piece of the puzzle • Impala: Goals, non-goals and features • Demo • Q+A • Part 2: • Impala Internals • Comparing Impala to other systems • Q+A Wednesday, 16 January 2013
system • Ideally suited to long-running, high-latency data processing workloads • But not as suitable for interactive queries, data exploration or iterative query refinement • All of which are keystones of data warehousing 5 Wednesday, 16 January 2013
storage cheap and flexible • SQL / ODBC are industry-standards • Analyst familiarity • BI tool integration • Legacy systems 6 Wednesday, 16 January 2013
storage cheap and flexible • SQL / ODBC are industry-standards • Analyst familiarity • BI tool integration • Legacy systems • Can we get the advantages of both? • With acceptable performance? 6 Wednesday, 16 January 2013
work both for analytical and transactional workloads • will support queries that take from milliseconds to hours • Runs directly within Hadoop: • Reads widely-used Hadoop file formats • talks to widely used Hadoop storage managers like HDFS and HBase • runs on same nodes that run Hadoop processes 7 Wednesday, 16 January 2013
work both for analytical and transactional workloads • will support queries that take from milliseconds to hours • Runs directly within Hadoop: • Reads widely-used Hadoop file formats • talks to widely used Hadoop storage managers like HDFS and HBase • runs on same nodes that run Hadoop processes • High performance • C++ instead of Java • runtime code generation via LLVM • completely new execution engine that doesn’t build on MapReduce 7 Wednesday, 16 January 2013
in cluster: one Impala daemon on each node with data • User submits query via ODBC/Beeswax Thrift API to any daemon • Query is distributed to all nodes with relevant data 8 Wednesday, 16 January 2013
in cluster: one Impala daemon on each node with data • User submits query via ODBC/Beeswax Thrift API to any daemon • Query is distributed to all nodes with relevant data • If any node fails, the query fails 8 Wednesday, 16 January 2013
in cluster: one Impala daemon on each node with data • User submits query via ODBC/Beeswax Thrift API to any daemon • Query is distributed to all nodes with relevant data • If any node fails, the query fails • Impala uses Hive’s metadata interface 8 Wednesday, 16 January 2013
in cluster: one Impala daemon on each node with data • User submits query via ODBC/Beeswax Thrift API to any daemon • Query is distributed to all nodes with relevant data • If any node fails, the query fails • Impala uses Hive’s metadata interface • Supported file formats: • text files (GA: with compression, including lzo) • sequence files with snappy / gzip compression • GA: Avro data files / columnar format (more on this later) 8 Wednesday, 16 January 2013
after Hive’s version of SQL • limited to Select, Project, Join, Union, Subqueries, Aggregation and Insert • only equi-joins, no non-equi-joins, no cross products • ORDER BY only with LIMIT • GA: DDL support (CREATE, ALTER) 9 Wednesday, 16 January 2013
after Hive’s version of SQL • limited to Select, Project, Join, Union, Subqueries, Aggregation and Insert • only equi-joins, no non-equi-joins, no cross products • ORDER BY only with LIMIT • GA: DDL support (CREATE, ALTER) • Functional Limitations • no custom UDFs, file formats, Hive SerDes • only hash joins: joined table has to fit in memory of a single node (beta) / aggregate memory of all executing nodes (GA) • join order = FROM clause order 9 Wednesday, 16 January 2013
Hive’s mapping of HBase table into metastore table • predicates on rowkey columns are mapped into start / stop row • predicates on other columns are mapped into SingleColumnValueFilters 10 Wednesday, 16 January 2013
Hive’s mapping of HBase table into metastore table • predicates on rowkey columns are mapped into start / stop row • predicates on other columns are mapped into SingleColumnValueFilters • HBase functional limitations • no nested-loop joins • all data stored as text 10 Wednesday, 16 January 2013
decision support systems • We generated 500MB data (not a lot, but enough to be illustrative!) • Let’s run a sample query against Hive 0.9, and against Impala 0.3 12 Wednesday, 16 January 2013
decision support systems • We generated 500MB data (not a lot, but enough to be illustrative!) • Let’s run a sample query against Hive 0.9, and against Impala 0.3 • Single node (VM! - caveat emptor), so we’re testing execution engine speeds 12 Wednesday, 16 January 2013
avg(ss_coupon_amt) agg3, avg(ss_sales_price) agg4 FROM store_sales JOIN date_dim on (store_sales.ss_sold_date_sk = date_dim.d_date_sk) JOIN item on (store_sales.ss_item_sk = item.i_item_sk) JOIN customer_demographics on (store_sales.ss_cdemo_sk = customer_demographics.cd_demo_sk) JOIN store on (store_sales.ss_store_sk = store.s_store_sk) where cd_gender = 'M' and cd_marital_status = 'S' and cd_education_status = 'College' and d_year = 2002 and s_state in ('TN','SD', 'SD', 'SD', 'SD', 'SD') group by i_item_id, s_state order by i_item_id, s_state limit 100; 13 Wednesday, 16 January 2013
intermediate data - less I/O • No multi-phase queries - much smaller startup / teardown overhead • Faster execution engine: generates fast code for each individual query 14 Wednesday, 16 January 2013
daemon (impalad) • handles client requests and all internal requests related to query execution over Thrift • runs on every datanode 16 Wednesday, 16 January 2013
daemon (impalad) • handles client requests and all internal requests related to query execution over Thrift • runs on every datanode • Statestore daemon (statestored) • provides membership information and metadata distribution • only one per cluster 16 Wednesday, 16 January 2013
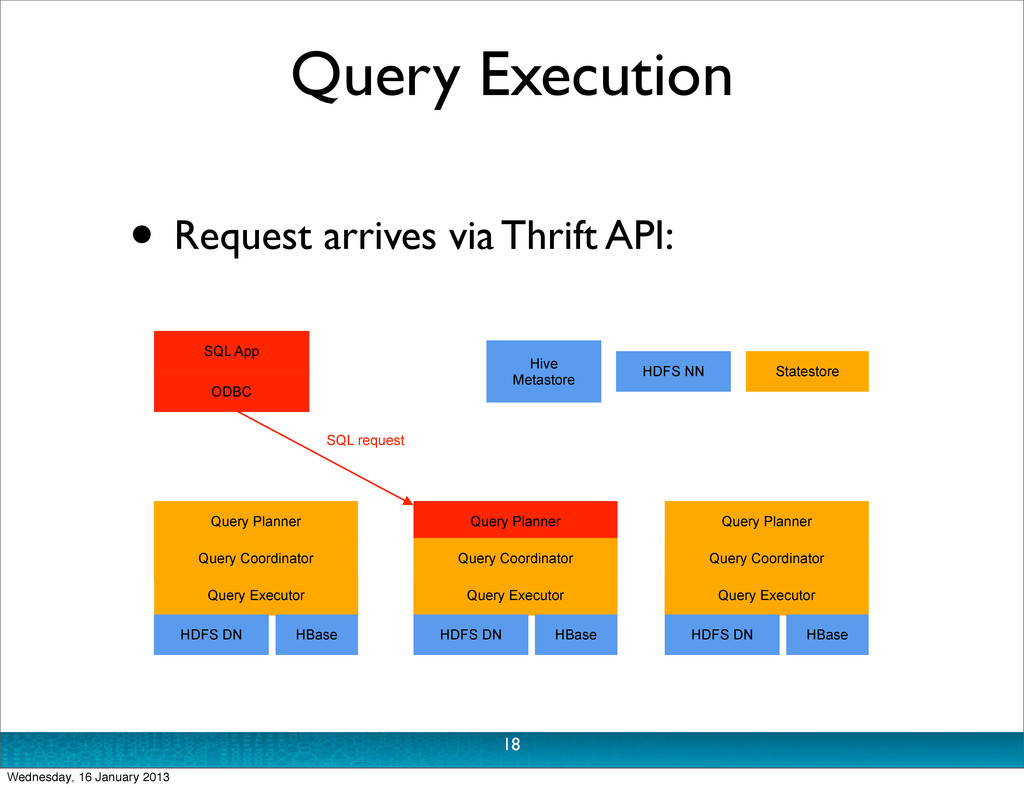
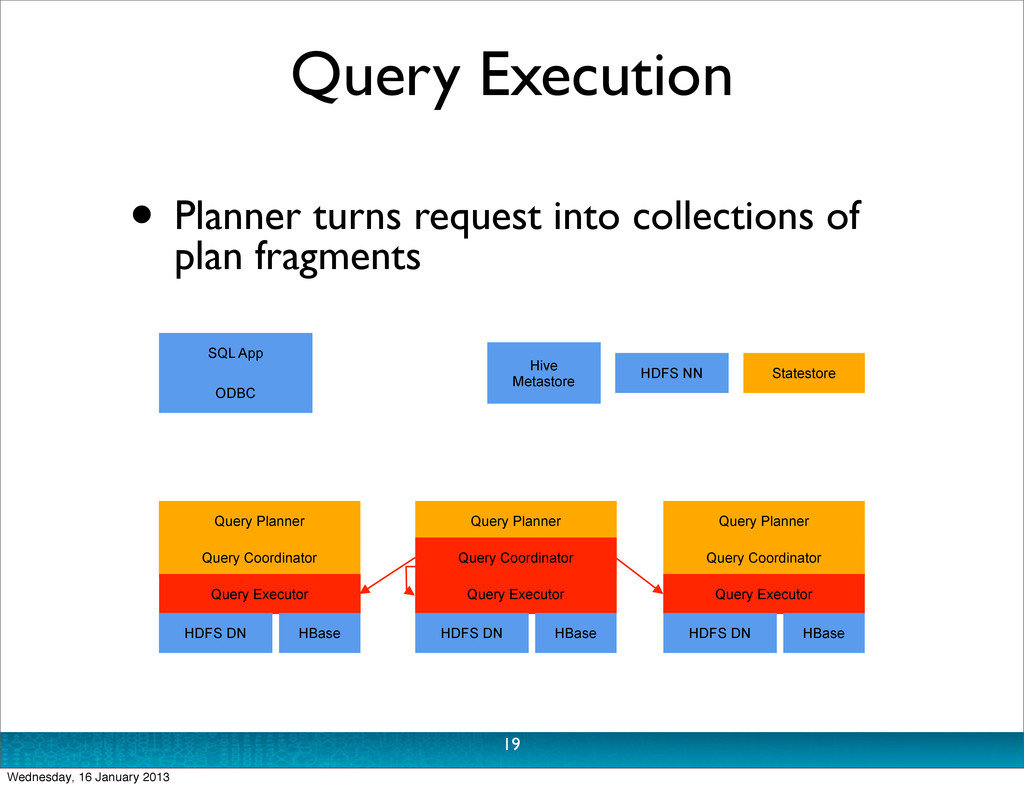
Thrift API (perhaps from ODBC, or shell) • Planner turns request into collections of plan fragments • ‘Coordinator’ initiates execution on remote impalad daemons 17 Wednesday, 16 January 2013
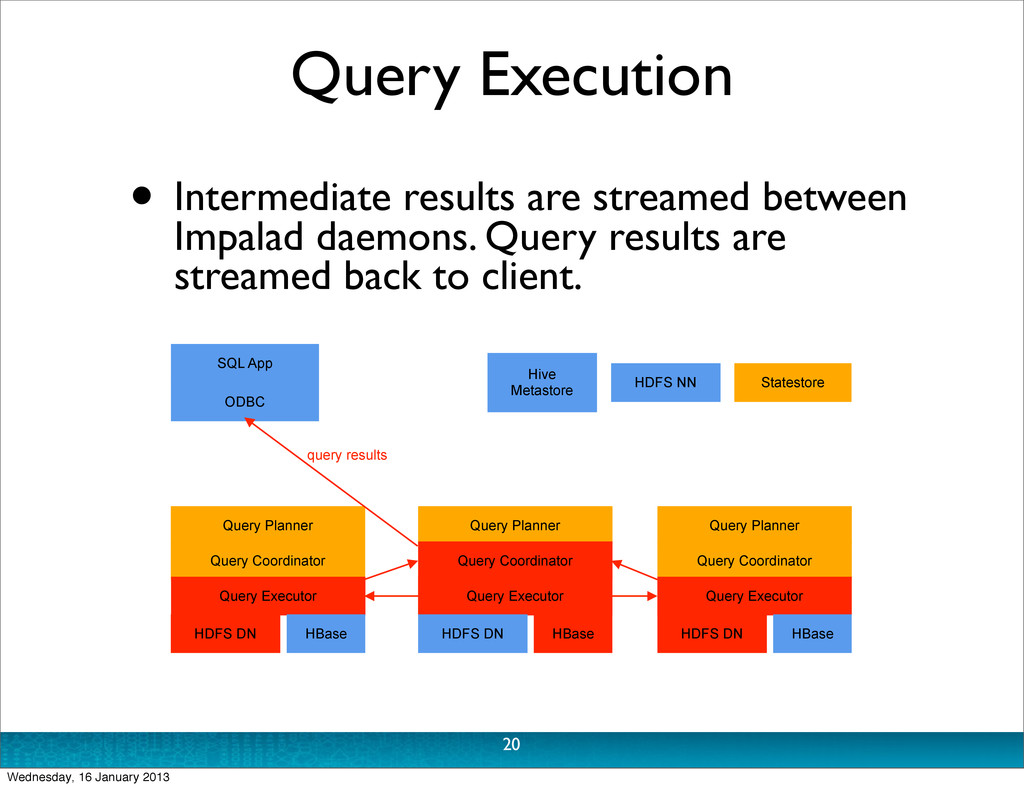
Thrift API (perhaps from ODBC, or shell) • Planner turns request into collections of plan fragments • ‘Coordinator’ initiates execution on remote impalad daemons • During execution: • Intermediate results are streamed between impalad daemons • Query results are streamed to client 17 Wednesday, 16 January 2013
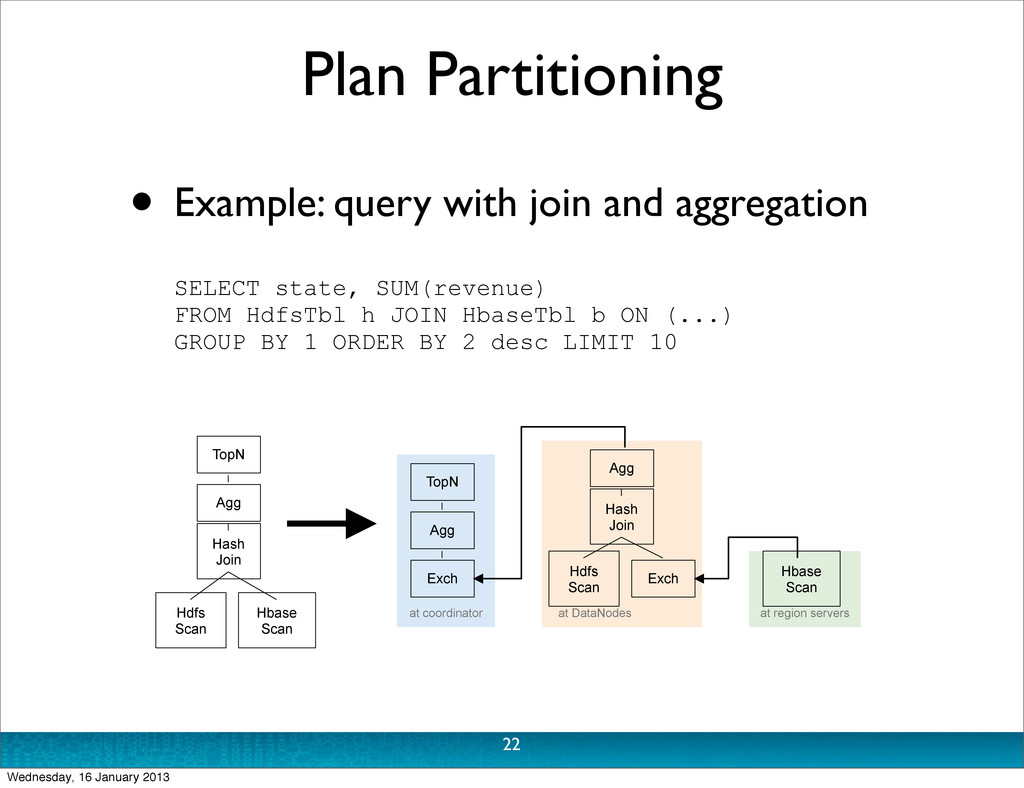
tree of plan operators • plan partitioning: partition single-node plan to maximise scan locality, minimise data movement • Plan operators: Scan, HashJoin, HashAggregation, Union, TopN, Exchange 21 Wednesday, 16 January 2013
tree of plan operators • plan partitioning: partition single-node plan to maximise scan locality, minimise data movement • Plan operators: Scan, HashJoin, HashAggregation, Union, TopN, Exchange • Distributed aggregation: pre-aggregate in individual nodes, merge aggregation at root 21 Wednesday, 16 January 2013
tree of plan operators • plan partitioning: partition single-node plan to maximise scan locality, minimise data movement • Plan operators: Scan, HashJoin, HashAggregation, Union, TopN, Exchange • Distributed aggregation: pre-aggregate in individual nodes, merge aggregation at root • GA: rudimentary cost-based optimiser 21 Wednesday, 16 January 2013
state, SUM(revenue) FROM HdfsTbl h JOIN HbaseTbl b ON (...) GROUP BY 1 ORDER BY 2 desc LIMIT 10 Hbase Scan Hash Join Hdfs Scan Exch TopN Agg Exch at coordinator at DataNodes at region servers Agg TopN Agg Hash Join Hdfs Scan Hbase Scan 22 Wednesday, 16 January 2013
Caches metadata between queries: no synchronous metastore API calls during query execution • Beta: Changes in metadata require manual refresh • GA: Metadata distributed through statestore 23 Wednesday, 16 January 2013
in C++ • runtime code generation for “big- loops” • Internal in-memory tuple format puts fixed-width data at fixed offsets • Hand-optimised assembly where needed 24 Wednesday, 16 January 2013
a hash- table • We know ahead of time the maximum number of tuples (in a batch), the tuple layout, what fields might be null and so on. • Pre-bake all this information into an unrolled loop that avoids branches and dead code • Function calls are inlined at compile- time 25 Wednesday, 16 January 2013
a hash- table • We know ahead of time the maximum number of tuples (in a batch), the tuple layout, what fields might be null and so on. • Pre-bake all this information into an unrolled loop that avoids branches and dead code • Function calls are inlined at compile- time • Result: significant speedup in real queries 25 Wednesday, 16 January 2013
• GA: metadata • GA: diagnostics, scheduling information • Soft-state • All data can be reconstructed from the rest of the system • Impala continues to run when statestore fails, but per-node state becomes increasingly stale 26 Wednesday, 16 January 2013
• GA: metadata • GA: diagnostics, scheduling information • Soft-state • All data can be reconstructed from the rest of the system • Impala continues to run when statestore fails, but per-node state becomes increasingly stale • Sends periodic heartbeats • Pushes new data • Checks for liveness 26 Wednesday, 16 January 2013
publish- subscribe system • API is awkward, and requires a lot of client logic • Multiple round-trips required to get data for changes to node’s children • Push model is more natural for our use case 27 Wednesday, 16 January 2013
publish- subscribe system • API is awkward, and requires a lot of client logic • Multiple round-trips required to get data for changes to node’s children • Push model is more natural for our use case • Don’t need all the guarantees ZK provides • Serializability • Persistence • Avoid complexity where possible! 27 Wednesday, 16 January 2013
publish- subscribe system • API is awkward, and requires a lot of client logic • Multiple round-trips required to get data for changes to node’s children • Push model is more natural for our use case • Don’t need all the guarantees ZK provides • Serializability • Persistence • Avoid complexity where possible! • ZK is bad at the things we care about, and good at the things we don’t 27 Wednesday, 16 January 2013
for data with nested structures • Distributed scalable aggregation on top of that • Columnar storage coming to Hadoop via joint project between Cloudera and Twitter 28 Wednesday, 16 January 2013
for data with nested structures • Distributed scalable aggregation on top of that • Columnar storage coming to Hadoop via joint project between Cloudera and Twitter • Impala plus columnar format: a superset of the published version of Dremel (which had no joins) 28 Wednesday, 16 January 2013
engine • High latency, low throughput queries • Fault-tolerance based on MapReduce’s on- disk checkpointing: materialises all intermediate results • Java runtime allows for extensibility: file formats and UDFs 29 Wednesday, 16 January 2013
engine • High latency, low throughput queries • Fault-tolerance based on MapReduce’s on- disk checkpointing: materialises all intermediate results • Java runtime allows for extensibility: file formats and UDFs • Impala: • Direct, process-to-process data exchange • No fault tolerance • Designed for low runtime overhead • Not nearly as extensible 29 Wednesday, 16 January 2013
from the development process: • Impala can get full disk throughput, I/O- bound workloads faster by 3-4x. • Multiple phase Hive queries see larger speedup in Impala • Queries against in-memory data can be up to 100x faster 30 Wednesday, 16 January 2013
• New data formats • LZO-compressed text • Avro • Columnar format • Better metadata handling through statestore • JDBC support 31 Wednesday, 16 January 2013
• New data formats • LZO-compressed text • Avro • Columnar format • Better metadata handling through statestore • JDBC support • Improved query execution, e.g. partitioned joins 31 Wednesday, 16 January 2013
• New data formats • LZO-compressed text • Avro • Columnar format • Better metadata handling through statestore • JDBC support • Improved query execution, e.g. partitioned joins • Production deployment guidelines • Load-balancing across Impalad daemons • Resource isolation within Hadoop cluster 31 Wednesday, 16 January 2013
• New data formats • LZO-compressed text • Avro • Columnar format • Better metadata handling through statestore • JDBC support • Improved query execution, e.g. partitioned joins • Production deployment guidelines • Load-balancing across Impalad daemons • Resource isolation within Hadoop cluster • More packages: RHEL 5.7, Ubuntu, Debian 31 Wednesday, 16 January 2013
HBase support • Composite keys, Avro data in columns • Indexed nested-loop joins • INSERT / UPDATE / DELETE • Additional SQL • UDFs • SQL authorisation and DDL • ORDER BY without LIMIT • Window functions • Support for structured data types 32 Wednesday, 16 January 2013
HBase support • Composite keys, Avro data in columns • Indexed nested-loop joins • INSERT / UPDATE / DELETE • Additional SQL • UDFs • SQL authorisation and DDL • ORDER BY without LIMIT • Window functions • Support for structured data types • Runtime optimisations • Straggler handling • Join order optimisation • Improved cache management • Data co-location for improved join performance 32 Wednesday, 16 January 2013
“User X can never have more than 5 concurrent queries running” • Goal: run exploratory and production workloads in same cluster without affecting production jobs 33 Wednesday, 16 January 2013
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Questions? @henryr / [email protected] Wednesday, 16 January 2013](https://files.speakerdeck.com/presentations/06b1b62049c40130332c123138155451/slide_102.jpg){kind=link}