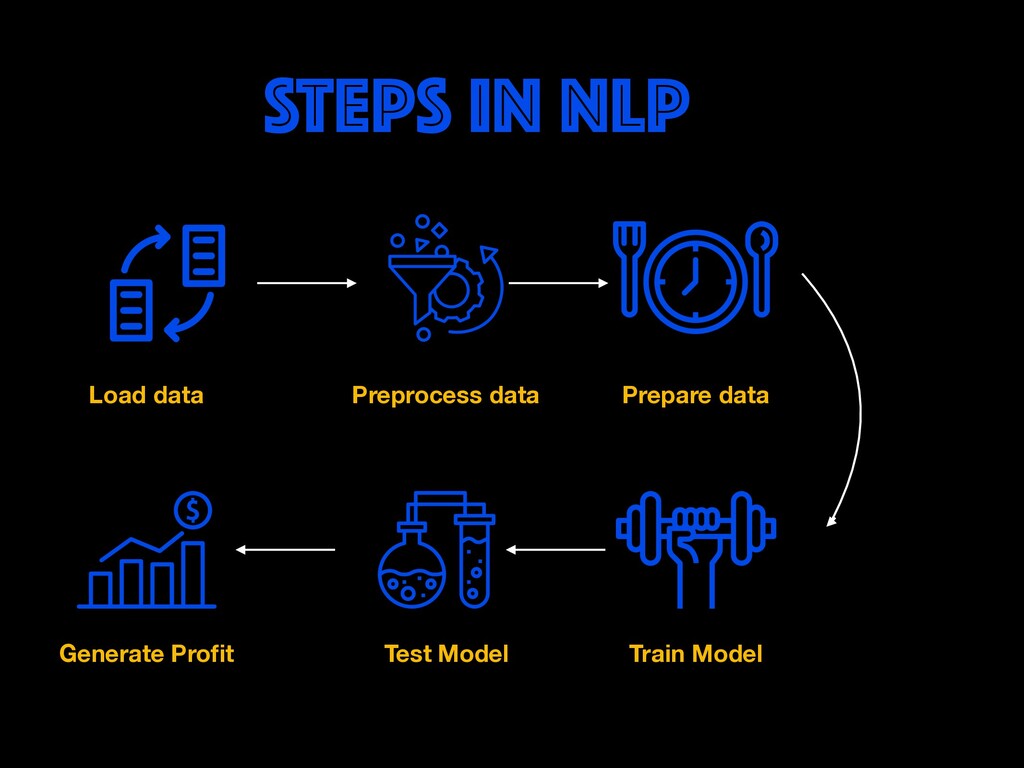
The popularity of the internet, social media and the ability to collect large amounts of user-generated content have paved the way for engineers to build intelligent products using NLP. In this workshop, we will learn how NLP based prototypes can be built. Hands-on labs for working on multiple methods of sentiment analysis will be done to understand behind the scenes of Sentiment Analysis.
* Explore ways of cleaning and representing Text data
* Implement common sentiment classification methods
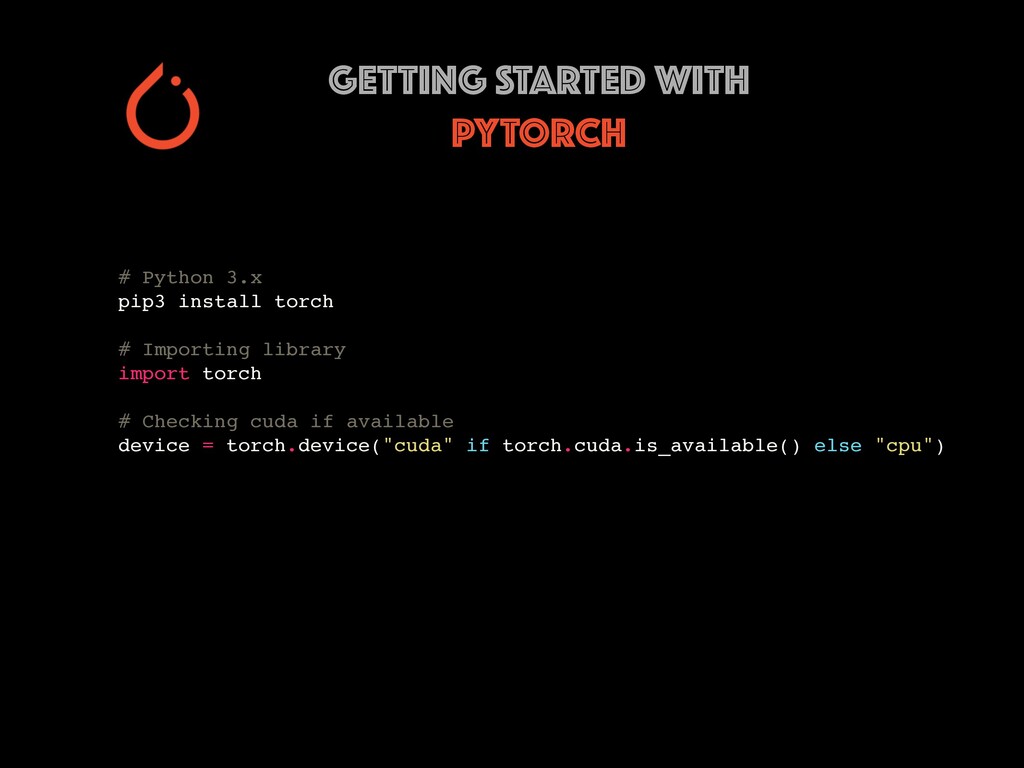
* Explore Deep learning framework Pytorch for NLP
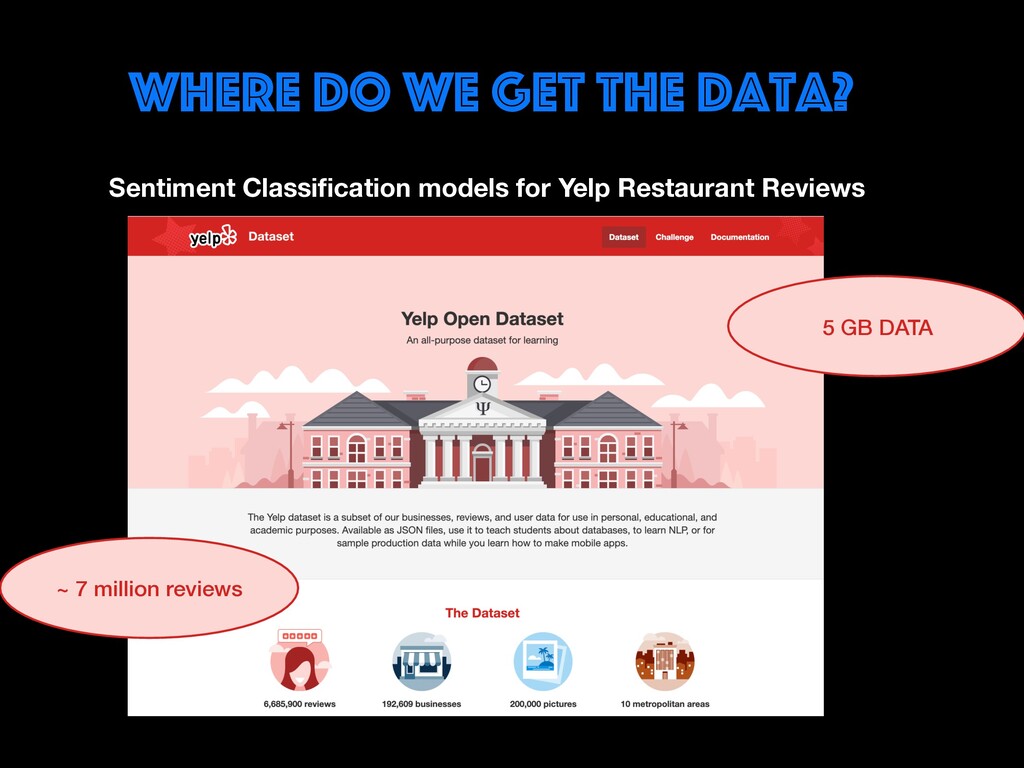
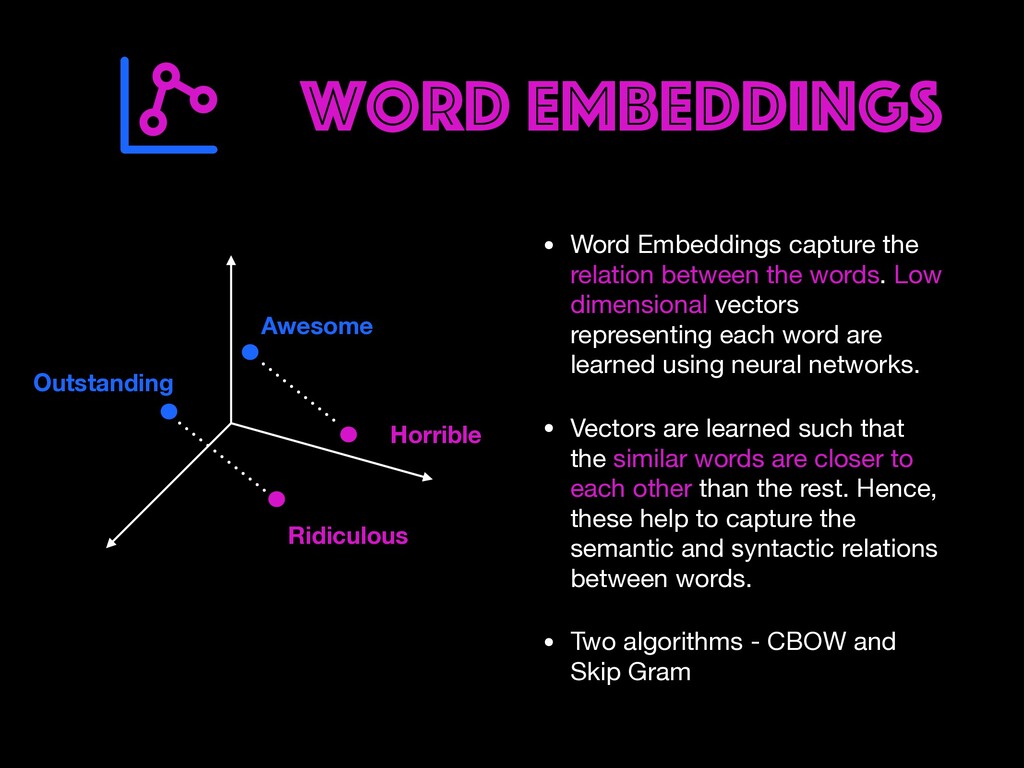
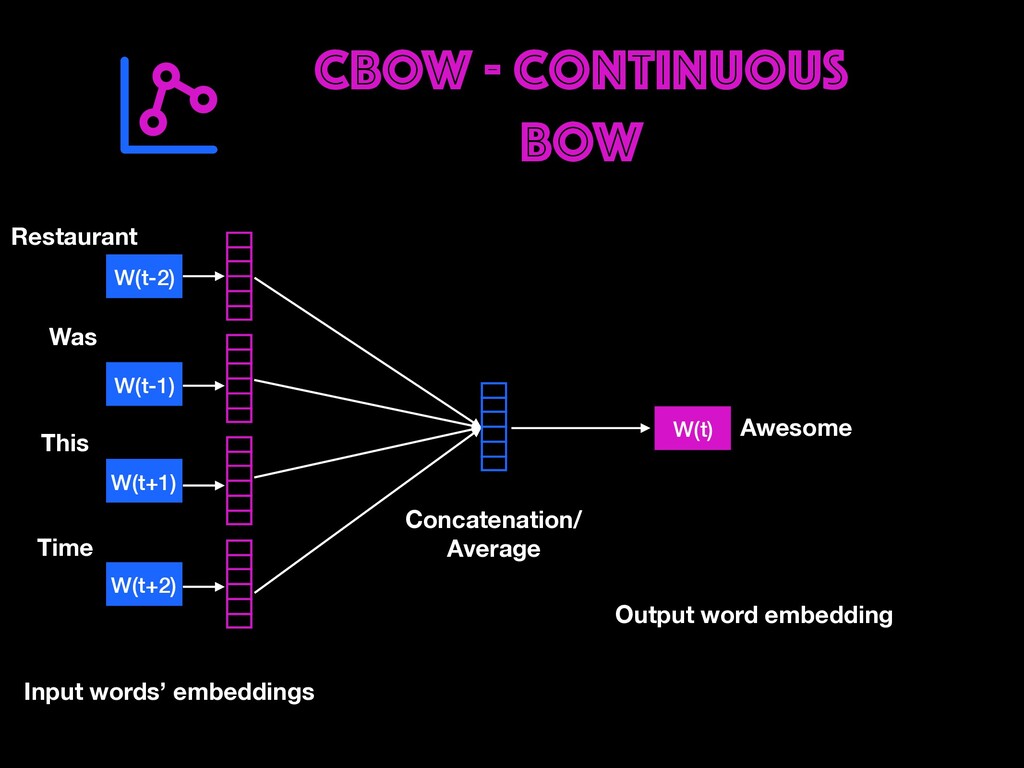
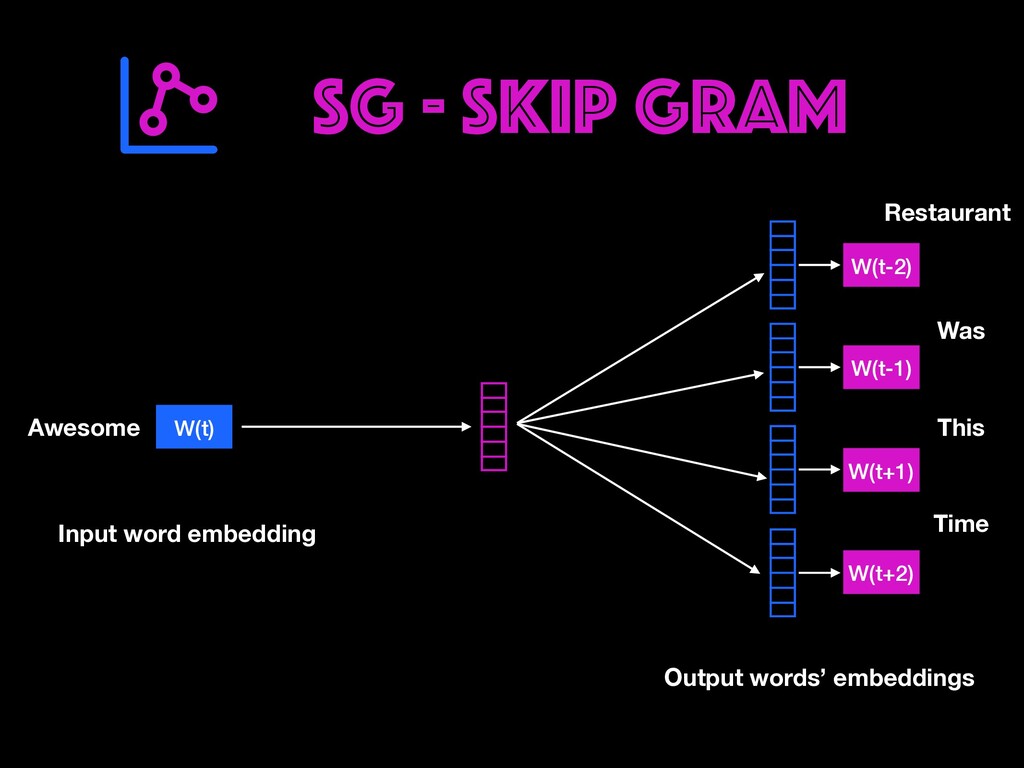
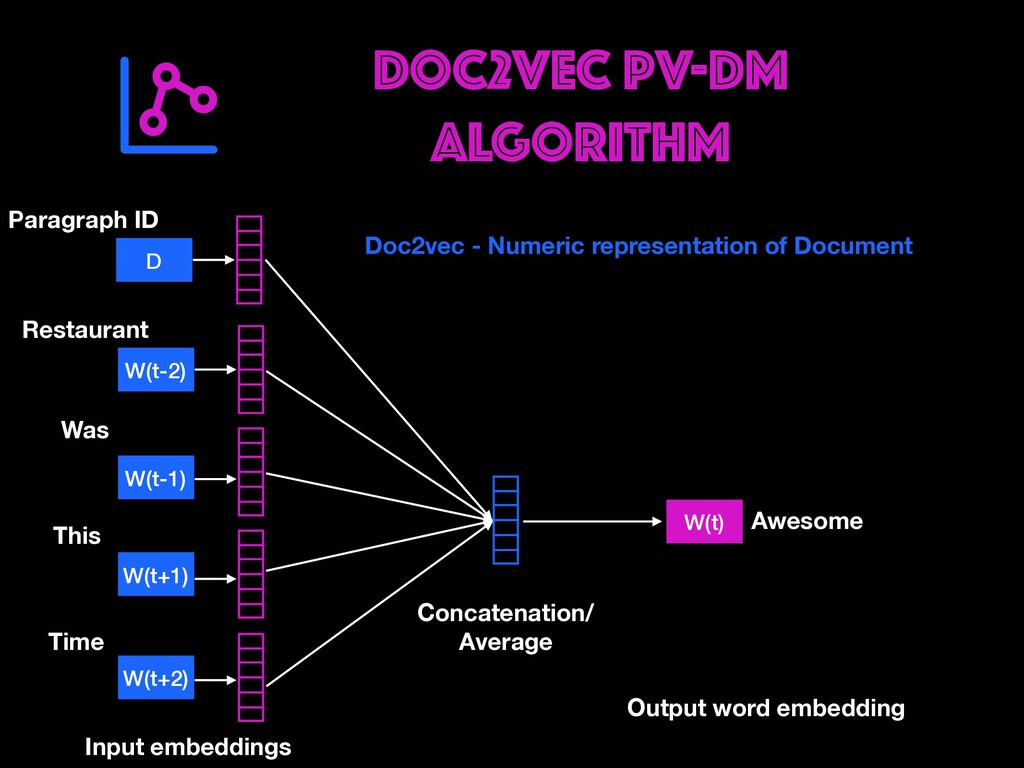
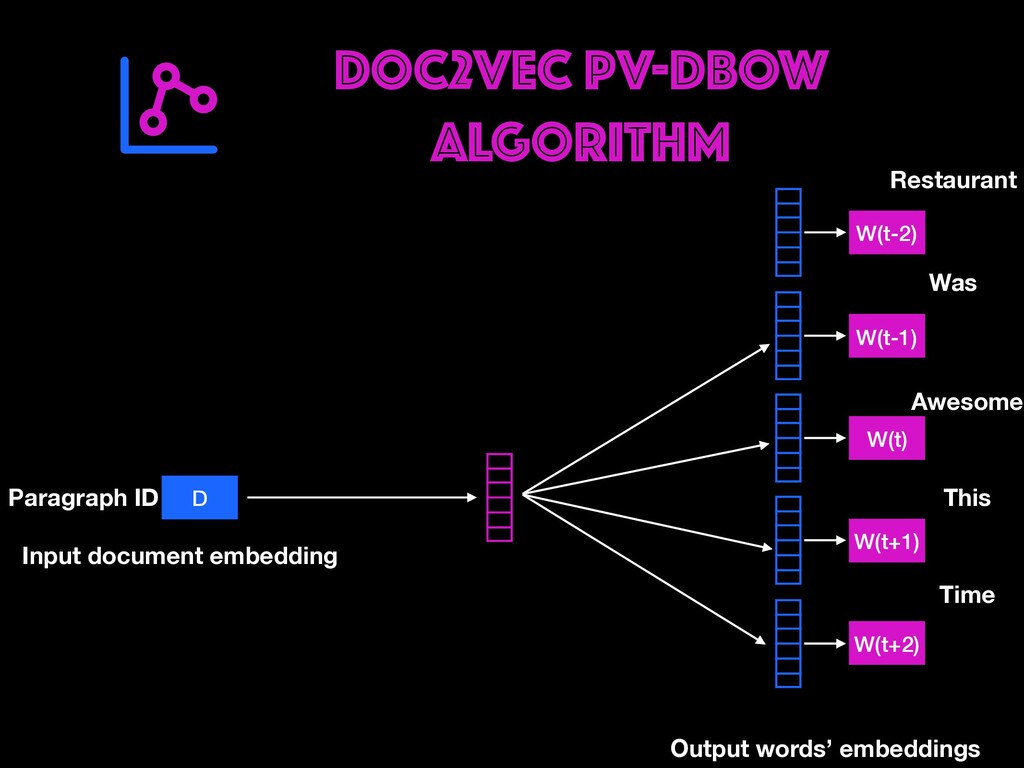
Restaurant review data will be explored to find user opinions. Different ways of cleaning, representing text (BOW, TF-IDF, Word Embeddings) and handling real-world data issues will be dealt with during the workshop. You will get to learn how to build AI prototypes with a rich ecosystem like Pytorch library developed by Facebook's AI Research lab. Google colab notebooks would be used during the sessions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GET THE METrics from sklearn.metrics import classification_report print(classification_report(Y_test['sentiment'],test_predictions)) Actual Labels](https://files.speakerdeck.com/presentations/7d453d1e9d824da6a11340dfce96438c/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! :) [email protected]](https://files.speakerdeck.com/presentations/7d453d1e9d824da6a11340dfce96438c/slide_82.jpg){kind=link}
{kind=link}