SEO Crawl Rank And Crawl Tank - Brighton SEO April 2016
Originally presented by Dawn Anderson at Brighton SEO in April 2016
Why you should take care of crawls (Intelligent use of crawl allocation (budget)). Investigating 'crawl budget', 'crawl rank', 'crawl tank' and 'crawl scheduling by Search Engines'
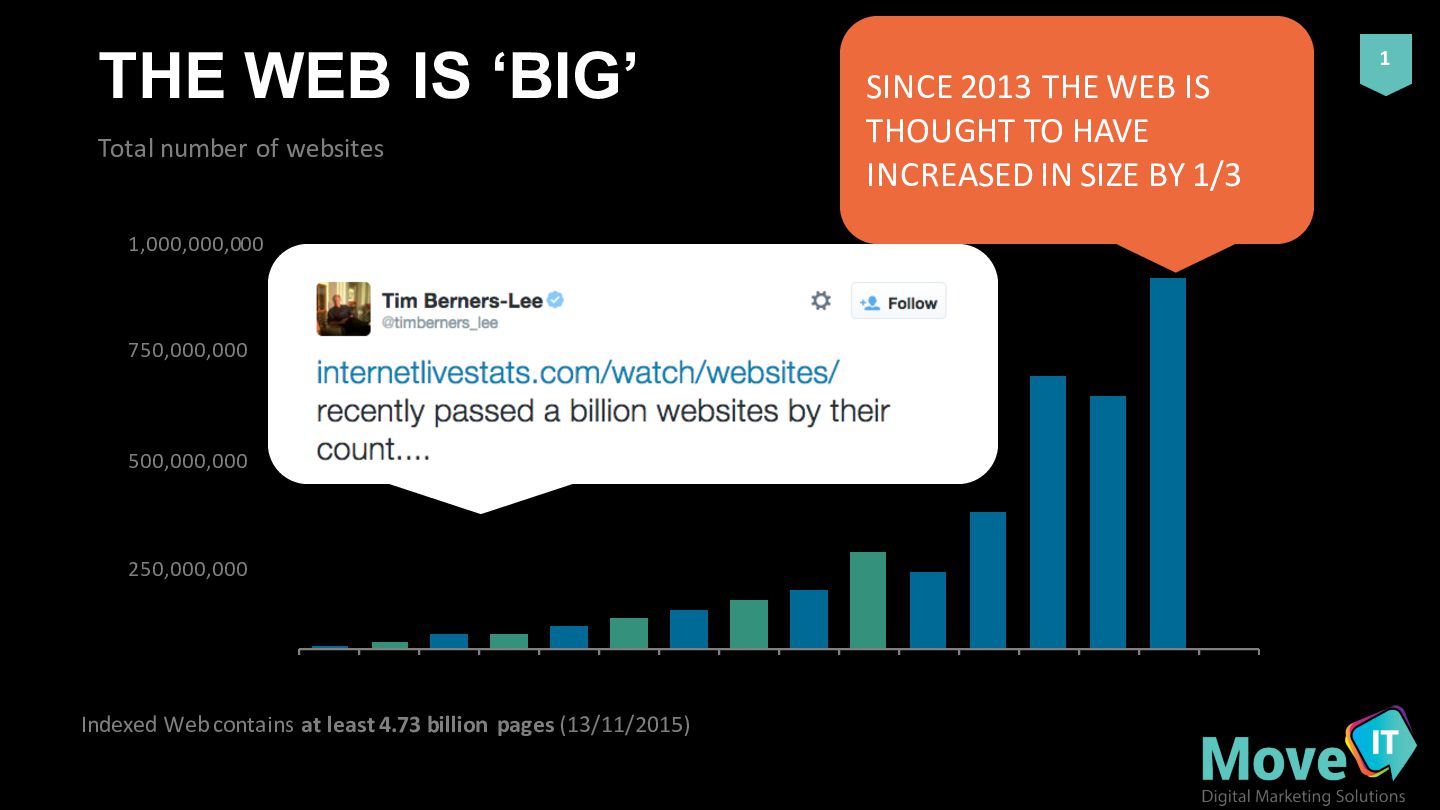
1 THE WEB IS ‘BIG’ Total number of websites 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 1,000,000,000 750,000,000 500,000,000 250,000,000 SINCE 2013 THE WEB IS THOUGHT TO HAVE INCREASED IN SIZE BY 1/3
THIS – WE ALL ‘LOVE CONTENT’ IMPORTANT TO NOTE THAT 75% OF WEBSITES ONLINE ARE DORMANT (E.G. PARKED DOMAINS) IMAGINE HOW MANY UNIQUE URLs COMBINED THIS AMOUNTS TO? – A LOT http://www.internetlivestats.com/total-‐number-‐of-‐websites/
URLs for crawling By assigning crawl period intervals to URLs How have search engines responded? By creating work ‘schedules’ for Googlebots 3 TOO MUCH CONTENT
CRAWLING) “While web pages can be manually selected for crawling, this becomes impracticable as the number of web pages grows. Moreover, to keep within the capacity limits of the crawler, automated selection mechanisms are needed to determine not only which web pages to crawl, but which web pages to avoid crawling. For instance, as of the end of 2003, the WWW is believed to include well in excess of 10 billion distinct documents or web pages, while a search engine may have a crawling capacity that is less than half as many documents.” -‐ Scheduler for search engine crawler Google Patent US 8042112 B1, (Zhu et al)
5 SOME GOOGLE CRAWL SCHEDULER PATENTS ‘Scheduling a recrawl’ - US 8386459 B1 ‘Web crawler scheduler that utilizes sitemaps from websites’ - US 8037054 B2 ‘Document reuse in a search engine crawler’ - US 8707312 B1 ‘Minimizing visibility of stale content in web searching including revising web crawl intervals of documents’ - US 8407204 B2 ‘Scheduler for search engine crawler’ - US 8042112 B1 ‘Distributed crawling of hyperlinked documents’ - US 7305610 B1 IT SEEMS PRIORITIZATION AND GOOGLEBOT CRAWL EFFICIENCY ARE IMPORTANT TO SEARCH ENGINES
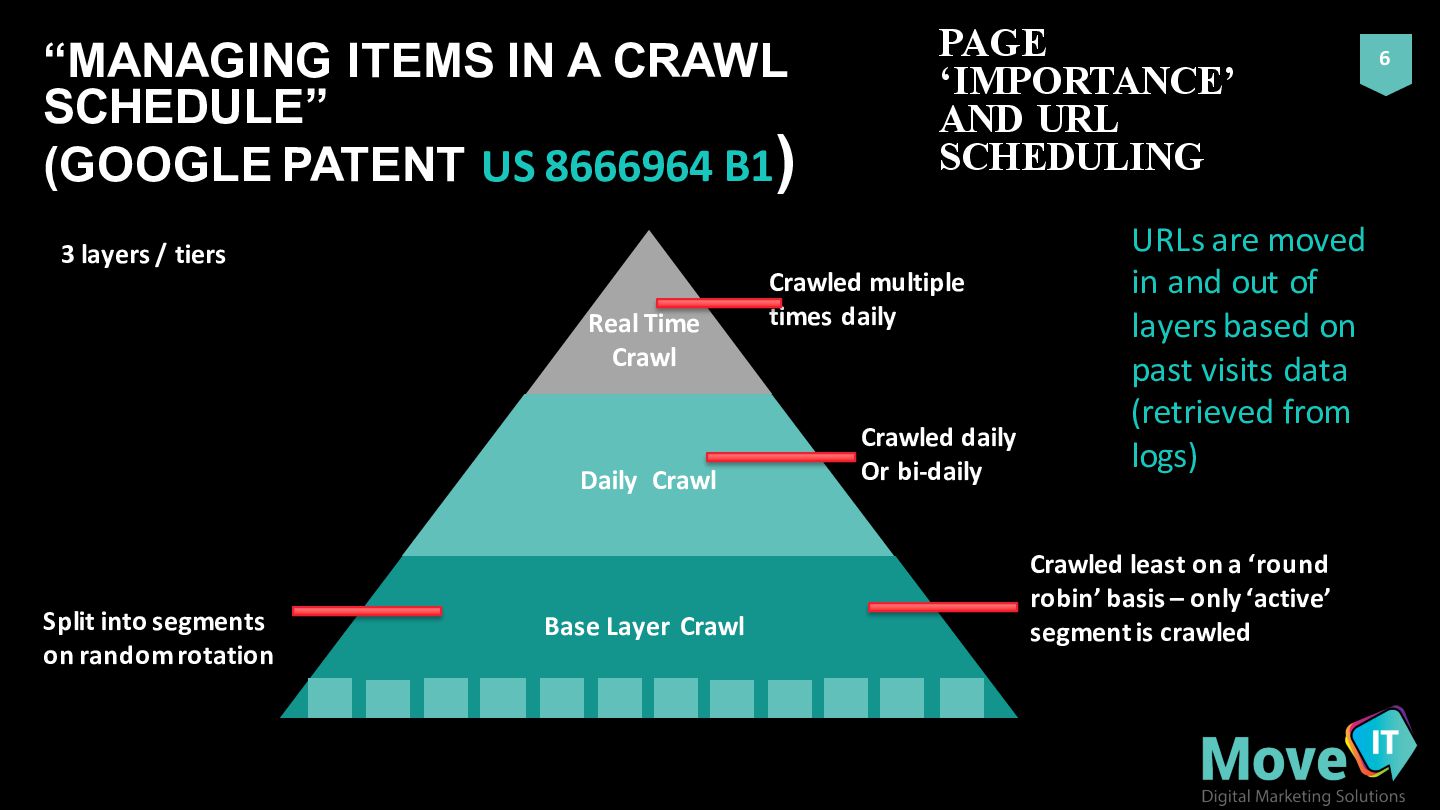
Crawled least on a ‘round robin’ basis – only ‘active’ segment is crawled Split into segments on random rotation 6 “MANAGING ITEMS IN A CRAWL SCHEDULE” (GOOGLE PATENT US 8666964 B1) Real Time Crawl Daily Crawl Base Layer Crawl 3 layers / tiers URLs are moved in and out of layers based on past visits data (retrieved from logs) PAGE ‘IMPORTANCE’ AND URL SCHEDULING
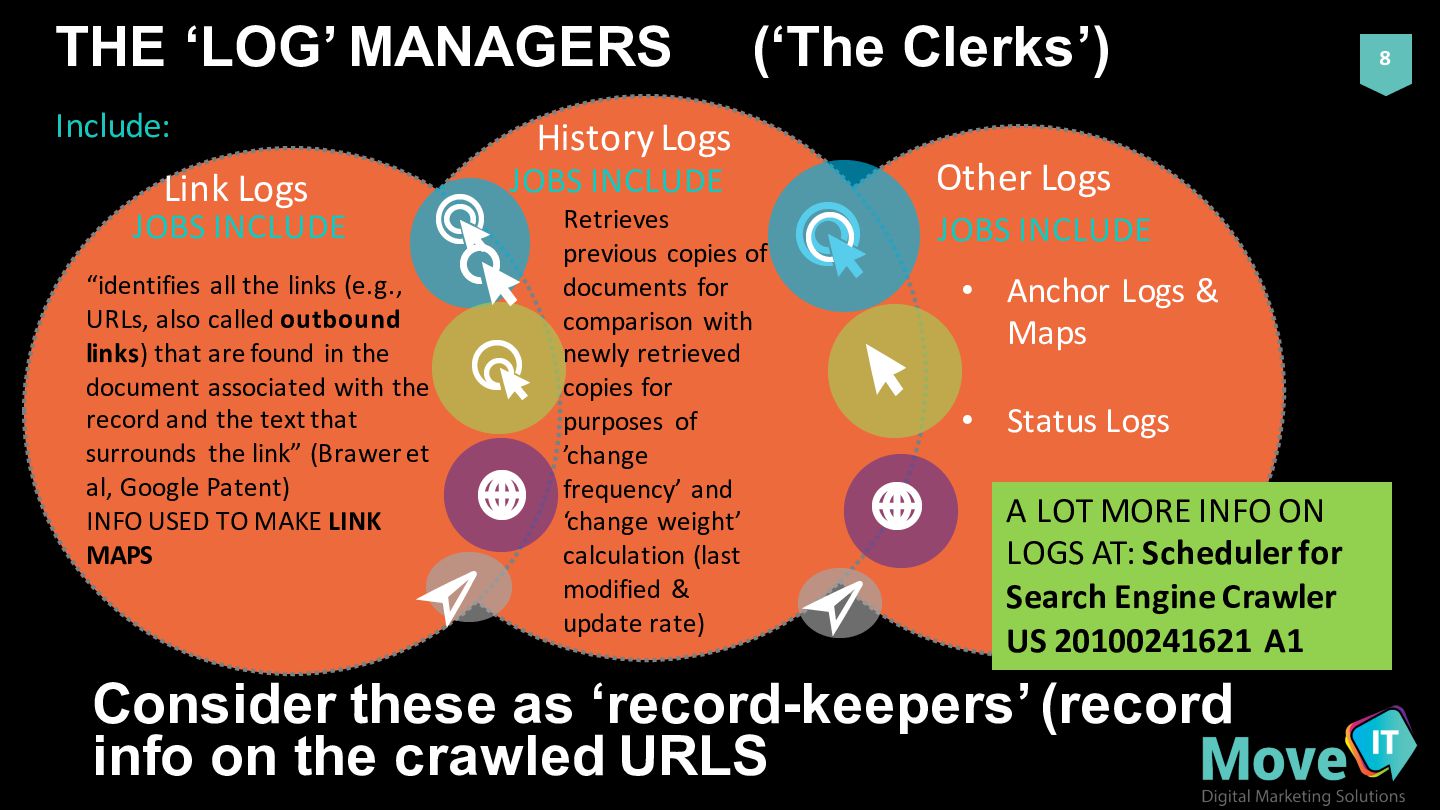
JOBS INCLUDE JOBS INCLUDE Other Logs JOBS INCLUDE Consider these as ‘record-keepers’ (record info on the crawled URLS Retrieves previous copies of documents for comparison with newly retrieved copies for purposes of ’change frequency’ and ‘change weight’ calculation (last modified & update rate) Include: “identifies all the links (e.g., URLs, also called outbound links) that are found in the document associated with the record and the text that surrounds the link” (Brawer et al, Google Patent) INFO USED TO MAKE LINK MAPS • Anchor Logs & Maps • Status Logs A LOT MORE INFO ON LOGS AT: Scheduler for Search Engine Crawler US 20100241621 A1
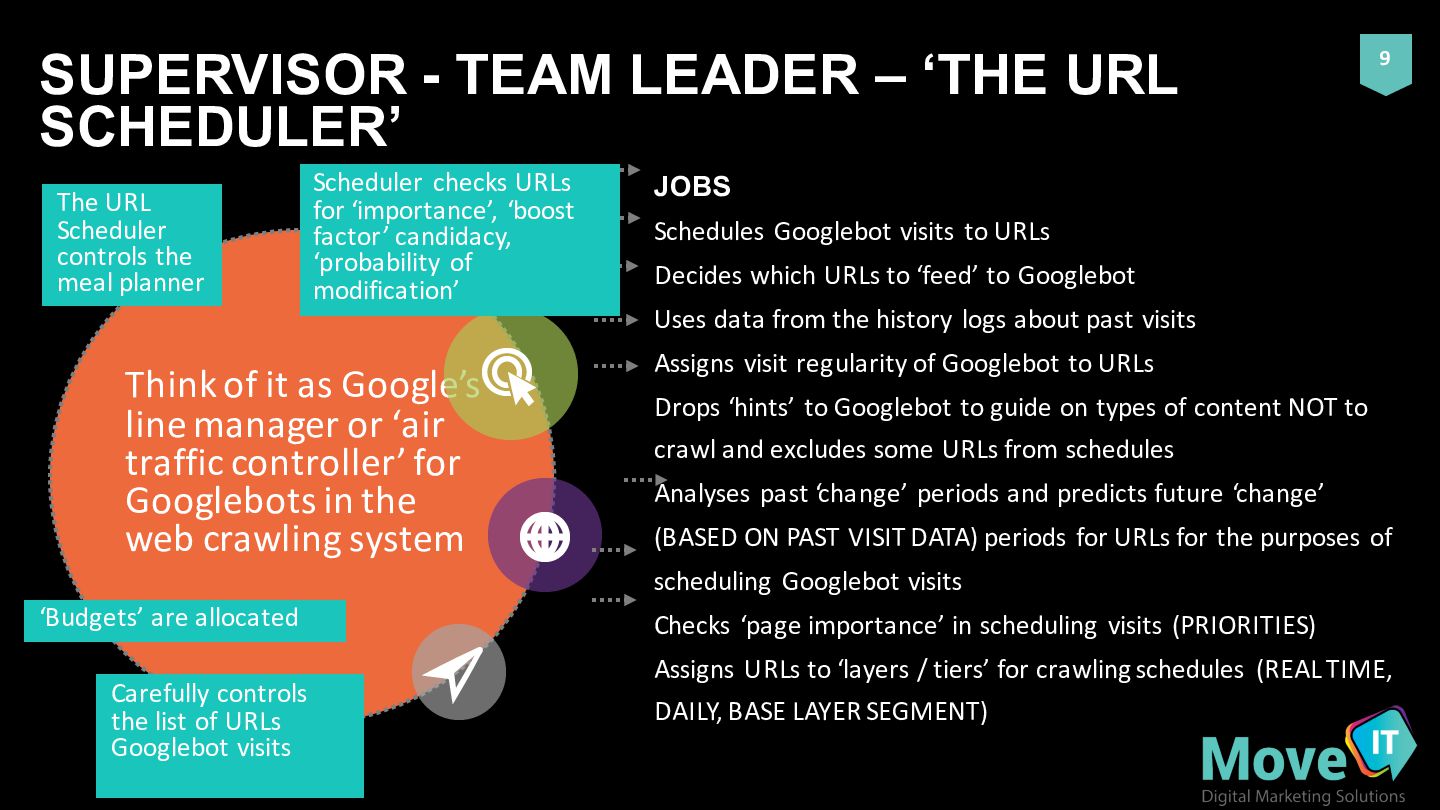
of it as Google’s line manager or ‘air traffic controller’ for Googlebots in the web crawling system JOBS Schedules Googlebot visits to URLs Decides which URLs to ‘feed’ to Googlebot Uses data from the history logs about past visits Assigns visit regularity of Googlebot to URLs Drops ‘hints’ to Googlebot to guide on types of content NOT to crawl and excludes some URLs from schedules Analyses past ‘change’ periods and predicts future ‘change’ (BASED ON PAST VISIT DATA) periods for URLs for the purposes of scheduling Googlebot visits Checks ‘page importance’ in scheduling visits (PRIORITIES) Assigns URLs to ‘layers / tiers’ for crawling schedules (REAL TIME, DAILY, BASE LAYER SEGMENT) The URL Scheduler controls the meal planner Scheduler checks URLs for ‘importance’, ‘boost factor’ candidacy, ‘probability of modification’ ‘Budgets’ are allocated Carefully controls the list of URLs Googlebot visits
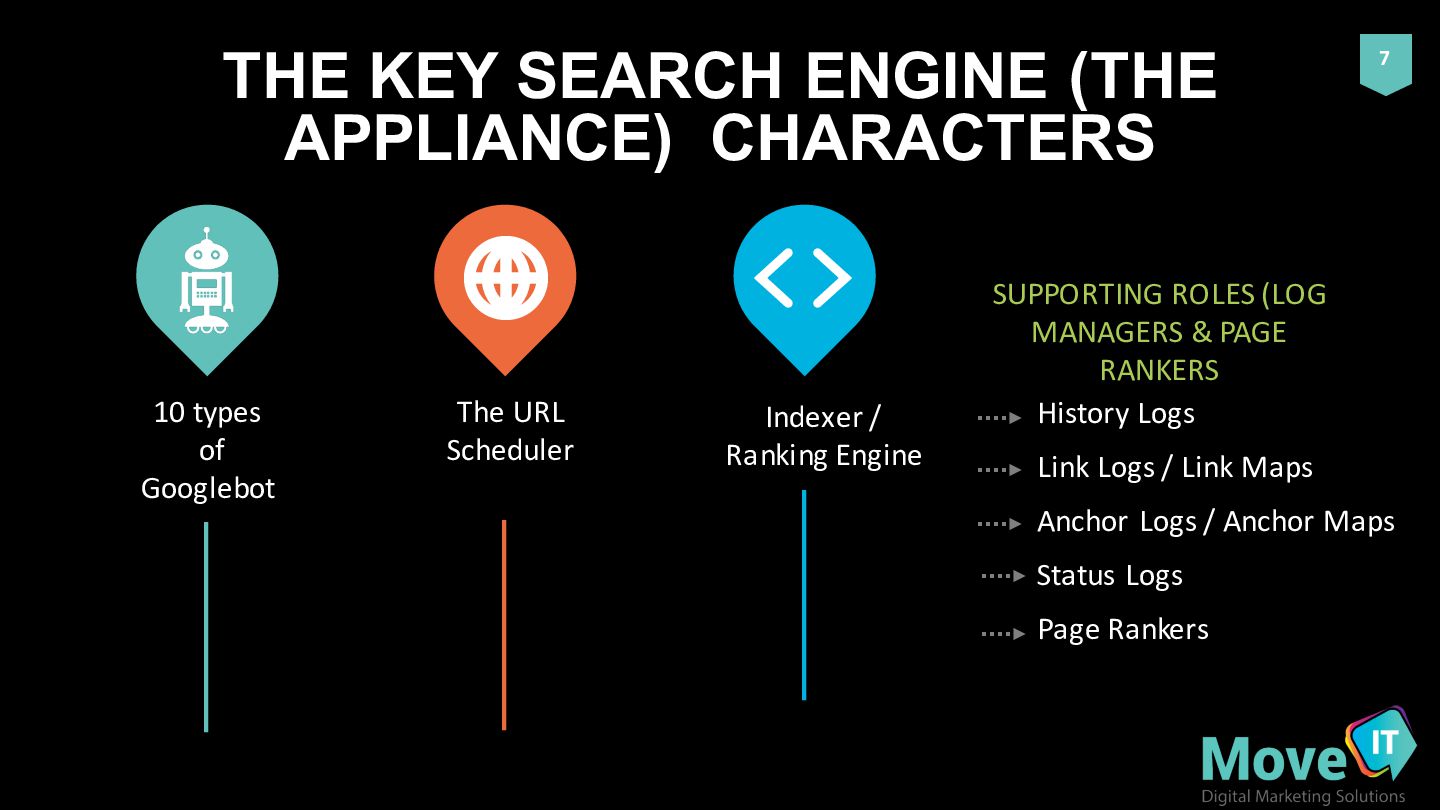
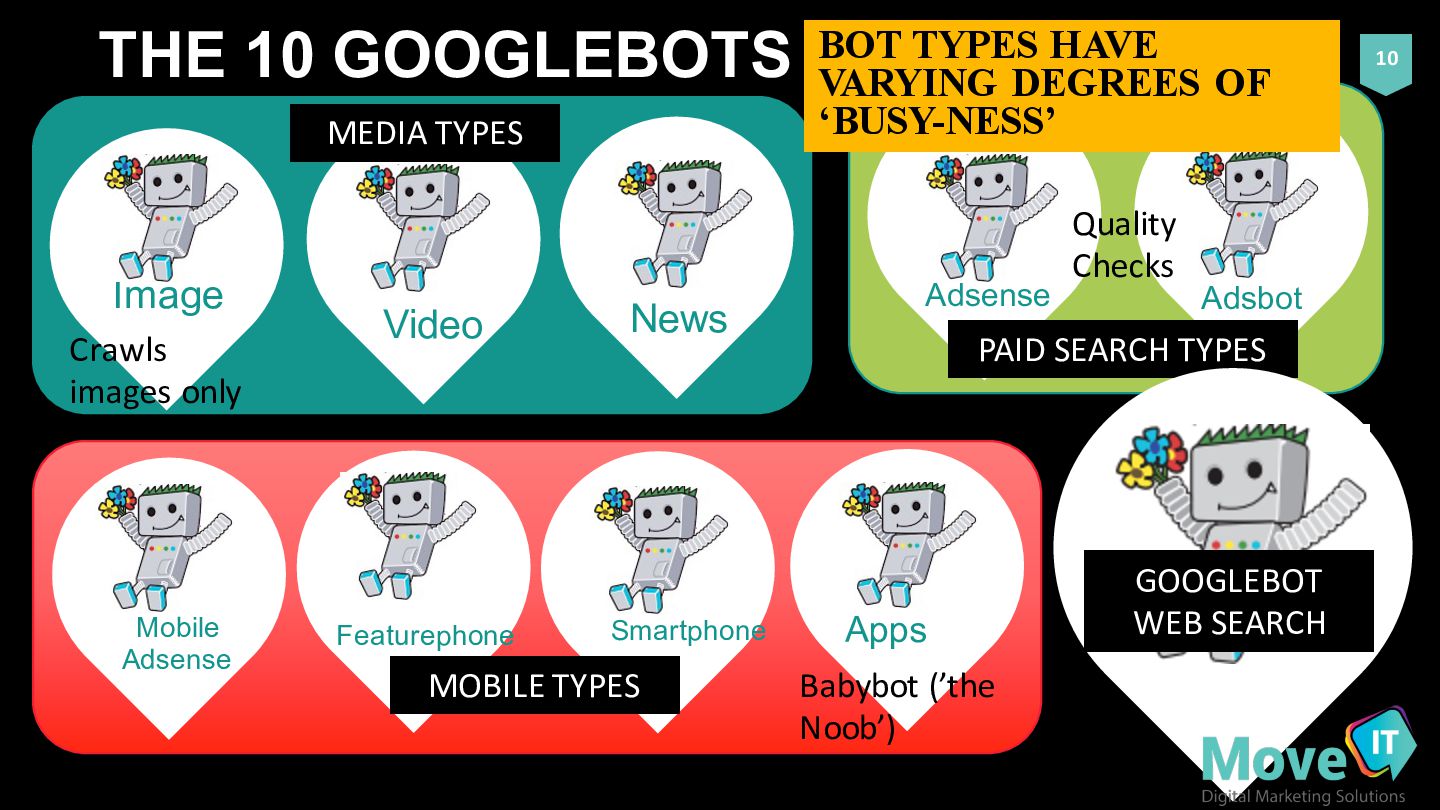
TYPES 10 MEDIA TYPES Smartphone Apps Featurephone Mobile Adsense MOBILE TYPES BOT TYPES HAVE VARYING DEGREES OF ‘BUSY-NESS’ GOOGLEBOT WEB SEARCH Crawls images only Quality Checks Babybot (’the Noob’)
Takes a list of URLs to crawl from URL Scheduler • Job varies based on ‘bot’ type (e.g. Image bot seems a bit of a ‘part timer’ (images change less frequently)) • Runs errands & makes deliveries for the URL server, indexer / ranking engine and logs • Makes notes of outbound linked pages and additional links for future crawling (in order for them to be assigned to future crawling schedules) • Takes notes of ‘hints’ from URL scheduler when crawling • Tells tales of URL accessibility status, server response codes, notes relationships between links and collects content checksums (binary data equivalent of web content) for comparison with past visits by history and link logs
the various logs (and the page rankers) of the search engine to index the URLs • Uses the combined data collected in order to index the results for a given query • TAKES DATA FROM THE LOGS TO GENERATE INDEXES “The indexer(s) 724 use the anchor maps 718 and other logs 716 to generate index(es) 726. The index(es) are used by the search engine to identify documents matching queries entered by users of the search engine.” (Web crawler scheduler that utilizes sitemaps from websites US 8037054 B2, Google Patent, Brawer et al, pub 2011)
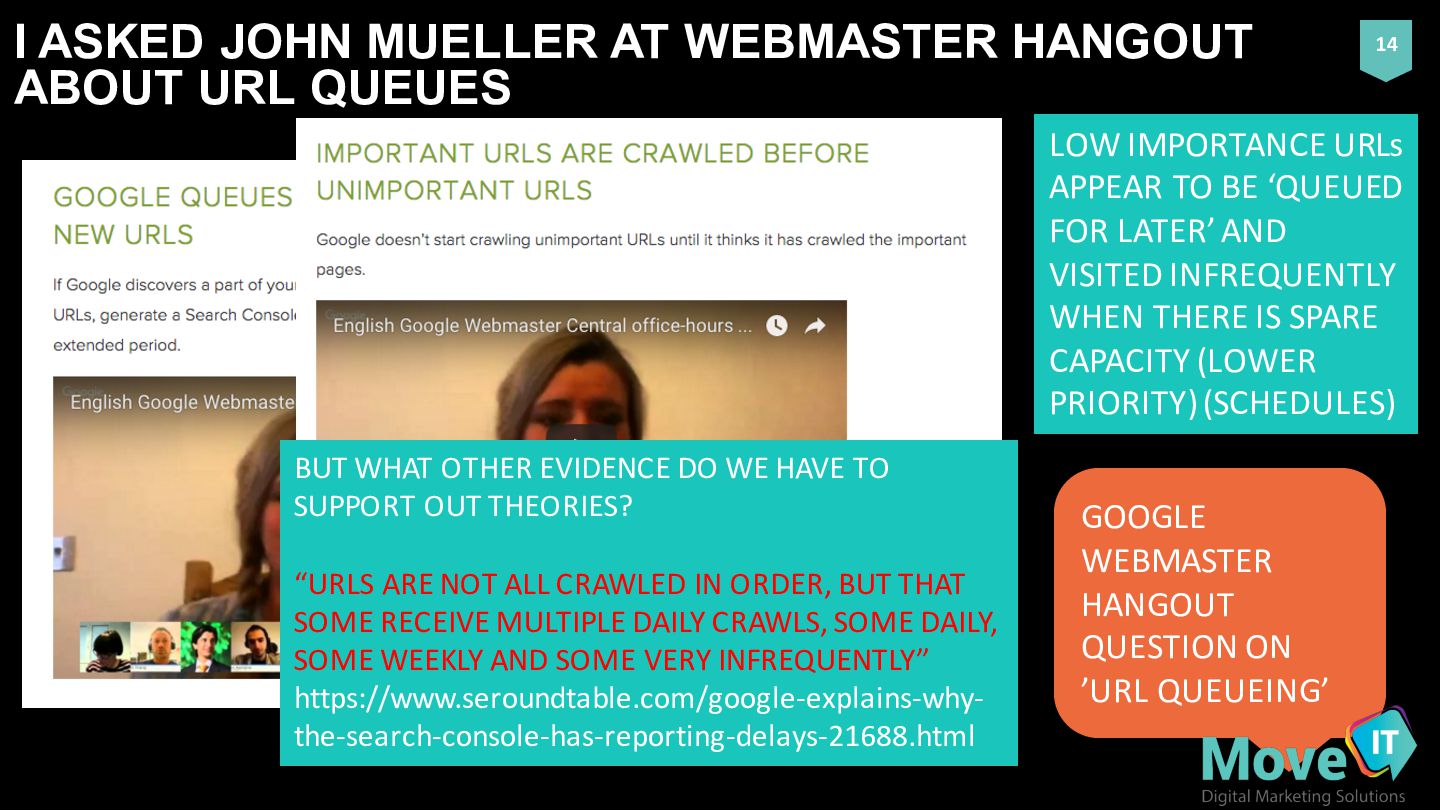
14 GOOGLE WEBMASTER HANGOUT QUESTION ON ’URL QUEUEING’ BUT WHAT OTHER EVIDENCE DO WE HAVE TO SUPPORT OUT THEORIES? “URLS ARE NOT ALL CRAWLED IN ORDER, BUT THAT SOME RECEIVE MULTIPLE DAILY CRAWLS, SOME DAILY, SOME WEEKLY AND SOME VERY INFREQUENTLY” https://www.seroundtable.com/google-‐explains-‐why-‐ the-‐search-‐console-‐has-‐reporting-‐delays-‐21688.html LOW IMPORTANCE URLs APPEAR TO BE ‘QUEUED FOR LATER’ AND VISITED INFREQUENTLY WHEN THERE IS SPARE CAPACITY (LOWER PRIORITY) (SCHEDULES)
for each remaining document identifier based on predetermined criteria (e.g., a page importance score of the document).” (Zhu et al, 2011) PATENT -‐ Scheduler for search engine crawler US 8042112 B1
CRAWL VISITS TO A HOST” 3. PAGES WITH A LOT OF LINKS GET CRAWLED MORE 4. THE VAST MAJORITY OF URLS ON THE WEB DON’T GET A LOT OF BUDGET ALLOCATED TO THEM (LOW TO 0 PAGERANK URLS). 2. ROUGHLY PROPORTIONATE TO PAGERANK AND HOST SPEED / CAPACITY Mostly taken from Eric Enge’s (interview with Matt Cutts (@mattcutts) interview from 2010 https://www.stonetemple.com/matt-‐cutts-‐ interviewed-‐by-‐eric-‐enge-‐2/
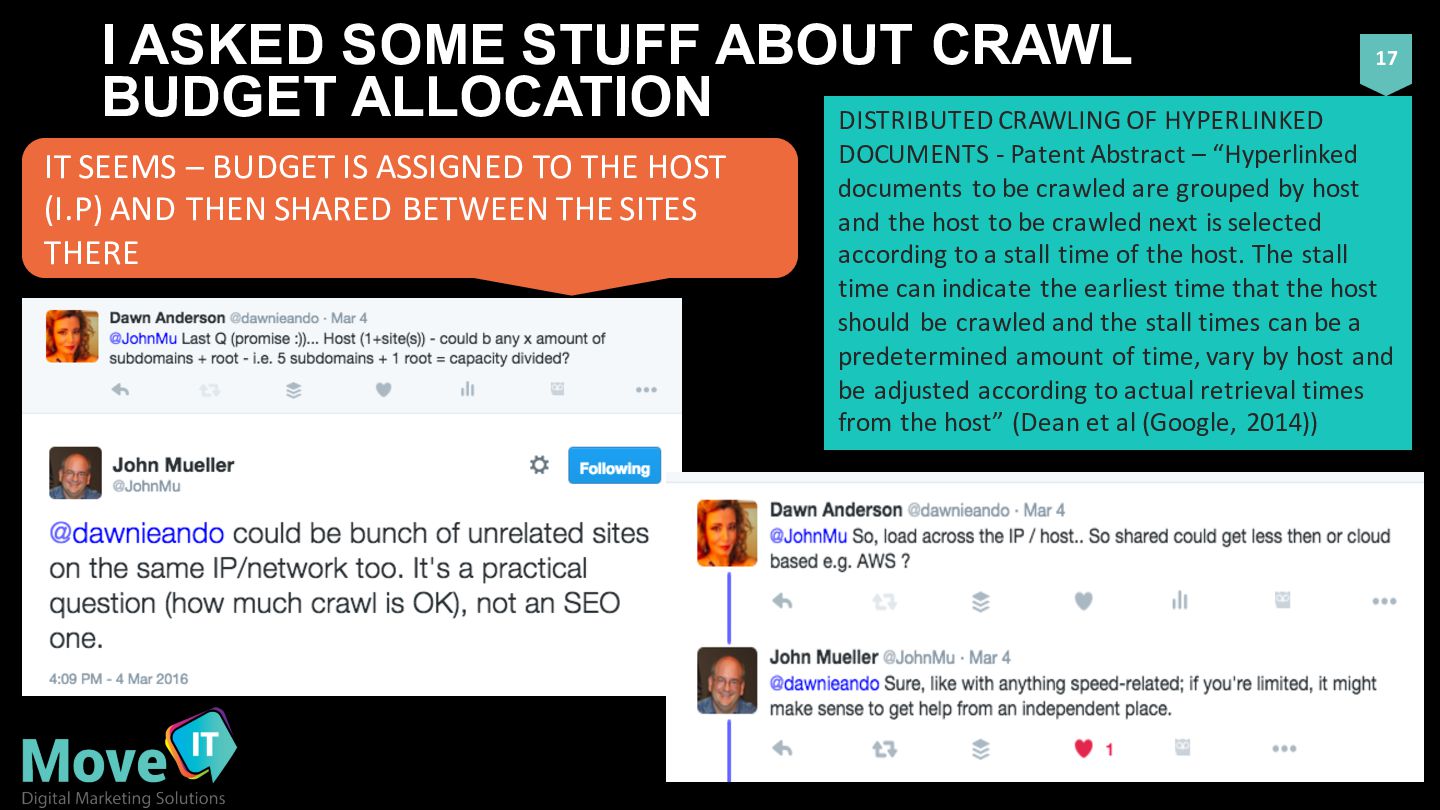
CRAWLING OF HYPERLINKED DOCUMENTS -‐ Patent Abstract – “Hyperlinked documents to be crawled are grouped by host and the host to be crawled next is selected according to a stall time of the host. The stall time can indicate the earliest time that the host should be crawled and the stall times can be a predetermined amount of time, vary by host and be adjusted according to actual retrieval times from the host” (Dean et al (Google, 2014)) IT SEEMS – BUDGET IS ASSIGNED TO THE HOST (I.P) AND THEN SHARED BETWEEN THE SITES THERE
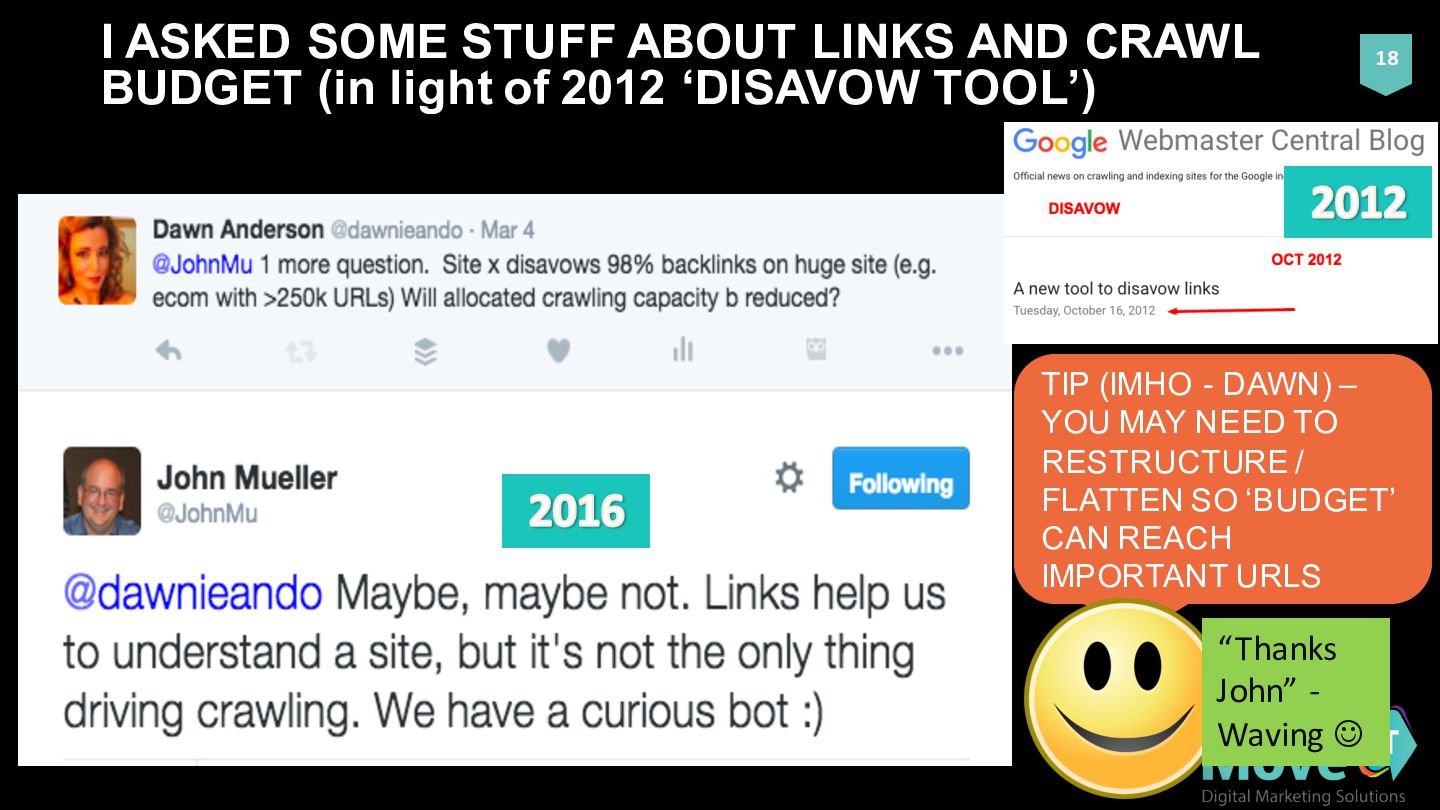
light of 2012 ‘DISAVOW TOOL’) 18 TIP (IMHO - DAWN) – YOU MAY NEED TO RESTRUCTURE / FLATTEN SO ‘BUDGET’ CAN REACH IMPORTANT URLS “Thanks John” -‐ Waving J
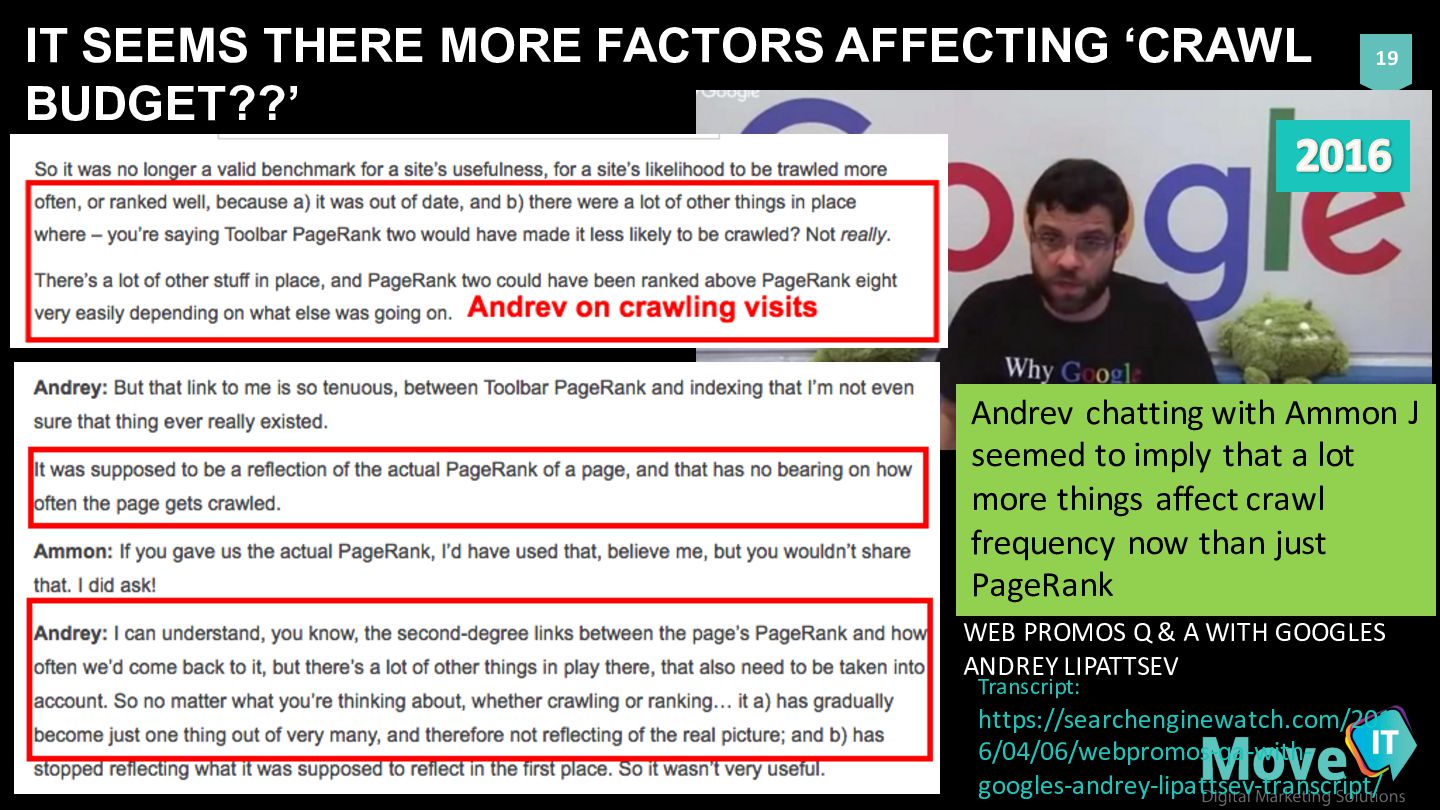
https://searchenginewatch.com/201 6/04/06/webpromos-‐qa-‐with-‐ googles-‐andrey-‐lipattsev-‐transcript/ WEB PROMOS Q & A WITH GOOGLES ANDREY LIPATTSEV Andrev chatting with Ammon J seemed to imply that a lot more things affect crawl frequency now than just PageRank
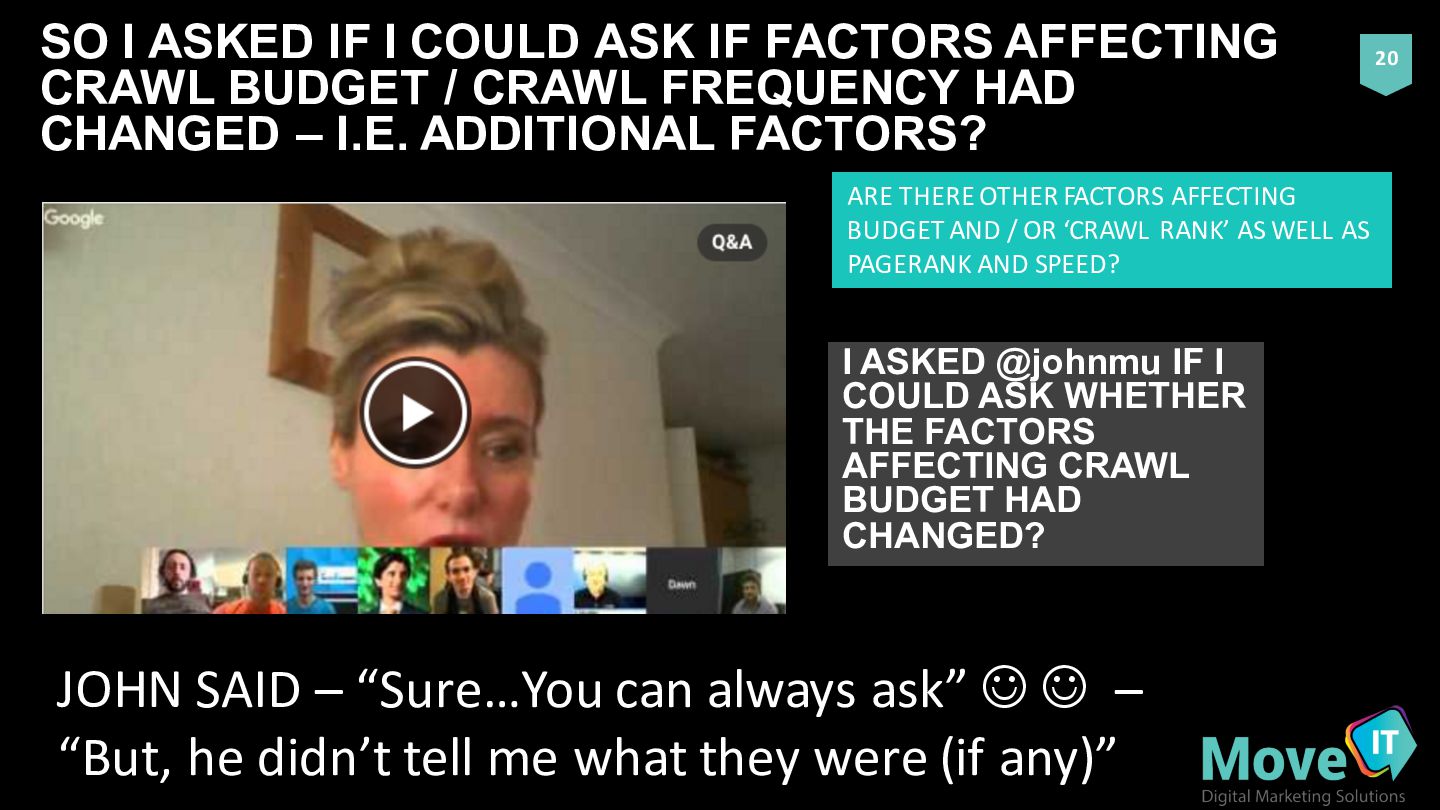
OR ‘CRAWL RANK’ AS WELL AS PAGERANK AND SPEED? I ASKED @johnmu IF I COULD ASK WHETHER THE FACTORS AFFECTING CRAWL BUDGET HAD CHANGED? JOHN SAID – “Sure…You can always ask” J J – “But, he didn’t tell me what they were (if any)” SO I ASKED IF I COULD ASK IF FACTORS AFFECTING CRAWL BUDGET / CRAWL FREQUENCY HAD CHANGED – I.E. ADDITIONAL FACTORS?
(CRITICAL & NON-CRITICAL) “Changes can be described as critical or non-critical and that determination may depend on the portion of the document changed, or the context of the changes, rather than the amount of text or content changed. Sometimes a change to a document may be insubstantial, e.g., the change of advertisements associated with a document. In this case, it is more appropriate to ignore those accessory materials in a document prior to making content comparisons. In other cases, e.g., as part of a product search, not every piece of information in a document is weighted equally by a potential user. For instance, the user may care more about the unit price of the product and the availability of the product. In this case, it is more appropriate to focus on the changes associated with information that is deemed critical to a potential user rather than something that is less significant, e.g., a change in a product's colour” (Minimizing Visibility of Stale Content in Web Searching Including Revising Web Crawl Intervals of Documents -‐ Anton Carver, Google Patent -‐ US 20130226897 A1, pub 2013) Probability & predictability of future ‘freshness’ (newness or critical material change) (‘CHANGE RATE’ APPEARS TO BE ‘LEARNED’) ’CHANGE RATE & CHANGE WEIGHT THRESHOLDS’
C = ∑ i = 0 n -‐ 1 weight i * feature NOT JUST ‘RANDOM’ CHANGE like Shuffle($variable) or RAND($variable) NOT ALL ‘FEATURES’ ARE CREATED EQUAL ACCORDING TO THIS LINE IN PATENTS –” weight i * feature” EXAMPLE FEATURES – E.G. A CHANGE IN PRICE (FEATURE) MAY BE WEIGHTED HIGHER THAN A CHANGE IN COLOUR (FEATURE) – FEATURE WEIGHT PRICE > FEATURE WEIGHT COLOUR ”DEPENDS ON HOW OFTEN THE PAGE CHANGES” IS MENTIONED A LOT IN WEBMASTER HANGOUTS Minimizing Visibility of Stale Content in Web Searching Including Revising Web Crawl Intervals of Documents -‐ Anton Carver, Google Patent -‐ US 20130226897 A1, pub 2013
2015), reported here by SERoundtable on quote from Google’s John Mueller @johnmu https://www.seroundtable.com/google-‐number-‐one-‐seo-‐advice-‐ be-‐consistent-‐21196.html DA -‐ I HAVE A FEELING CONSISTENCY IS IMPORTANT FOR ‘HISTORY LOGS’ TO ‘LEARN’ CHANGE RATES / THRESHOLDS
URLs 24 ‘RANDOM’ CHANGE created programmatically like Shuffle($variable) or RAND($variable) may even be seen as ‘hints’ TO GOOGLEBOT TO ‘NOT’ CRAWL HINTS = ‘MEH CHANGES’ (E.G. PATTERNS OF ’SAME OLD, SAME OLD STUFF’ DUPLICATES, PROGRAMMATICALLY GENERATED CONTENT) "Hints may also be employed on pages that are automatically generated and/or contain dynamically generated elements that result in the page having a different checksum every time it is crawled” (Managing Items In A Crawl Schedule, Google Patent - US 8666964 B1)
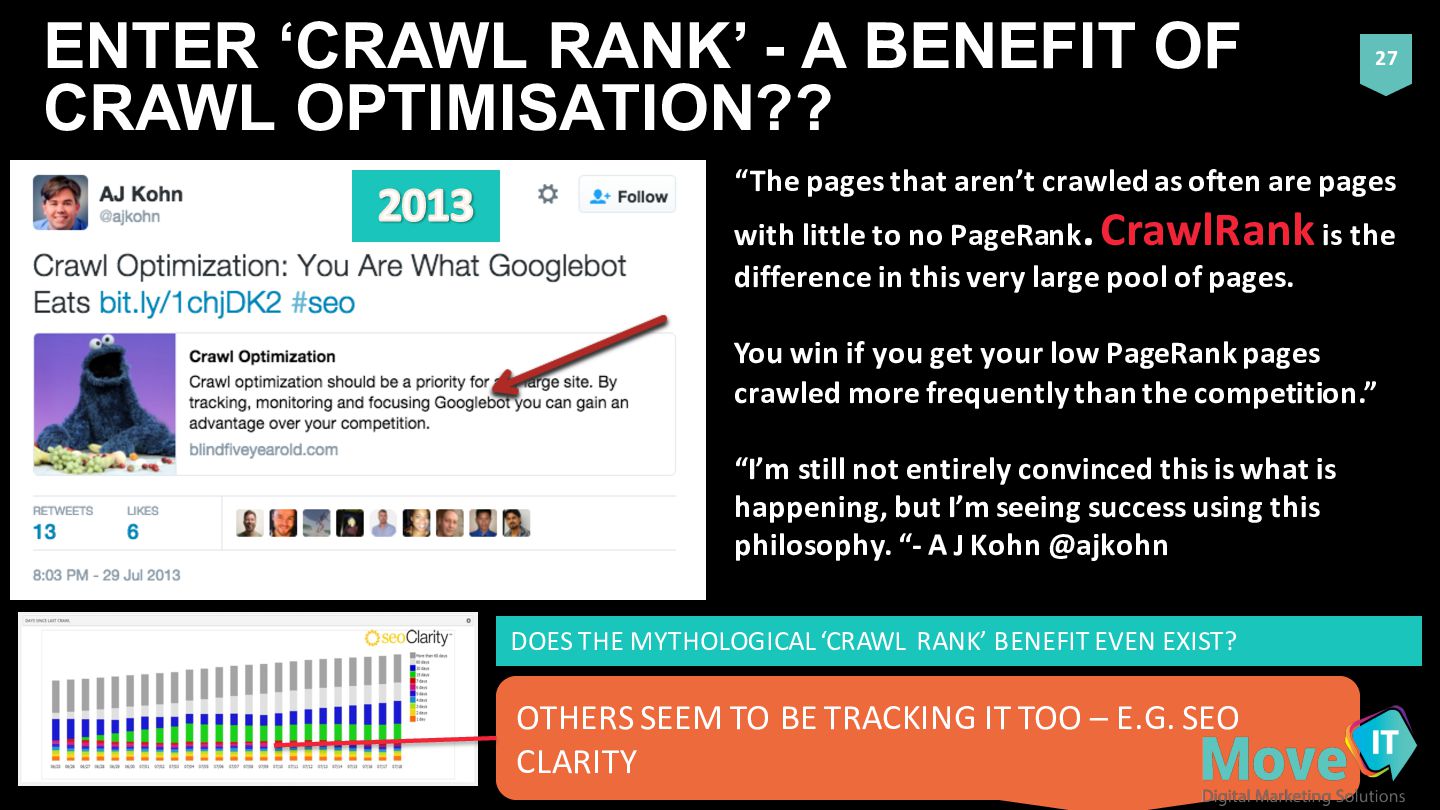
“The pages that aren’t crawled as often are pages with little to no PageRank. CrawlRankis the difference in this very large pool of pages. You win if you get your low PageRank pages crawled more frequently than the competition.” “I’m still not entirely convinced this is what is happening, but I’m seeing success using this philosophy. “-‐ A J Kohn @ajkohn OTHERS SEEM TO BE TRACKING IT TOO – E.G. SEO CLARITY DOES THE MYTHOLOGICAL ‘CRAWL RANK’ BENEFIT EVEN EXIST?
KOHN IF HE STILL THOUGHT IT APPLIED NOW? “Thanks A.J” -‐ Waving J ”I still see evidence that getting pages crawled frequently (within 7-‐10 days) seems to have an impact on their ability to rank well” (AJ Kohn, 2016)
ALL BE STRONGER THAN YOU BUT THERE ARE A LOT OF PAGES ON BIG SITES WITH NO STRENGTH YOU WON’T BEAT THE STRONG URLs WITH CRAWL OPTIMISATION ALONE You are unlikely to beat these URLs with crawl optimisation techniques alone. These URLs are not the intended target for these tactics – TOO STRONG SAVE SOME BATTLES FOR LATER Strong URLs
LEVEL WITH LOW TO 0 PAGE RANK URLS 32 PICK OFF THE WEAKER URLS WHEN BATTLING WITH A BIG SITE – LOW TO NO PAGE RANK URLS • TARGETS THE LOW STRENGTH PAGES FURTHER DOWN IN THE SITES OF COMPETITORS (SUBCATEGORY PAGES E.G. IN ECOMMERCE SITES • THERE ARE A LOT OF PAGES (MILLIONS WITH LITTLE TO NO PAGE RANK) • YOU’RE AIMING TO BEAT THOSE VIRTUALLY NO STRENGTH IN 1,000s OF URLS POWERFUL WELL KNOWN BRANDS BUT NO STRENGTH LOWER DOWN THE ARCHITECTURE MANY LOW VOL / DEEP URLs ARE COMPLETE WEEDS ON BEHEMOTH SITES Weak URLs
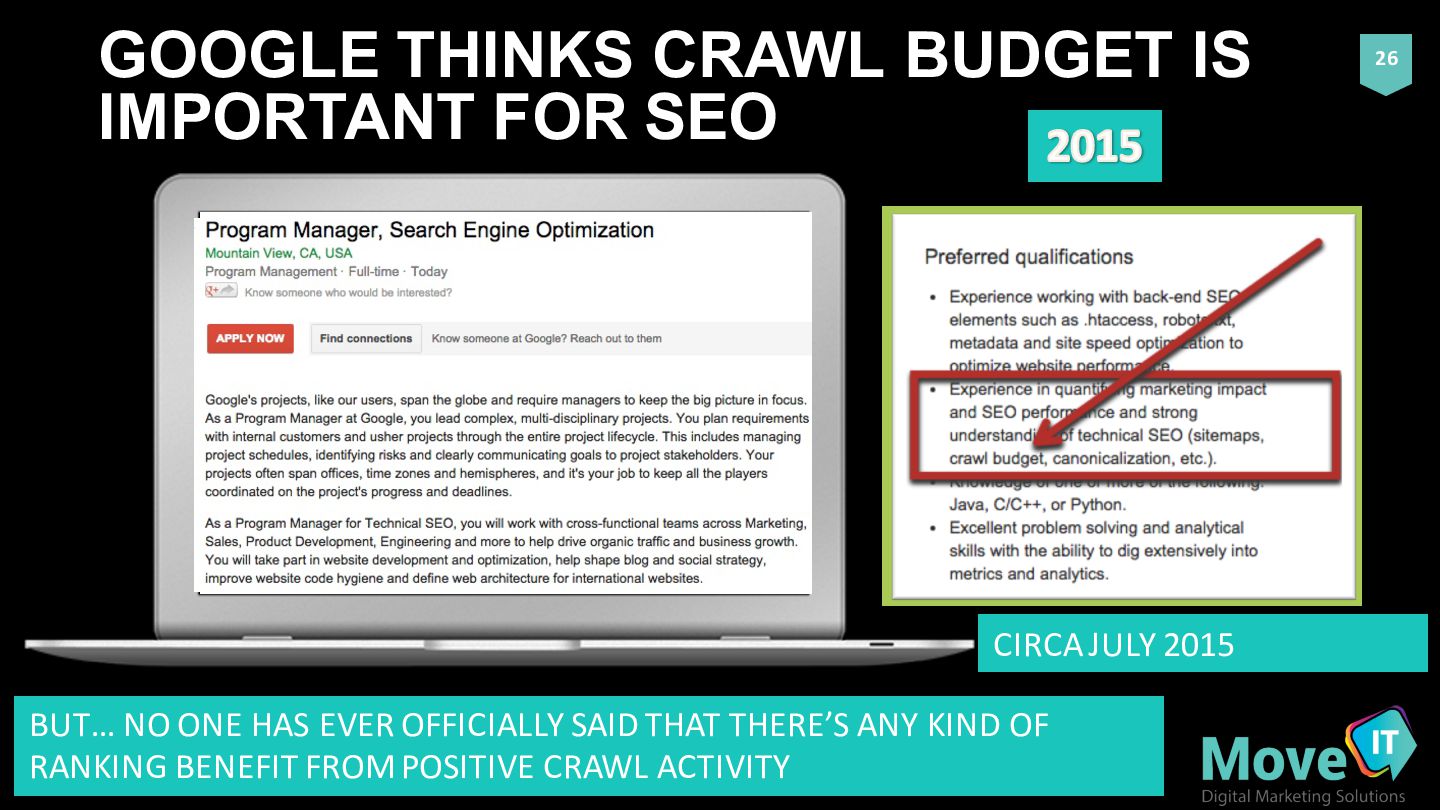
(E.G. ON PARAMETERS) FULL TRANSCRIPT -‐ https://www.stonetemple.com/matt-‐cutts-‐interviewed-‐by-‐eric-‐enge-‐2/ THIS WAS IN THE ORIGINAL INTERVIEW WITH MATT CUTTS ALSO LOTS OF THE PATENTS MENTION “PAGE IMPORTANCE (WHICH MAY INCLUDE PAGERANK)”
ON IMPORTANCE 13 “Thanks Bill” -‐ Waving J THIS REFERENCES THE PROBLEM OF THE SIZE OF THE WEB AND PRIORITIZES IMPORTANT PAGES Efficient Crawling Through URL Ordering Page et al
33 • Googlebot is also ‘hunting’… Hunting for relevant ‘needles’ in 1,000,000,000s of straws of ‘hay’ on the web • It’s about making your ‘one needle’ stand out in importance in not just your own site’s haystack, but tens of thousands of competing similar straws of hay in other site’s haystacks… (DON’T JUST MAKE YOUR HAYSTACK BIGGER) “Hey, you Googlebot… This is the needle” via architectural internal linking without blur of duplication or too many redirects or canonicalization
consistently indicate via clean internal individual URL importance emphasis, the importance of your URLs, how will Googlebot know which are the most important?”
URL IMPORTANCE FROM YOUR OWN SITE) THESE ARE YOUR ‘VOTES’ TO GOOGLEBOT ON THE IMPORTANCE OF EACH URL EMPLOY ‘CONSISTENT’ INTERNAL LINK STRATEGIES THINK OF THESE AS ‘WALL-‐TIES’ HOLDING YOUR BUILDING (SITE ARCHITECTURE) TOGETHER STOP VOTING FOR THE WRONG URLS FROM WITHIN YOUR OWN SITE. WRONG TARGETS RANKING?… CHECK INTERNAL LINKS From Google Support Pages Consistent internal & external emphasis of a URLs ’IMPORTANCE’
SPIDER TRAPS (INFINITE LOOPS), INDIVIDUAL URLS VISITED LESS AND LESS FREQUENTLY BECAUSE THERE’S TOO MANY) BUT IS THERE PERHAPS AN OPPOSITE OF ‘CRAWL RANK’? - ’CRAWL TANK’?? IS THERE ADVERSE EFFECT WHEN CRAWLING GOES BAD?
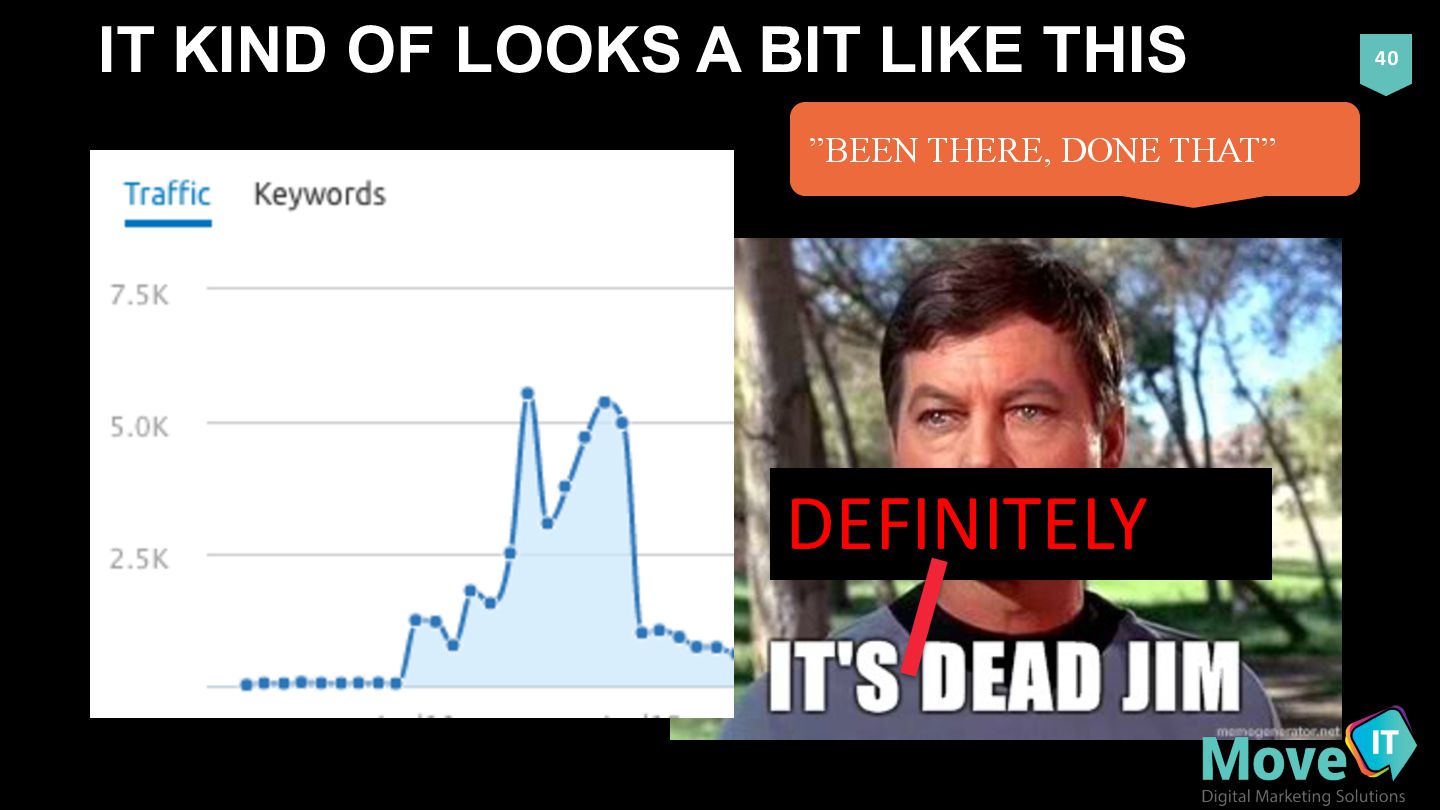
39 SITE SEO DEATH BY TOO MANY URLS AND INSUFFICIENT CRAWL BUDGET TO SUPPORT (EITHER DUMPING A NEW THIN PARAMETER INTO A SITE OR INFINITE LOOP (CODING ERROR) (SPIDER TRAP)) ”BEEN THERE, DONE THAT”
confirmed unimportant to queries with each iterative crawl visit to other similar or duplicate content checksum URLs? MULTPLE RANDOM URLs competing for same query confirm irrelevance of all competing in-‐site URLs with no dominant relevant IMPORTANT URL?
speed’ Logical structure Correct ‘response’ codes XML sitemaps ‘Successful crawl visits ‘Seeing everything’ on a page Taking ‘hints’ Clear unique single ‘URL fingerprints’ (no duplicates) Predicting likelihood of ‘future change’ Slow sites Too many redirects Being bored (Meh) (‘Hints’ are built in by the search engine systems – Takes ‘hints’) Being lied to (e.g. On XML sitemap priorities) Crawl traps and dead ends Going round in circles (Infinite loops) Spam URLs Crawl wasting minor content change URLs ‘Hidden’ and blocked content Uncrawlable URLs Duplicate URLs Not just any change Critical material change Predicting future change Dropping ‘hints’ to Googlebot Sending Googlebot Where ‘the action is’ 43 LIKES DISLIKES CHANGE IS KEY BASED ON DATA FROM THE HISTORY LOGS - CAN WE INFLUENCE VIA CRAWL OPTIMISATION TO ESCAPE THE ‘BASE LAYER HOME’ OF THE ’UNIMPORTANT’ URLS?
PERSONAL PROJECT – MY 20 IN 70: 20:10 MIX IT’S NOT MOBILE FRIENDLY OR HTTPS (HANGS HEAD IN SHAME), AND YES, IT NEEDS A MAKEOVER… BUT… TIME… , RESOURCES, BUDGET…BLAH BLAH THERE IS NO ‘BIG BRAND’ MARKETING, VC BACKING, TV OR RADIO ADS (LIKE COMPETITORS) – JUST ME -‐ ‘CHIPPING AWAY’ 90%+ OF TRAFFIC IS NON-‐BRANDED GENERIC ORGANIC
@johnmu during Webmaster Hangout https://goo.gl/1p ToL8 ARE THE URLS THAT YOU WANT BEING CRAWLED ‘REAL TIME’, DAILY OR INFREQUENTLY? (REGULAR LOG ANALYSIS AND INTERVENTION TO EMPHASISE IMPORTANCE) MY THOUGHTS (DA) -‐ You need to find out which ones are getting crawled in the ‘real time’ schedule, the ‘daily crawl’ schedule and via random selection in the ‘dross’ (or UNLIKELY TO CHANGE A LOT / UNIMPORTANT) ‘base layer’ section. If it’s not the URLs that you want to be there, then formulate a plan to improve the ‘importance’ of URLS. (NOTE: JOHN DID NOT SAY THIS)
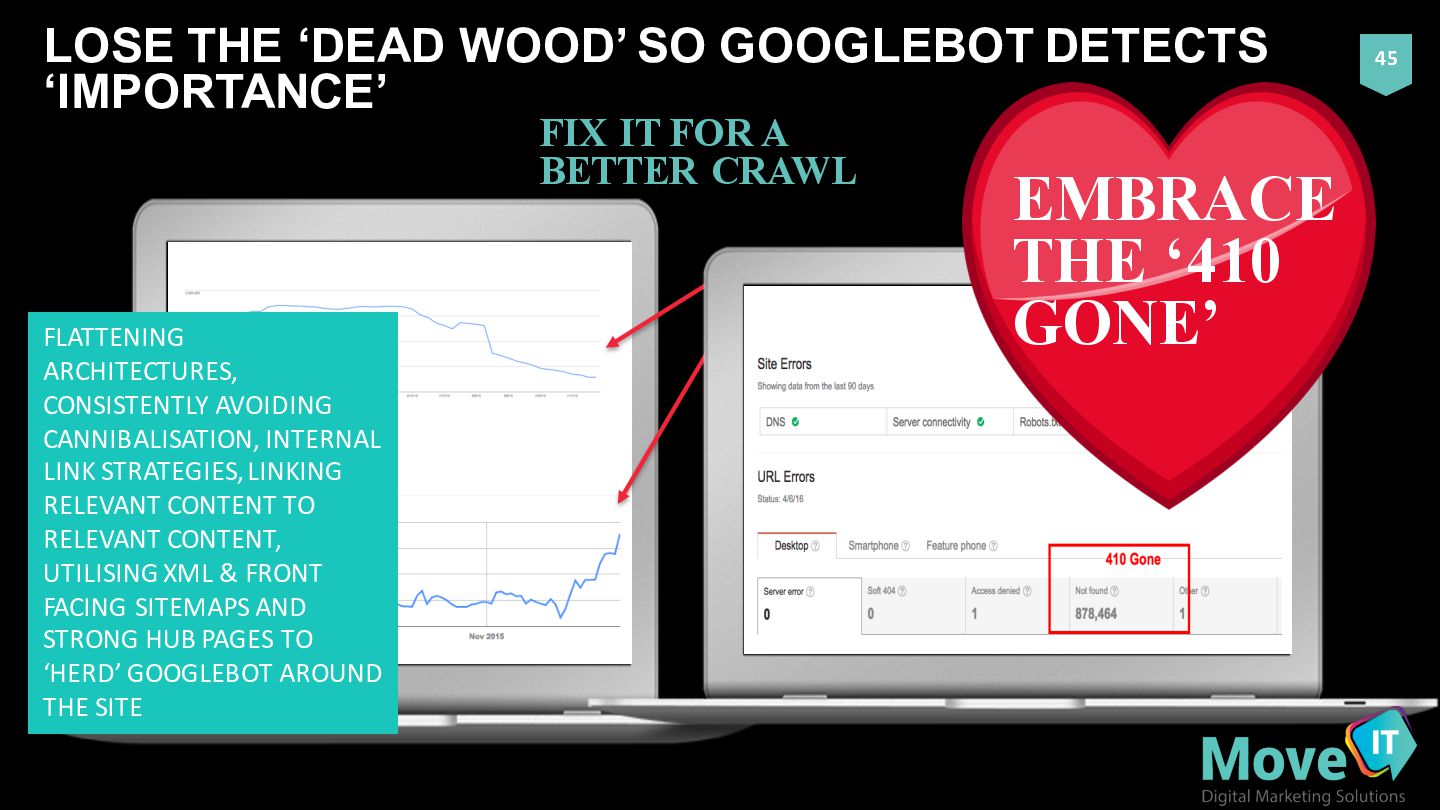
IT FOR A BETTER CRAWL EMBRACE THE ‘410 GONE’ FLATTENING ARCHITECTURES, CONSISTENTLY AVOIDING CANNIBALISATION, INTERNAL LINK STRATEGIES, LINKING RELEVANT CONTENT TO RELEVANT CONTENT, UTILISING XML & FRONT FACING SITEMAPS AND STRONG HUB PAGES TO ‘HERD’ GOOGLEBOT AROUND THE SITE
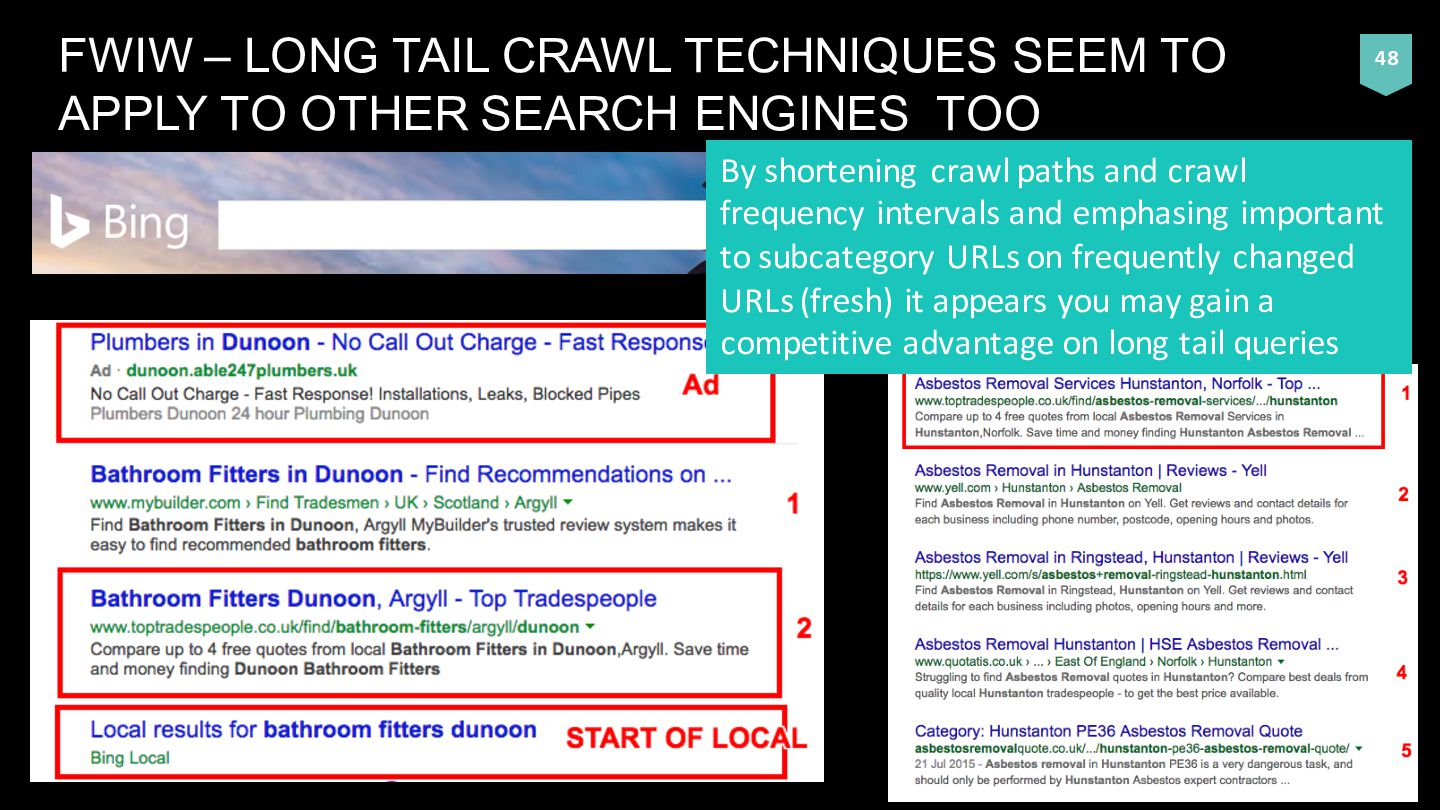
TO OTHER SEARCH ENGINES TOO By shortening crawl paths and crawl frequency intervals and emphasing important to subcategory URLs on frequently changed URLs (fresh) it appears you may gain a competitive advantage on long tail queries
COMPLEX TO ANSWER WITH A SIMPLE FEW EXAMPLES OF COURSE (TOO MANY FACTORS) – BUT… FOOD FOR THOUGHT ‘CRITICAL MATERIAL CHANGE FREQUENCY’ (FRESHNESS) AND DETECTED URL IMPORTANCE EMPHASIS VIA EXTERNAL OR INTERNAL SIGNALS (INC PAGERANK) SEEM KEY IS IT ‘CRAWL RANK’ OR ‘EMPHASING URL IMPORTANCE’ BETTER THAN COMPETITORS EMPHASE IMPORTANCE OF LOW TO NO PAGERANK PAGES WHERE FEW OTHER FACTORS SEPARATE?
IT APPEARS TO BE APPORTIONED BY THE URL SCHEDULER (BUDGET) 2. PAGES WITH A LOT OF (HEALTHY??) LINKS GET CRAWLED MORE (EXTERNAL AND INTERNAL?) (BUDGET AND RANK?) 3. THERE ARE URL EXCLUSIONS – ( ’HINT TRIPPERS’, OBJECTIONABLE CONTENT AND ‘SPAM URLS’?? ) (BUDGET) 4 – ‘CRITICAL MATERIAL CHANGE’ (FRESHNESS) AND THE PROBABILITY AND PREDICTABILITY OF CHANGE CORRELATE (BUDGET) 5 –’CONSISTENT’ EMPHASIS OF URL IMPORTANCE(BUT I THINK THAT THIS WAS ALWAYS THERE) MAY BE ’CRAWL RANK’(BUDGET AND RANK??) ’CRAWL RANK’ -‐ IS IT CORRELATION OR CAUSATION? (DO IMPORTANT PAGES GET CRAWLED MORE, OR IS IT BECAUSE THEY ARE CRAWLED MORE THEY ARE IMPORTANT?)
INDICATING YOU ARE STILL ON TRACK? BECAUSE -‐ BRINGING A ROCKET BACK ON COURSE IS ‘CHALLENGING’ REGULAR TESTS AND EARLY DIAGNOSIS ARE CRUCIAL – STOP, CHECK AND KEEP CHECKING ‘TANK’ OR ‘RANK’? – YOU DECIDE
8042112 B1, (Zhu et al) -‐ https://www.google.com/patents/US8707313 Managing items in crawl schedule – Google Patent (Alpert) http://www.google.ch/patents/US8666964 Document reuse in a search engine crawler -‐ Google Patent (Zhu et al) https://www.google.com/patents/US8707312 Web crawler scheduler that utilizes sitemaps (Brawer et al) -‐ http://www.google.com/patents/US8037054 Distributed crawling of hyperlinked documents (Dean et al) -‐ http://www.google.co.uk/patents/US7305610 Minimizing visibility of stale content (Carver) -‐ http://www.google.ch/patents/US20130226897
http://oak.cs.ucla.edu/~cho/papers/cho-‐order.pdf Crawl Optimisation (Blind Five Year Old – A J Kohn -‐ @ajkohn) http://www.blindfiveyearold.com/crawl-‐ optimization Scheduling a recrawl (Auerbach) -‐ http://www.google.co.uk/patents/US8386459 Scheduler for search engine crawler (Zhu et al) -‐ http://www.google.co.uk/patents/US8042112 Efficient crawling through URL ordering (Page et al) -‐ http://oak.cs.ucla.edu/~cho/papers/cho-‐order.pdf Google Explains Why The Search Console Reporting Is Not Real Time (SERoundtable) https://www.seroundtable.com/google-‐explains-‐why-‐the-‐search-‐console-‐has-‐reporting-‐delays-‐21688.html Crawl Data Aggregation Propagation (Mueller) -‐ https://goo.gl/1pToL8 Matt Cutts Interviewed By Eric Enge -‐ https://www.stonetemple.com/matt-‐cutts-‐interviewed-‐by-‐eric-‐enge-‐ 2/ Web Promo Q and A with Google’s Andrev Lippatsev -‐ https://searchenginewatch.com/2016/04/06/webpromos-‐qa-‐with-‐googles-‐andrey-‐lipattsev-‐transcript/ Google Number 1 SEO Advice – Be Consistent -‐ https://www.seroundtable.com/google-‐number-‐one-‐seo-‐ advice-‐be-‐consistent-‐21196.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}