class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws .....{ String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
Can PredictionIO solve this problem? A: Not at this moment. That’s why we focus on collaborative filtering algorithms right now which don’t require the use of features. And we believe that the involvement of data scientists is needed for many specific problems. PredictionIO is positioned as a tool to make their work easier, but not as a replacement. Q: How’s PredictionIO different from Weka? A: Weka, like Mahout, is a ML algorithm library. You can see PredictionIO as a layer on top of it, which helps you to implement algorithm into production environment by providing a complete infrastructure. Q: How do you compare PredictionIO with RapidMiner? A: RapidMiner is a great product to define data engineering workflow visually. PredictionIO focuses on a different problem -- i.e. deploying ML solution into production environment. Q: How does the algorithm evaluation metrics work in PredictionIO? A: At this moment, you can evaluate algorithms by some offline metrics, such as Mean Average Precision, based on your existing data. Q: What’s the business model? A: We focus on making PredictionIO a useful open source product at this moment.
![Simon Chan [email protected] Data Science London - April 24, 2013](https://files.speakerdeck.com/presentations/4863c01095380130010e5225ae2bc12a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
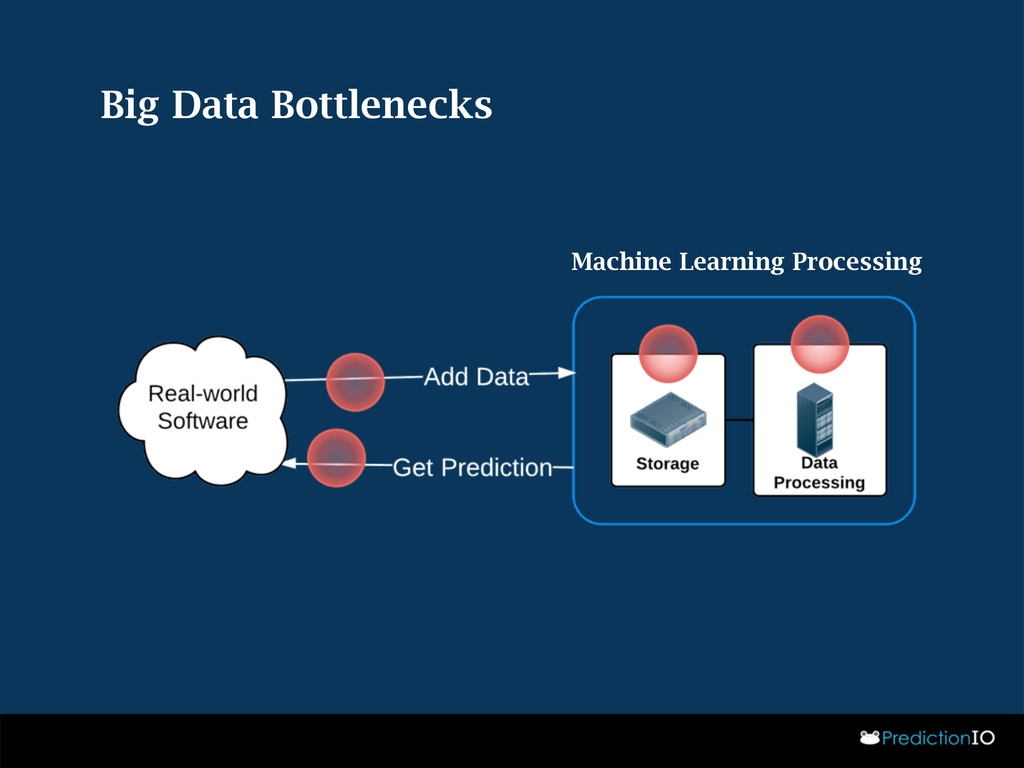{kind=link}
{kind=link}
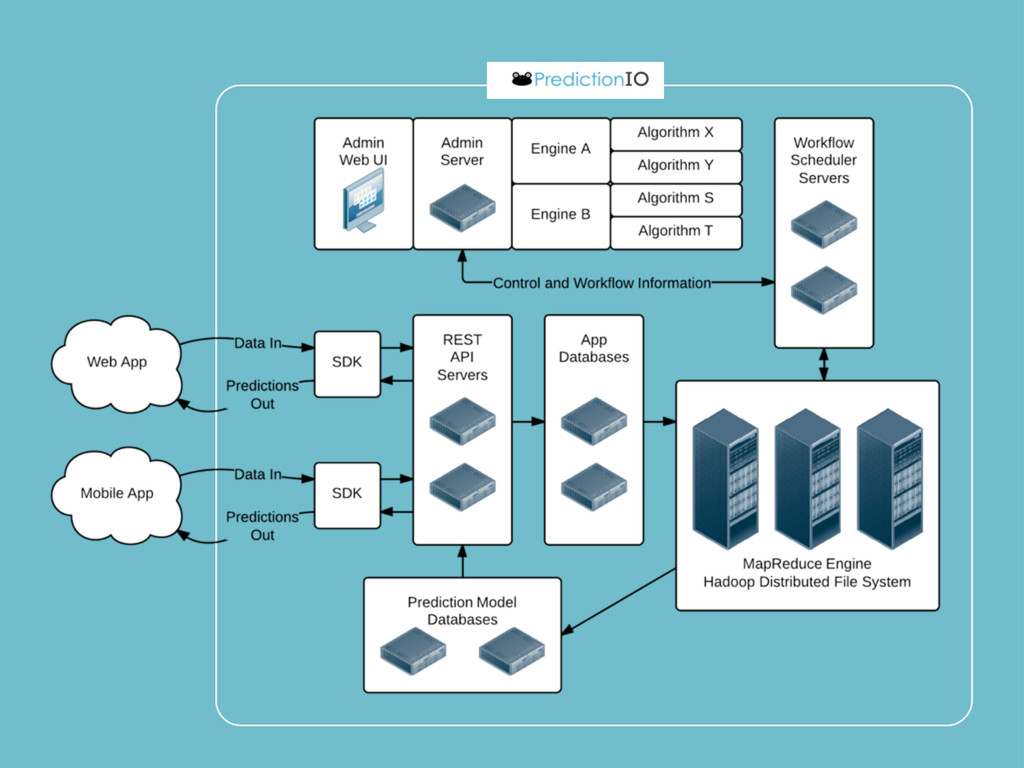{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
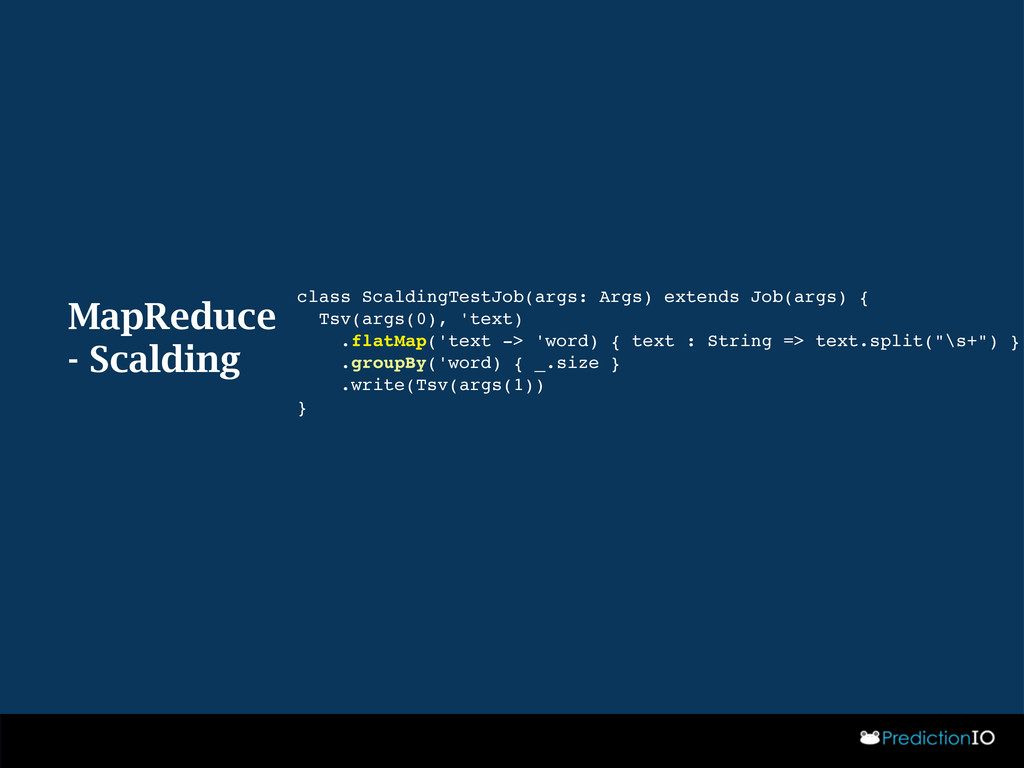{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}