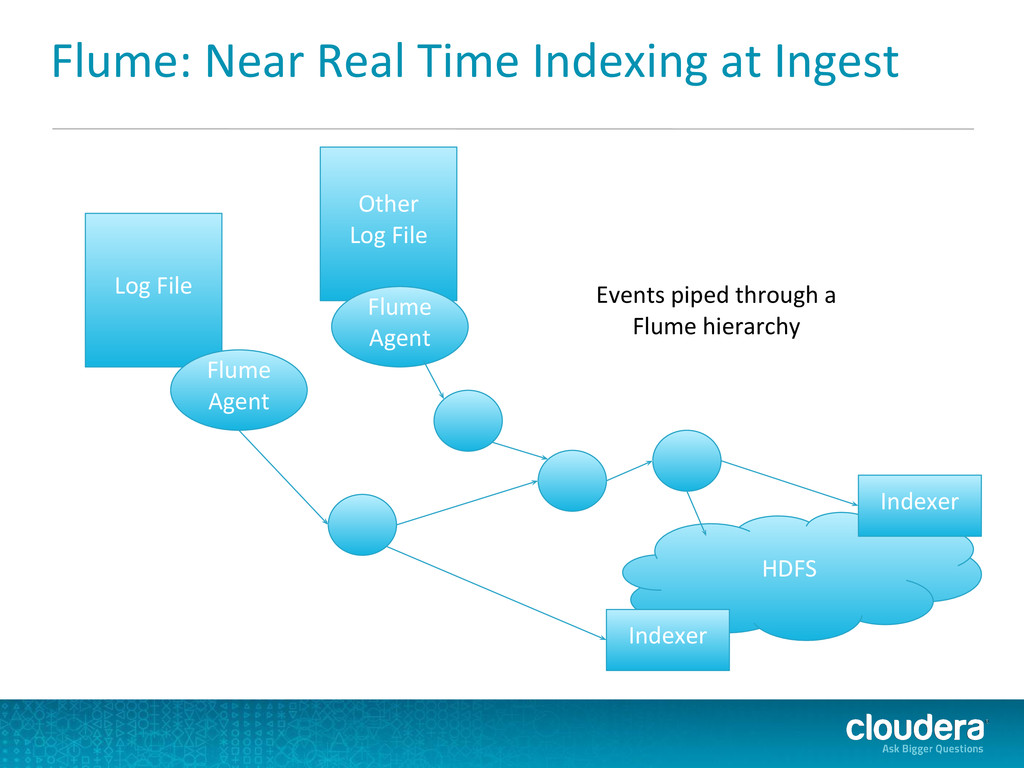
knowledge • Single data set for multiple computing frameworks Fast • Exploratory analysis, esp. unstructured data • Broad range of indexing options to accommodate needs Efficient • Single scalable platform; no incremental investment • No need for separate systems, storage Experts know MapReduce. Savvy people know SQL. Everyone knows Search.
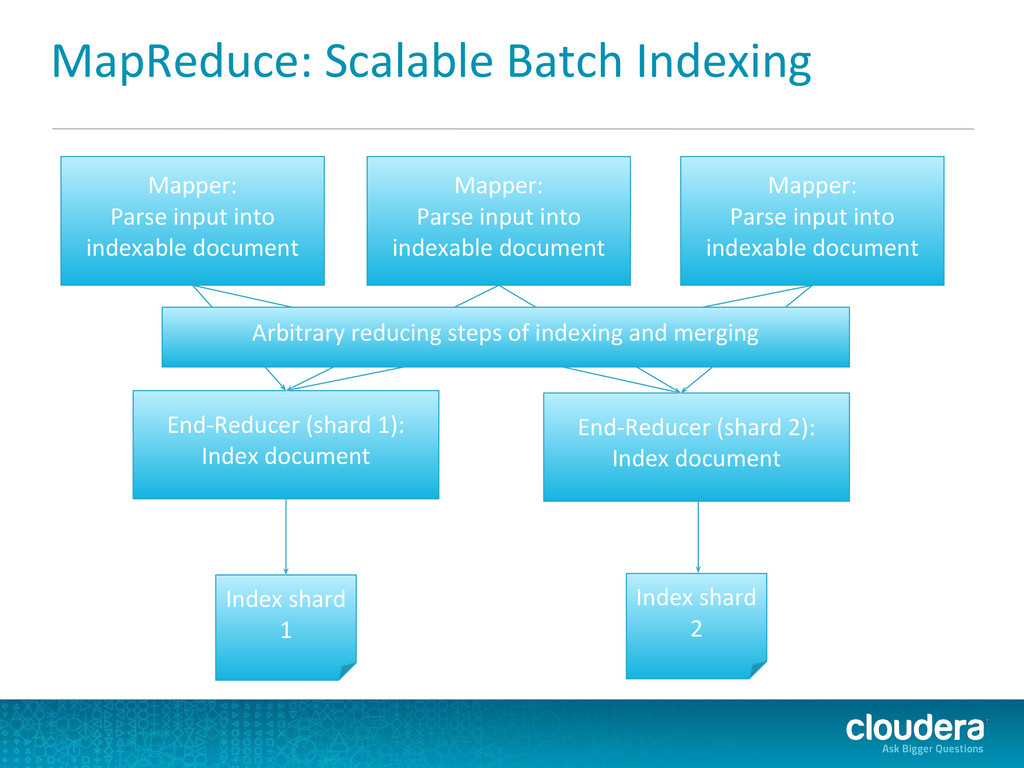
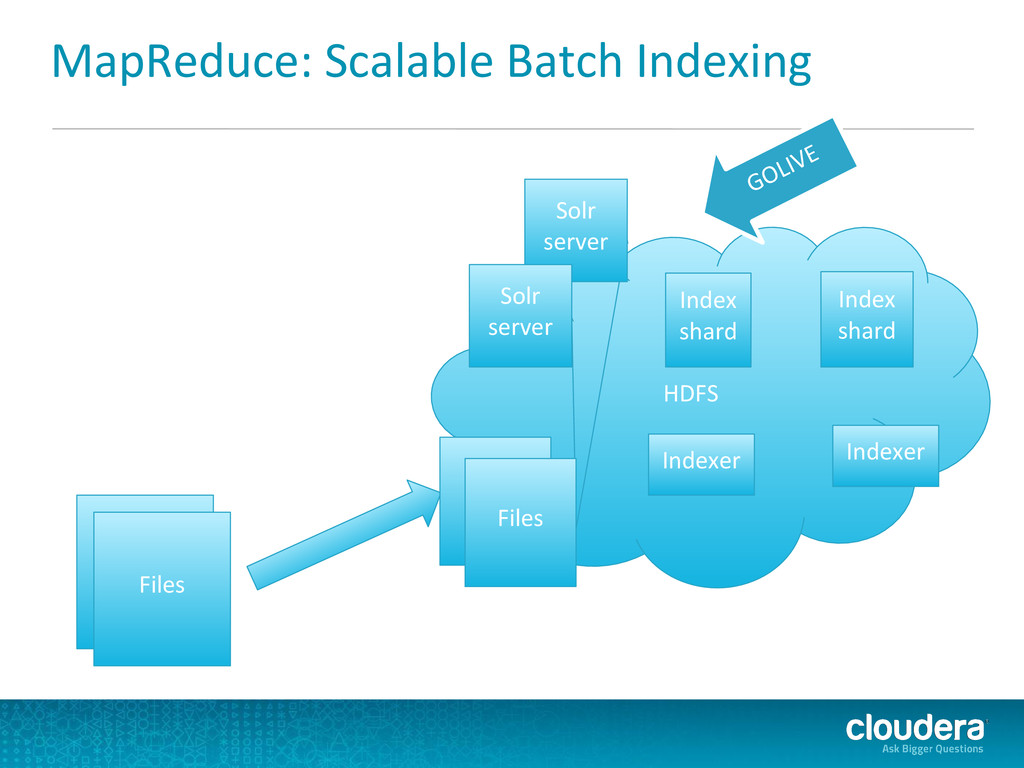
(shard 2): Index document Mapper: Parse input into indexable document Mapper: Parse input into indexable document Mapper: Parse input into indexable document Index shard 1 Index shard 2 Arbitrary reducing steps of indexing and merging
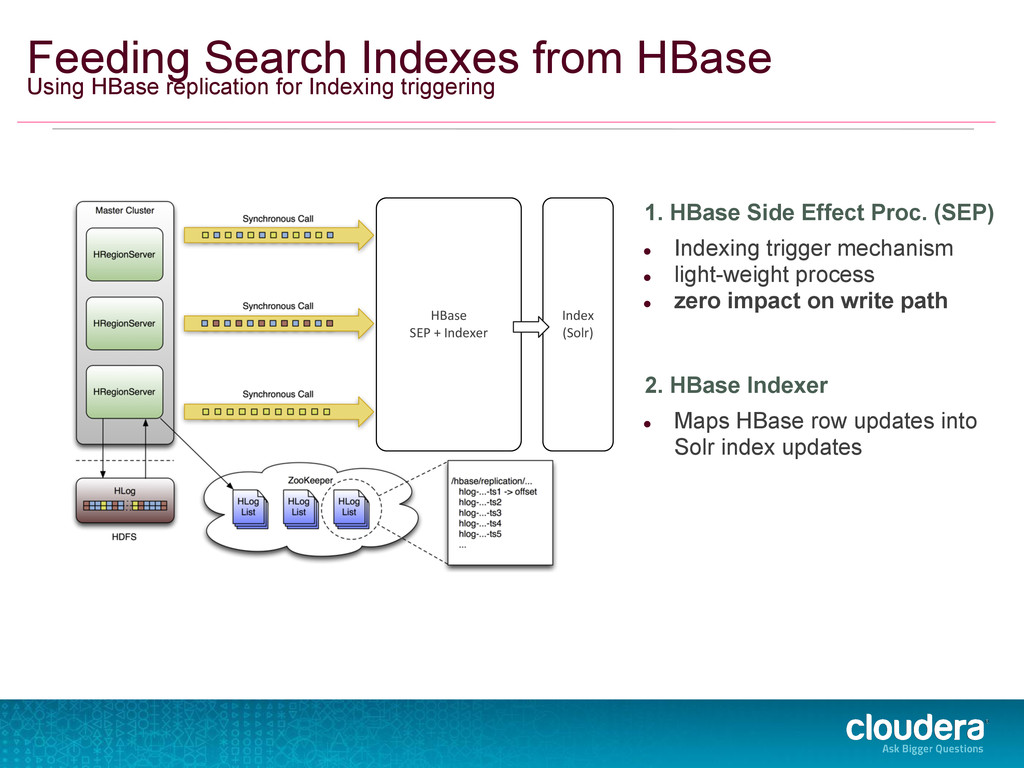
• light-weight process • zero impact on write path 2. HBase Indexer • Maps HBase row updates into Solr index updates Feeding Search Indexes from HBase Using HBase replication for Indexing triggering HBase SEP + Indexer Index (Solr)
Unified management and monitoring • Over time, more and more advanced index management and monitoring • Shard resource utilization • Rule-based re-sharding • Social and statistical relevance optimizations • And much more… Cloudera Manager: Simplified Management
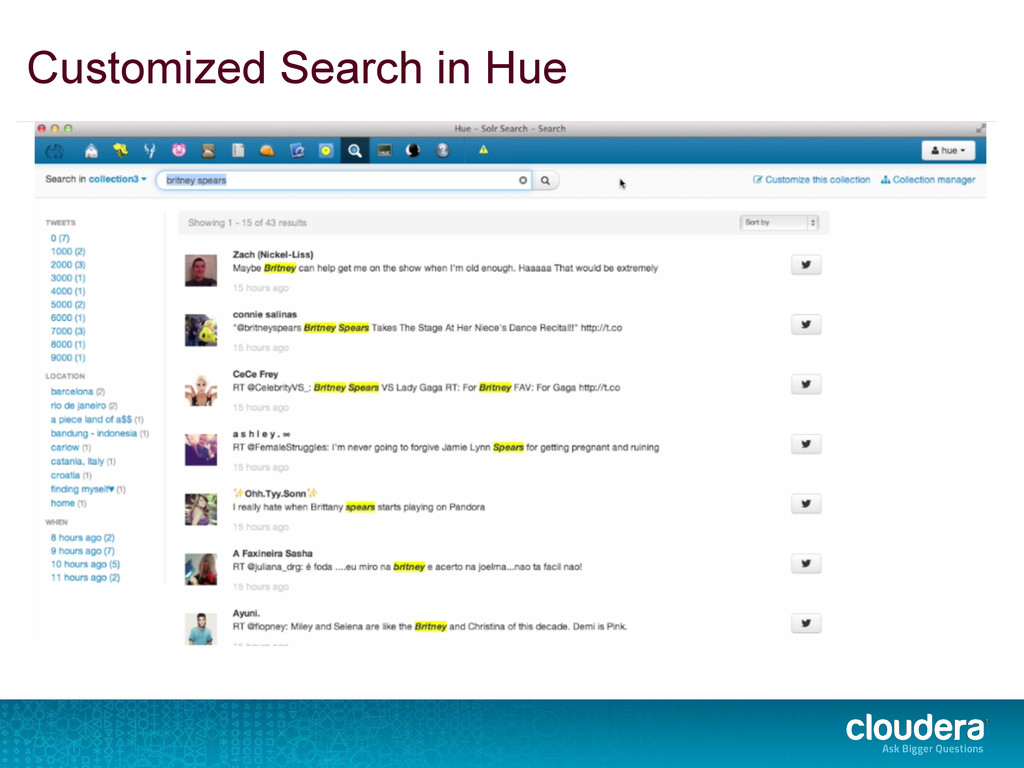
faceted navigation • Batch, near real-time, and on-demand indexing Apache Solr integrated with CDH • Established, mature search with vibrant community • Separate runtime like MapReduce, Impala • Incorporated into the Hadoop platform Open Source • Apache licensed • Standard Solr APIs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}