Taghrid Samak1, Monte Goode1, Ewa Deelman2, Gaurang Mehta2, Fabio Silva2, Karan Vahi2 Christopher Brooks3 Priscilla Moraes4, Martin Swany4 1 1 Lawrence Berkeley National Laboratory 2 University of Southern California, Information Sciences Institute 3 University of San Francisco 4 University of Delaware
Is a given workflow going to “fail”? Are specific resources causing problems? Which application sub-components are failing? Is the data staging a problem? In large workflows, some failures, etc. are normal This work is about learning from known problems, which patterns of failures, etc. are unusual and require adaptation Do all of this as generally as possible: Can we provide a solution that can apply to all workflow engines? 3 CNSM 2011, October 24-28, Paris, France
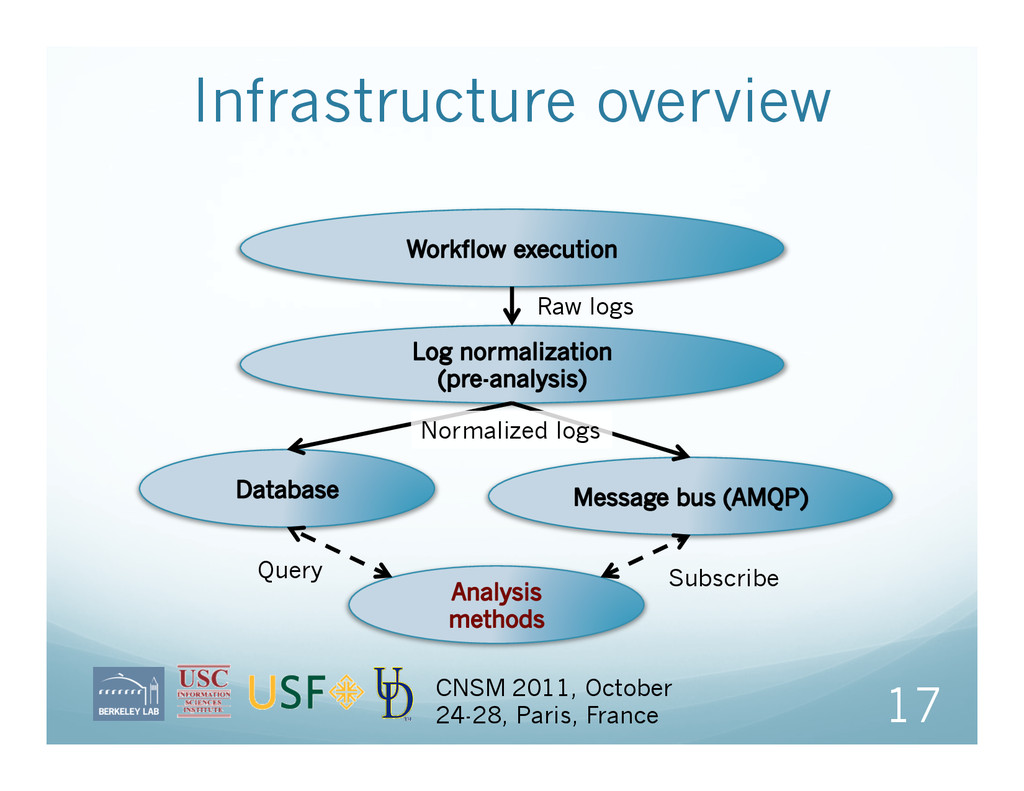
Collect all the data in real-time Run analysis, also in real-time, on the collected data map low-level failures to application-level characteristics Feed back analysis to user, workflow engine 4 CNSM 2011, October 24-28, Paris, France
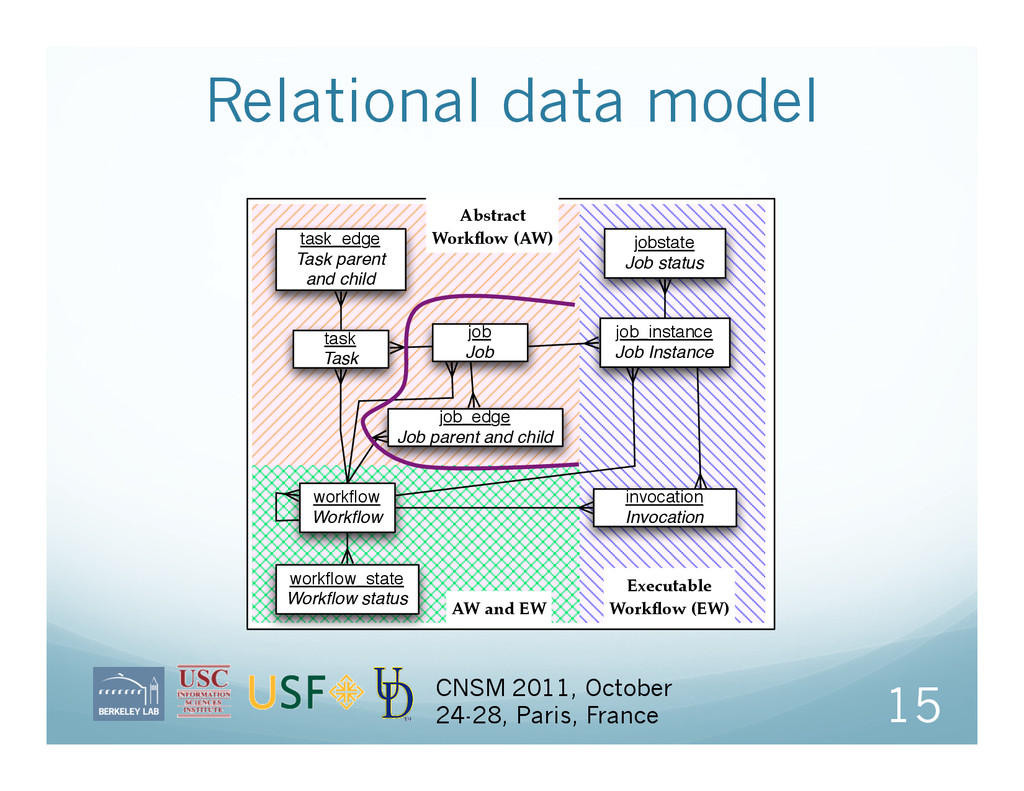
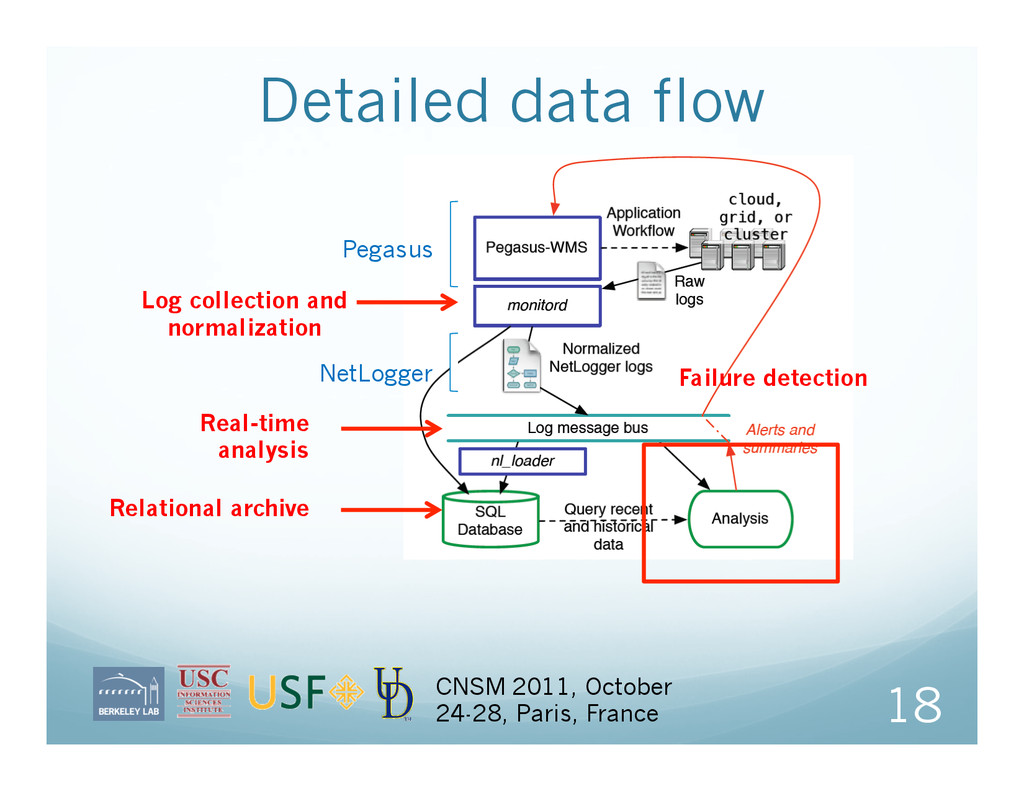
France Workflows start as a resource-independent statement of computations, input and output data, and dependencies This is called the Abstract Workflow (AW) For each workflow run, Pegasus-WMS plans the workflow, adding helper tasks and clustering small computations together This is called the Executable Workflow (EW) Note: Most of the logs are from the EW but the user really only knows the AW.
Sub-workflow: Workflow that is contained in another workflow Task: Representation of a computation in the AW Job: Node in the EW May represent part of a task (e.g., a stage-in/out), one task, or many tasks Job instance: Job scheduled or running by underlying system Due to retries, there may be multiple job instances per job Invocation: One or more executables for a job instance Invocations are the instantiation of tasks, whereas jobs are an intermediate abstraction for use by the planning and scheduling sub-systems 13 CNSM 2011, October 24-28, Paris, France
hierarchical, name unique identifiers (workflow, job, etc.) values and metadata Used NETCONF YANG data-modeling language, keyed on event name [RFCs: 6020 6021 (6087)] YANG schema (see bit.ly/nQfPd1) documents and validates each log event 14 CNSM 2011, October 24-28, Paris, France container stampede.xwf.start { description “Start of executable workflow”; uses base-event; leaf restart_count { type uint32; description "Number of times workflow was restarted (due to failures)”; }} Snippet of schema
AW and EW task_edge Task parent and child task Task job Job jobstate Job status job_instance Job Instance workflow Workflow job_edge Job parent and child workflow_state Workflow status invocation Invocation CNSM 2011, October 24-28, Paris, France
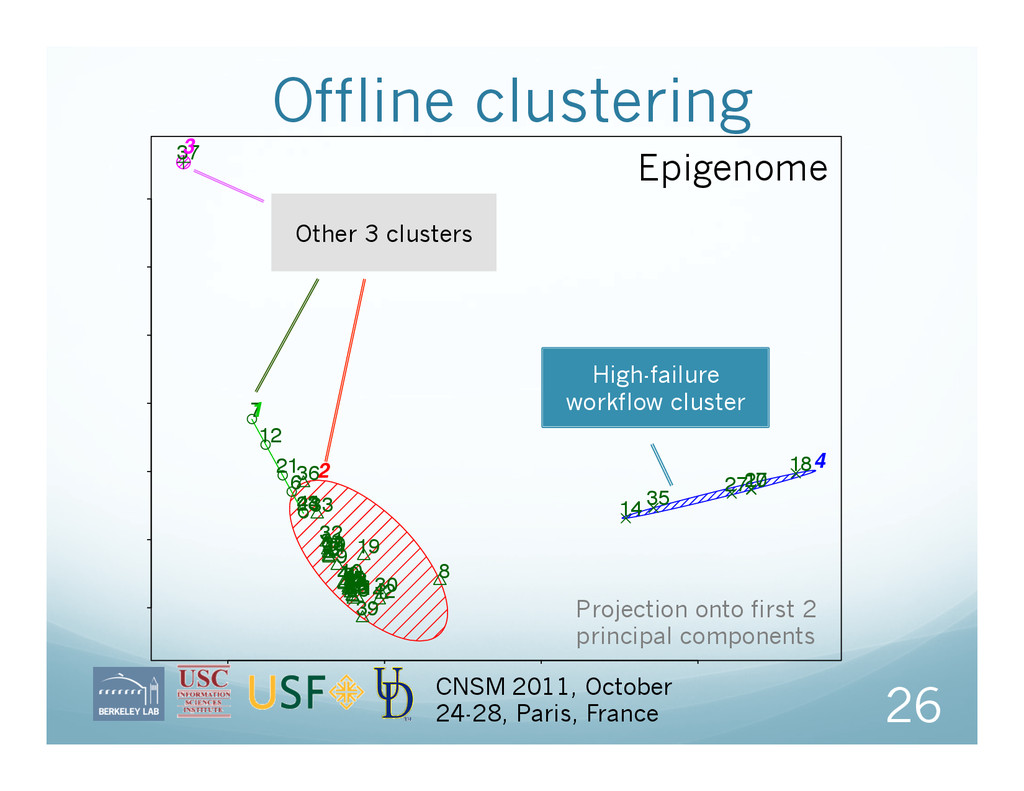
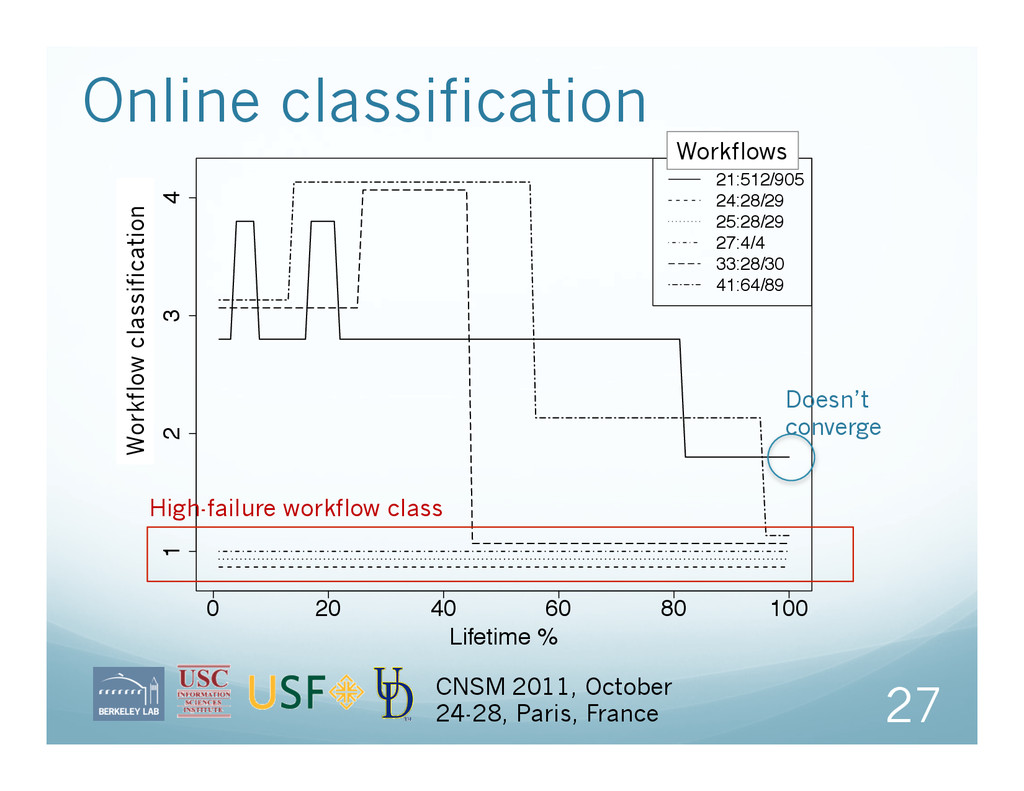
Successful jobs Failed jobs Success duration Fail duration Offline clustering on historical data Algorithm: k-means Online analysis classifies workflows according to nearest cluster 22
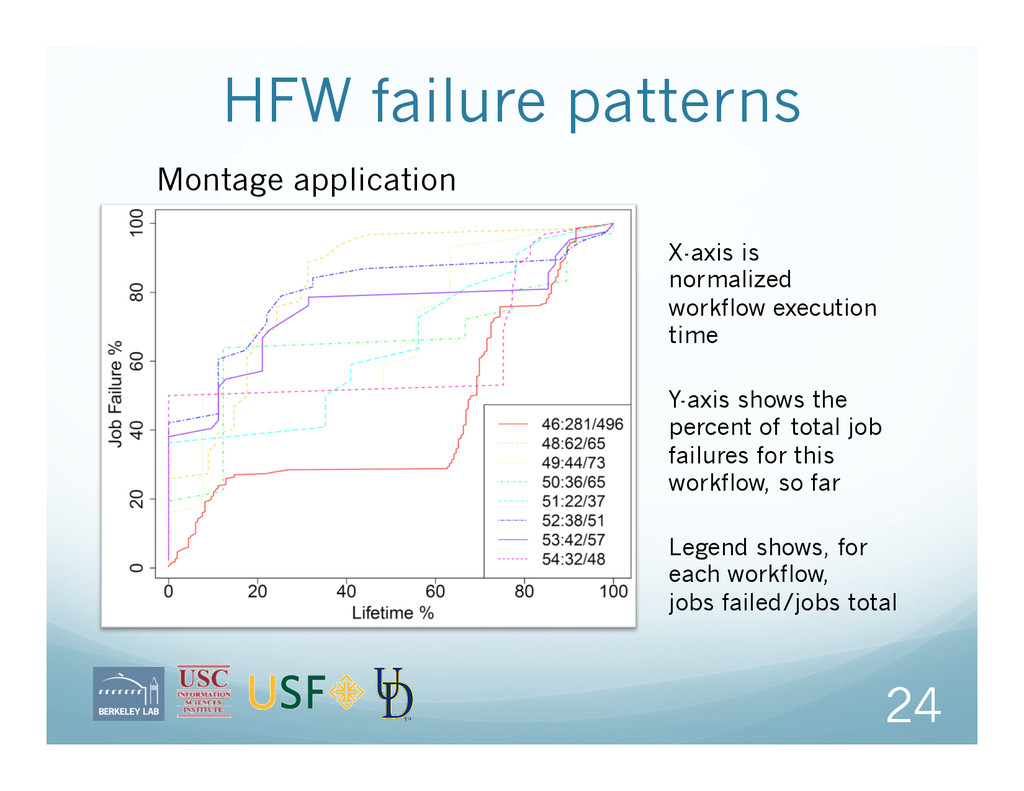
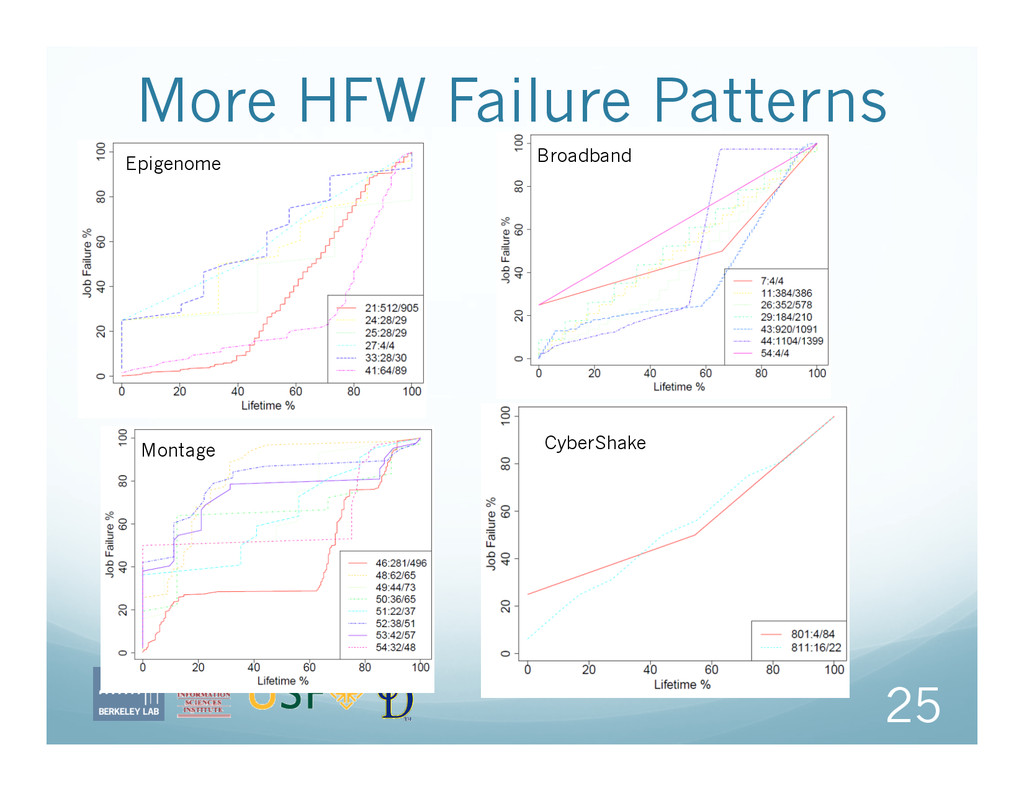
workflows until they complete or time out But in the experimental logs, workflows are never marked as “failed” Aside: this is fixed in the newest version Therefore, we use a simple heuristic for identifying workflows as problematic: HFW means: > 50% of jobs failed 23 CNSM 2011, October 24-28, Paris, France
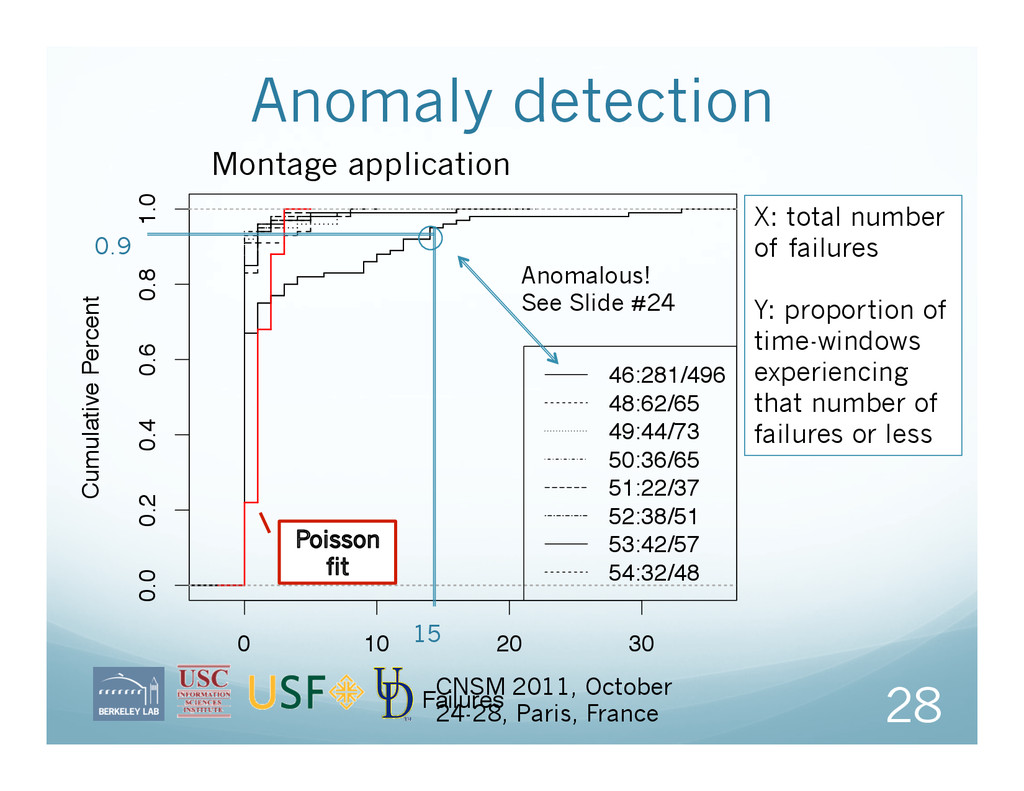
job failures for this workflow, so far Legend shows, for each workflow, jobs failed/jobs total X-axis is normalized workflow execution time Montage application
0.8 1.0 Failures Cumulative Percent 46:281/496 48:62/65 49:44/73 50:36/65 51:22/37 52:38/51 53:42/57 54:32/48 28 CNSM 2011, October 24-28, Paris, France X: total number of failures Y: proportion of time-windows experiencing that number of failures or less 0.9 15 Montage application Anomalous! See Slide #24
challenging but important task Unsupervised learning can be used to model high- level workflow failures from historical data High failure classes of workflows can be predicted in real-time with high accuracy Future directions Analysis; root-cause investigation System; notifications and updates Working with data from other workflow systems CNSM 2011, October 24-28, Paris, France 30
and AI-based techniques Automatically locates physical locations for both workflow components and data Finds appropriate resources to execute Reuses existing data products where applicable Publishes newly derived data products Provides provenance information 34 CNSM 2011, October 24-28, Paris, France
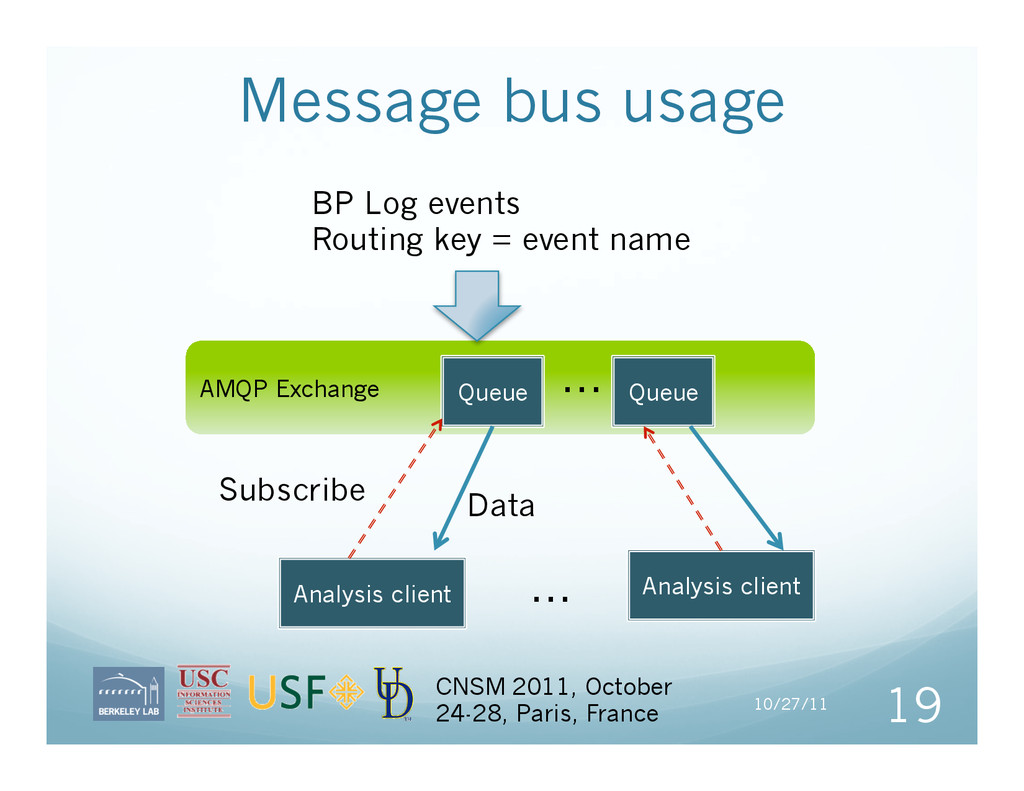
start and end of significant events, with additional identifiers and metadata in a std. line-oriented ASCII format (Best Practices or BP) APIs are provided, incl. in-memory log aggregation for high frequency events; but message generation is often best done within an existing framework Logging and Analysis Tools Parse many existing formats to BP Load BP into message bus, MySQL, MongoDB, etc. Generate profiles, graphs, and CSV from BP data 35 CNSM 2011, October 24-28, Paris, France
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}