on the rapid development of novel functional materials. But it takes almost twenty years to develop new materials. How can we do it faster? Solar cells, advanced batteries, TCOs, and fuel cells will all play a role in our energy future.
2011: Materials Genome Ini/a/ve which aims to “fund computa(onal tools, so-ware, new methods for material characteriza2on, and the development of open standards and databases that will make the process of discovery and development of advanced materials faster, less expensive, and more predictable” Source: "Materials Genome IniBaBve for Global CompeBBveness" hFp://www.whitehouse.gov/sites/default/files/microsites/ostp/materials_genome_iniBaBve-‐final.pdf
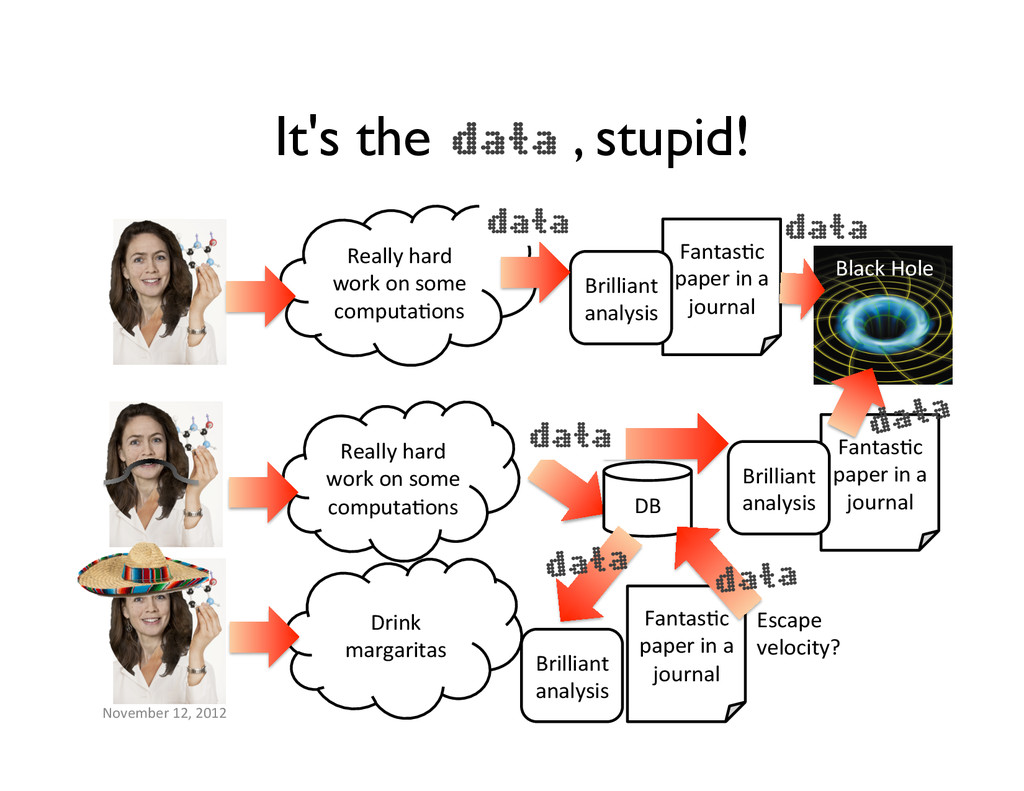
work on some computaBons FantasBc paper in a journal Really hard work on some computaBons FantasBc paper in a journal Black Hole data data Drink margaritas FantasBc paper in a journal DB data Brilliant analysis Brilliant analysis Brilliant analysis Escape velocity? data data data data
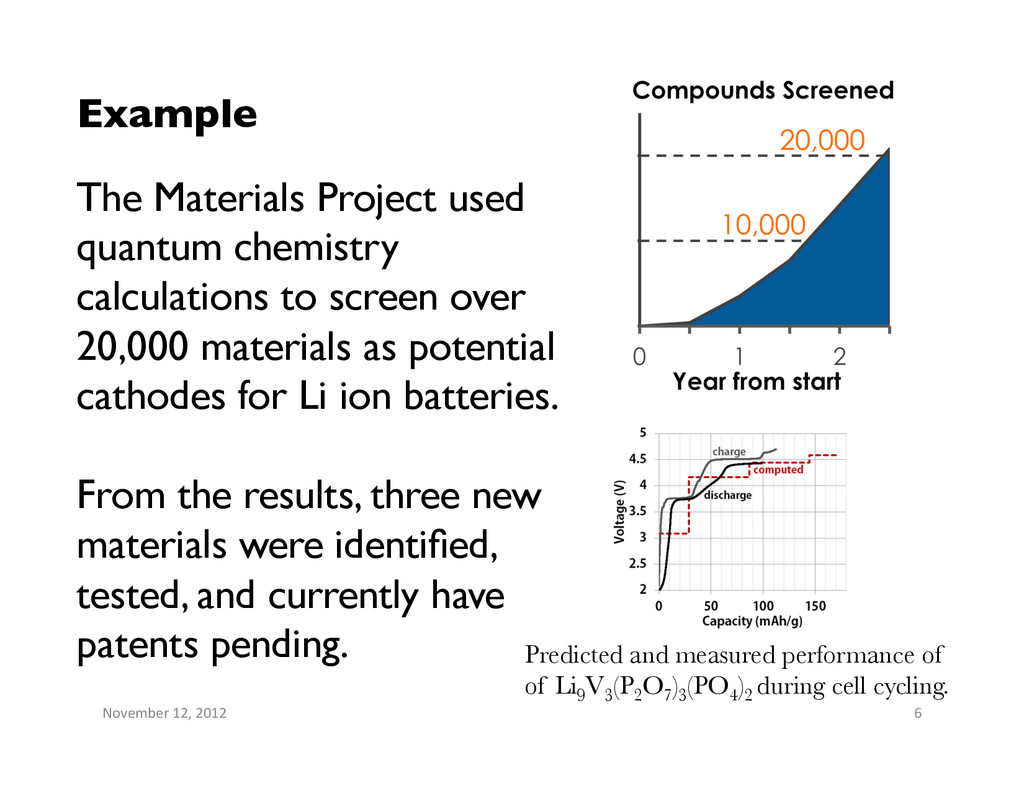
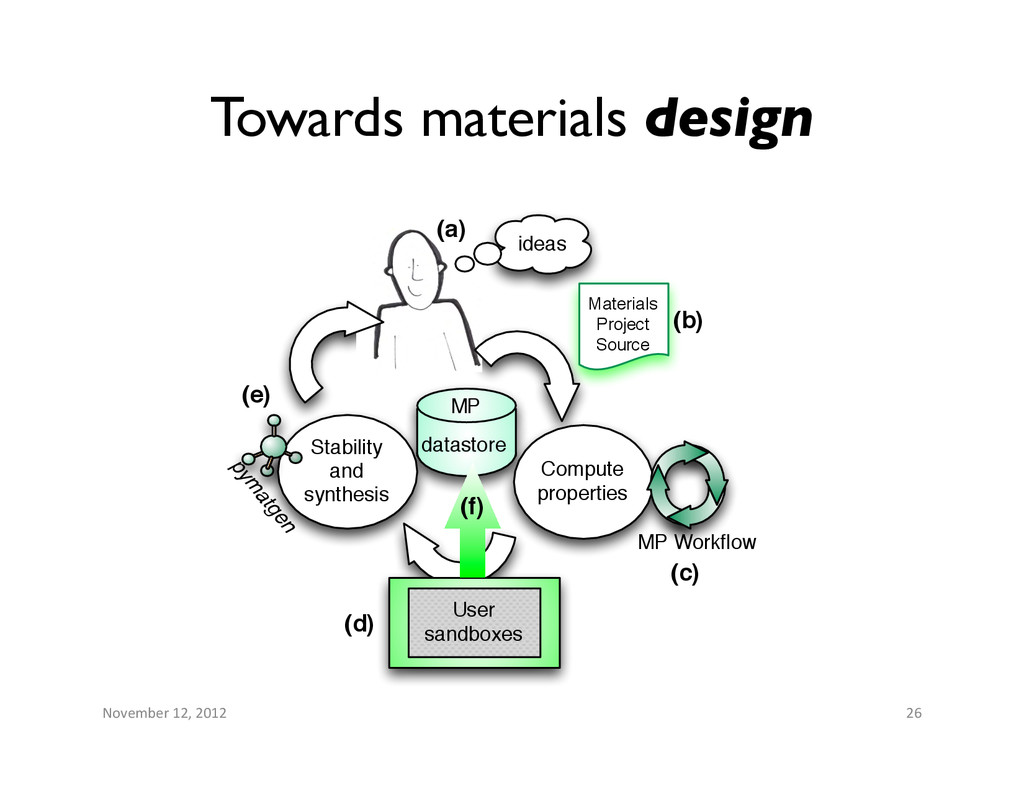
performance of of Li9 V3 (P2 O7 )3 (PO4 )2 during cell cycling. The Materials Project used quantum chemistry calculations to screen over 20,000 materials as potential cathodes for Li ion batteries. From the results, three new materials were identified, tested, and currently have patents pending.
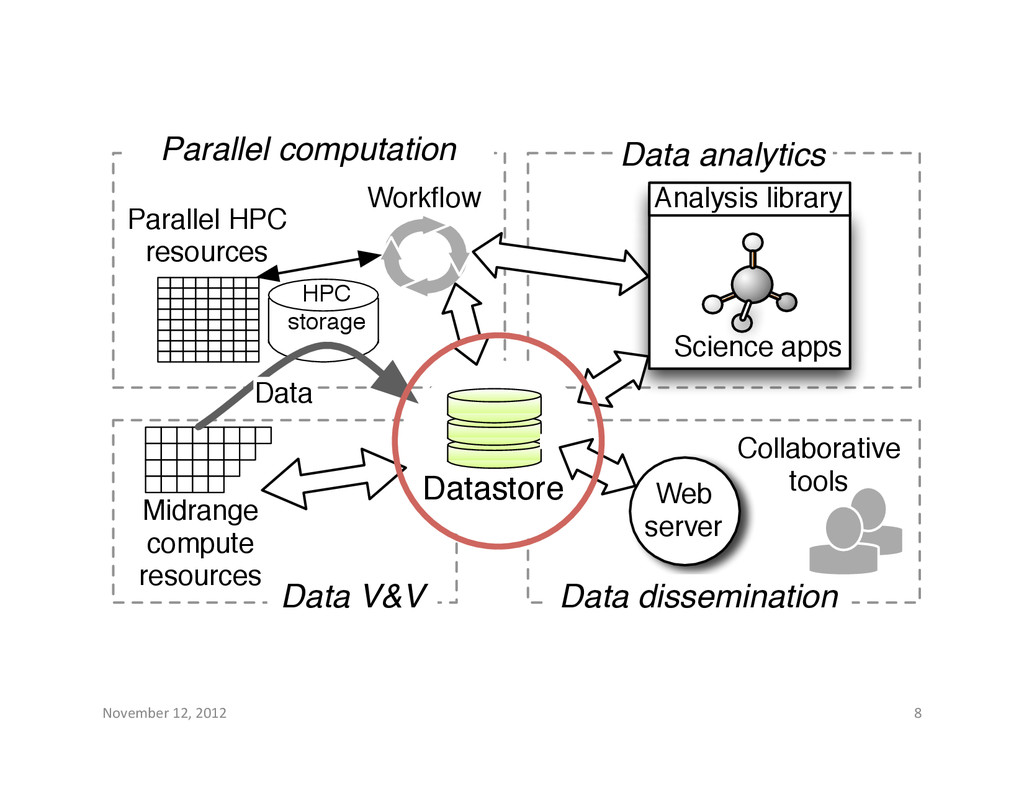
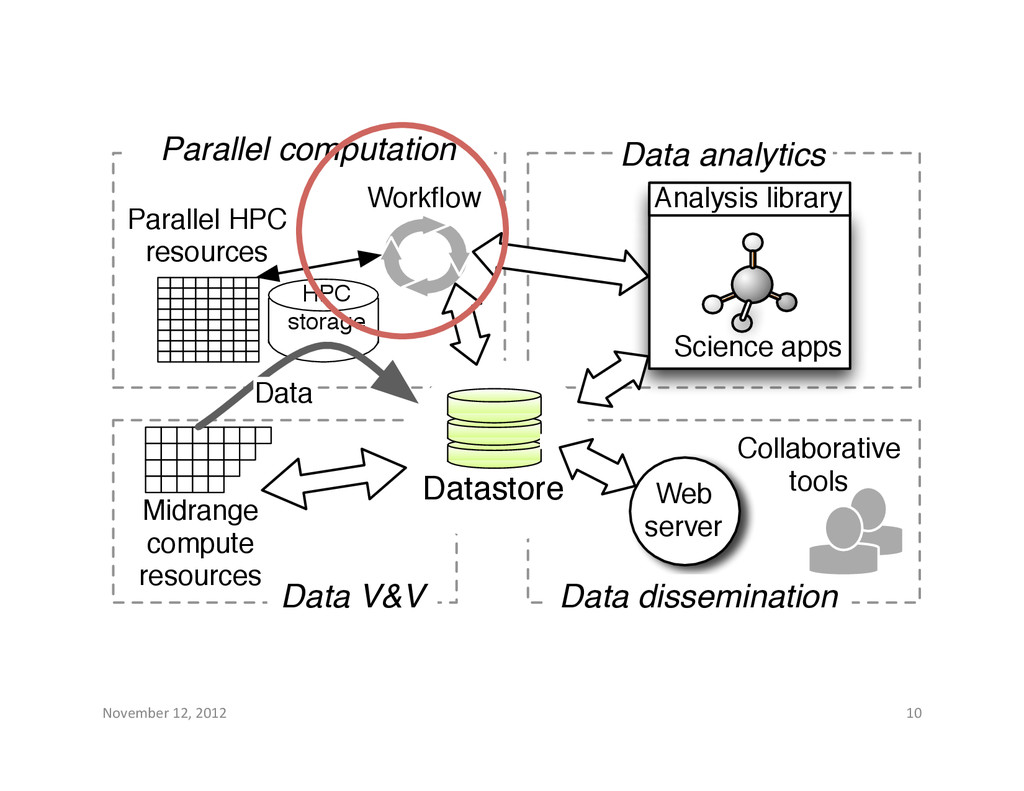
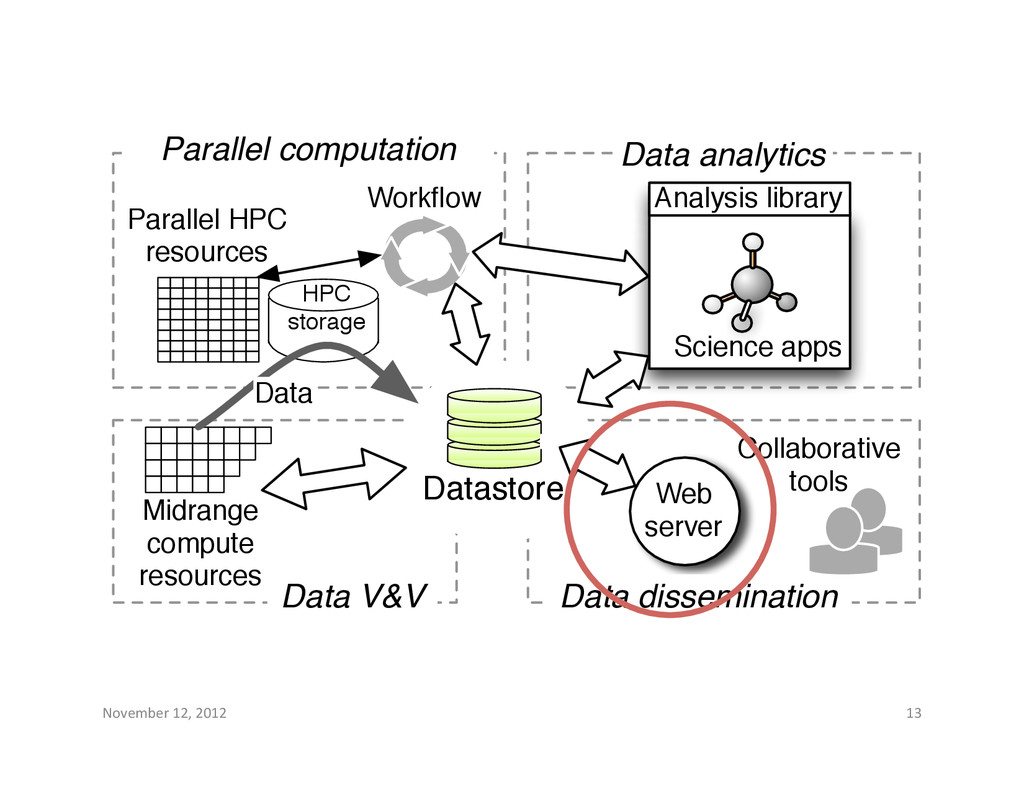
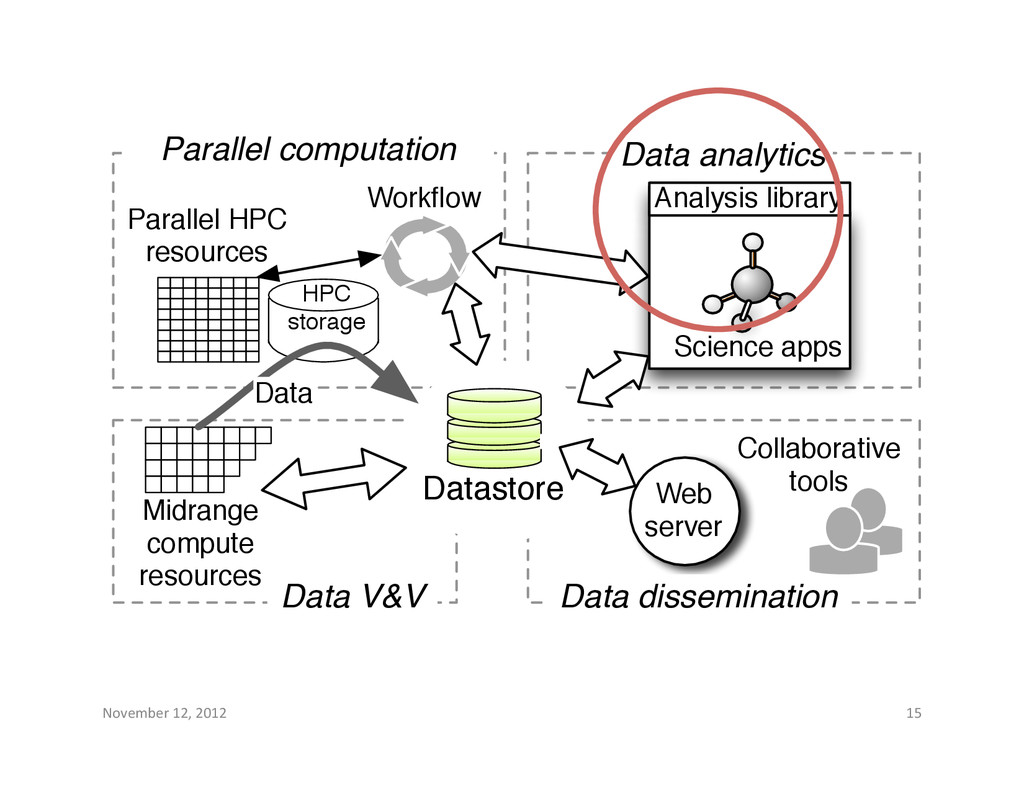
resources Datastore Data dissemination Collaborative tools Web server Analysis library Science apps Data V&V Midrange compute resources Workflow HPC storage Data Data analytics
simple query language Ease of administration Good performance on read-heavy workloads where most of the data can fit into memory. Poor performance at huge scale Bad for write-heavy workloads
resources Datastore Data dissemination Collaborative tools Web server Analysis library Science apps Data V&V Midrange compute resources Workflow HPC storage Data Data analytics
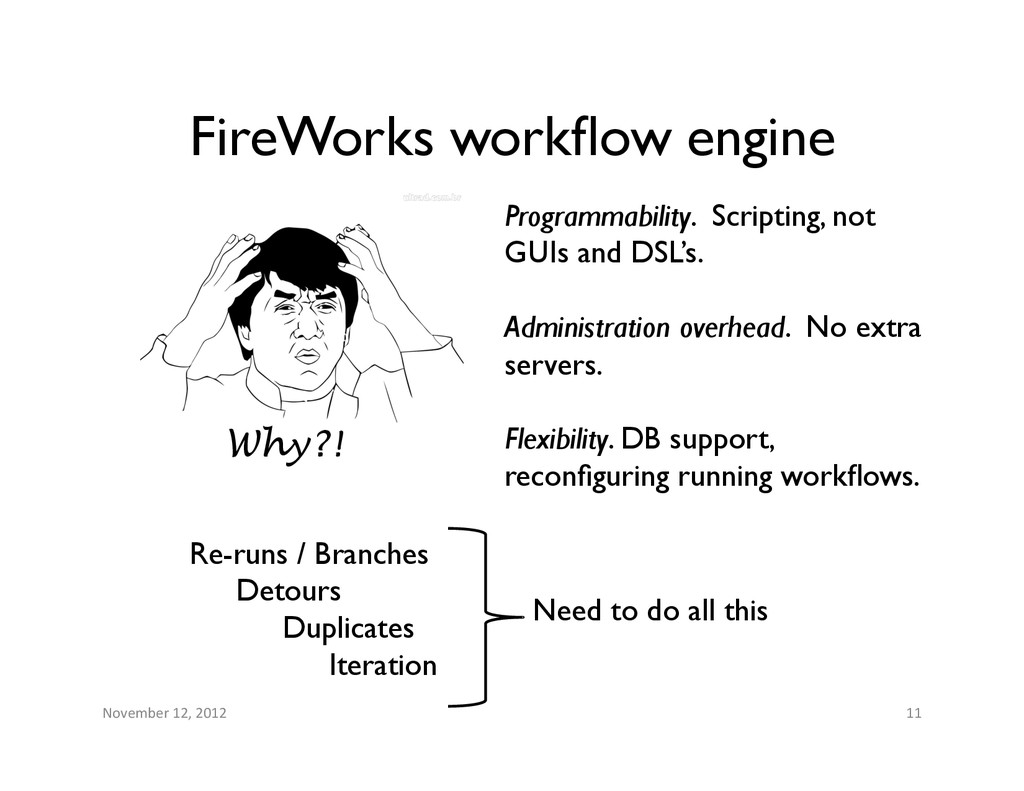
Scripting, not GUIs and DSL’s. Administration overhead. No extra servers. Flexibility. DB support, reconfiguring running workflows. Re-runs / Branches Detours Duplicates Iteration Why?! Need to do all this
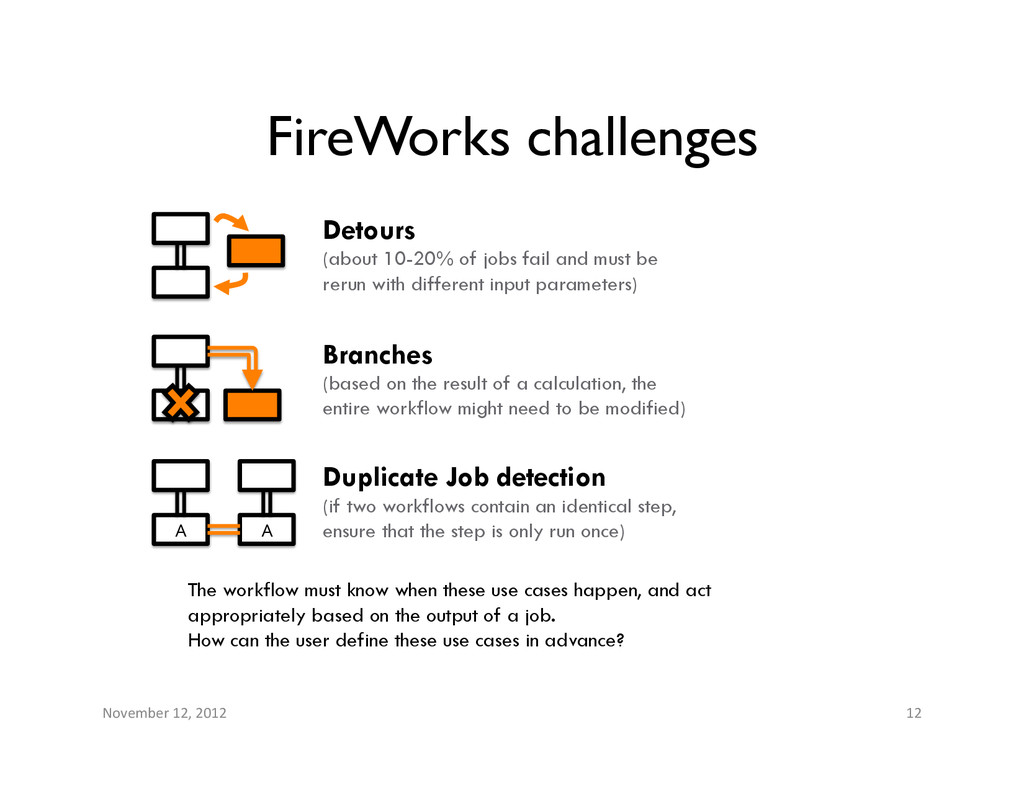
Detours (about 10-20% of jobs fail and must be rerun with different input parameters) Branches (based on the result of a calculation, the entire workflow might need to be modified) Duplicate Job detection (if two workflows contain an identical step, ensure that the step is only run once) The workflow must know when these use cases happen, and act appropriately based on the output of a job. How can the user define these use cases in advance?
resources Datastore Data dissemination Collaborative tools Web server Analysis library Science apps Data V&V Midrange compute resources Workflow HPC storage Data Data analytics
of unit cell Disqus comment button Detailed structure X-ray diffraction pattern (interactive) Bandstructure and Density of states (interactive) Calculation iterations Comments
resources Datastore Data dissemination Collaborative tools Web server Analysis library Science apps Data V&V Midrange compute resources Workflow HPC storage Data Data analytics
best of circumstances – this ain't the best of circumstances • Scaling analytic functions – "learning" which compounds are stable – need to get data to appropriate programming model (MapReduce, Parallel R, ..) November 12, 2012 20
– No dedicated resources for this – Automation a must • Constant validation and verification – (see above) – MapReduce – Ticket/bug system November 12, 2012 21
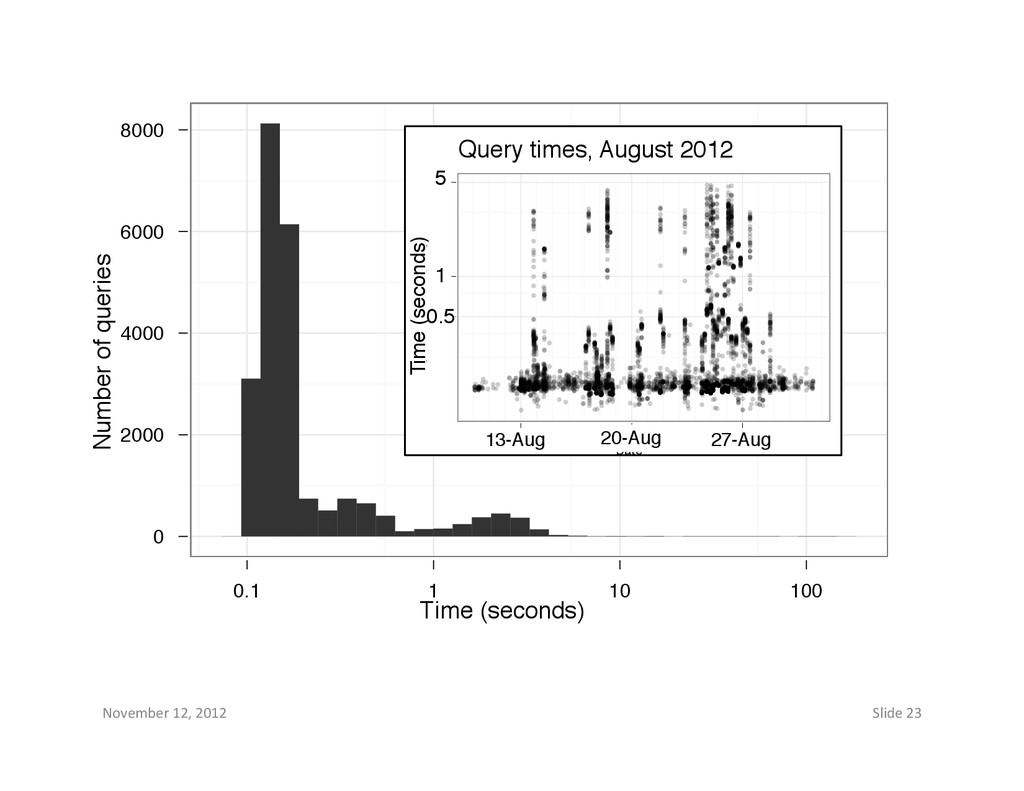
– Sharing model for data ("sandboxes") – Shouldn't this build on broader practices? • (A: yes, but how to do this and get something done) • Query performance – see next slide November 12, 2012 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}