Resilience vs. Chaos Engineering @ Codemotion Meetup en Accenture C85
Estas son las slides de la charla que realicé el pasado 12/12 sobre "ingeniería de la resiliencia y el caos" en nuestra fantástica oficina de Accenture C85, co-organizado con Codemotion.
Java Community of Practice co-lead Iberia Cloud First DevOps lead Advanced Technology Center Cloud First Architecture & Platforms lead Communities matter: coordinating MálagaJUG / Málaga Scala / BoquerónSec Father of two, husband, whistle player, video gamer, sci-fi *.*, Lego, Raspberry Pi, Star Wars, Star Trek, LOTR, Halo, Borderlands, Watch Dogs, Diablo, StarCraft, Black Desert,… LLAP! ABOUT ME @deors314 in/deors JORGE HIDALGO
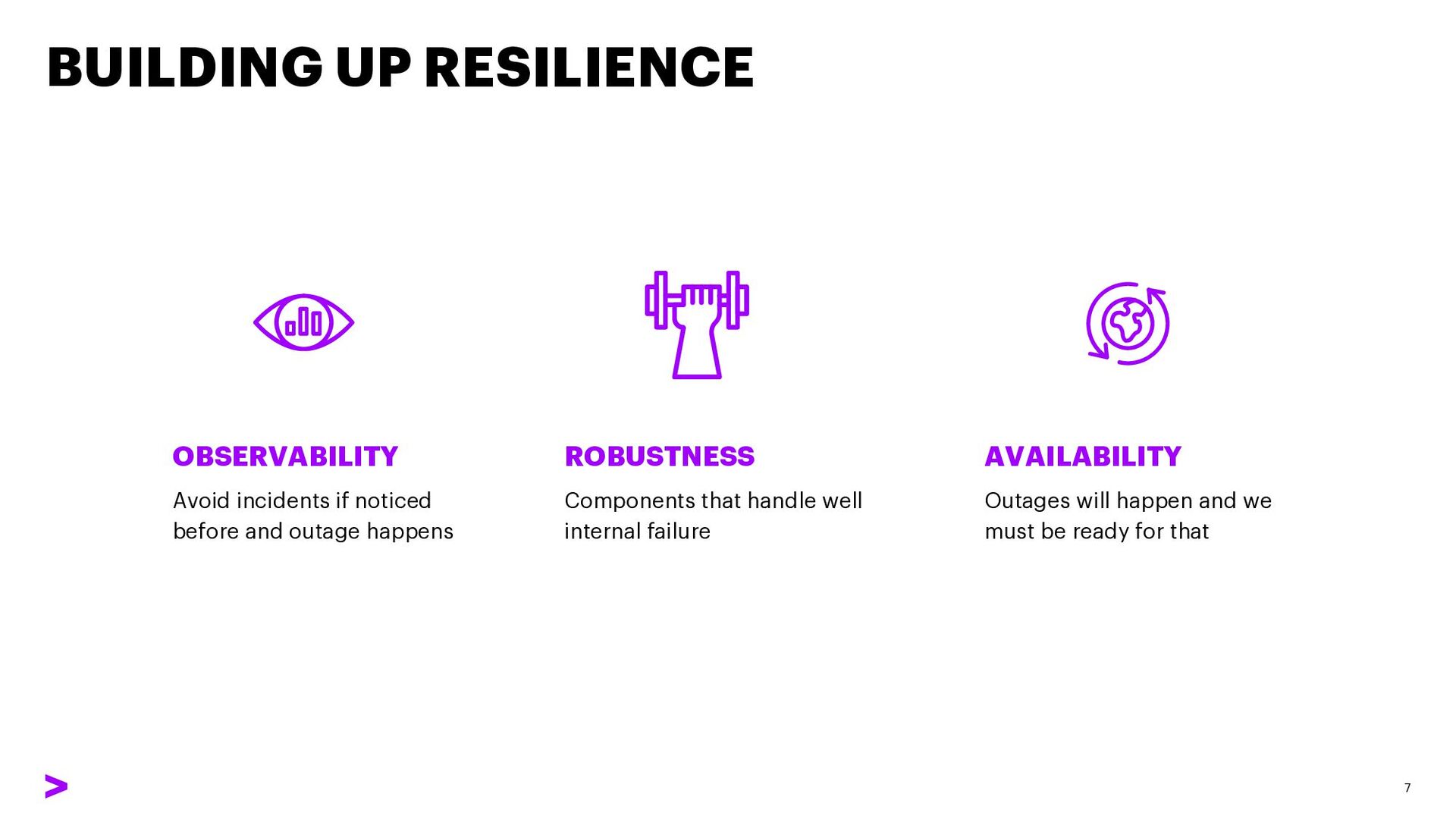
software-intensive systems is a must- have capability as failures become normal, and as such systems architecture design must be oriented towards the early identification of problems, mitigation and fast reaction to outages 4
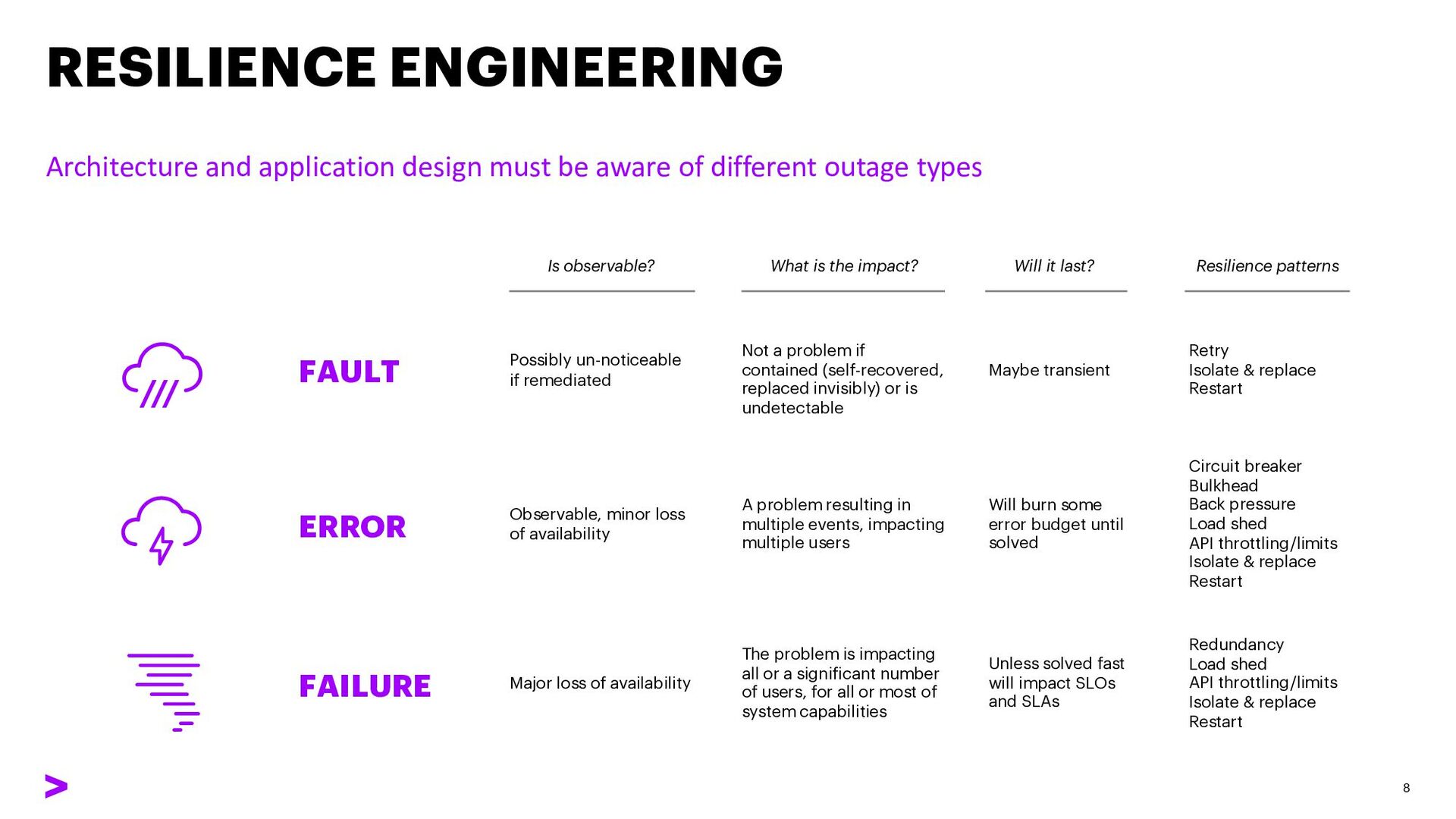
different outage types 8 Circuit breaker Bulkhead Back pressure Load shed API throttling/limits Isolate & replace Restart FAULT ERROR FAILURE Is observable? What is the impact? Will it last? Resilience patterns Possibly un-noticeable if remediated Observable, minor loss of availability Major loss of availability Not a problem if contained (self-recovered, replaced invisibly) or is undetectable A problem resulting in multiple events, impacting multiple users The problem is impacting all or a significant number of users, for all or most of system capabilities Maybe transient Retry Isolate & replace Restart Will burn some error budget until solved Unless solved fast will impact SLOs and SLAs Redundancy Load shed API throttling/limits Isolate & replace Restart
that could impact our systems and customers. PLAN AN EXPERIMENT Create a hypothesis about what could go wrong CONTAIN THE BLAST RADIUS Execute the smallest test that will teach something (And have a rollback plan in case something goes wrong) SCALE OR SQUASH Found an issue? Superb, it can be fixed now! Otherwise, increase the blast radius until the experiment runs at full scale
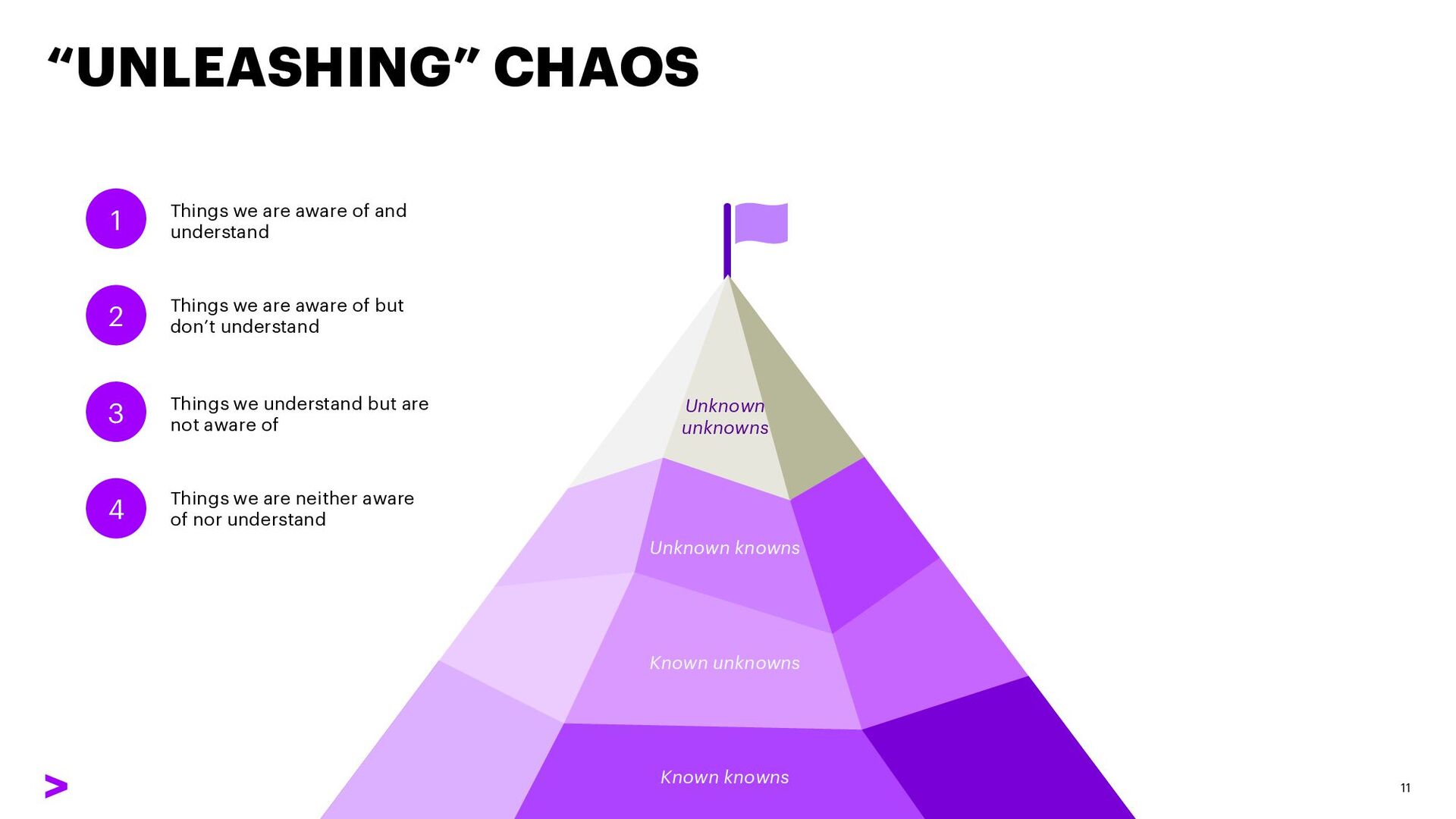
unknowns 1 2 3 4 Things we are aware of and understand Things we are aware of but don’t understand Things we understand but are not aware of Things we are neither aware of nor understand
with measuring normal activity, ensure that you have the right telemetry in place, and only afterwards plan for an experiment Plan first experiments on known-knowns and progressively go for more advanced (e.g., complex to simulate) and larger blast radius experiments Every experiment should have one or more performance metrics to halt the experiment if impacted, and one or more scenario metrics to verify the hypothesis of the experiment NEVER TEST A KNOWN BROKEN SYSTEM
a node in our Kubernetes cluster fails, it is replaced with another node and workloads are distributed across the cluster Known-unknowns: We know that the node is replaced, and we have logs to check for that, but we don’t know the average time that it takes from experiencing a failure until the cluster is back to previous state Unknown-knowns: If we shutdown two or more nodes at the same time the system should recover by itself, but we don’t know how much time will it take to recover and how many running apps will be impacted by the outage Unknown-unknowns: We don’t know exactly what would happen if we shutdown the entire Kubernetes cluster in our main region, and we don’t know the time needed to restore from the latest backups in a brand-new cluster on a different region 1 2 3 4 Experiment: Shut down one cluster node and measure times along the recovery process (increase cluster size before to reduce app outages!) Experiment: Repeat the experiment at different days and times, get an idea of the average MTTD/MTTR, configure alerts accordingly (e.g., this is taking too long to recover) Experiment : Shut down two cluster nodes at the same time (remember to increase the cluster size beforehand!), measure recovery times at different moments along the week, and repeat periodically (e.g., monthly) Experiment : You are not ready to run this experiment yet – first prioritize the engineering work to handle this failure scenario (e.g., build a backup cluster and run DR exercises) before a chaos experiment is planned and executed
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}