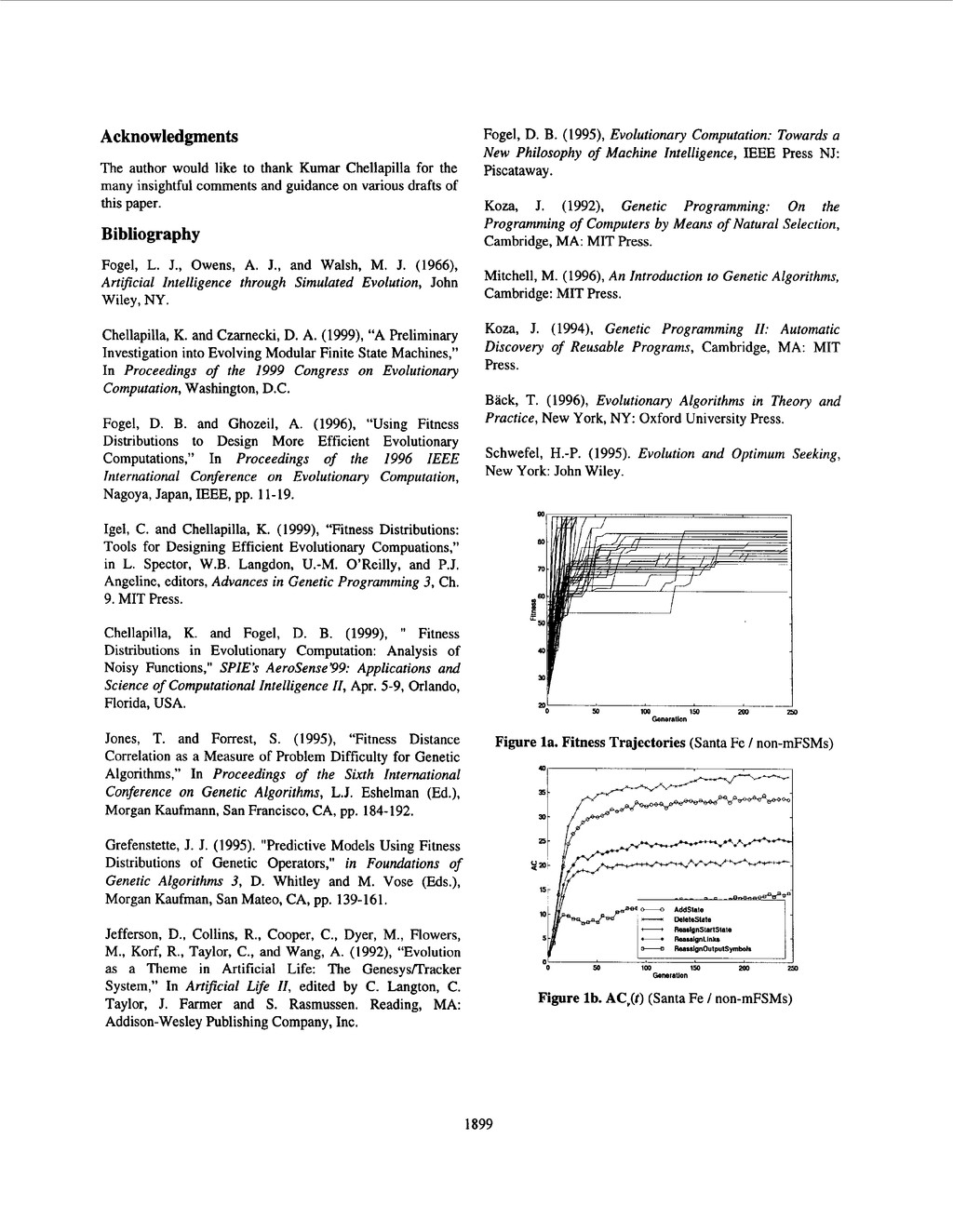
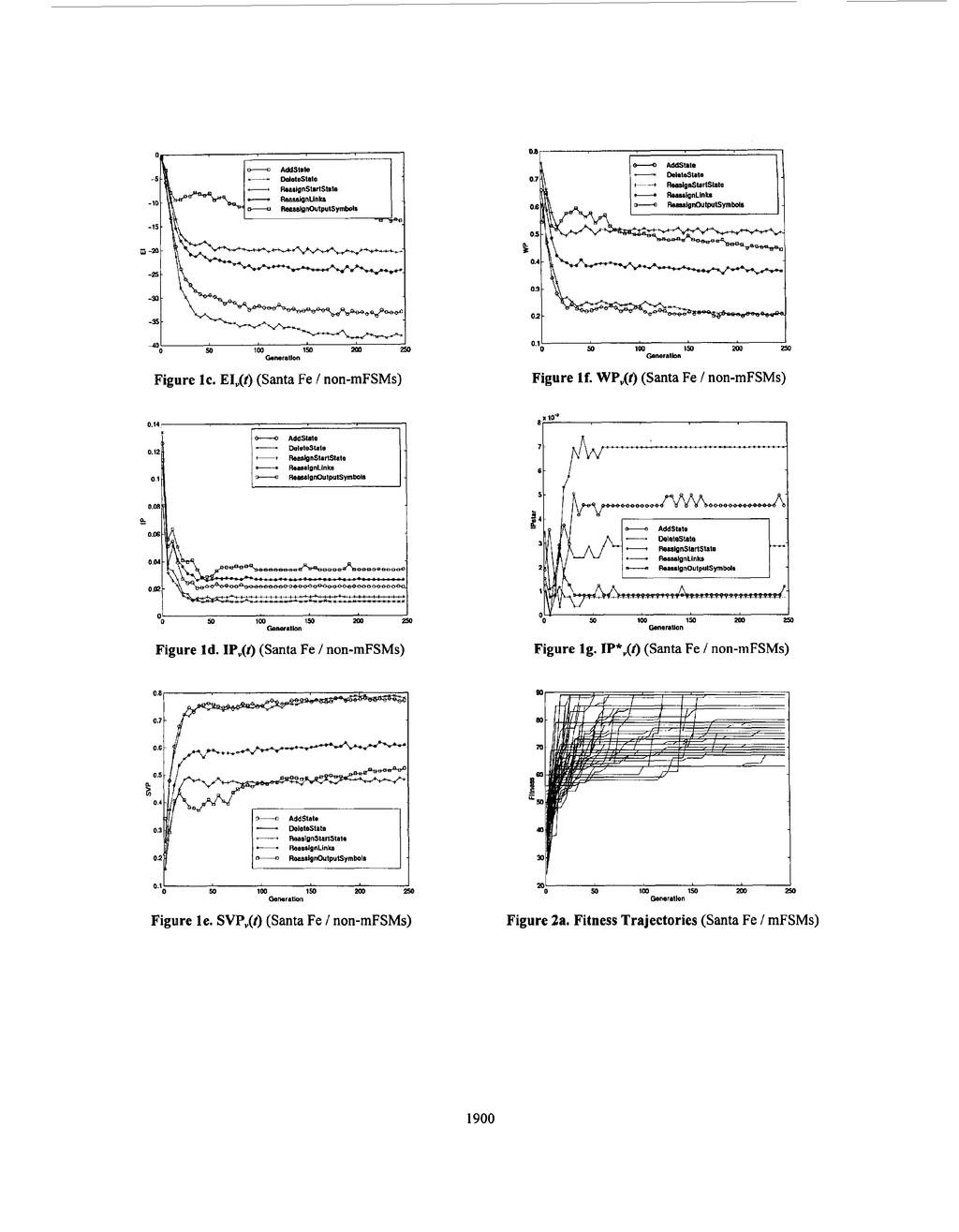
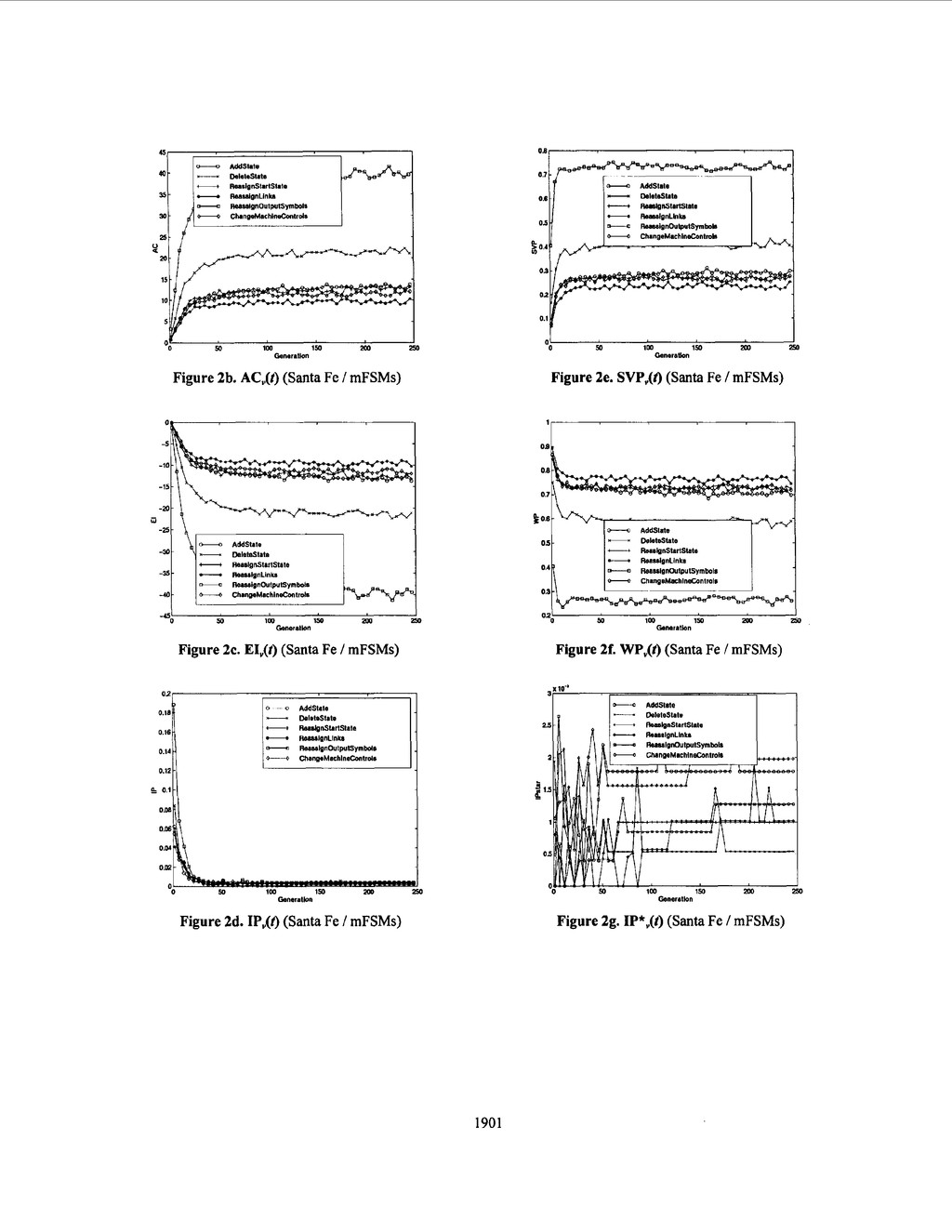
the many insightful comments and guidance on various drafts of this paper. Bibliography Fogel, L. J., Owens, A. J., and Walsh, M. J. (1966), Artificial Intelligence through Simulated Evolution, John Wiley, NY. Chellapilla, K. and Czarnecki, D. A. (1999), “A Preliminary Investigation into Evolving Modular Finite State Machines,” In Proceedings of the 1999 Congress on Evolutionary Computation, Washington, D.C. Fogel, D. B. and Ghozeil, A. (1996), “Using Fitness Distributions to Design More Efficient Evolutionary Computations,” In Proceedings of the I994 IEEE International Conference on Evolutionary Computation, Nagoya, Japan, IEEE, pp. 11-19. Igel, C. and Chellapilla, K. (1999), “Fitness Distributions: Tools for Designing Efficient Evolutionary Compuations,” in L. Spector, W.B. Langdon, U.-M. O’Reilly, and P.J. Angeline, editors, Advances in Genetic Programming 3, Ch. 9. MIT Press. Chellapilla, K. and Fogel, D. B. (1999), ” Fitness Distributions in Evolutionary Computation: Analysis of Noisy Functions,” SPIE’S AeroSense ’99: Applications and Science of Computational Intelligence Il, Apr. 5-9, Orlando, Florida, USA. Jones, T. and Forrest, S. (1995), “Fitness Distance Correlation as a Measure of Problem Difficulty for Genetic Algorithms,” In Proceedings of the Sixth International Conference on Genetic Algorithms, L . J . Eshelman (Ed.), Morgan Kaufmann, San Francisco, CA, pp. 184-192. Grefenstette, J. J. (1995). “Predictive Models Using Fitness Distributions of Genetic Operators,” in Foundations of Genetic Algorithms 3, D. Whitley and M. Vose (Eds.), Morgan Kaufman, San Mateo, CA, pp. 139-161. Jefferson, D., Collins, R., Cooper, C., Dyer, M., Flowers, M., Korf, R., Taylor, C., and Wang, A. (1992), “Evolution as a Theme in Artificial Life: The Genesysnracker System,” In Artijkial Life 11, edited by C. Langton, C. Taylor, J. Farmer and S . Rasmussen. Reading, MA: Addison-Wesley Publishing Company, Inc. Fogel, D. B. (1995), Evolutionary Computation: Towards a New Philosophy of Machine Intelligence, IEEE Press NJ: Piscataway . Koza, J. (1992), Genetic Programming: On the Programming of Computers by Means of Natural Selection, Cambridge, MA: MIT Press. Mitchell, M. (1996), An Introduction to Genetic Algorithms, Cambridge: MIT Press. Koza, J. ( 1994), Genetic Programming 11: Automatic Discovery of Reusable Programs, Cambridge, MA: MIT Press. Back, T. (1996), Evolutionary Algorithms in Theory and Practice, New York, NY: Oxford University Press. Schwefel, H.-P. (1995). Evolution and Optimum Seeking, New York: John Wiley. a. 80 70 40 P 50 1 m 150 200 Generation 20 2 0 / U 50 1 m Generation 150 200 0 Figure la. Fitness Trajectories (Santa Fe / non-mFSMs) 3 5 30 25 15 10 5 0 50 im 150 200 m tenerallon Figure lb. AC,(t) (Santa Fe / non-mFSMs) 1899
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}