in SEO • Occasional SEO conference speaker • EU, UK, US, Global Search Awards judge • Previous digital marketing lecturer & trainer • Industry publication contributor • Now predominantly consulting all of the time Stalker of information retrieval threads and IR conference hashtags since 2017
Searchers asked to provide feedback • Netflix users asked to thumbs up a film • Spotify favouriting or playlist building - leads to further recommendations • User groups / user panels • Sites asking for feedback • Professional expert relevance annotators • Paid human contractor evaluators
delegated to crowd workers, with a substantial decrease in terms of quality of the annotation, compensated by a huge increase in annotated data.” (Clarke et al, 2022)
at $2.22 billion in 2022 and it is expected to expand at a compound annual growth rate of 28.9% from 2023 to 2030, with the market then expected to be worth $13.7 billion.” Source: Grand View Research, 2021
• Assistant • AI content detection • Search quality evaluation • Image detection labelling • AI content detection training • Any other ML driven application
significantly undertrained, a consequence of the recent focus on scaling language models while keeping the amount of training data constant. …we find for compute-optimal training …for every doubling of model size the number of training tokens should also be doubled.” – “Training Compute-Optimal Large Language Models” (Hoffman et al, 2022)
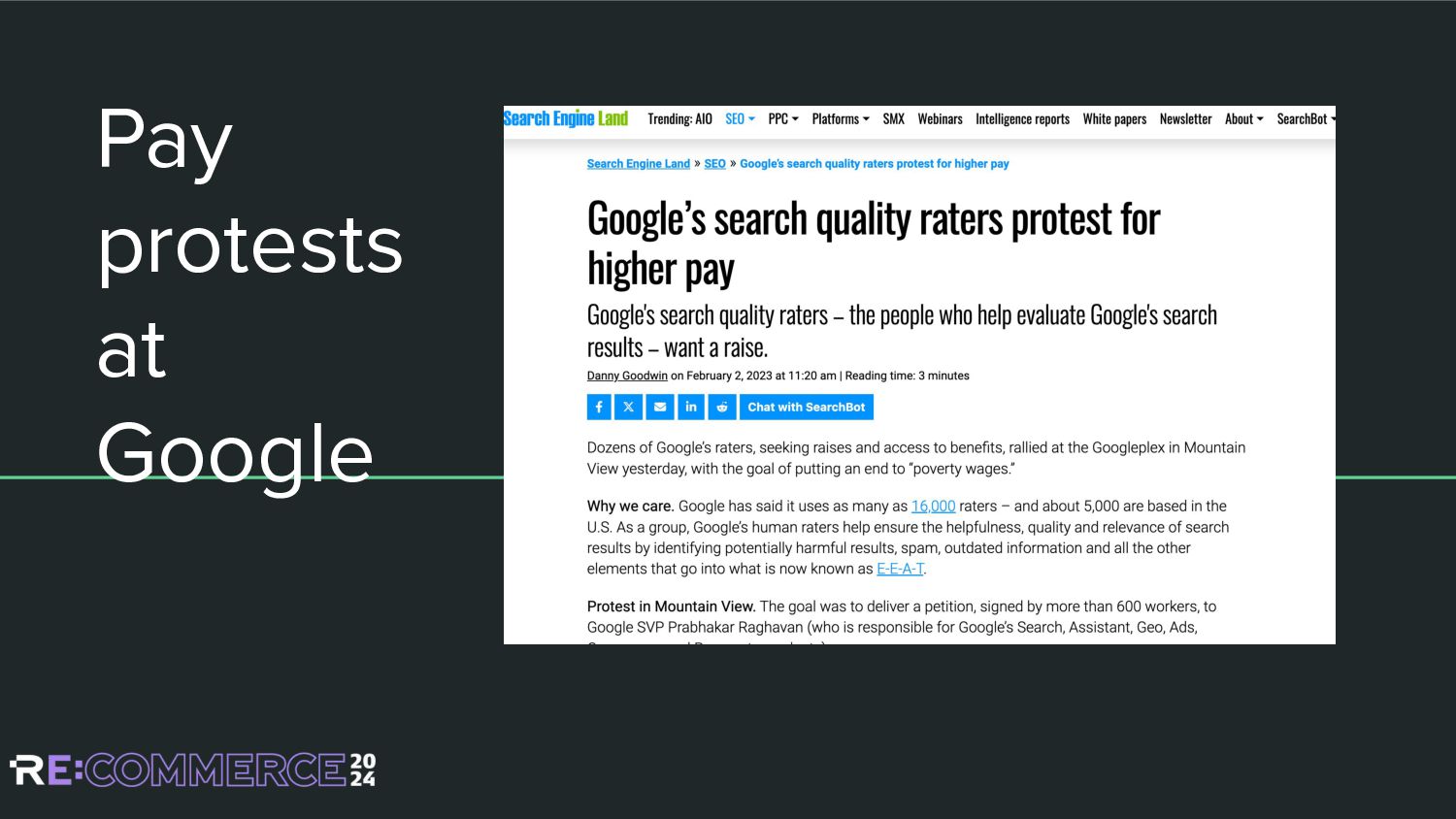
from large scale crowd-labelling’ (Thomas et al, 2022) Findings: • Fatigue • Time of day & day of week • Anchoring • Task-switching • Left-side bias • General disagreement on relevance
5) LLM agents to emulate the behaviour of search relevance evaluators • Produce enough gold and silver labels to build relevance training data for much larger data sets • Train the agents initially on gold labels ‘Large language models can accurately predict searcher preferences’ (Thomas et al, 2023)
but with these we find that models produce better labels than third-party workers, for a fraction of the cost, and these labels let us train notably better rankers.” (Thomas et al, 2023)
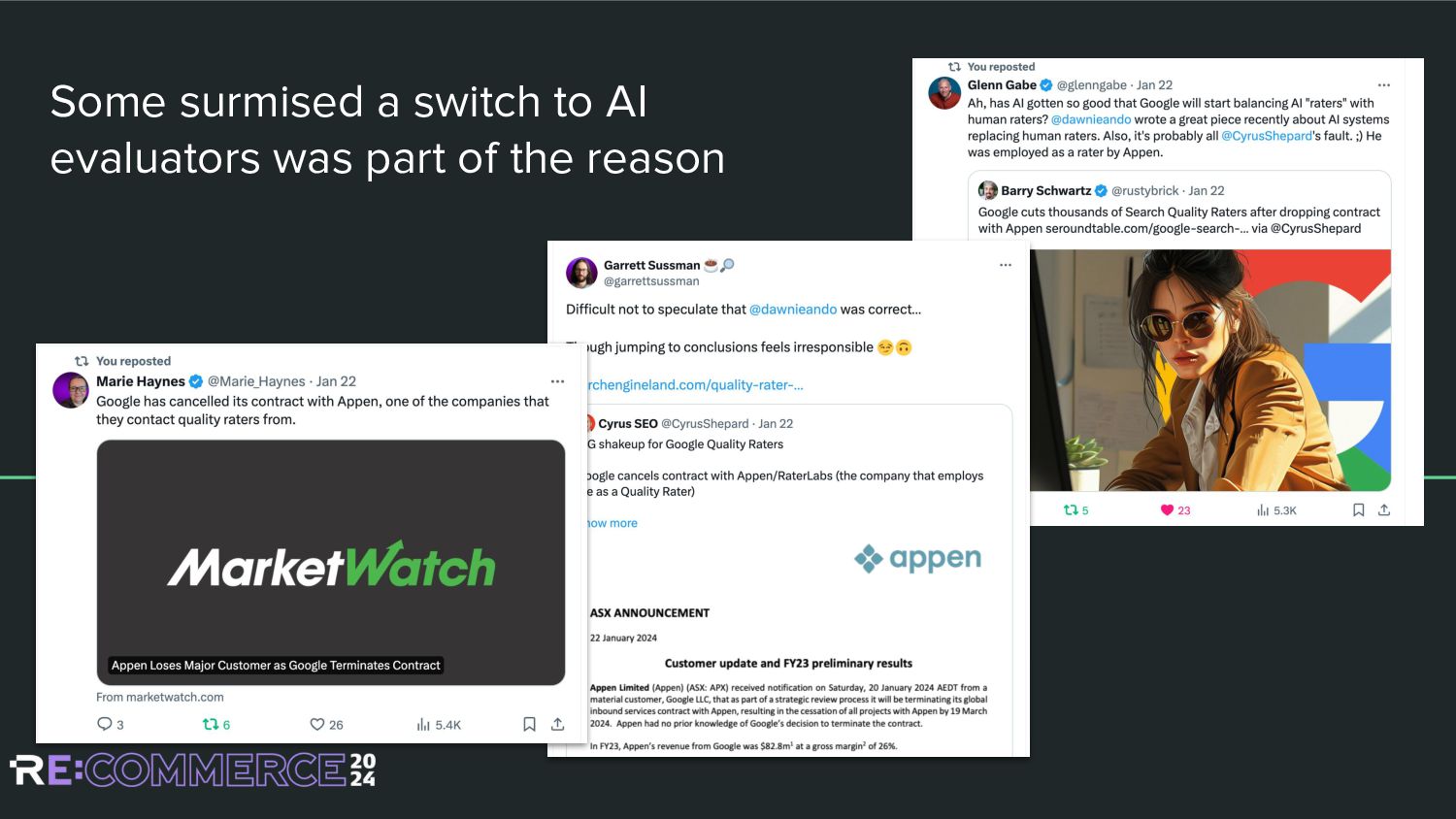
with such technology are: it is likely that in the next few years, we will assist in a substantial increase in the usage of LLMs to replace human annotators.” (Clarke et al, 2022)
a concern that machine-annotated assessments might degrade the quality, while dramatically increasing the number of annotations available.” Clarke et al, 2022
{kind=link}
{kind=link}
{kind=link}
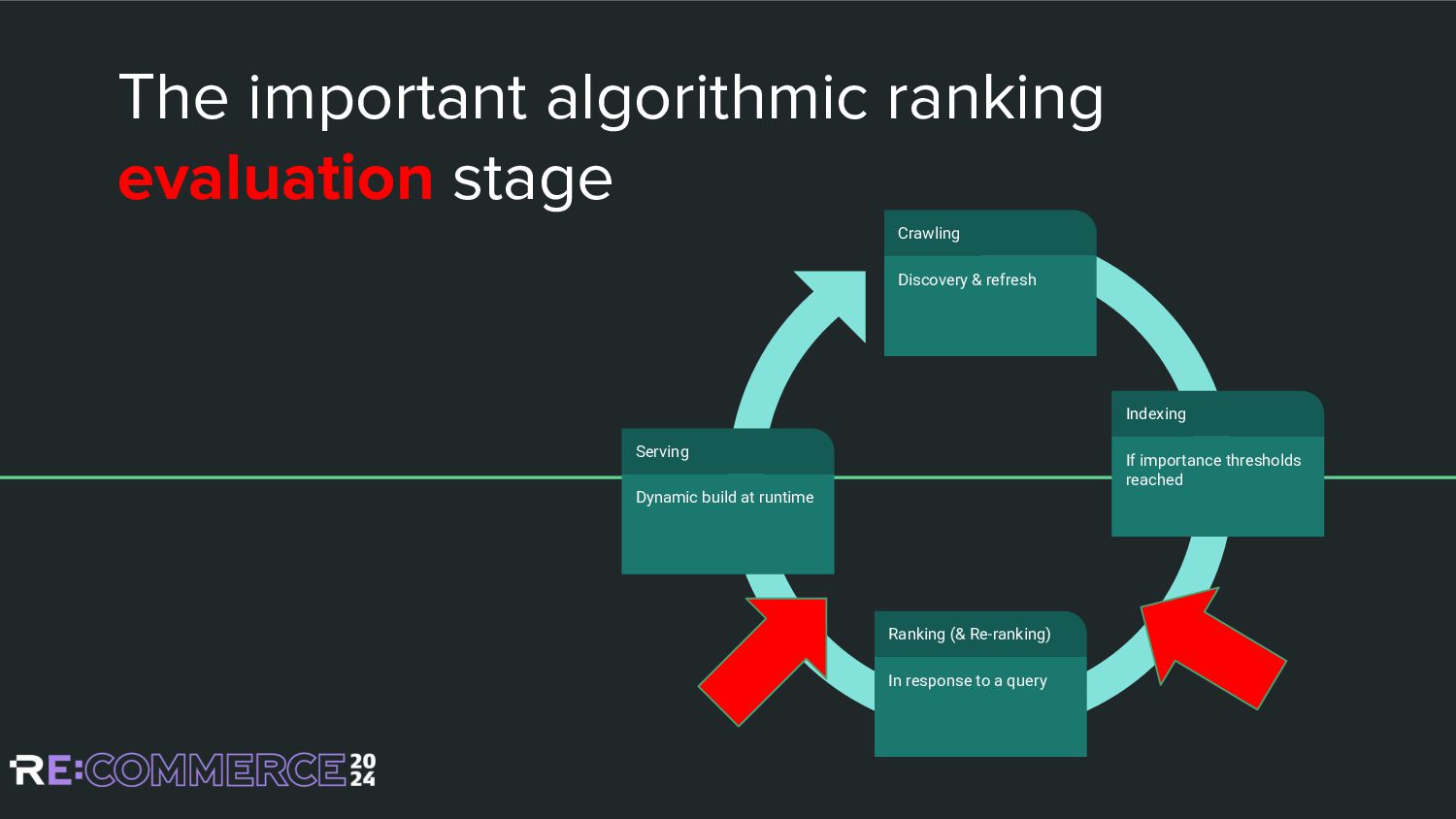{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
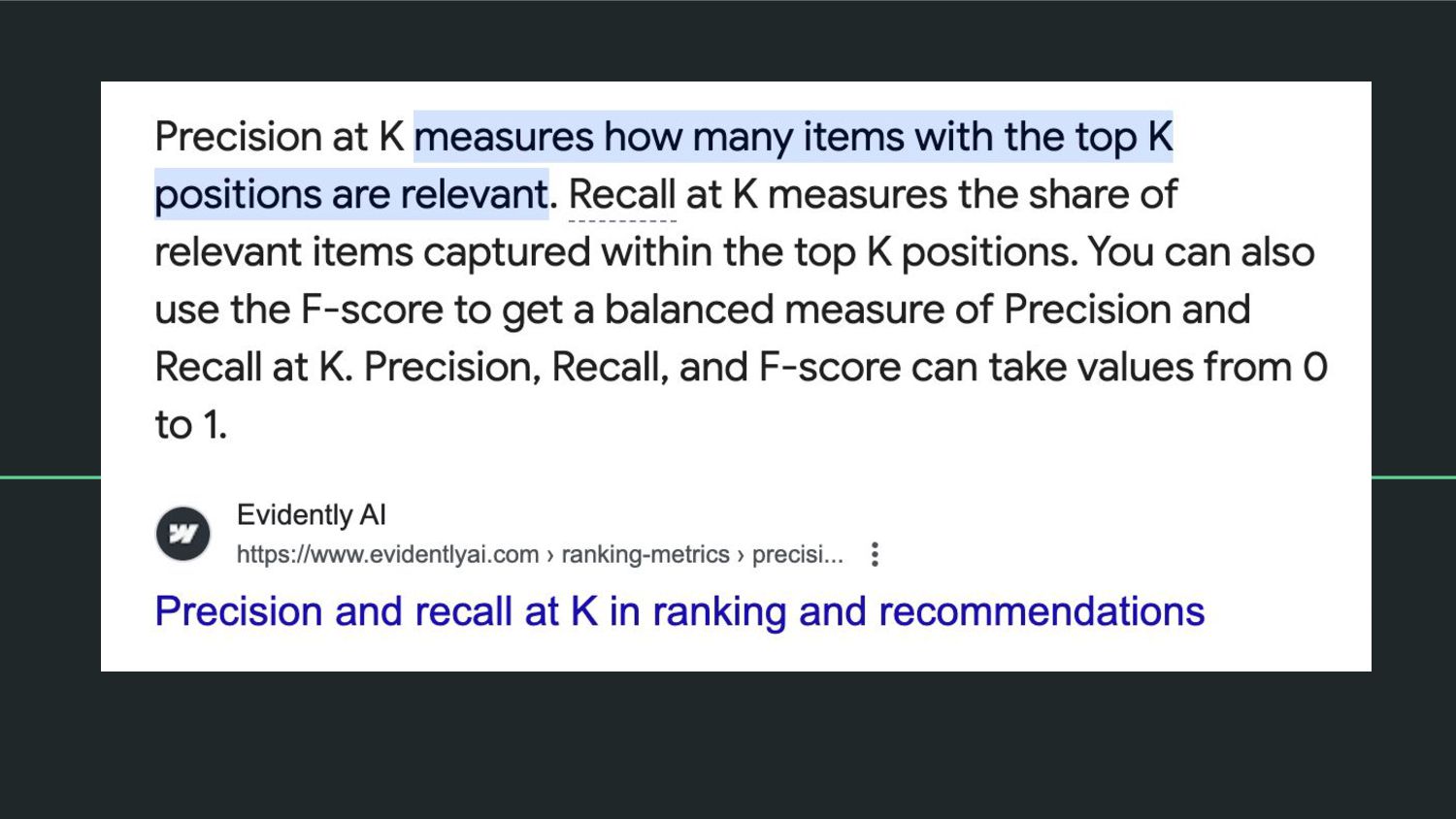{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
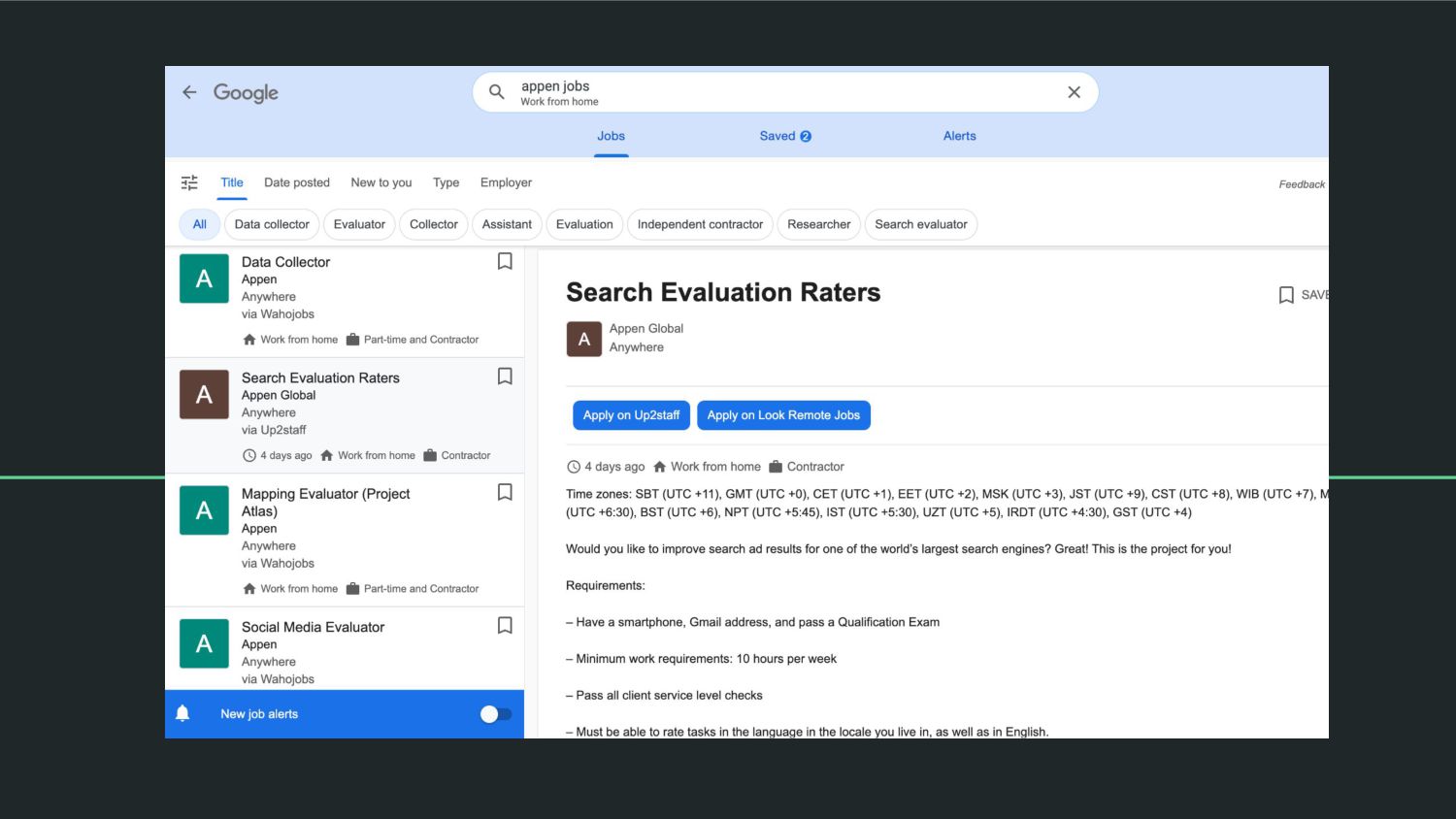{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
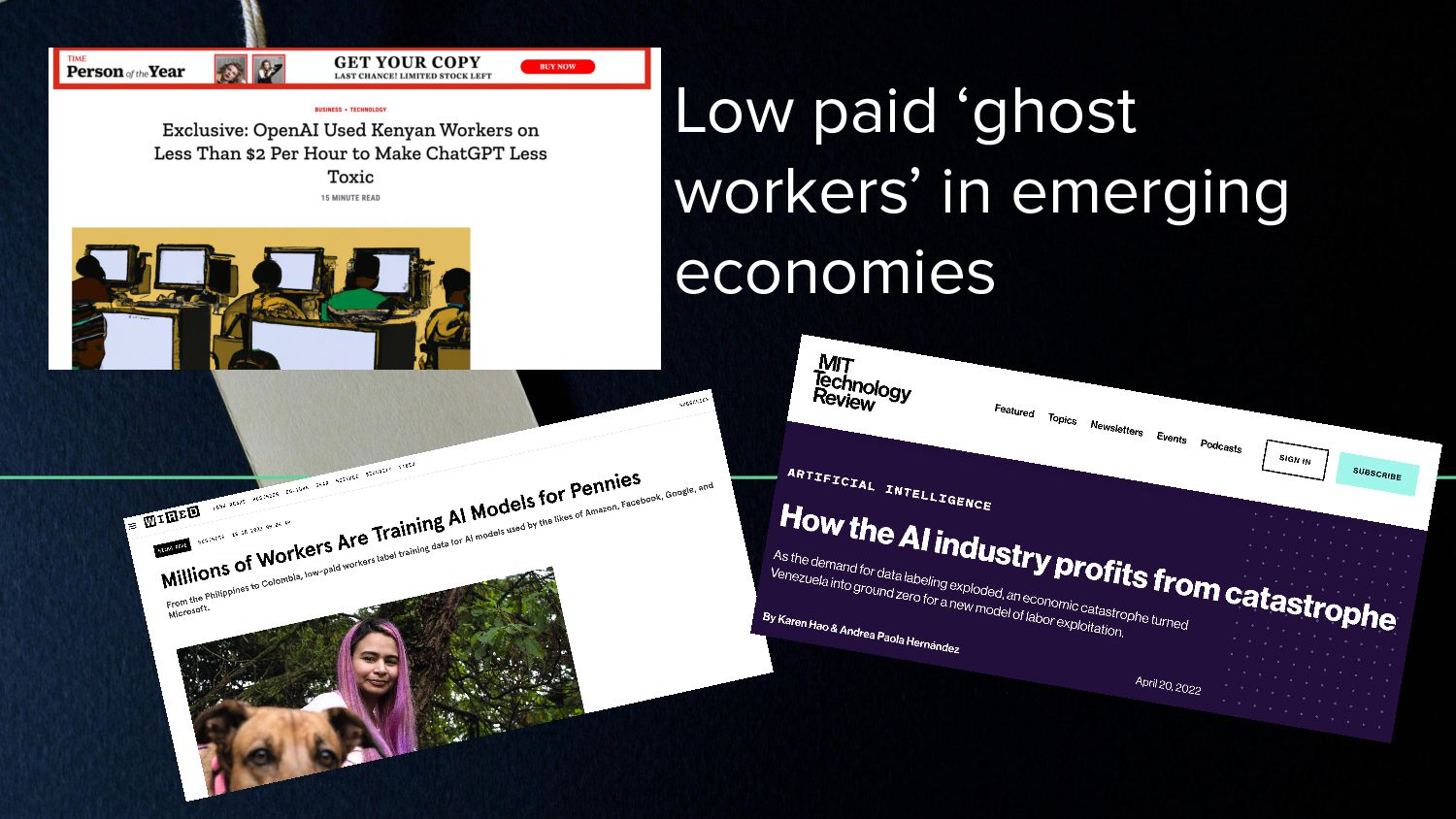{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}