Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
キャディでのApache Iceberg, Trino採用事例 -Apache Iceberg...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
[email protected]
June 19, 2025
Technology
660
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
キャディでのApache Iceberg, Trino採用事例 -Apache Iceberg and Trino Usecase in CADDi--
2025年6月18日に開催されたIceberg Japan Metup# 2でエンジニアの前多が発表した資料です
[email protected]
June 19, 2025
More Decks by
[email protected]
See All by
[email protected]
製造業にRAGを導入する開発体制の変遷 / ManuAI1
caddi_eng
1
110
バラバラな見積明細と戦う話 / ManuAI2
caddi_eng
0
110
LLMに図面は読めるか – 製造業の「暗黙知」を突破するコンテキスト設計3つのアプローチ / LLMcontext
caddi_eng
1
220
「定型」を許さない製造業データへの挑戦 高度な絞り込みと意味検索を両立する実践 / ElasticON
caddi_eng
0
270
製造業ドメインにおける LLMプロダクト構築: 複雑な文脈へのアプローチ
caddi_eng
1
800
事業状況で変化する最適解。進化し続ける開発組織とアーキテクチャ
caddi_eng
1
17k
製造業の会計システムをDDDで開発した話
caddi_eng
3
2.4k
【CADDI VIETNAM】Company Deck for Engineers
caddi_eng
0
2.3k
CADDi Company Deck_Global.pdf
caddi_eng
1
800
Other Decks in Technology
See All in Technology
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
150
20260720_クラウド女子会×PyLadiesTokyoコラボ Amazon Bedrock ハンズオン用資料
yuuka51
2
110
キャリアLT会#3
beli68
2
250
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
170
システム監視入門
grimoh
1
190
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
640
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.6k
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
250
そのドキュメント、自動化しませんか?
yuksew
1
420
PHPで作って学ぶリアルタイム音声対話AIとWebSocket入門 by ムナカタ
munakata
0
140
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
520
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
120
Featured
See All Featured
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
How to build a perfect <img>
jonoalderson
1
5.8k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
440
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
Speed Design
sergeychernyshev
33
1.9k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Accessibility Awareness
sabderemane
1
160
Believing is Seeing
oripsolob
1
170
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
740
Transcript
© CADDi Inc. © CADDi Inc. キャディでの Apache Iceberg, Trino採⽤事例
- Apache Iceberg and Trino Usecese in CADDi - Kentaro Maeda Iceberg Japan Meetup #2 2025/06/18 1
© CADDi Inc. 2 About Me Kentaro Maeda • X:
@kencharos • Software Engineer at CADDi ◦ Java, Go, k8s, Istio, envoy • お酒と⽝
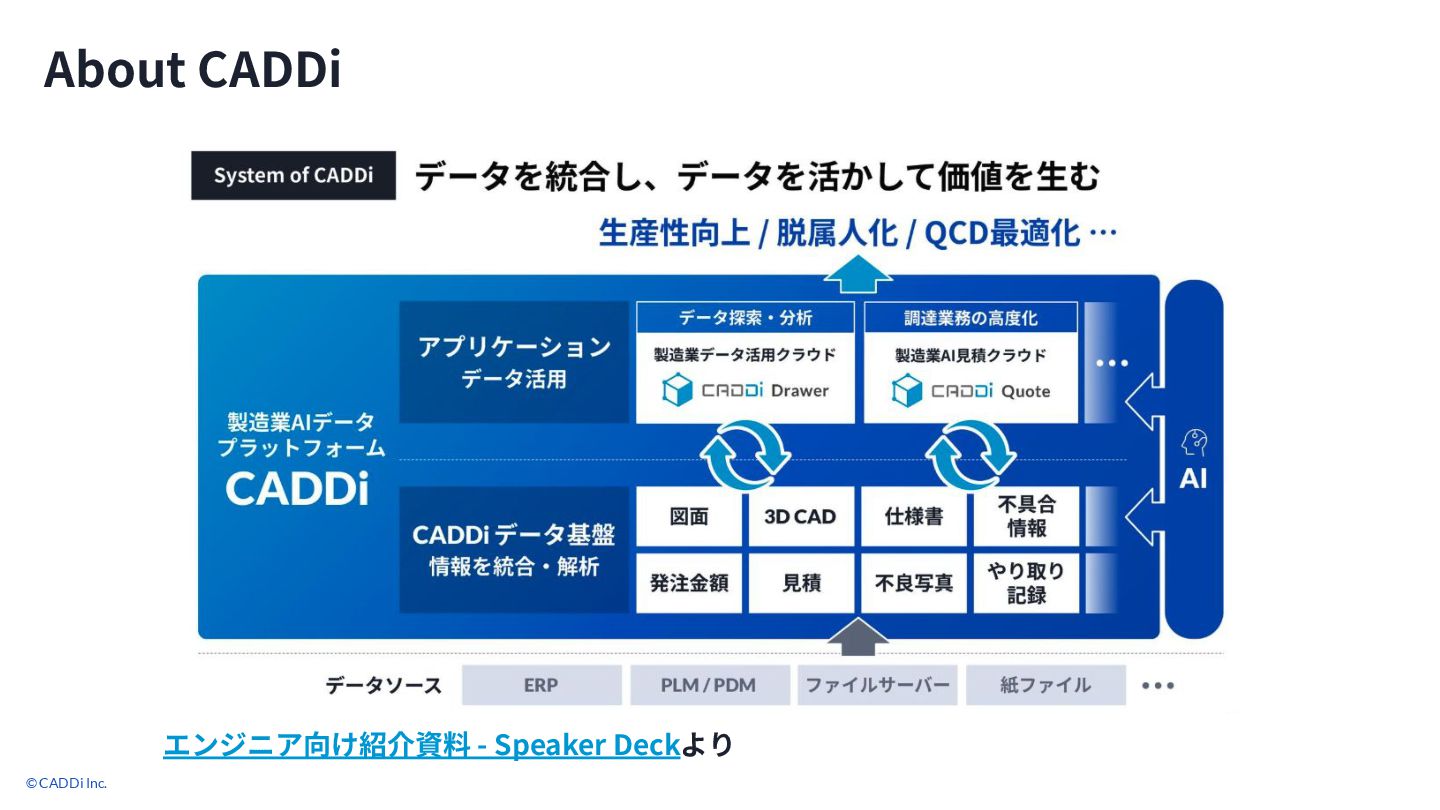
© CADDi Inc. 3 About CADDi エンジニア向け紹介資料 - Speaker Deckより
© CADDi Inc. 4 Theme 私たちは、2024年の秋からApache Iceberg, Trinoを中核としたデータ活⽤サー ビスを開発しています Apache
Iceberg, Trinoをスモールスタートで運⽤している事例についてお伝えし ます
© CADDi Inc. 5 Contents • 製造業で扱うデータの複雑さ • Apache Iceberg
と Trinoの採⽤ • 開発中の困りごととその解決策 • 今後の展望
© CADDi Inc. 6 製造業で扱うデータの複雑さ
© CADDi Inc. 製造業で扱うデータは多種多様 会社ごとに扱うデータの種類、フォーマット、サイズなどは異なる。 7 分類 具体例 構造化データ •
実績データ(見積実績、受注実績、発注実績、製造実績、検査実績、出荷実績、 請求実績、在庫実績など • マスタデータ(顧客情報、製品、仕入れ先、工程、設備情報、検査器具、チャージ など) 半構造化データ • CAD 非構造化データ • 図面 • 写真 • 文書(仕様書、マニュアル、不具合報告書、議事録など )
© CADDi Inc. データ活⽤のためには解析と関連付けが必要 • データを集めるだけで、データを検索できないのでは活⽤はできない • 検索‧分析できる状態までデータを解析して蓄積する必要がある • 蓄積したデータ同⼠を関連付けることで、企業活動を促進する
データの分析と関連付けのために、データを蓄積する基盤が必要であると考えた 8
© CADDi Inc. 9 Apache Iceberg と Trinoの採⽤
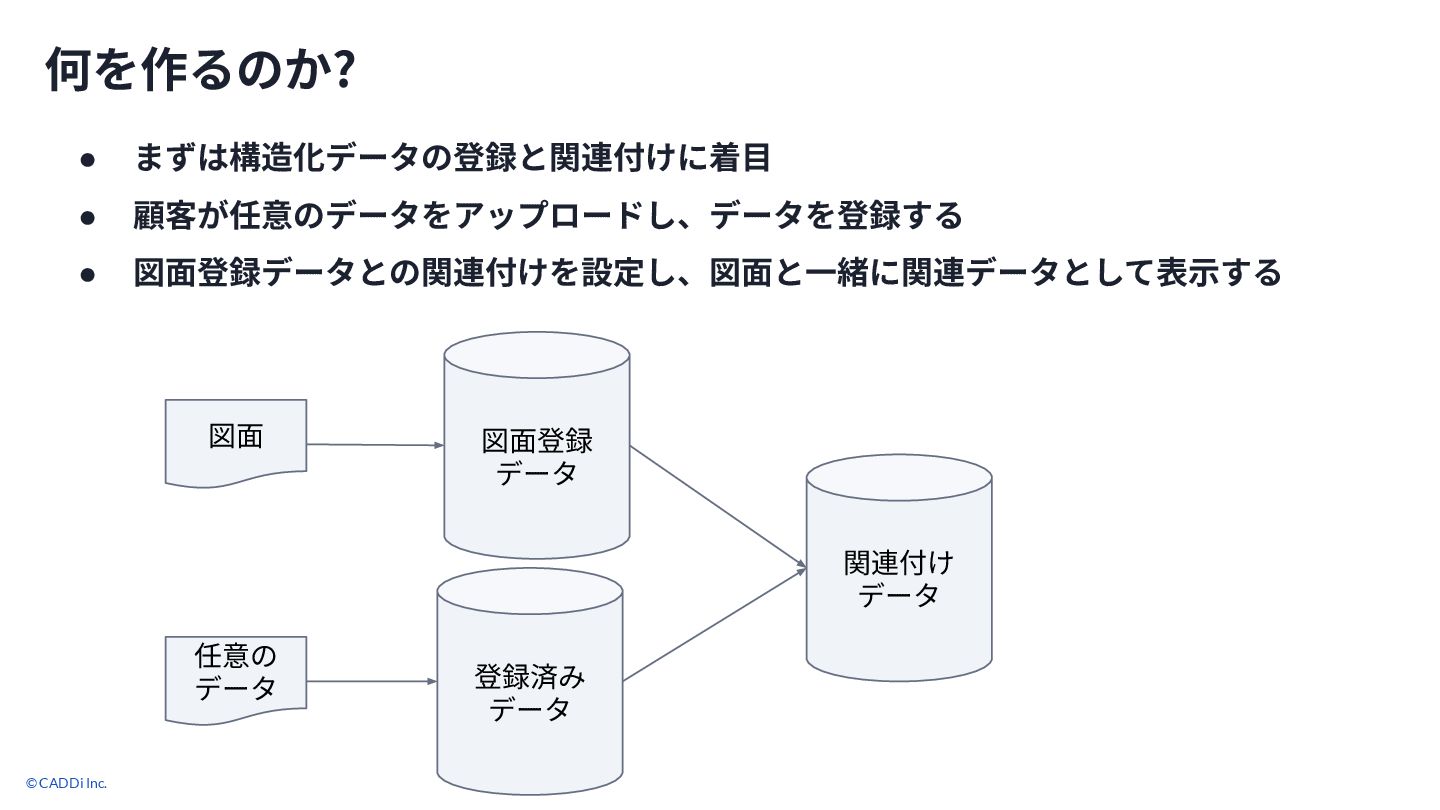
© CADDi Inc. 何を作るのか? • まずは構造化データの登録と関連付けに着⽬ • 顧客が任意のデータをアップロードし、データを登録する • 図⾯登録データとの関連付けを設定し、図⾯と⼀緒に関連データとして表⽰する
10 図⾯登録 データ 登録済み データ 図⾯ 任意の データ 関連付け データ
© CADDi Inc. Iceberg, Trinoを選んだ理由 • タイミングが良かった ◦ 開発を始めた頃にIcebergと周辺技術が成熟してきていた •
従来のデータ基盤技術と⽐較して、運⽤しやすい構成 ◦ オブジェクトストレージ+クエリエンジン、HDFSのようなストレージの運⽤が不要 • ある程度のクセはあるが、CRUDができるデータフォーマット • スケールしやすい構成 ◦ ⼤量データでなくても低コストストレージと、クエリエンジンのスケールによって コストを抑えやすい • 現在はTrinoのみだが、⽤途に応じてクエリエンジンを使い分けることができる 11
© CADDi Inc. その他の技術選定の候補 • いくつかの候補を挙げたが、仮説検証の速さ、構成変更のしやすさ、コストやデータサイズが 増えた場合の影響などを重視して決定した 12 製品 メリット
デメリット RDBMS 扱いやすさ データサイズ拡大時のコストとパフォーマンス BigQuery マネージドサービス 大規模でも扱える コスト見積もりが困難 DuckDB 導入が容易 サーバーアプリケーション向きではない Apache Spark 大規模データの参照・編集に すぐれる 今回はデータの参照中心の要件であるため、運用が 楽なTrinoを採用(将来の採用はあり得る ) 有償製品 豊富な機能、サポート 仮説検証時点では調達リードタイム等を考慮して見 送り(将来の採用はあり得る )
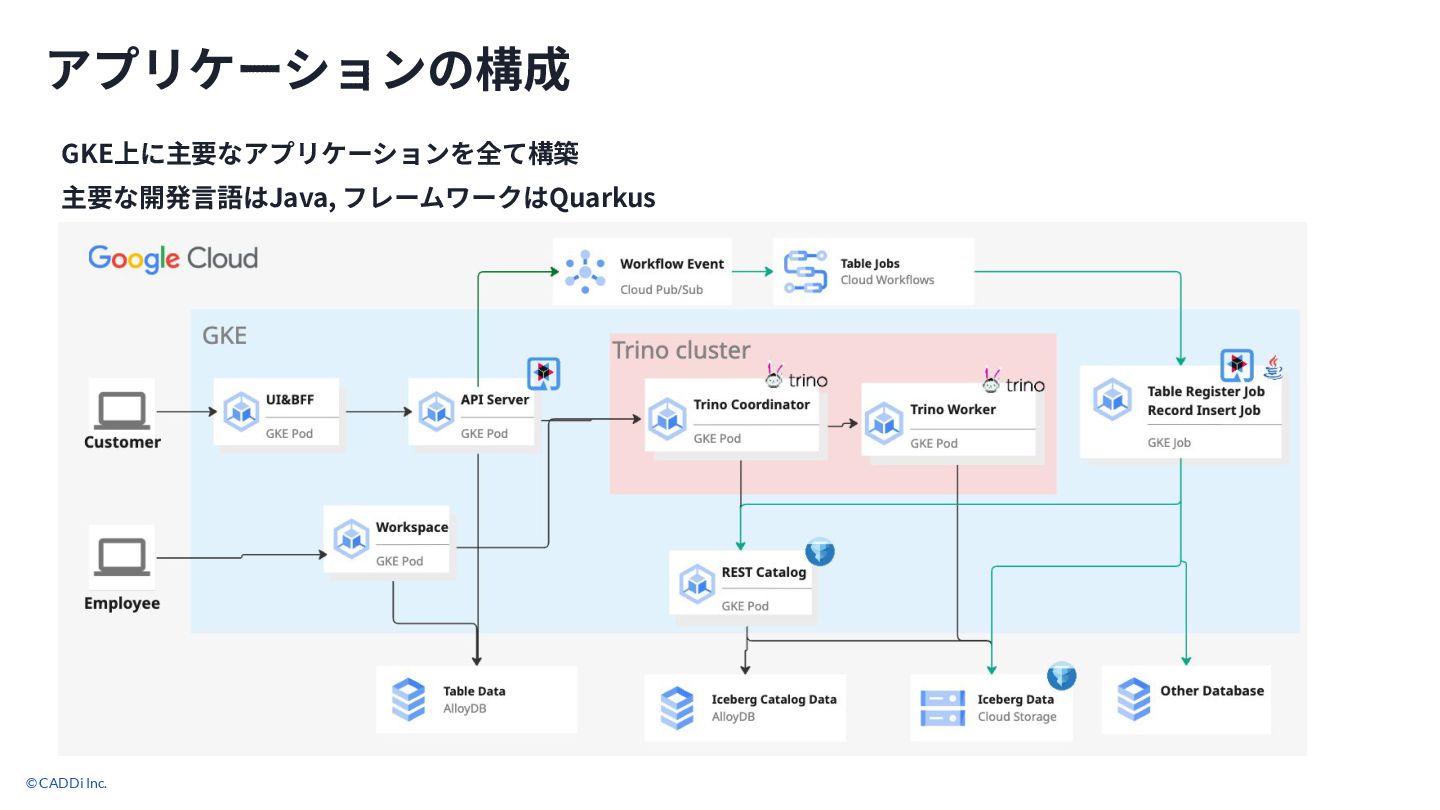
© CADDi Inc. アプリケーションの構成 GKE上に主要なアプリケーションを全て構築 主要な開発⾔語はJava, フレームワークはQuarkus 13
© CADDi Inc. 14 開発中の困りごととその解決策
© CADDi Inc. Iceberg Catalog選定問題 • 開発当時(2024年秋), Icebergの Catalogについてはhiveが基本でREST Catalog
はこれから標準 になっていくという雰囲気 • 当初はGoogle Cloud Dataproc Metastore を使う想定だったが、以下の理由によって諦めた ◦ Icebergのみを使うのにhive metastore を使うのは学習コストが⾼い ◦ 認証認可をやるには Kerberosの運⽤が必要になりそう • 将来移⾏するリスクを飲む前提で、tabulario/iceberg-rest (現在は iceberg-rest-fixture)と RDBMSを採⽤ • REST Catalogは現時点でも⾊々な選択肢があるので、今後の動向を⾒守っている ◦ Google Cloudの BigQuery Metastoreにも期待 15
© CADDi Inc. ⼤量データ投⼊が遅い問題 • 性能テストで1000万件以上のデータ投⼊のために、Trinoからデータ投⼊をしていたら2⽇か かっても終わらなかった • IcebergのJava API
を使って、Trinoを介さず直接データを書き込むようにした ◦ おおよそ 1000万件を 15分で処理できるように ◦ アップロードファイル単位のコミット制御も可能になった ◦ 詳しくは -> https://caddi.tech/2025/03/31/114754 • リリース開始後に数百万件の実データ投⼊の要件が発⽣したので、アプリケーションの登録 処理にも流⽤して効率をあげた ◦ 今後はPyIcebergや Sparkなども試していきたい 16
© CADDi Inc. 17 今後の展望
© CADDi Inc. 今後の展望 製造業AIデータプラットフォームCADDiを⽀えるデータ基盤として機能と品質を充実させ ていく • セキュリティ、認証認可の強化 • データカタログなどデータ基盤としての機能の拡充
• データパイプラインや⾃動メンテナンスなどの⾮機能の充実 18
© CADDi Inc. まとめ • スモールスタートからでもIceberg, Trinoは⾃分たちで制御可能なデータ基盤技術 ◦ 簡単ではないが、ものすごく複雑でもない ◦
これまでのデータ基盤技術の集⼤成だと感じる • エコシステムがこれからも充実していきそうなIcebergにこれからも注⽬していきた い 19
© CADDi Inc. © CADDi Inc. 20 終わり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}