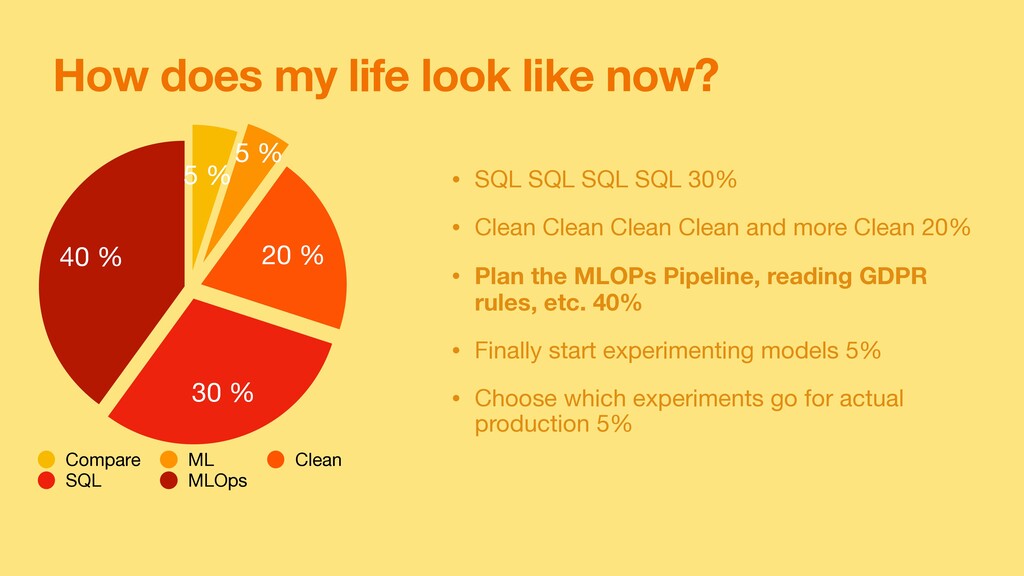
SQL SQL 30% • Clean Clean Clean Clean and more Clean 20% • Plan the MLOPs Pipeline, reading GDPR rules, etc. 40% • Finally start experimenting models 5% • Choose which experiments go for actual production 5% 40 % 30 % 20 % 5 % 5 % Compare ML Clean SQL MLOps
ML Systems. https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning - Entails implementing automation and monitoring at all steps of ML system construction, including integration, testing, releasing, deployment and infrastructure management - With ML Systems CT ( Continuous retraining and serving model) is new and also the CI part involves testing of the data schema, models etc. on top of usual unit testing. - DevOps is a popular practice in developing and operating large-scale software systems. It involves CI (Continuous Integration) and CD ( Continuous Delivery)
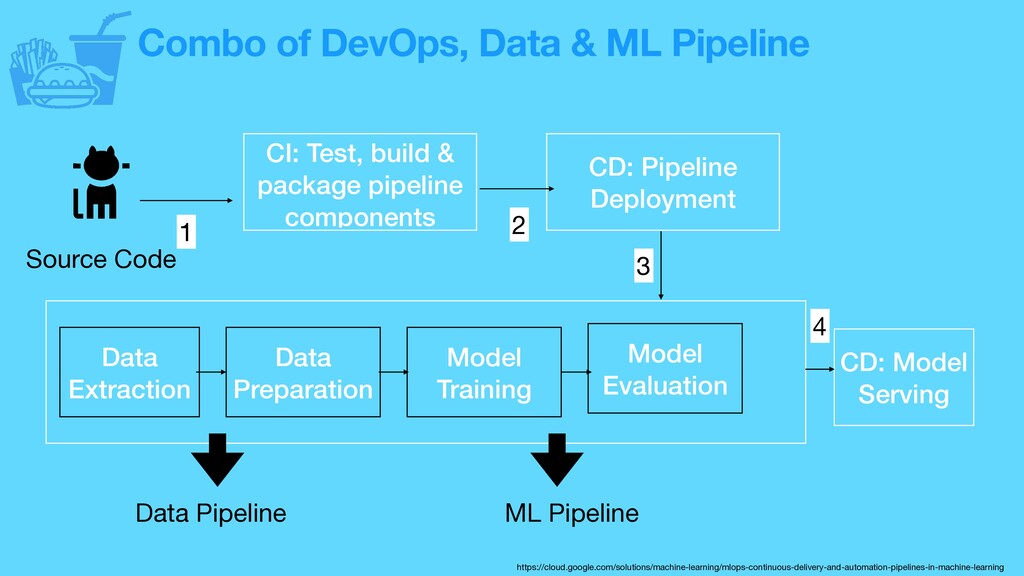
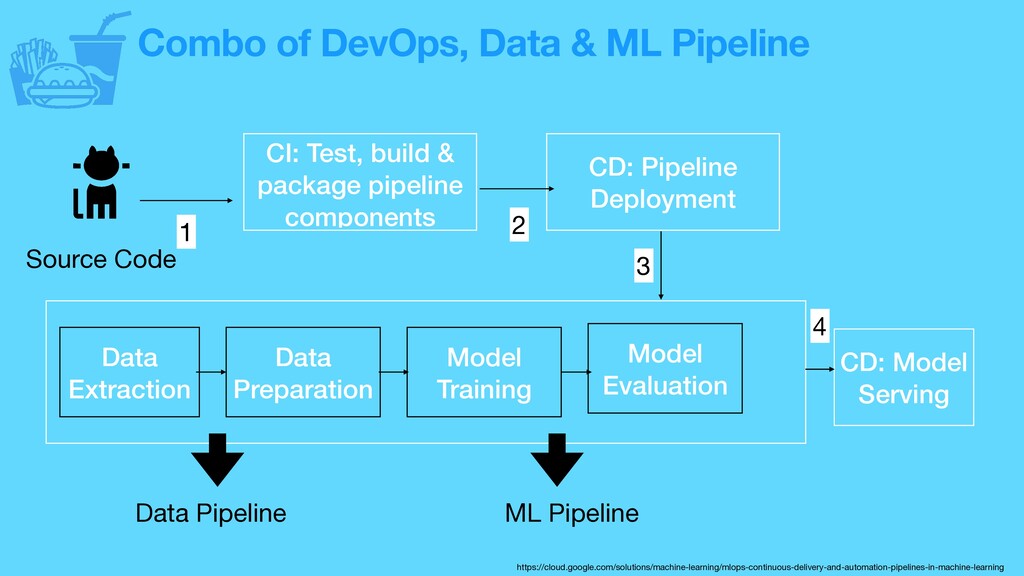
Test, build & package pipeline components CD: Pipeline Deployment Data Extraction Data Preparation Model Training Model Evaluation CD: Model Serving Data Pipeline ML Pipeline 1 2 3 4 https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
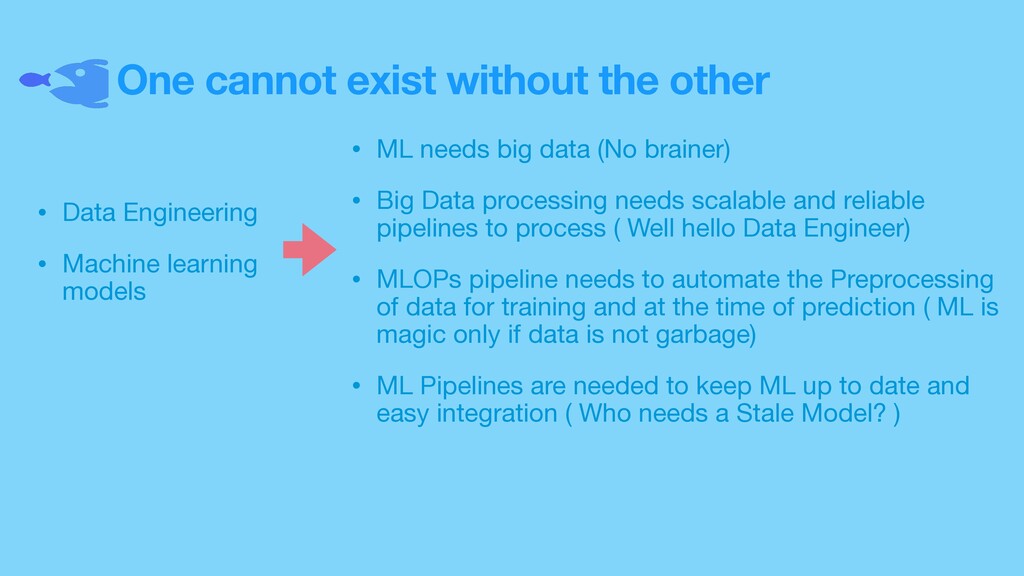
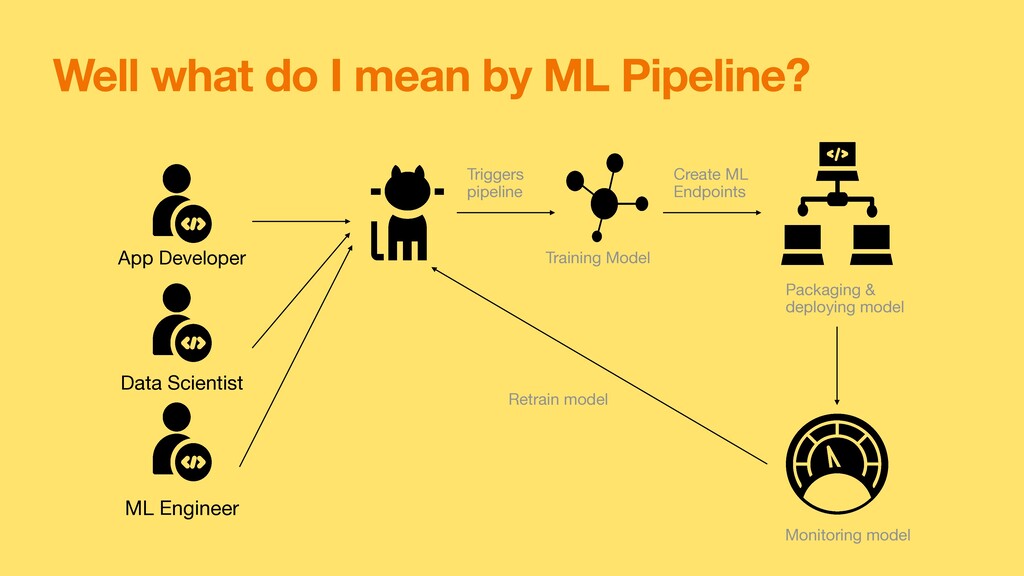
Machine learning models • ML needs big data (No brainer) • Big Data processing needs scalable and reliable pipelines to process ( Well hello Data Engineer) • MLOPs pipeline needs to automate the Preprocessing of data for training and at the time of prediction ( ML is magic only if data is not garbage) • ML Pipelines are needed to keep ML up to date and easy integration ( Who needs a Stale Model? )
Reeeaaaal goooood at SQL • Develops code that preprocesses data e ffi ciently ( Pandas, PySpark etc. ) • Be familiar with data pipeline products that can scale ( Air fl ow, Apache NiFi etc. ) • Setting up data 24*7 monitoring • Know how to set up DevOps pipeline or at least be able to work with it.
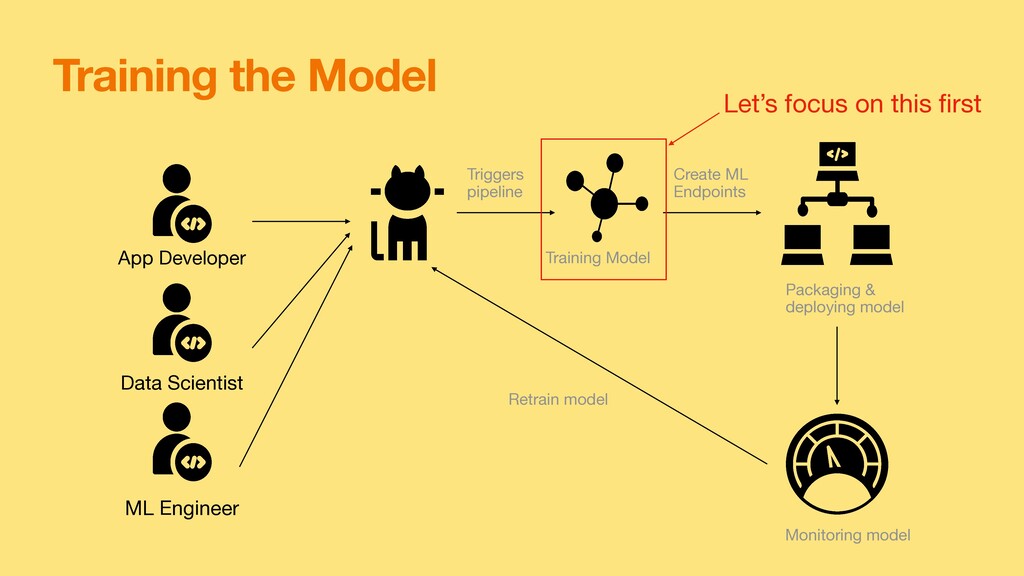
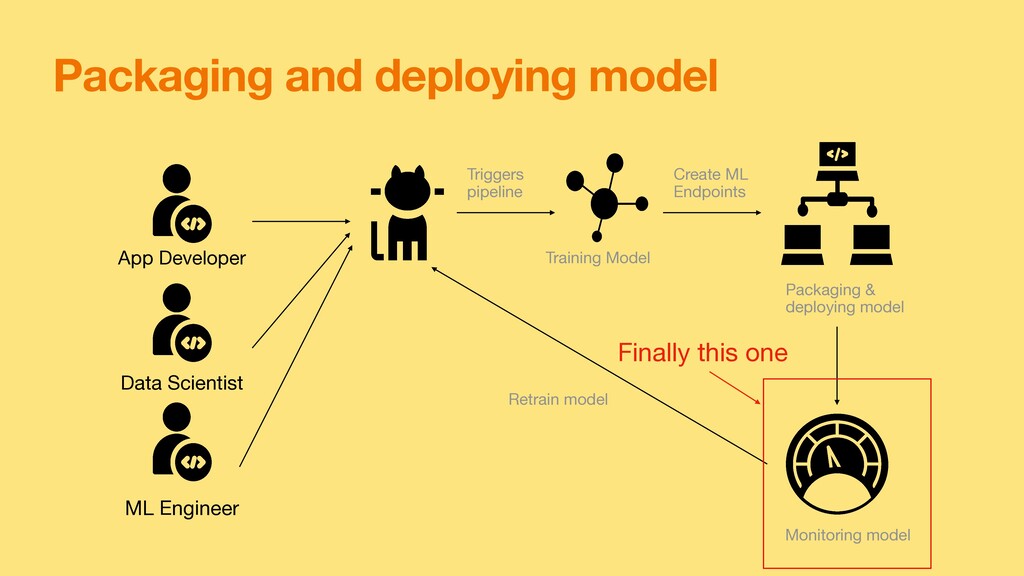
reliable ML Pipeline with training, testing and prediction automated on changes to code or data • Know how to use di ff erent data versioning tools and Machine learning pipeline technologies ( Sagemaker, DVC, Splitsgraph, etc. ) • Build ML models and know various frameworks ( PyTorch, Tensor fl ow, Keras etc. ) • Be able to stitch Data Engineer Pipeline with Machine learning Pipeline • Maintain the production model
for storing python package containing train code & storing the model •Project Setup for example in GCP: •Training code is structured as Python Package in /trainer subdirectory. def _train_and_evaluate(estimator, dataset, output_dir) : """Runs model training and evaluation. Args: estimator: (pipeline.Pipeline), Pipeline instance, assemble pre-processing steps and model training dataset: (pandas.DataFrame), DataFrame containing training data output_dir: (string), directory that the trained model will be exported Returns: None """ x_train, y_train, x_val, y_val = utils.data_train_test_split(dataset ) estimator.fit(x_train, y_train ) # Note: for now, use `cross_val_score` defaults (i.e. 3-fold) scores = model_selection.cross_val_score(estimator, x_val, y_val, cv=3 ) logging.info(scores ) # Write model and eval metrics to `output_dir` model_output_path = os.path.join ( output_dir, 'model', metadata.MODEL_FILE_NAME ) metric_output_path = os.path.join ( output_dir, 'experiment', metadata.METRIC_FILE_NAME ) utils.dump_object(estimator, model_output_path ) utils.dump_object(scores, metric_output_path ) Reference: https://github.com/GoogleCloudPlatform/cloudml-samples/tree/master/sklearn/sklearn-template/template/trainer Reference:https://cloud.google.com/ai-platform/docs/getting-started-keras
deploy the model Reference:https://cloud.google.com/ai-platform/training/docs/overview Python package path & assign module that AI platform will run Job-dir is path to google storage where intermediate and outputs are stored. Number of nodes on which the job will be ran
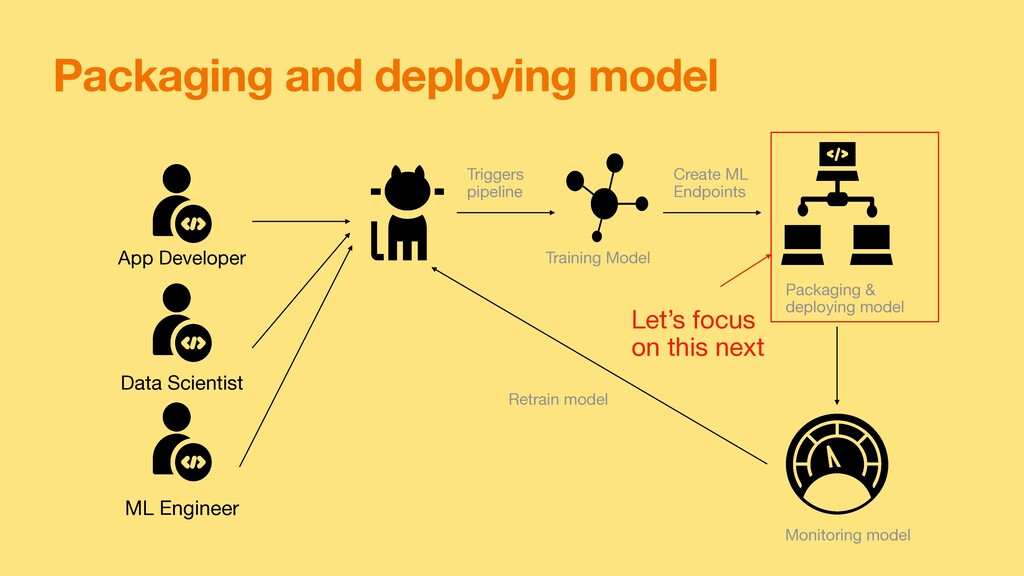
resource in AI Platform 2. Create a model version and serve 3. Once the service is available you can invoke as shown in the code. Reference:https://github.com/GoogleCloudPlatform/cloudml-samples/blob/master/sklearn/sklearn-template/template/scripts/predict.py import googleapiclient.discovery def predict(project, model, data, version=None) : """Run predictions on a list of instances. Args: project: (str), project where the Cloud ML Engine Model is deployed. model: (str), model name. data: ([[any]]), list of input instances, where each input instance is a list of attributes. version: str, version of the model to target. Returns: Mapping[str: any]: dictionary of prediction results defined by the model. """ service = googleapiclient.discovery.build('ml', 'v1' ) name = 'projects/{}/models/{}'.format(project, model ) if version is not None : name += '/versions/{}'.format(version ) response = service.projects().predict ( name=name, body= { 'instances': dat a }).execute( ) if 'error' in response : raise RuntimeError(response['error'] ) return response['predictions' ]
Test, build & package pipeline components CD: Pipeline Deployment Data Extraction Data Preparation Model Training Model Evaluation CD: Model Serving Data Pipeline ML Pipeline 1 2 3 4 https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
Choose one of your choice, GCP is my personal fav ) • Learn Data Pipeline tools • Experiment data pipeline tools in Cloud • Use CICD (DevOPs) pipeline in your projects • Learn about ML Pipeline tools • Experiment ML pipeline tools in Cloud • Learn to integrate Data pipeline with ML Pipeline in Cloud
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}