Scheduling stuff sounds like a pretty straight forward thing to do, doesn’t it? Simply set up a cron with a schedule (after looking at the cron syntax online, of course), tell it what to do and forget about it.
Well, if you have ever worked with scheduling systems, you know that isn’t the end of the story. Monitoring, failure isloation, retries, choking preventions, etc. make sure you think about that 5 AM job in your sleep.
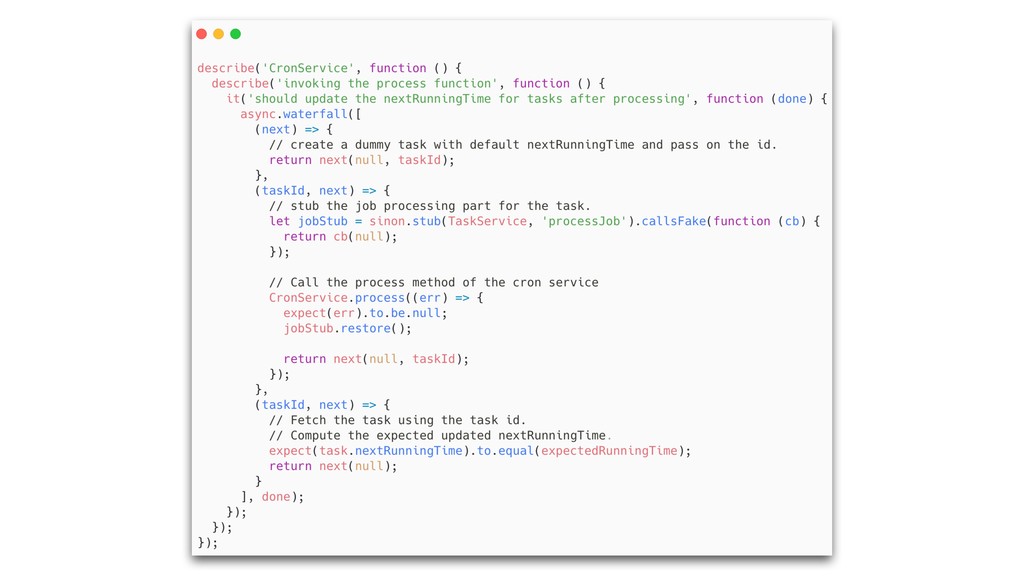
Idempotency can help - slightly. This talk tries to encapsulate some of my learnings building a distributed scheduler in Node, some of the pain points I faced and how embracing idempotency helped relieve some of those pains.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
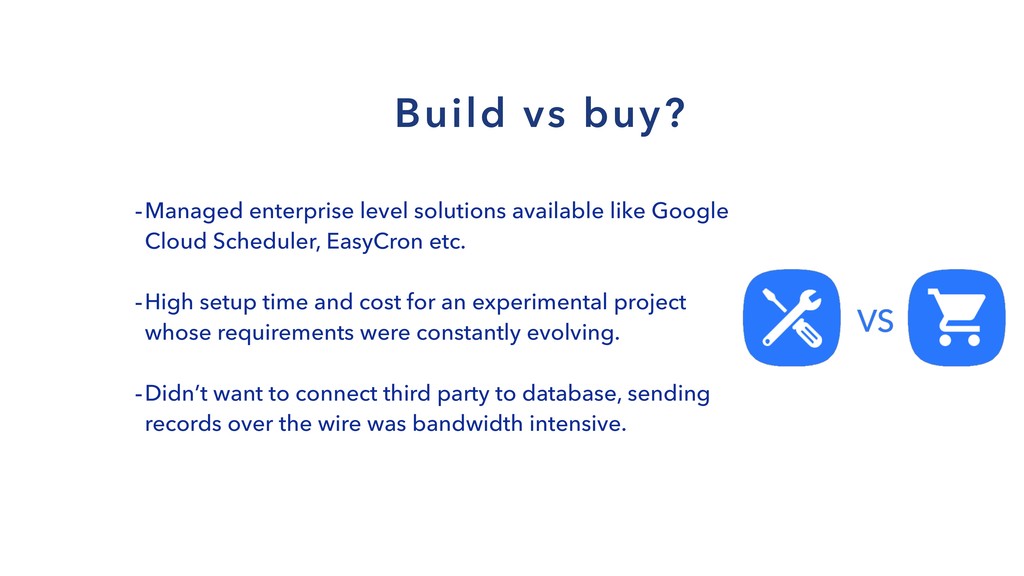{kind=link}
{kind=link}
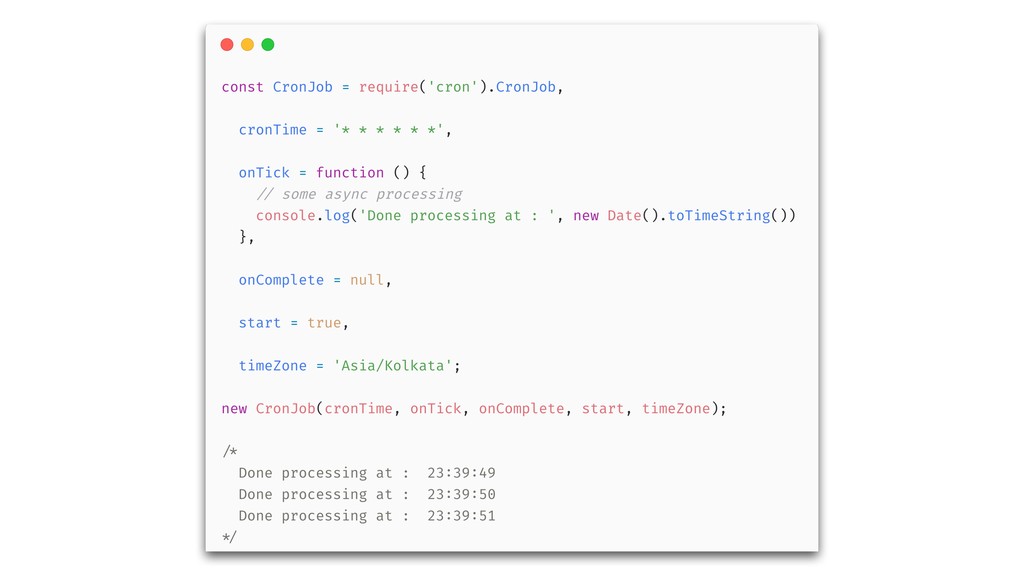{kind=link}
{kind=link}
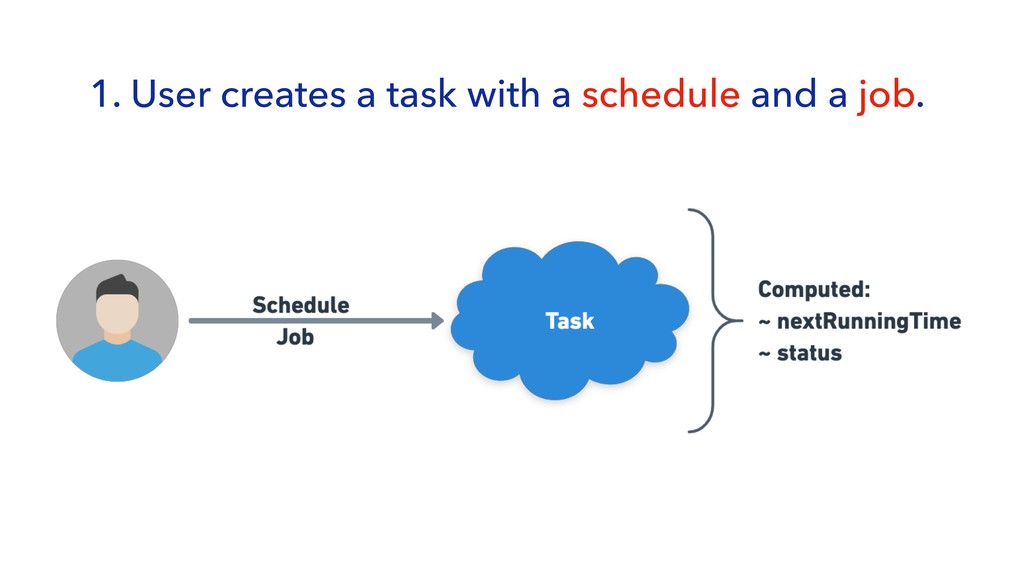{kind=link}
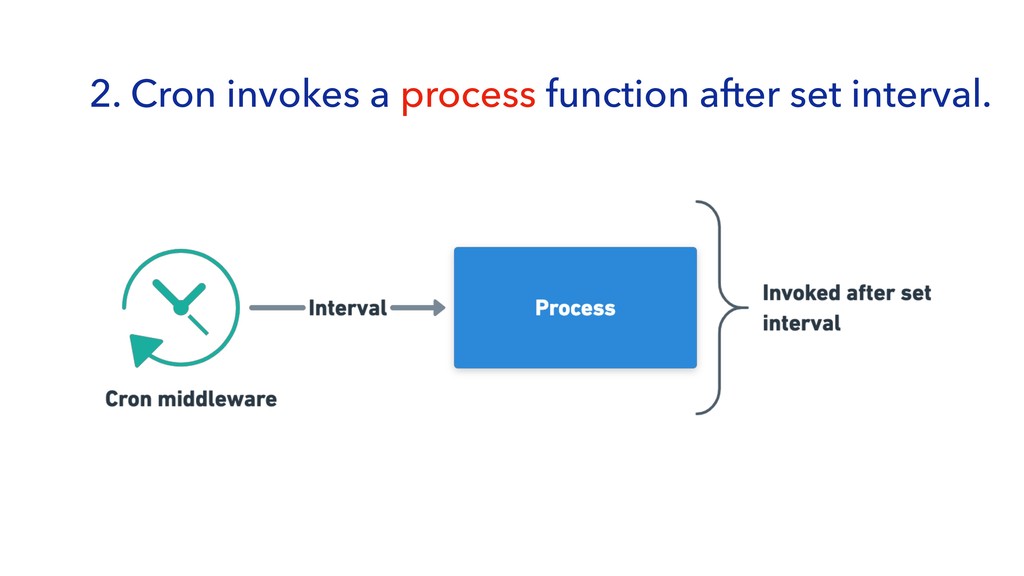{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}