Storing blobs (ex. binary images) • Storing keys size > value data size (sometimes) • Serving between 100Kqps to 2.5Mqps per cluster • Low latency at 99perc < 2ms • Data size per cluster between 500Gb to ~12Tb (with replica) • All data fits in memory • Inter datacenter replication (custom client driver)
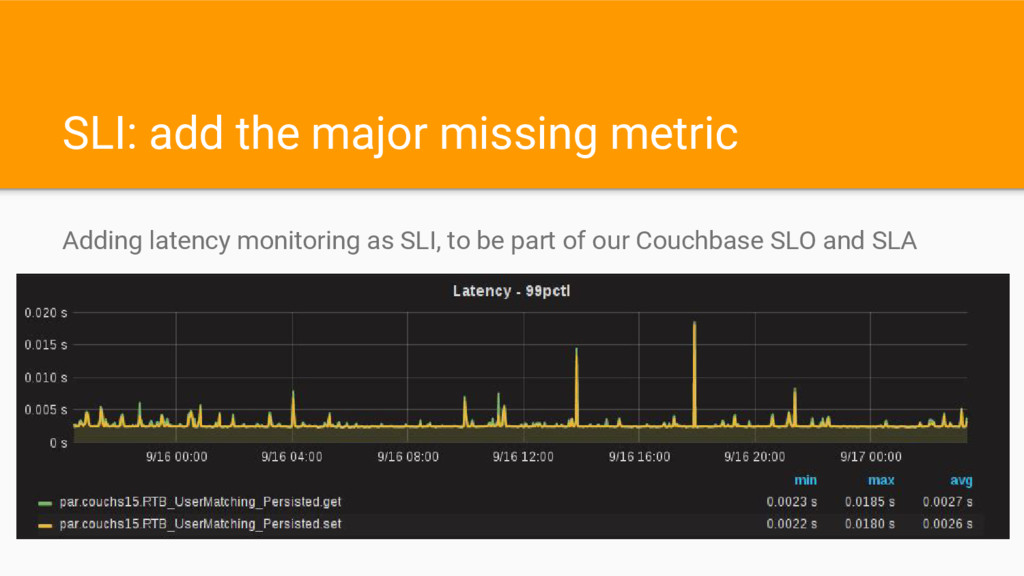
persisted buckets • No dedicated latency monitoring tool • No auto restart/upgrade orchestrator • Server benchmarks update required • Lack of Couchbase best practices
(256GB RAM, 6x400GB SSD RAID10, 1Gb Network interface) (2x injectors + 1 server) • Key size: UUID string (36 bytes) + Couchbase metadata (56 bytes) • Value size: uniform range between 750 B and 1250 B (avg 1 kB) • Number of items: 50M/node (with replica) or 100M/node (without replica) • Resident active items (= items fully in RAM): ~50% • Value-only ejection mode (only data value can be removed from RAM, keeping metadata + key in RAM).
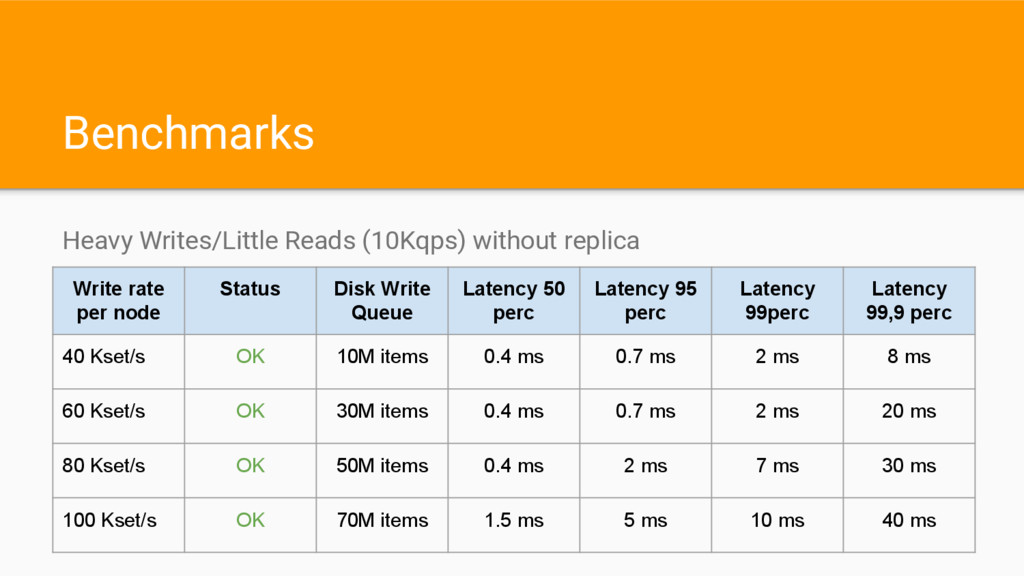
node Status Disk Write Queue Latency 50 perc Latency 95 perc Latency 99perc Latency 99,9 perc 40 Kset/s OK 10M items 0.4 ms 0.7 ms 2 ms 8 ms 60 Kset/s OK 30M items 0.4 ms 0.7 ms 2 ms 20 ms 80 Kset/s OK 50M items 0.4 ms 2 ms 7 ms 30 ms 100 Kset/s OK 70M items 1.5 ms 5 ms 10 ms 40 ms
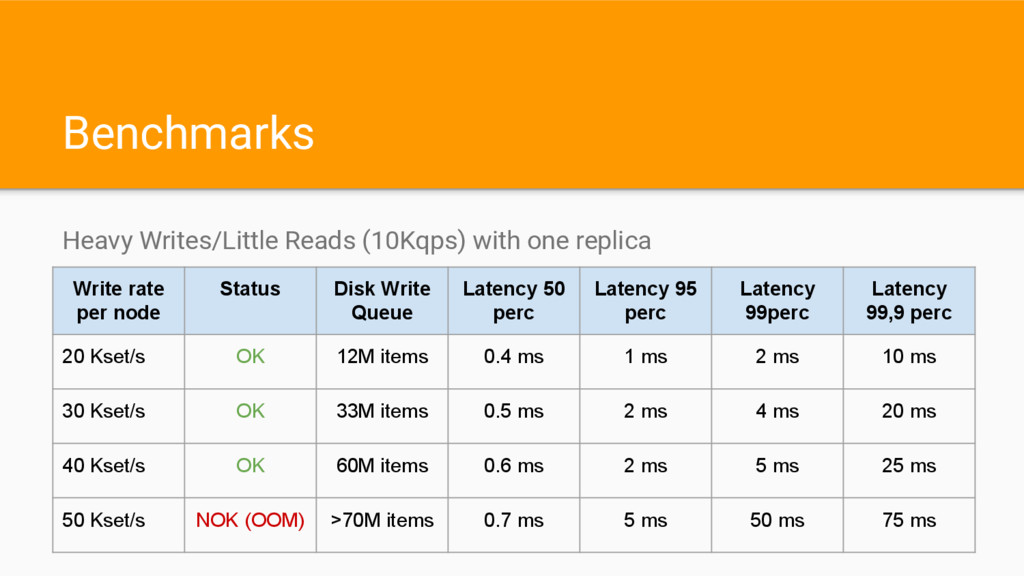
per node Status Disk Write Queue Latency 50 perc Latency 95 perc Latency 99perc Latency 99,9 perc 20 Kset/s OK 12M items 0.4 ms 1 ms 2 ms 10 ms 30 Kset/s OK 33M items 0.5 ms 2 ms 4 ms 20 ms 40 Kset/s OK 60M items 0.6 ms 2 ms 5 ms 25 ms 50 Kset/s NOK (OOM) >70M items 0.7 ms 5 ms 50 ms 75 ms
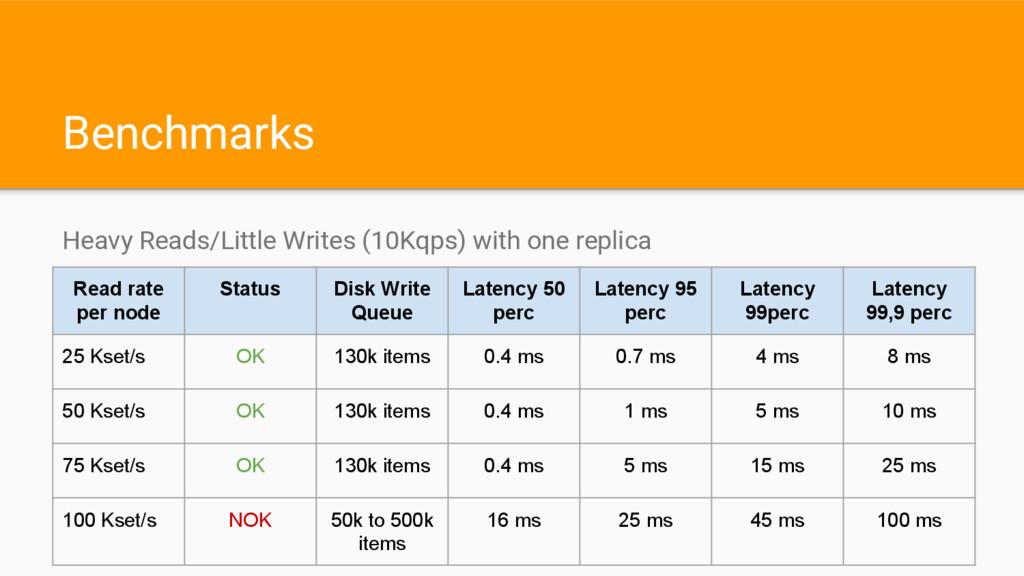
per node Status Disk Write Queue Latency 50 perc Latency 95 perc Latency 99perc Latency 99,9 perc 25 Kset/s OK 130k items 0.4 ms 0.7 ms 4 ms 8 ms 50 Kset/s OK 130k items 0.4 ms 1 ms 5 ms 10 ms 75 Kset/s OK 130k items 0.4 ms 5 ms 15 ms 25 ms 100 Kset/s NOK 50k to 500k items 16 ms 25 ms 45 ms 100 ms
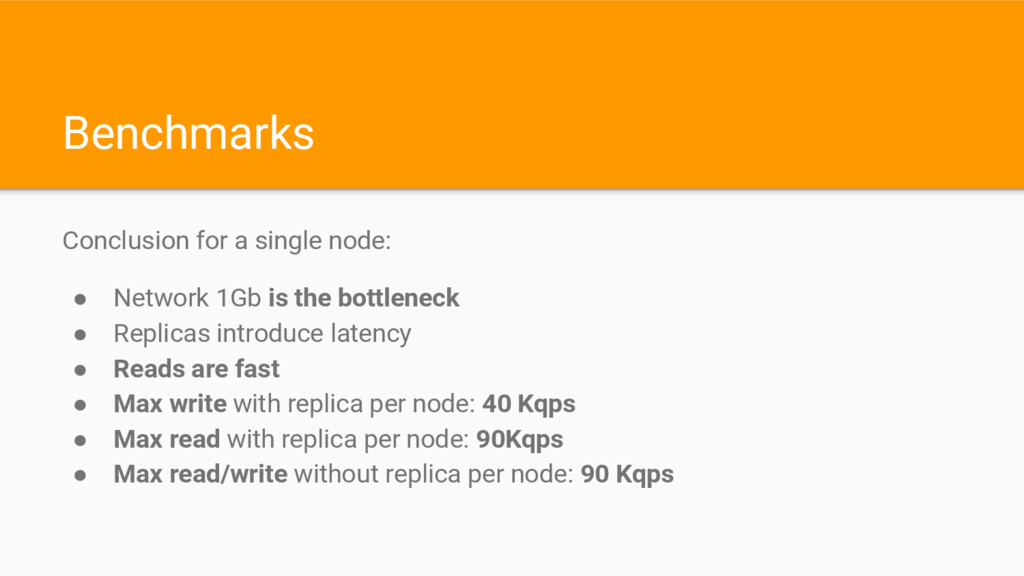
the bottleneck • Replicas introduce latency • Reads are fast • Max write with replica per node: 40 Kqps • Max read with replica per node: 90Kqps • Max read/write without replica per node: 90 Kqps
the enterprise version • Need to apply new configuration options that require a restart of all the nodes in a cluster • Need to apply fixes that require a reboot of all the nodes in a cluster • Need to reinstall servers from scratch
deploy applications and configuration • We did not want to add another new tool in the loop • Nothing with the required features already exists • We developed a FOSS Chef cookbook for this and other use-cases: Choregraphie https://github.com/criteo-cookbooks/choregraphie
with rebalance • Rolling upgrade with rebalance • Use an optional, additional server to speed up rebalance • Rolling reboot with rebalance • Rolling reinstall with rebalance Choregraphie is open source! Feel free to contribute
• 10Gb network cards • Upgrade to Couchbase 4.5 • Upgrade kernel to a newer LTS vanilla to enable specific SSD enhancement (multi queues SSD) • Switch to Mesos to reduce administration time
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}