programmers know, Python and Ruby feature a Global Interpreter Lock (GIL) • More precise: CPython and MRI • It limits thread performance on multicore • Theoretically restricts code to a single CPU 2
a trivial CPU-bound function def countdown(n): while n > 0: n -= 1 3 • Run it once with a lot of work COUNT = 100000000 # 100 million countdown(COUNT) • Now, divide the work across two threads t1 = Thread(target=count,args=(COUNT//2,)) t2 = Thread(target=count,args=(COUNT//2,)) t1.start(); t2.start() t1.join(); t2.join()
threaded versions perform the same amount of work (same # calculations) • There is the GIL... so no parallelism • Performance should be about the same 5
11 Sequential Threaded (2 threads) : 6.9s : 63.0s (9.1x slower!) • Ruby 1.9 on Windows Server 2008 (2 cores) Sequential Threaded (2 threads) : 3.32s : 3.45s (~ same) • Why does it get that much slower on Windows?
• A simple test - message echo (pseudocode) def client(nummsg,msg): while nummsg > 0: send(msg) resp = recv() sleep(0.001) nummsg -= 1 def server(): while True: msg = recv() send(msg) • To be less evil, it's throttled (<1000 msg/sec) • Not a messaging stress test
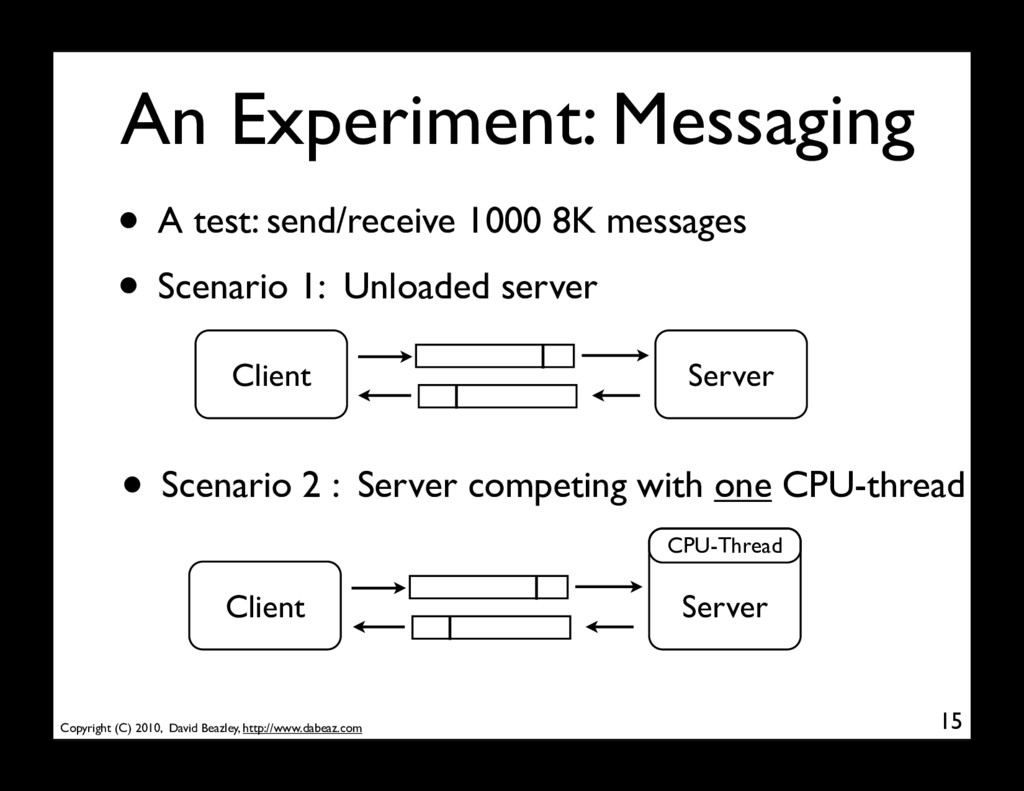
• A test: send/receive 1000 8K messages • Scenario 1: Unloaded server Server Client • Scenario 2 : Server competing with one CPU-thread Server Client CPU-Thread
GIL does far more than limit cores • It can make performance much worse • Better performance by turning off cores? • 5000x performance hit on Linux? • Why? 23
• Must you abandon Python/Ruby for concurrency? • Having threads restricted to one CPU core might be okay if it were sane • Analogy: A multitasking operating system (e.g., Linux) runs fine on a single CPU • Plus, threads get used a lot behind the scenes (even in thread alternatives, e.g., async) 24
have been discussing some of these issues in the Python community since 2009 26 http://www.dabeaz.com/GIL • I'm less familiar with Ruby, but I've looked at its GIL implementation and experimented • Very interested in commonalities/differences
threads (e.g., pthreads) • Managed by OS • Concurrent execution of the Python interpreter (written in C) 28 • System threads (e.g., pthreads) • Managed by OS • Concurrent execution of the Ruby VM (written in C)
Parallel execution is forbidden • There is a "global interpreter lock" • The GIL ensures that only one thread runs in the interpreter at once • Simplifies many low-level details (memory management, callouts to C extensions, etc.) 29
The GIL results in cooperative multitasking 31 Thread 1 Thread 2 Thread 3 block block block block block • When a thread is running, it holds the GIL • GIL released on blocking (e.g., I/O operations) run run run run run release GIL acquire GIL release GIL acquire GIL
You may actually want to compute something! • Fibonacci numbers • Image/audio processing • Parsing • The CPU will be busy • And it won't give up the GIL on its own 33
and reacquires the GIL every 100 "ticks" • 1 Tick ~= 1 interpreter instruction 34 • Background thread generates a timer interrupt every 10ms • GIL released and reacquired by current thread on interrupt
CPU Bound Thread Run 100 ticks Run 100 ticks Run 100 ticks • Every 100 VM instructions, GIL is dropped, allowing other threads to run if they want • Not time based--switching interval depends on kind of instructions executed release acquire release acquire release acquire
CPU Bound Thread Run Run Timer Thread Timer (10ms) Timer (10ms) release acquire release acquire • Loosely mimics the time-slice of the OS • Every 10ms, GIL is released/acquired
Both Python and Ruby have C code like this: 37 void execute() { while (inst = next_instruction()) { // Run the VM instruction ... if (must_release_gil) { GIL_release(); /* Other threads may run now */ GIL_acquire(); } } } • Exact details vary, but concept is the same • Each thread has periodic release/acquire in the VM to allow other threads to run
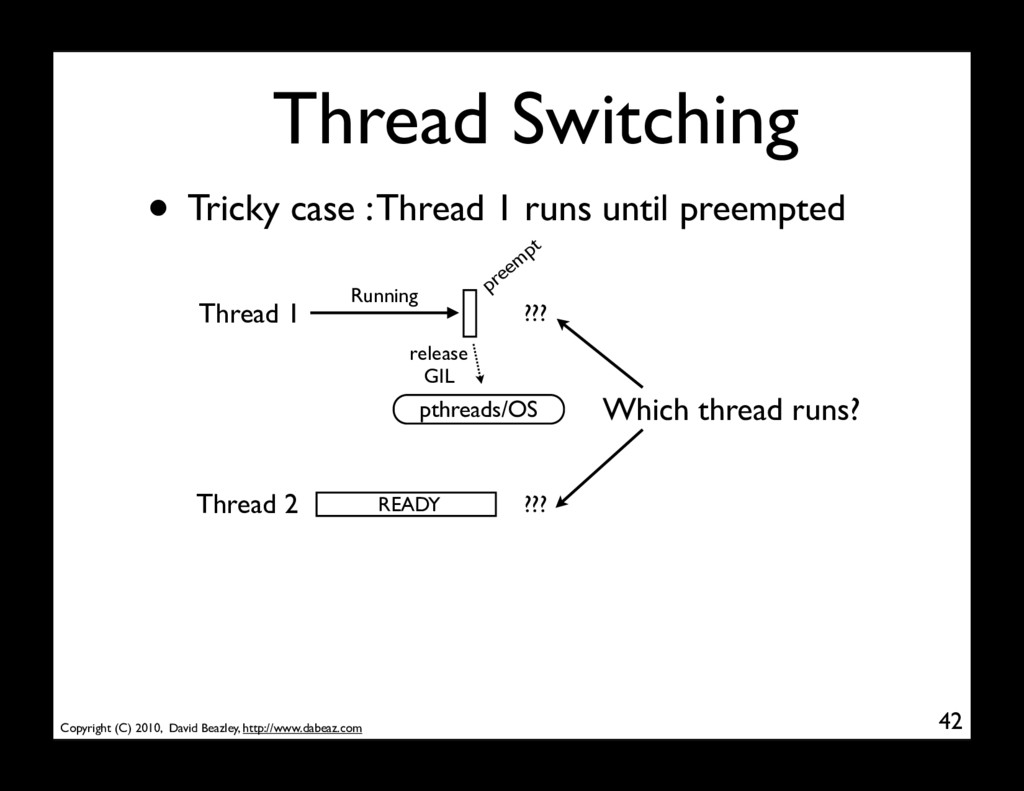
might expect that Thread 2 will run 43 • But you assume the GIL plays nice... Thread 1 Running Thread 2 READY preem pt pthreads/OS release GIL Running schedule READY acquire GIL
might actually happen on multicore 44 Thread 1 Running Thread 2 READY preem pt pthreads/OS release GIL schedule Running acquire GIL fails (GIL locked) READY • Both threads attempt to run simultaneously • ... but only one will succeed (depends on timing)
{ GIL_release(); /* Other threads may run now */ GIL_acquire(); } • This code doesn't actually switch threads • It might switch threads, but it depends • What operating system • # cores • Lock scheduling policy (if any)
{ GIL_release(); sleep(0); /* Other threads may run now */ GIL_acquire(); } • This doesn't force switching (sleeping) • It might switch threads, but it depends • What operating system • # cores • Lock scheduling policy (if any)
{ GIL_release(); sched_yield() /* Other threads may run now */ GIL_acquire(); } • Neither does this (calling the scheduler) • It might switch threads, but it depends • What operating system • # cores • Lock scheduling policy (if any)
are conflicting goals • Python/Ruby - wants to run on a single CPU, but doesn't want to do thread scheduling (i.e., let the OS do it). • OS - "Oooh. Multiple cores." Schedules as many runnable tasks as possible at any instant • Result: Threads fight with each other 48
there is a CPU-bound thread, I/O bound threads have a hard time getting the GIL 51 Thread 1 (CPU 1) Thread 2 (CPU 2) Network Packet Acquire GIL (fails) run Acquire GIL (fails) Acquire GIL (fails) Acquire GIL (success) preempt preempt preempt preempt run sleep Might repeat 100s-1000s of times run run run
Messaging on Linux (8 Cores) Ruby 1.9 (no threads) Ruby 1.9 (1 CPU thread) : 1.18s : 5839.4s • Locks in Linux have no fairness • Consequence: Really hard to steal the GIL • And Ruby only retries every 10ms
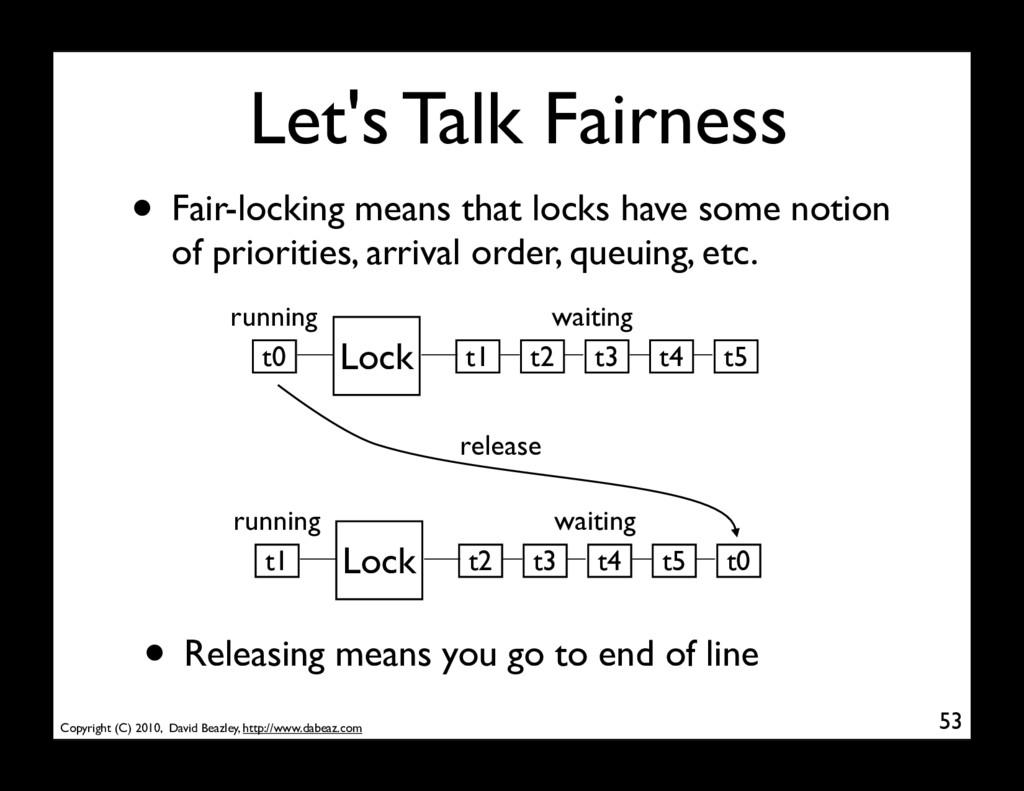
• Fair-locking means that locks have some notion of priorities, arrival order, queuing, etc. Lock t1 t2 t3 t4 t5 waiting t0 running Lock t2 t3 t4 t5 t0 waiting t1 running release • Releasing means you go to end of line
What actually happens under the covers def server(): while True: size = recv(4) msg = recv(size) send(size) send(msg) GIL release GIL release GIL release GIL release • Why? Each operation might block • Catch: Passes control back to CPU-bound thread
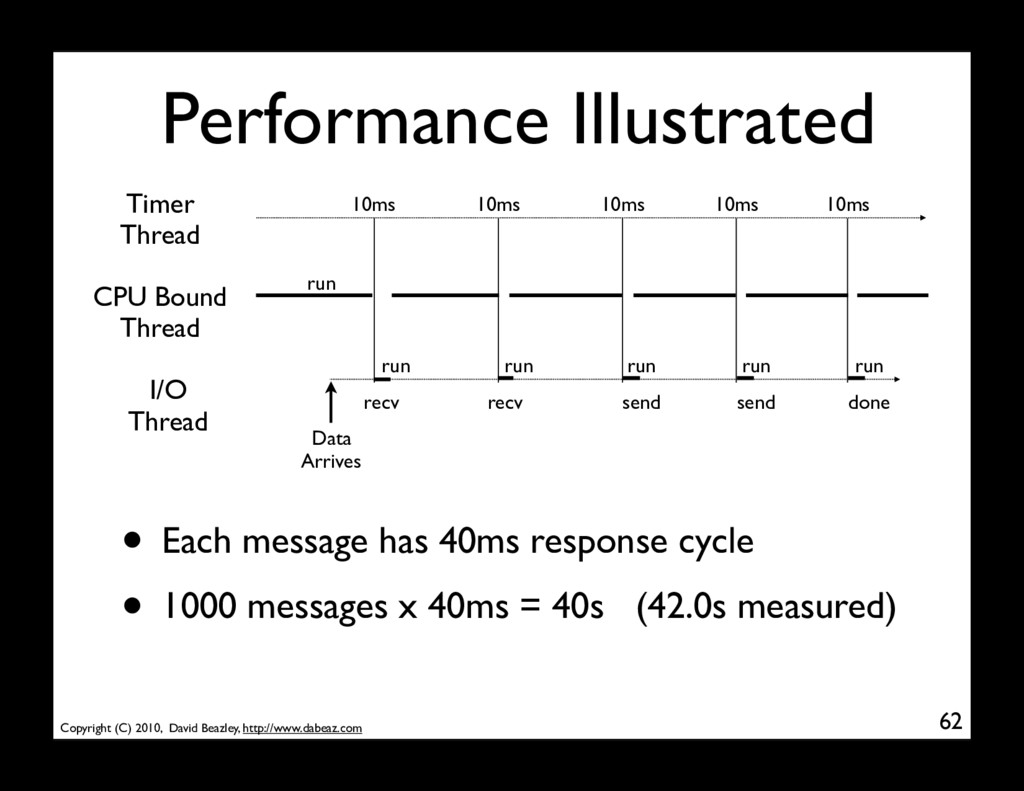
Bound Thread run Timer Thread 10ms I/O Thread 10ms 10ms 10ms Data Arrives recv recv send send done run run run run run 10ms • Each message has 40ms response cycle • 1000 messages x 40ms = 40s (42.0s measured)
yes, everyone hates threads • However, that's only because they're useful! • Threads are used for all sorts of things • Even if they're hidden behind the scenes 64 Don't use threads!
GIL acquisition now based on timeouts 67 Thread 1 Thread 2 READY running wait(gil, TIMEOUT) release running IOWAIT data arrives wait(gil, TIMEOUT) 5ms drop_request • Involves waiting on a condition variable
threads significantly degrade I/O 68 Thread 1 Thread 2 READY running run data arrives • This is the same problem as in Ruby • Just a shorter time delay (5ms) data arrives running READY run release running READY data arrives 5ms 5ms 5ms
can directly observe the delays (messaging) 69 Python/Ruby (No threads) Python 3.2 (1 Thread) Ruby 1.9 (1 Thread) : 1.29s (no delays) : 20.1s (5ms delays) : 42.0s (10ms delays) • Still not great, but problem is understood
: Priority scheduling • Earlier versions of Ruby had it • It works (OS-X, 4 cores) 71 Ruby 1.9 (1 Thread) Ruby 1.8.7 (1 Thread) Ruby 1.8.7 (1 Thread, lower priority) : 42.0s : 40.2s : 10.0s • Comment: Ruby-1.9 allows thread priorities to be set in pthreads, but it doesn't seem to have much (if any) effect
bring new challenges • Starvation • Priority inversion • Implementation complexity • Do you have to write a full OS scheduler? • Hopefully not, but it's an open question 73
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}