CC BY 4.0 PLATFORM ENGINEERING MEETS AI AT SCALE Our AI Agents Are Finally In Production — And Now What? Building, Deploying & Running Agentic AI Platforms at Scale 5 agents? 500 agents? 5,000 agents? ship it!
CC BY 4.0 AGENDA ✎ What We'll Cover Today 01 Agents as Containers scalable · reliable · observable 02 Agent Evaluation development & production evals 03 AI Agent Skills Pipelines SkillOps gentle introduction 04 Agent Observability what's unique to AI agents 05 Agent Throttling rate limiting specifics for AI agents
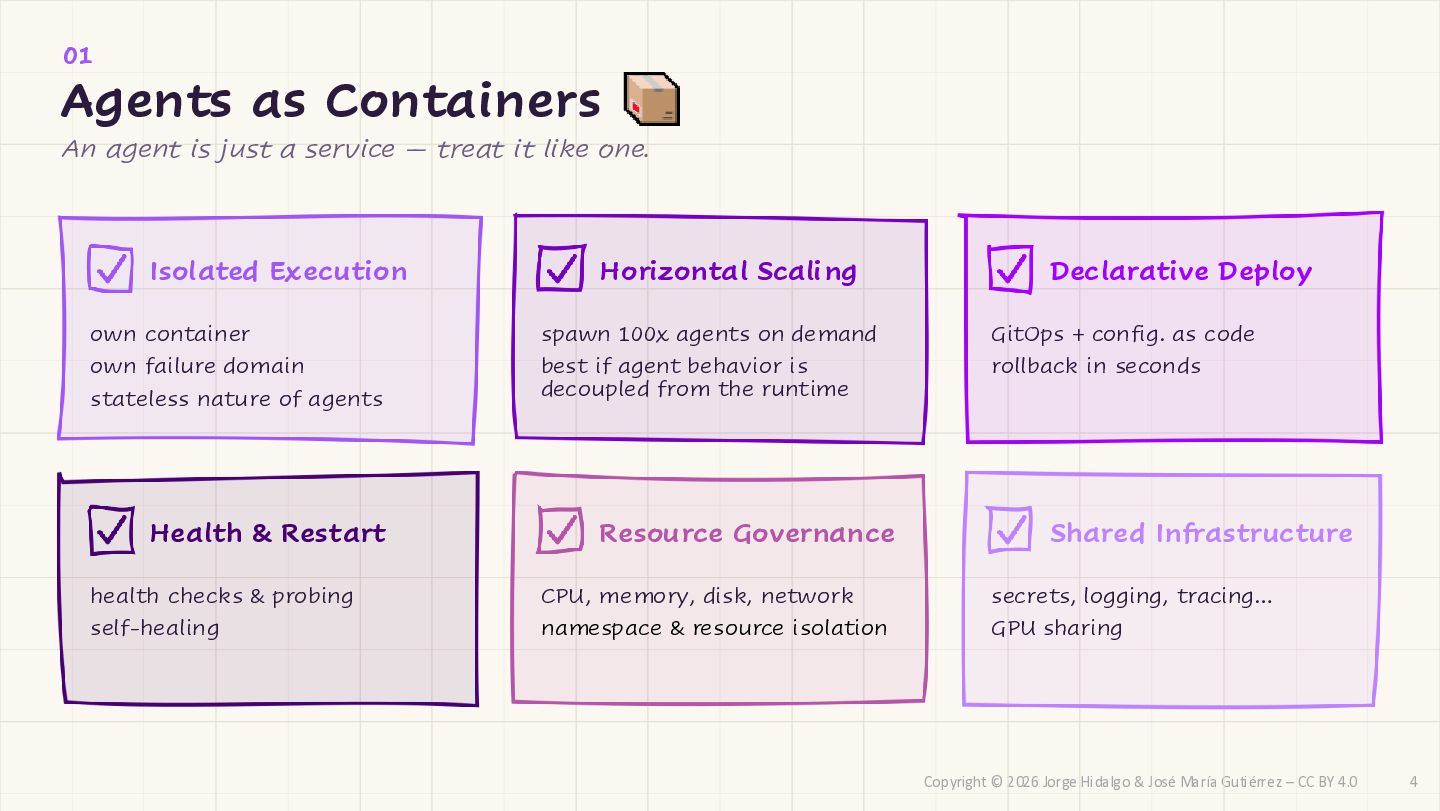
CC BY 4.0 01 Agents as Containers An agent is just a service — treat it like one. Isolated Execution own container own failure domain Horizontal Scaling spawn 100x agents on demand best if agent behavior is decoupled from the runtime Declarative Deploy GitOps + config. as code rollback in seconds Health & Restart health checks & probing self-healing Resource Governance CPU, memory, disk, network namespace & resource isolation Shared Infrastructure secrets, logging, tracing… GPU sharing stateless nature of agents 4
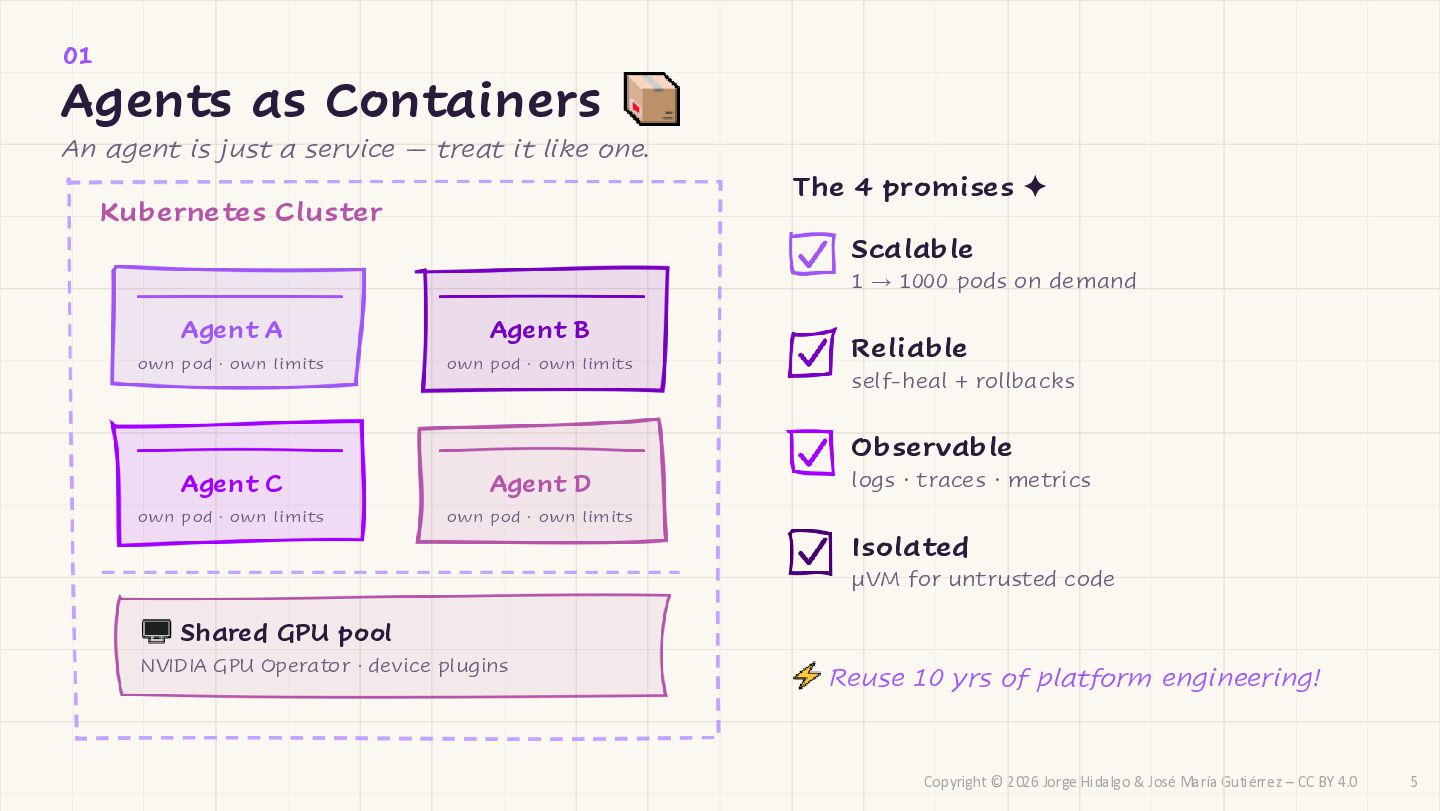
CC BY 4.0 Kubernetes Cluster Agent A own pod · own limits Agent B own pod · own limits Agent C own pod · own limits Agent D own pod · own limits Shared GPU pool NVIDIA GPU Operator · device plugins The 4 promises ✦ Scalable 1 → 1000 pods on demand Reliable self-heal + rollbacks Observable logs · traces · metrics Isolated µVM for untrusted code Reuse 10 yrs of platform engineering! 01 Agents as Containers An agent is just a service — treat it like one. 5
CC BY 4.0 Isolation spectrum 🪜 Plain containers trusted code · fastest · shared kernel Google gVisor user-space kernel · medium isolation Kata / Firecracker µVMs untrusted code · HW boundary · ~200ms default to µVMs for untrusted code; relax only if safe The serving stack Nodes NVIDIA GPU Operator · GPU-aware sched Inference engine vLLM — attention algorithm, batching & queueing Serving layer Kserve (with llm-d) / KubeAI · OpenAI-compatible API Multi-model LiteLLM / Ray Serve · KubeRay on top for complex pipes Pipelines Kubeflow / Airflow / Argo / ZenML abstraction 01 · STATE OF THE ART Agents as Containers The 2025–26 frontier: Isolation = a threat-model choice. GPUs are first-class. 6
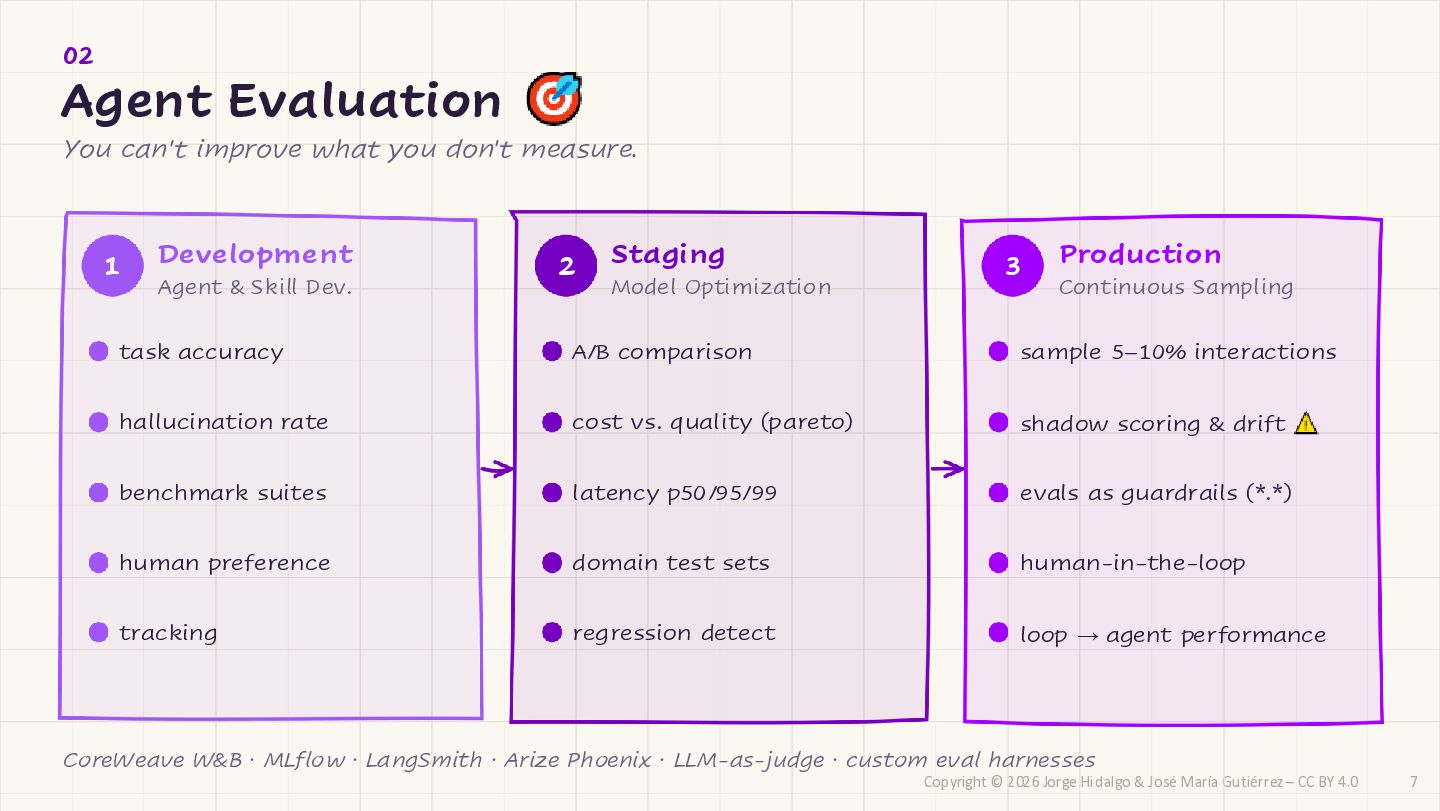
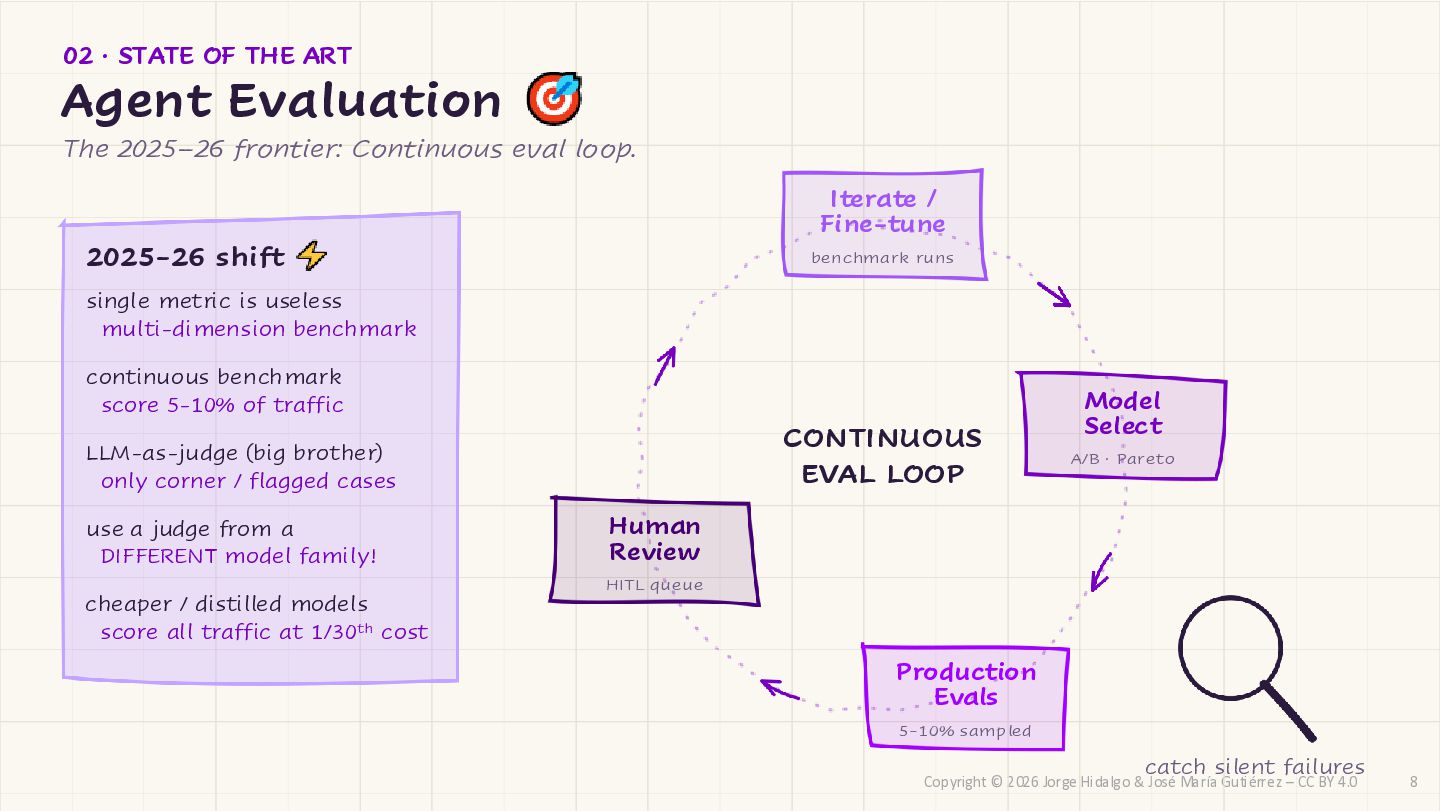
CC BY 4.0 CONTINUOUS EVAL LOOP Iterate / Fine-tune benchmark runs Model Select A/B · Pareto Production Evals 5-10% sampled Human Review HITL queue 2025-26 shift single metric is useless multi-dimension benchmark continuous benchmark score 5-10% of traffic LLM-as-judge (big brother) only corner / flagged cases use a judge from a DIFFERENT model family! catch silent failures cheaper / distilled models score all traffic at 1/30th cost 02 · STATE OF THE ART Agent Evaluation The 2025–26 frontier: Continuous eval loop. 8
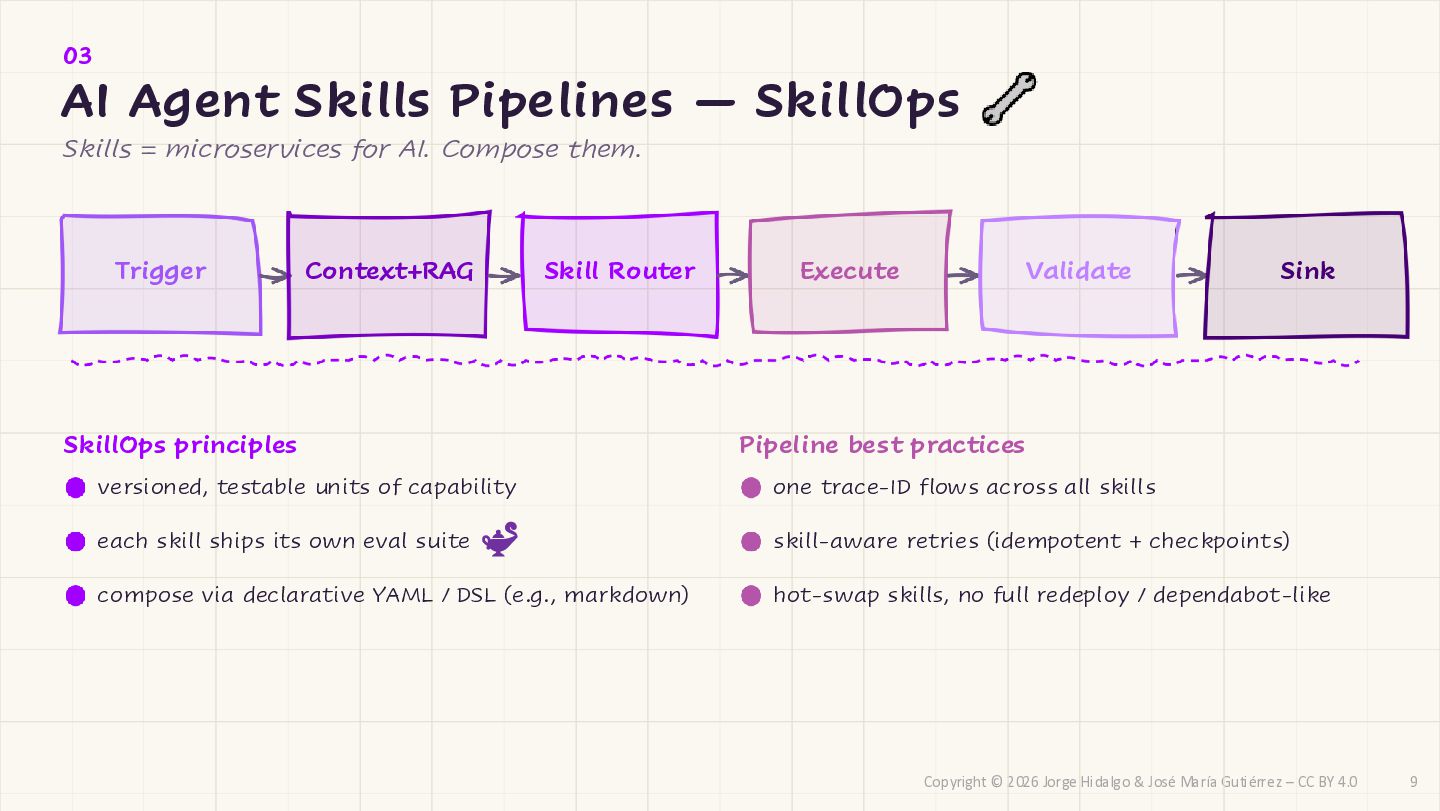
CC BY 4.0 03 AI Agent Skills Pipelines — SkillOps Skills = microservices for AI. Compose them. Trigger Context+RAG Skill Router Execute Validate Sink SkillOps principles versioned, testable units of capability each skill ships its own eval suite compose via declarative YAML / DSL (e.g., markdown) Pipeline best practices one trace-ID flows across all skills skill-aware retries (idempotent + checkpoints) hot-swap skills, no full redeploy / dependabot-like 9
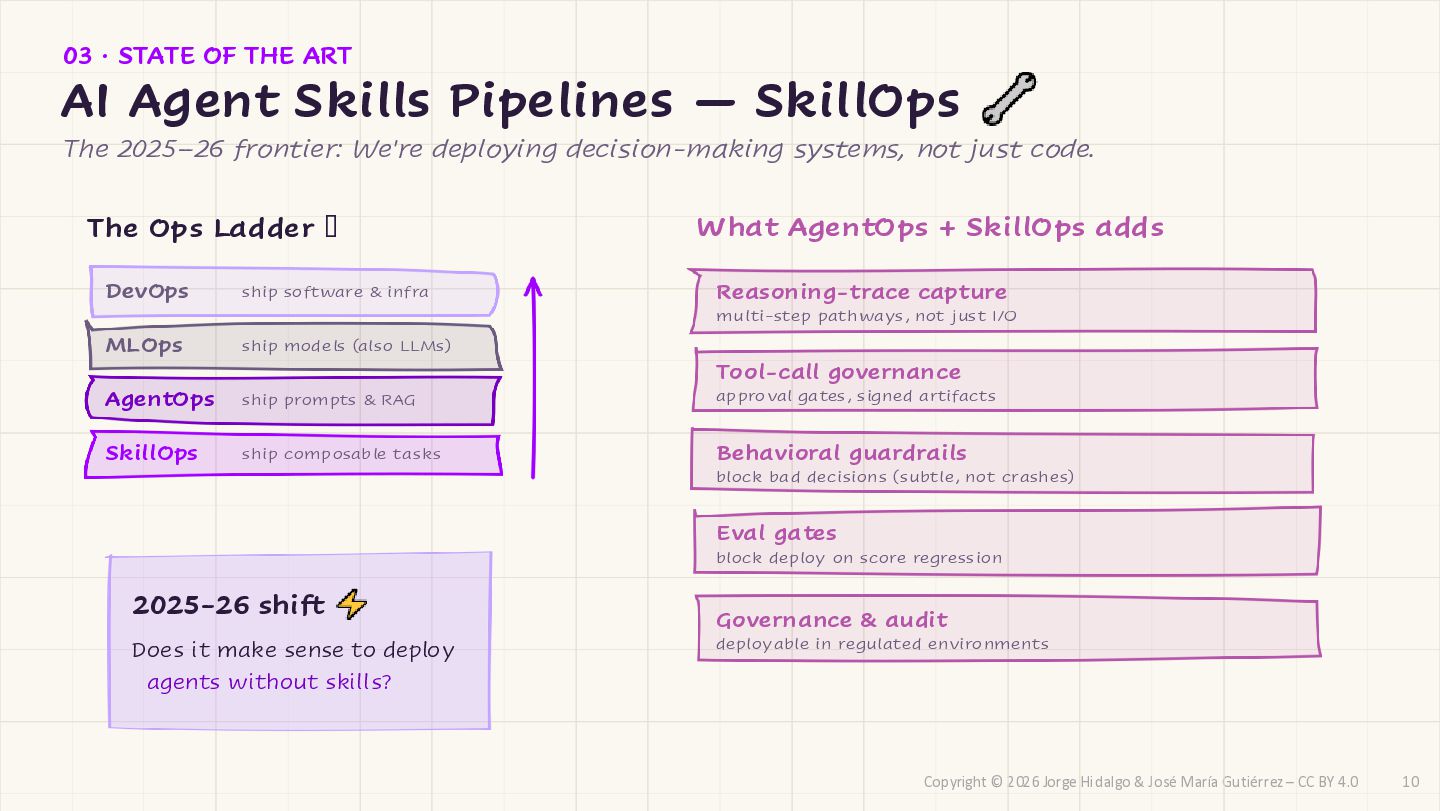
CC BY 4.0 What AgentOps + SkillOps adds Reasoning-trace capture multi-step pathways, not just I/O Tool-call governance approval gates, signed artifacts Behavioral guardrails block bad decisions (subtle, not crashes) Eval gates block deploy on score regression Governance & audit deployable in regulated environments The Ops Ladder 🪜 DevOps ship software & infra MLOps ship models (also LLMs) AgentOps ship prompts & RAG SkillOps ship composable tasks 2025-26 shift Does it make sense to deploy agents without skills? 03 · STATE OF THE ART AI Agent Skills Pipelines — SkillOps The 2025–26 frontier: We're deploying decision-making systems, not just code. 10
CC BY 4.0 A trace = nested spans invoke_agent chat: model call execute_tool: search() execute_tool: db.query() chat: synthesis / validation OpenTelemetry GenAI conventions with standard gen_ai.* attributes Signals ‘classic’ APM misses 🪙 tokens in / out $ per inference prompt version semantic drift tool success % ctx. exhaustion Why Agent Observability matters same prompt may have different outputs cost scales with tokens not requests external reputation is very sensitive to semantic drift, bias, toxicity, completeness, accuracy, etc. MCP tool-call tracing layer (e.g., external system call) 04 AI Agent Observability Agents fail by looking like success. (see next slide) retrieval 12
CC BY 4.0 https://github.com/open-telemetry/semantic-conventions-genai/blob/main/docs/gen-ai/README.md 5+1 groups of signals of gen_ai.* Events prompts/completions (input/output) Exceptions API error, rate limiting, model errors Metrics token usage, TTFT (latency), duration Model Spans Inference, embeddings, retrievals, memory Agent Spans invoke agent, update memory, exec. tool MCP context propagation, operations, sessions In practice Auto-instrumentation exists drop-in with OTel packages / OpenLLMetry Still ‘in development' status “here be dragons” Don't store prompts in attributes storage bill + PII risk Overhead negligible but overhead varies async batch <1% but LLM calls take seconds 04 · STATE OF THE ART AI Agent Observability The 2025–26 frontier: OpenTelemetry GenAI – the open standard. + conventions for Anthropic, Azure AI, AWS Bedrock and OpenAI Semantic ‘signals’ are not covered configure your evals as metrics (e.g., W&B, Phoenix) 13
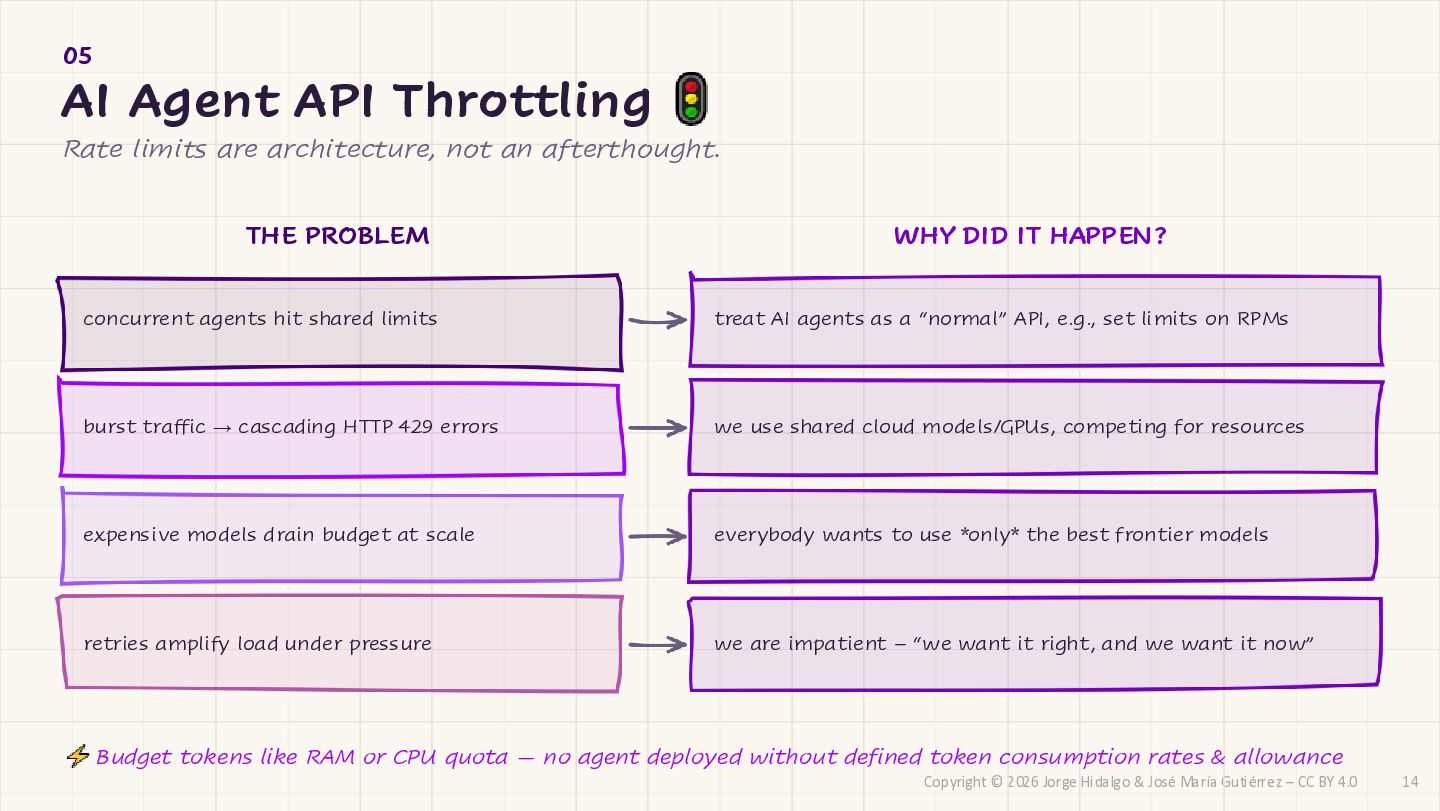
CC BY 4.0 05 AI Agent API Throttling Rate limits are architecture, not an afterthought. THE PROBLEM WHY DID IT HAPPEN? concurrent agents hit shared limits treat AI agents as a “normal” API, e.g., set limits on RPMs burst traffic → cascading HTTP 429 errors we use shared cloud models/GPUs, competing for resources expensive models drain budget at scale everybody wants to use *only* the best frontier models retries amplify load under pressure we are impatient – “we want it right, and we want it now” Budget tokens like RAM or CPU quota — no agent deployed without defined token consumption rates & allowance 14
CC BY 4.0 "The #1 incident: an agent that retries, and retries..." The 3-Layer AI Gateway L1 · Token Budgets & Hierarchical Quotas set limits on token-per-minute, not RPM · set quotas per team, user/customer, agent, model, etc. · set quotas around the clock L2 · Circuit Breaker trips on cost-velocity, weight-balancing, repeats, context growth · set rules for exponential back-off · set batches & wait queues L3 · Fallback Chain on 429s reroute for graceful degradation (Opus → Sonnet → Haiku → 503) · set multi-key/provider strategies · use cached responses 05 · STATE OF THE ART AI Agent API Throttling The 2025-26 frontier: Token-based limits & the AI gateway. Gateways: LiteLLM · Bifrost · Cloudflare · Kong AI · OpenRouter · Zuplo 15
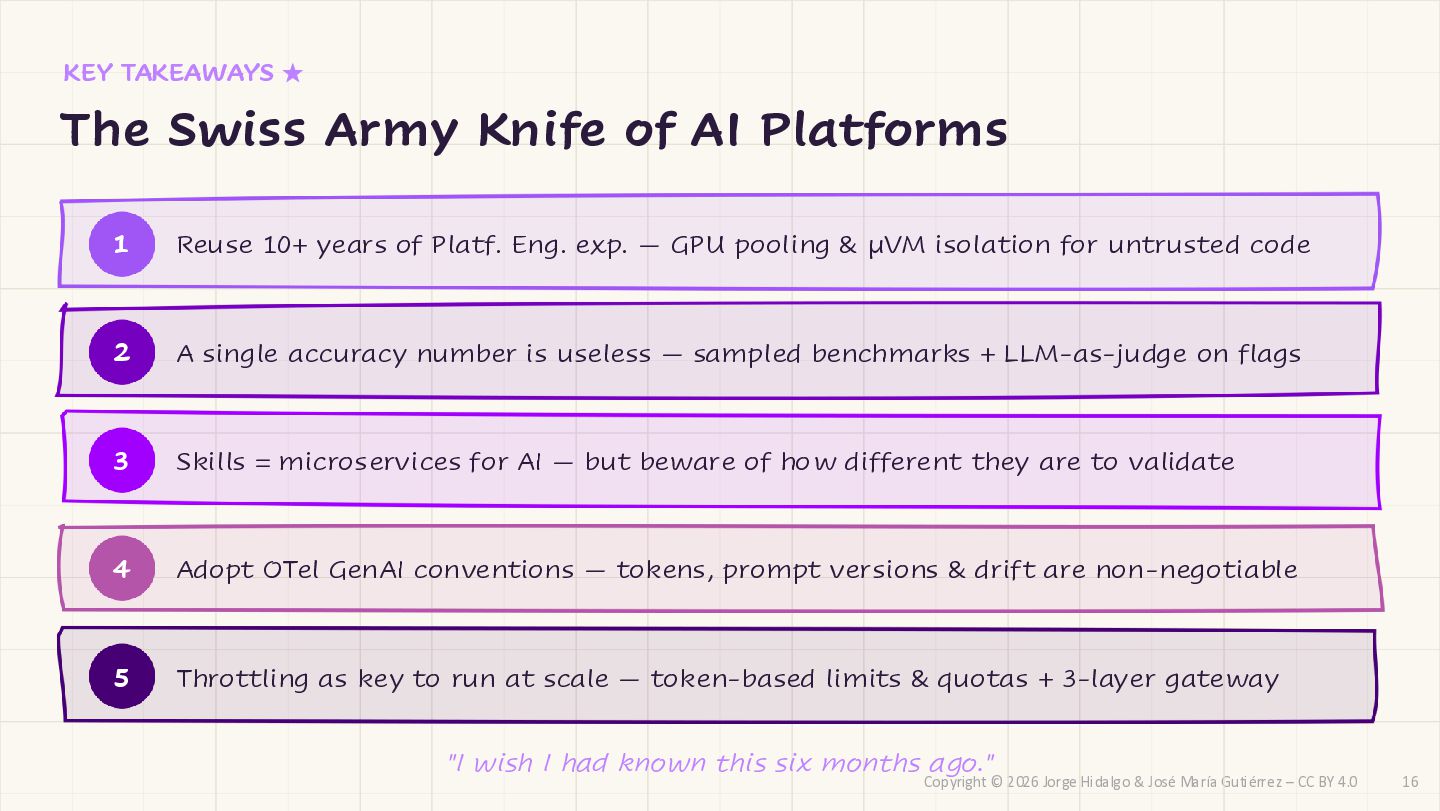
CC BY 4.0 KEY TAKEAWAYS ★ The Swiss Army Knife of AI Platforms 1 Reuse 10+ years of Platf. Eng. exp. — GPU pooling & µVM isolation for untrusted code 2 A single accuracy number is useless — sampled benchmarks + LLM-as-judge on flags 3 Skills = microservices for AI — but beware of how different they are to validate 4 Adopt OTel GenAI conventions — tokens, prompt versions & drift are non-negotiable 5 Throttling as key to run at scale — token-based limits & quotas + 3-layer gateway "I wish I had known this six months ago." 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}