We’re a broadcast analytics company that is powered by convos in social media. MEASURE AND UNDERSTAND TV AUDIENCES With the advent of social media convos have moved from the living room to the web. We spotted an opportunity to harness these conversations to provide insights to allow Broadcasters, prog makers, advertisers, brand - understand the audience better. Development of the platform started in late 2011, and I’m going to talk about how its architecture developed and changed. I hope to provide you with some useful pointers for managing change in a data platform while maintaining your sanity and your clients’ unconditional adoration.
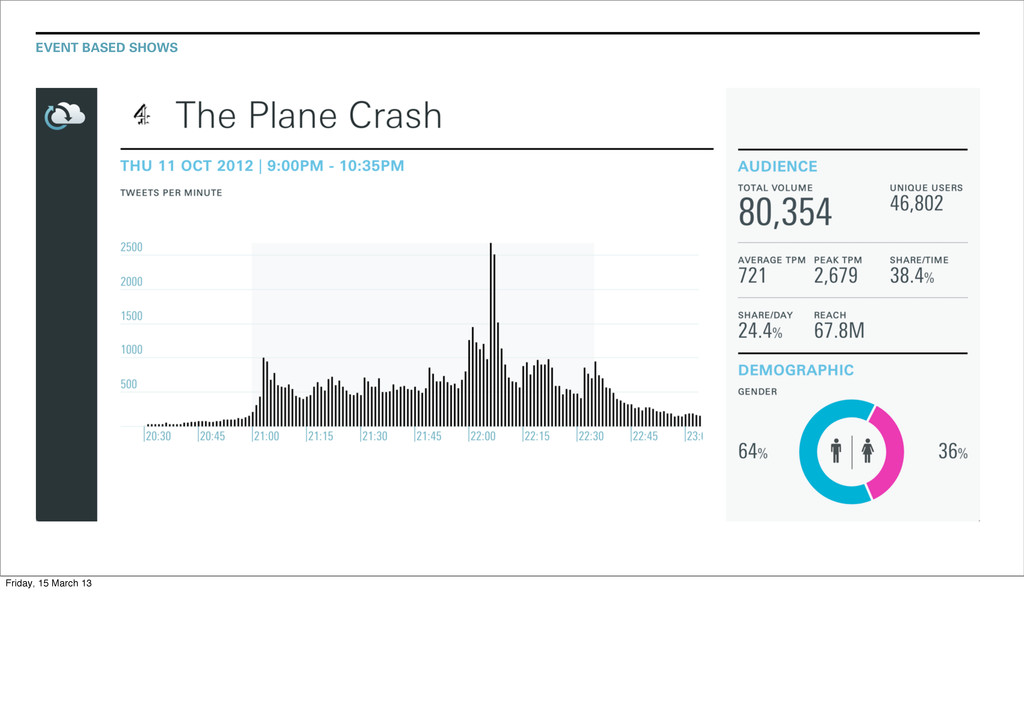
search terms • Search the firehose for matching Tweets • Show them in a pretty UI • Profit! Friday, 15 March 13 We live in the hip and groovy world of audience measurement - the social equivalent of 9m people watched EastEnders
cloud servers for our application Relatively constant load. EC2 *very* expensive. We also do broadcast monitoring, hard to hang an aerial on the cloud.
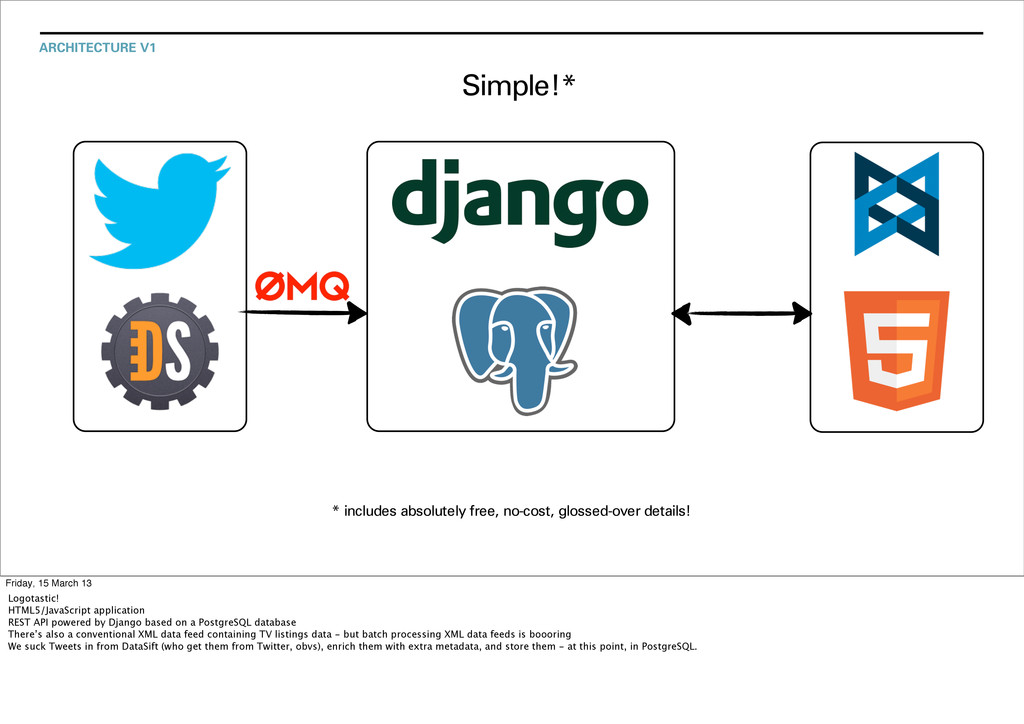
Friday, 15 March 13 Logotastic! HTML5/JavaScript application REST API powered by Django based on a PostgreSQL database There’s also a conventional XML data feed containing TV listings data - but batch processing XML data feeds is boooring We suck Tweets in from DataSift (who get them from Twitter, obvs), enrich them with extra metadata, and store them - at this point, in PostgreSQL.
sanity to network programming No, it’s not really a message queue. Well, it is, but that’s only an implementation detail. Provides a few socket types: push/pull, publish/subscribe, request/reply, router/dealer Various patterns possible, see the Guide Lets you easily write small daemons that talk to each other over 0MQ - discourages shared state, encourages message-based architecture = easier to scale This probably sounds familiar to Erlang programmers ;) Many language bindings = use the right language/tool for the job, plumb your C/Python/Erlang bits together using 0MQ Can even use inproc to get rid of traditional shared state/mutex architectures with internal message passing = much more reliable, faster. We use 0MQ in our tweet processing pipeline - tweets come in from DS, we fan out to a number of workers, enrich and persist Factor your application in components talking over 0MQ, and you need maintain only your message formats, no fragile, monolithic architecture
JSON documents PostgreSQL is rubbish for working with JSON documents. It’s a relational database, after all. Large tables are painful All we could do was offer some simple tweet counts and filters Any extra filter required ALTER TABLE (which is actually OK in PostgreSQL) to add a field for it, and modifications to the processing pipeline to extract the field from the tweet JSON and store it
that: • Stored JSON natively • Talked HTTP for easy integration • Handled slowly changing schemas gracefully • Was very fast to query • Just Add Servers Friday, 15 March 13 Anyone? Anyone?
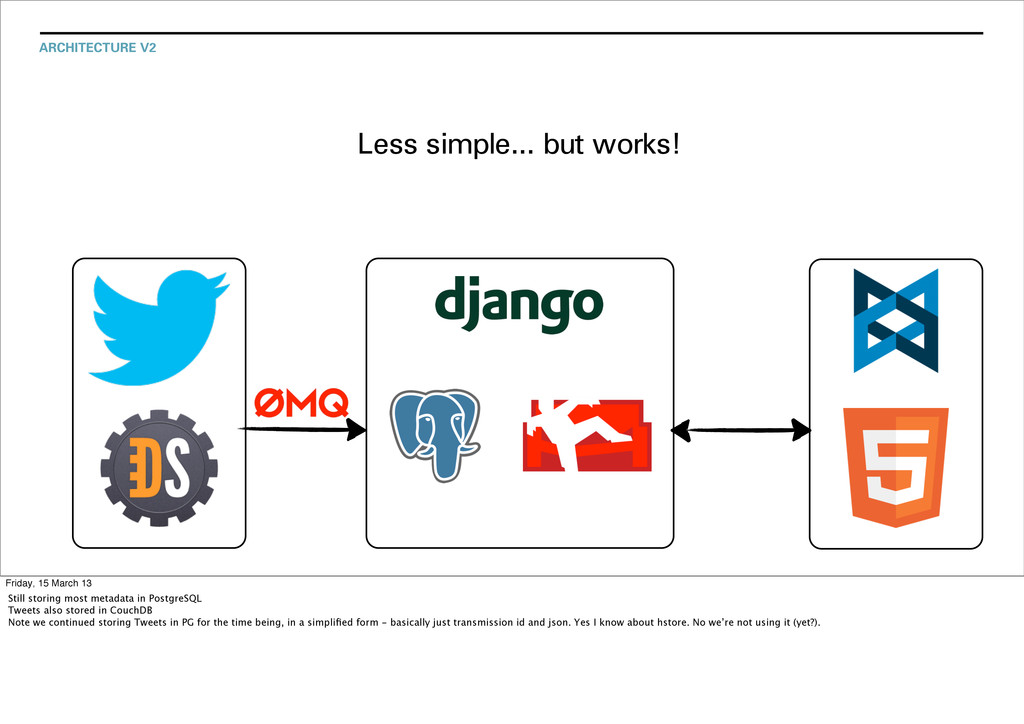
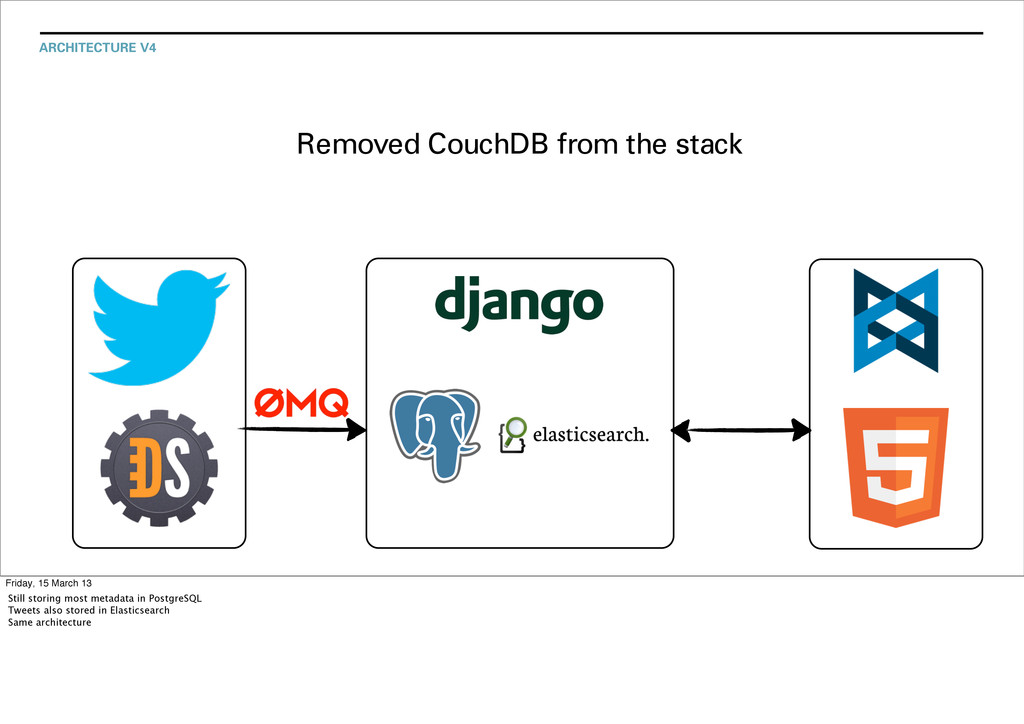
Still storing most metadata in PostgreSQL Tweets also stored in CouchDB Note we continued storing Tweets in PG for the time being, in a simplified form - basically just transmission id and json. Yes I know about hstore. No we’re not using it (yet?).
while • I even priced up using Cloudant • I asked their support folks Difficult Questions • Then we had some new requirements • Apply multiple filters at once • Smattering of ad-hoc analysis Friday, 15 March 13
but... • Combinatorial view explosion Friday, 15 March 13 Basically need a view in CouchDB for each kind of query you’re going to do This rapidly grows extremely painful as you add more filters
that: • Stored JSON natively • Talked HTTP for easy integration • Handled slowly changing schemas gracefully • Was very fast to query • And supported flexible, ad-hoc-ish querying • Just Add Servers Friday, 15 March 13
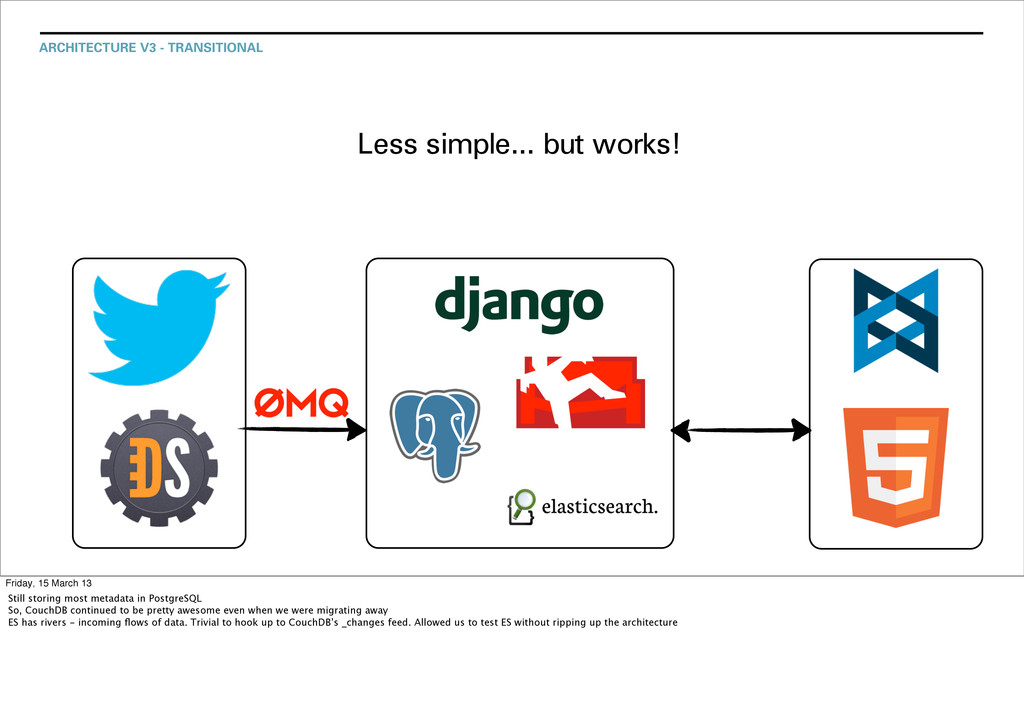
March 13 Still storing most metadata in PostgreSQL So, CouchDB continued to be pretty awesome even when we were migrating away ES has rivers - incoming flows of data. Trivial to hook up to CouchDB’s _changes feed. Allowed us to test ES without ripping up the architecture
system can talk HTTP, it makes life easier for everyone • ... but you CouchDB folks knew that already :) KEY POINT: HTTP FOR EXTERNAL SERVICES Friday, 15 March 13
Yes, tweets still get written to PostgreSQL • Dump tweets older than 1 month to S3 • Not without problems (OHAI AUTOVACUUM) Friday, 15 March 13 Autovaccuum - among other things - reclaims space. Bit like compaction. Poor case which we hit with large inserts and deletes -> partitioning
CouchDB story though • PostgreSQL isn’t the right choice for either: • The short-term storage before tweets go into Elasticsearch • Longer-term storage for data mining Friday, 15 March 13 Currently, tweets come in live and aren’t persisted until they’ve been enriched and stored in PostgreSQL Not ideal - if something in the 0MQ pipeline breaks, we lose tweets. CouchDB could be a good fit here, as a short term store. Rendundant streamer with own standalone store. Can then replicate in on-demand. Some challenges around Adaptive Search. Longer term storage, maybe less likely - something like Cassandra or HDFS probably a better fit - would be nice to leverage all the tooling in the Hadoop world, even if it looks a nightmare to maintain...
individual pieces and components when you have well-defined interfaces between them Friday, 15 March 13 For us, this basically boils down to the JSON structure of the Tweet.
they’re unit, integration, functional, Byzantine, or minty • They should be there, they should have good coverage, and they should be automated Friday, 15 March 13 Tough to make three-and-a-bit architecture changes without comprehensive tests to make sure you haven’t broken anything. Especially when the backend tech team is just you.
this time we’d kept on storing those tweets in PostgreSQL Turns out that while PostgreSQL is rubbish for querying json objects, it’s actually pretty good at storing lots of text TOAST - best thing since sliced bread - allows large values to be stored efficiently, compressed transparently Kept a lid on disk usage while we figured stuff out Tens to hundreds of millions of rows in a table (just don’t query it by anything except a very selective index) Handy! PostgreSQL rocks. POSTGRESQL ROCKS Sure, it has its limitations. But it’s an incredible piece of software. Not all problems are non-relational, folks!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}